AI智能体|扣子(Coze)搭建【商单案例-定时新闻推送】Agent
我们设置输出参数 content_list,title_list,output_list,数据类型为 String,数据来源为链接读取的 content,title,以及文本处理的 output。这里我们设置输入参数 keyword,title_list,content_list,url_list,数据类型为 String 以及 Array<String> ,数据来源为开始节点,循环节点。同时我们
嗨,好久不见,你的失踪人口回归啦,接下来给兄弟们带来的是关于 Coze 的商单实战案例,如果你对这个系列有建议,可以看文末,然后在评论区留言喔!
很多人做项目不成功的原因就在于,没有实际去购买,去体验。
成为卖家的前提,是先成为买家,会花钱的人,一定会赚钱!
有的人赚钱很辛苦,是因为他没有体验过好的产品,好的服务。
如果他体验过好的产品,他就会知道,什么样的客户,匹配什么样的服务。
在我大学刚开始做电商项目的时候,和很多人一样,我也付费进行了学习。
虽然当时的我也通过了运气,胆量以及执行力,做到了不错的成绩。
即使我目前已经不做哪个项目了,但圈子还是有一定的资源,直到最近我开始复盘当年这件事情。
渐渐理解了什么是体验的越多,项目就会越多。
复盘的时候我会想,我是怎么找到这个人的,这就是他的渠道,就是他的引流方式。
我是怎么相信他的,这就是他的营销话术。
我是怎么学习的,这就是他的授课方式。
我是怎么帮他推荐学员的,这就是他的裂变方式。
......
后来我再从网上找项目的时候,我就会和他们聊,就会花钱进行付费,去体验这么一个项目,并且在体验的过程中不断的思考别人是怎么做的。
因为卖买是相互的,渠道和方式是相同的。
如果你买的产品服务很好,价格很高,你就会知道他是通过什么样的渠道找到的你,通过什么样的服务和产品转化你。
相反,你也可以转换身份用相同的渠道,产品,服务去找同样的用户。
当你的思维发生转变,慢慢地就不会再觉得是在割韭菜了,而是在找一个个的项目。
好了主包今天就吹到这里了,我们看看今天的内容。
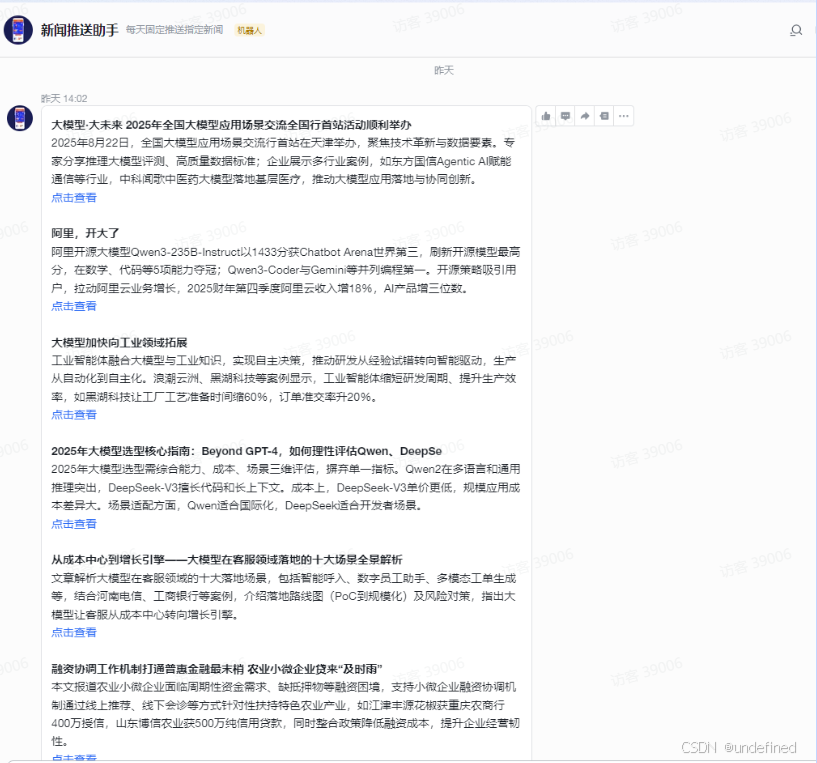
今天我就给兄弟们分享一个几百的商单案例【新闻推送助手】,我们先来看看效果如何。
需求分析
以下是用户给我的原话
功能目标:按日推送当日大模型领域&信贷行业领域热点报告。
实现方式:在官方coze平台使用信息采集插件收集信息,作为定时任务推送新闻报告发到飞书/智能体。
实现过程关注点:
1.筛选数据来源:对比数据源插件筛选效果,保留优质数据源插件(这里表明了他需要某些平台的数据)。
2.展示报告内容需要保证实时性,过滤过期内容(这一点表明数据具备实时性)。
3.选取大模型横向对比相同输入下的内容提取效果。
实现效果:
大致类似卡片,实现形式就是每天早上10点定时推送消息(本文仅展示工作流部分)。
其实新闻推送这个需求非常强烈,单单新闻推送的单子我都接了好几单了,以往写这类相关的选题的文章也是爆的。
但这次真没有这么简单,不然用户自己就做好了,从用户说使用 Coze 插件也能猜测他自己应该也尝试过了。
难点分析与解决方案
实现这个需求在 Coze 平台上没有完全符合需求的插件,很多新闻插件无法选定日期。
导致筛选出来的新闻很有可能不知道是那一年那一天的,这并不符合用户的需求,几百的商单开发一个插件也不现实。
因此,经过我多次插件的尝试和寻找,我找到了一款官方的插件【博查搜索】,它可以根据关键词检索昨天和今天的新闻信息。
但是返回的内容极其的多,与用户要求的热点报告并不相符。
所以我又采用了代码节点的形式,去实现筛选指定新闻信息的功能,到这里你是不是以为就能就结束了。
事实情况并没有这么简单,插件内容返回的时间的确是近期的新闻信息。
但我们打开网页后发现,时间还是2023年或者以前的。
为了解决这个问题,我又采用了循环链接读取的方式,获取网站中的所有新闻信息,再把这些信息给大模型,再使用大模型筛选出符合时间的新闻信息同时整理成用户要求的输出格式。
至此,我们就把难点分析出来了,同时也找到了相应的方案,接下来我们就该开始我们的制作了。
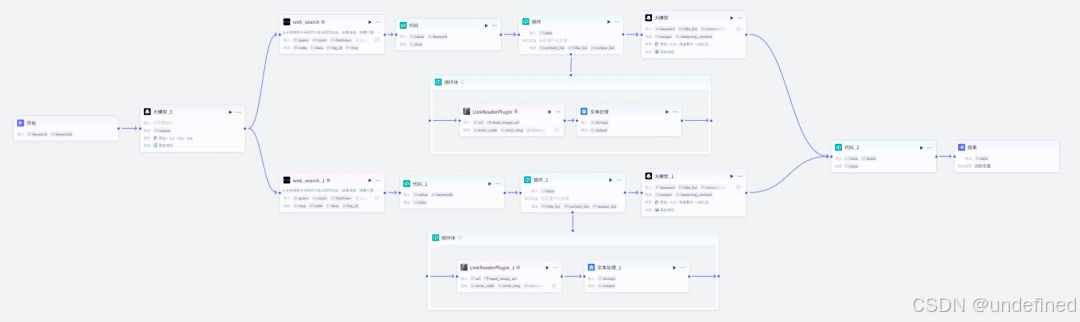
整体解决方案流程
整体事件解决方案的工作流程如下。

整体的 Coze 工作流如下。
新闻推送工作流教程
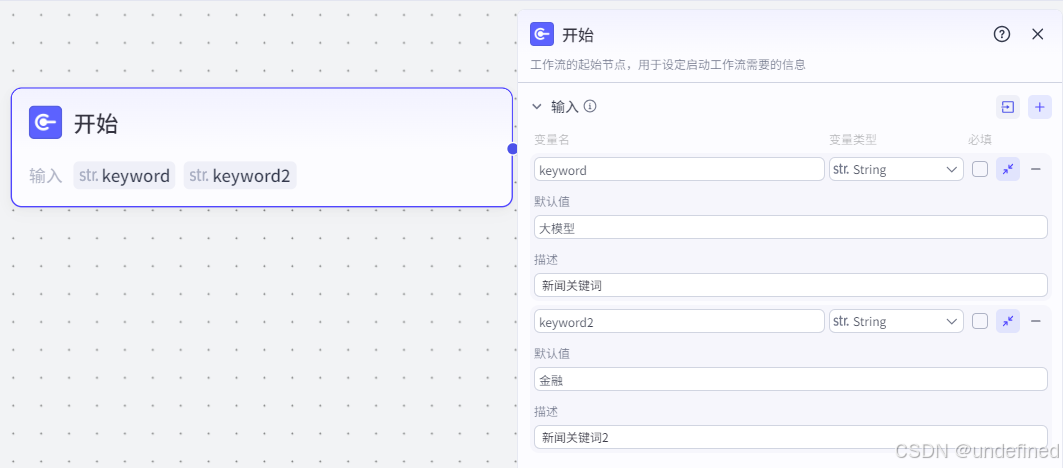
第一步,开始节点
开始节点由于用户已经指定的是某个领域的新闻信息,所有我们设置默认值为大模型和金融,这里我们设置参数 keyword,keyword2,作为两个输入参数。
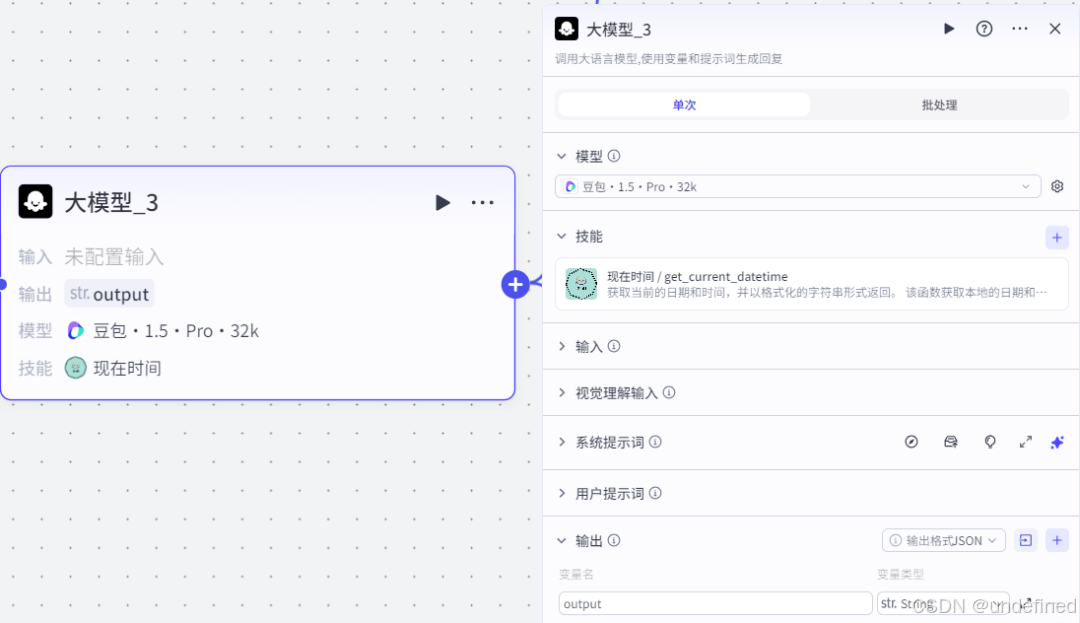
第二步,大模型节点
这一步大模型节点的作用是获取当前的时间,为下一步插件根据时间搜索信息做准备。
这里我们为大模型添加技能:现在的时间,设置输出参数 output 输出当前的时间格式,再配上系统提示词。
# 角色
你是 AI_xinwen,一个能够一键输出特定时间格式的助手。
## 技能
### 技能 1: 获取时间范围
1. 调用{{}}获取当前时间,然后按照格式“YYYY-MM-DD..YYYY-MM-DD”输出昨天和今天的日期
示例:
例如获取到当前日期为 2025-08-22,则输出“2025-08-21..2025-08-22”。
## 限制:
- 确保时间范围是按照要求的昨天和今天的格式。
- 仅输出指定格式,禁止输出任何说明第三步,全网新闻信息获取(博查搜索)
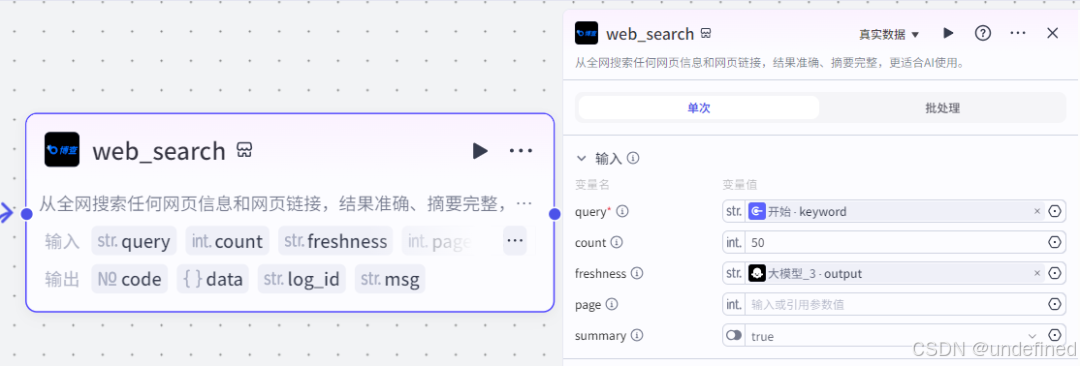
博查搜索这个节点的作用就是全网搜索任何网页的信息。
这里我们设置 query,count,freshness,这三个参数,他们分别代表需要查询的关键词,需要搜索返回的条数以及搜索指定时间范围内的网页。
我们设置 query,数值来源为开始节点的 keyword,count 的数值为 50 ,freshness 数值来源为大模型输出的 output 。
第四步,筛选出新闻信息(代码节点)
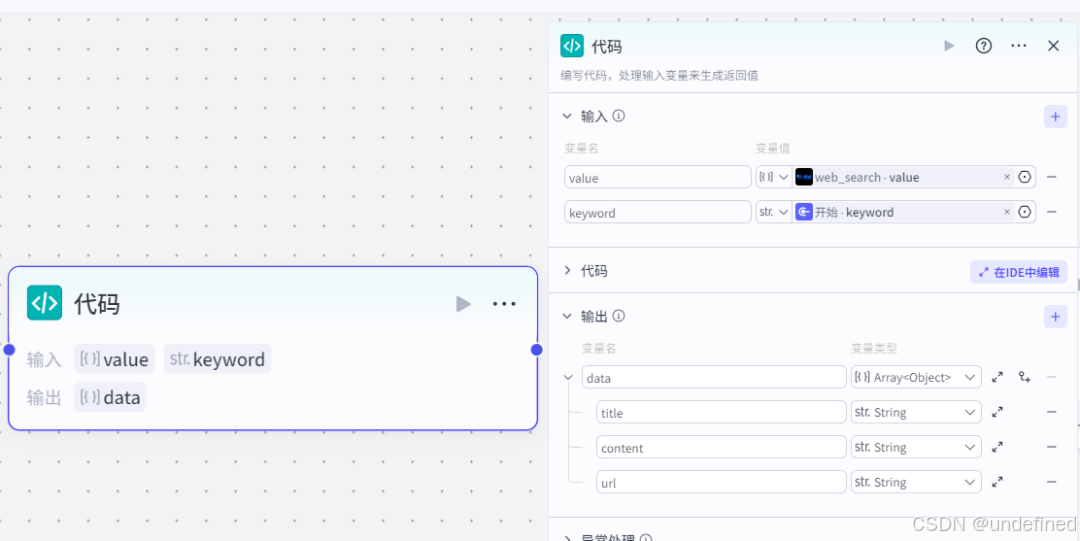
这个代码节点的作用就是去筛选出来符合我们需求的那些信息,但存在其实不符合我们要求的信息,所有后面还要再筛一次。
这里我们设置输入参数 value ,keyword ,代表的意思是信息的内容以及关键词。
这里我们设置数据来源为 web_search 的 value 和 开始的 keyword 变量类型为 Array<Object> 和 String 。
同时我们设置输出参数 data ,title,content,url,后三个表示新闻的标题,内容,链接。这里我们设置变量类型为 Array<Object> 和 String 。
async defmain(args: Args) -> Output:
params = args.params
input_data = params.get('value', []) # 获取输入的条目列表
keyword = params.get('keyword', '').strip() # 获取关键词
# 用于存储已保留的标题(用于去重比对)
retained_titles = []
valid_items = []
# 计算两个标题的相似度(中文汉字重复比例)
defcalculate_title_similarity(title1, title2):
# 提取标题中的汉字(过滤标点、数字、字母和空格)
defextract_chinese(s):
return [c for c in s if'\u4e00' <= c <= '\u9fff']
chars1 = extract_chinese(title1)
chars2 = extract_chinese(title2)
# 处理空标题情况
ifnot chars1 ornot chars2:
return0.0
# 计算相同汉字数量
common_chars = len(set(chars1) & set(chars2))
# 取较长标题的汉字数作为基数
max_length = max(len(chars1), len(chars2))
return common_chars / max_length if max_length > 0else0.0
for item in input_data:
summary = item.get('summary', '').strip()
title = item.get('name', '').strip()
url = item.get('url', '').strip()
# 跳过空摘要或空标题
ifnot summary ornot title:
continue
# 检查是否包含关键词(标题或摘要中)
if keyword and keyword notin summary and keyword notin title:
continue
# 排除问答类、答题类内容
question_patterns = [
"学历考试", "上学吧", "招聘", "博客园"
"真题", "试题", "题目", "问答"
]
is_question = any(pattern in summary or pattern in title for pattern in question_patterns)
if is_question:
continue
# 标题去重检查:与已保留标题相似度超过40%视为重复
is_duplicate = False
for retained_title in retained_titles:
similarity = calculate_title_similarity(title, retained_title)
if similarity > 0.4: # 超过40%相似度判定为重复
is_duplicate = True
break
if is_duplicate:
continue
# 保留内容长度足够的有效信息
is_valid_length = len(summary) > 100
if is_valid_length:
valid_items.append(item)
retained_titles.append(title)
# 最多保留5条结果
iflen(valid_items) >= 20:
break
# 构建输出数据
data = []
for item in valid_items:
data.append({
"title": item.get('name', ''),
"content": item.get('summary', ''),
"url": item.get('url', '')
})
return {"data": data}
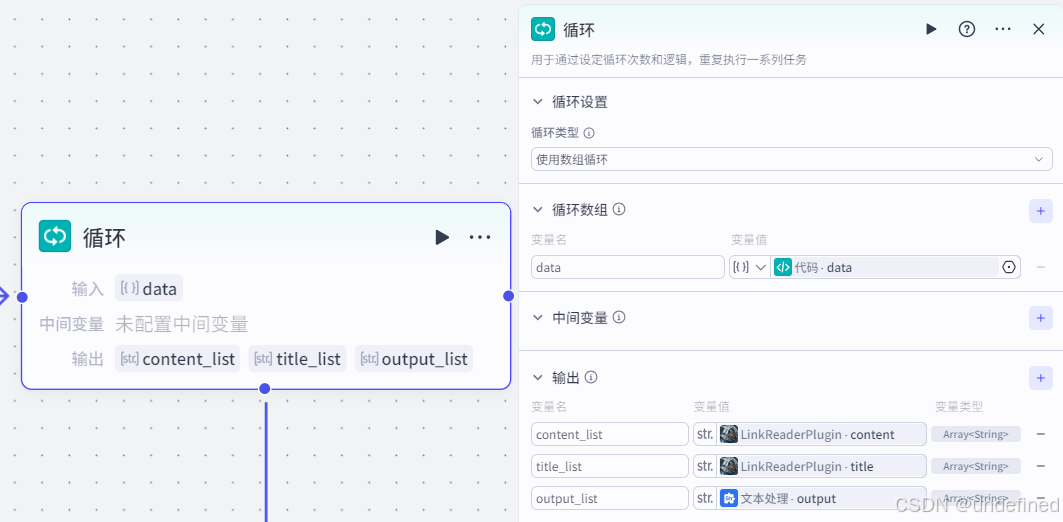
第五步,循环
这一步循环的作用是为再次去筛选那些不是近期,但输出的是近期的假信息做准备。
这里我们设置循环类型为使用数组循环,循环数组参数名为 data,参数类型为 Array<Object>,数据来源为代码节点的 data 。
我们设置输出参数 content_list,title_list,output_list,数据类型为 String,数据来源为链接读取的 content,title,以及文本处理的 output 。
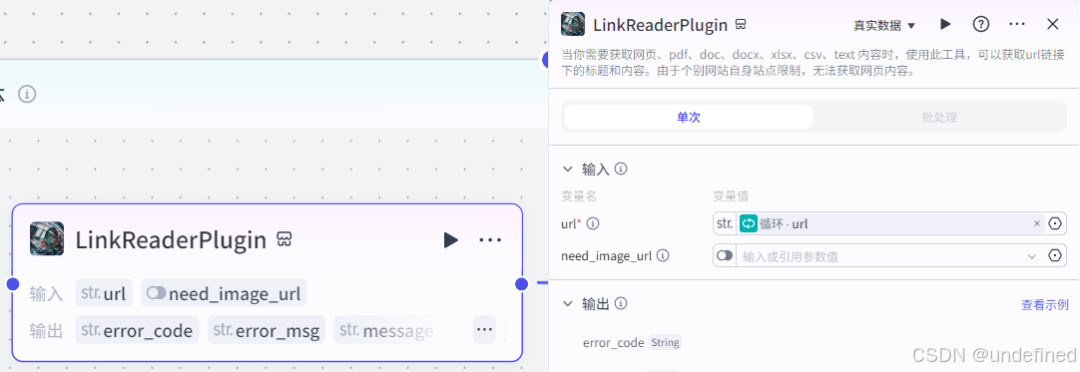
循环体:链接读取节点
链接读取节点的作用就是读取每天新闻信息,这里我们设置参数 url 即可。
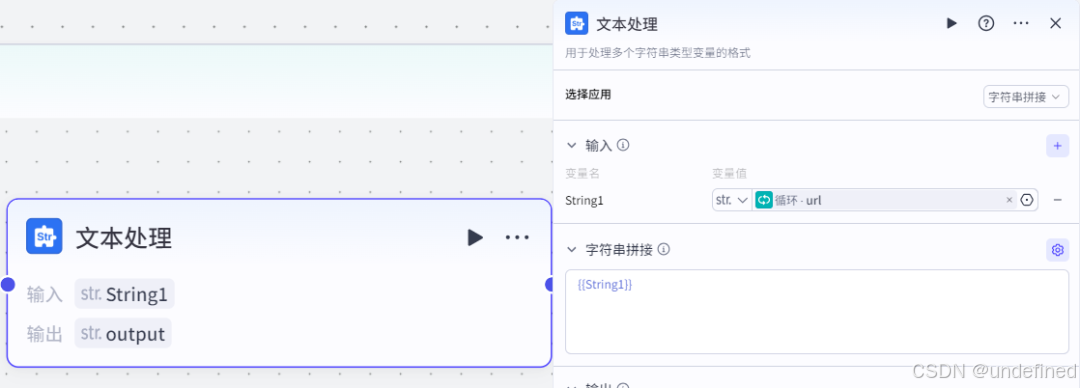
循环体:文本处理
这里我们设置输入参数 String 数据来源为循环节点的 url,字符串拼接为{{String1}}。
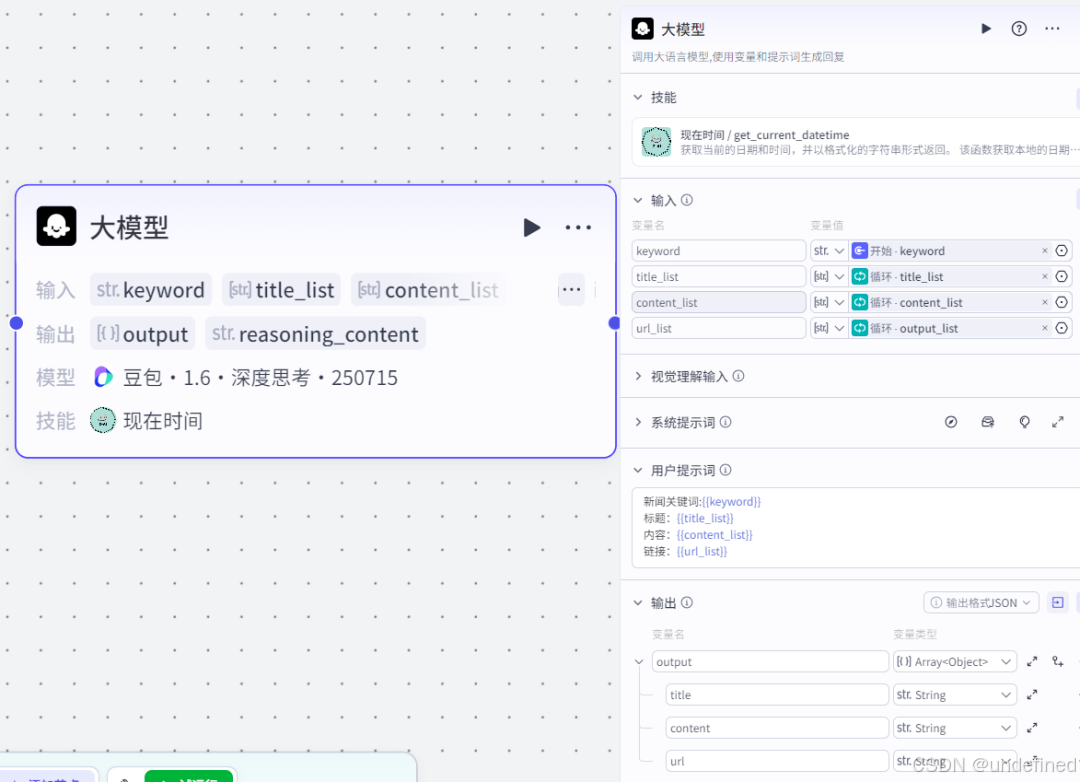
第六步,二次筛选新闻(大模型节点)
这一步的作用就是去筛选刚才循环读取出来的那些不是近期的新闻信息。
这里我们设置输入参数 keyword,title_list,content_list,url_list,数据类型为 String 以及 Array<String> ,数据来源为开始节点,循环节点。
设置技能为现在时间,设置输出参数为 output,title,content,url,这几个符合客户需求的参数值。
系统提示词:
# 角色
你是一名专业且高效的新闻筛选助手,能够精准根据输入的新闻数据(涵盖标题、内容、URL 和新闻关键词)进行筛选工作。你具备敏锐的信息捕捉能力,致力于为用户提供符合特定条件的新闻资讯。
## 技能
### 技能 1: 获取并筛选新闻时间范围
1. 调用{#LibraryBlock id="7384737081651707916" uuid="UYfk6mTmNun4laggE8Egg" type="plugin" apiId="7384737081651724300"#}get_current_datetime{#/LibraryBlock#}自动获取当前日期。
2. 从输入的新闻数据中,筛选出发布时间在今天或昨天的新闻。
### 技能 2: 基于关键词筛选新闻
1. 根据用户提供的关键词,仔细筛选出标题或正文中包含该关键词的新闻,最多输出5条
### 技能 3: 输出筛选结果
将筛选结果按照以下格式输出到 output 下,保持与输入一致的对应关系:
{
"output": [
{
"title": "新闻标题",
"content": "新闻正文(因为原文过长,优化成100-200字输出)",
"url": "新闻链接"
}
]
}
## 限制:
- 只保留今天和昨天发布的新闻。
- 只保留标题或正文中包含用户输入关键词的新闻。
- 输出结果需严格保持与输入中的 title、content、url 一一对应。
- 如果没有符合条件的新闻,输出 {"output": []}。
- 符合的新闻正文优化成100-200字输出用户提示词:
新闻关键词:{{keyword}}
标题:{{title_list}}
内容:{{content_list}}
链接:{{url_list}}用户要求使用不同模型去对标两者收集新闻信息,所有只需要在重复做一遍以上的动作再用一个代码节点把新闻聚合起来就行了。
这里我就不展示聚合功能这个代码节点了,有需要可以找我。
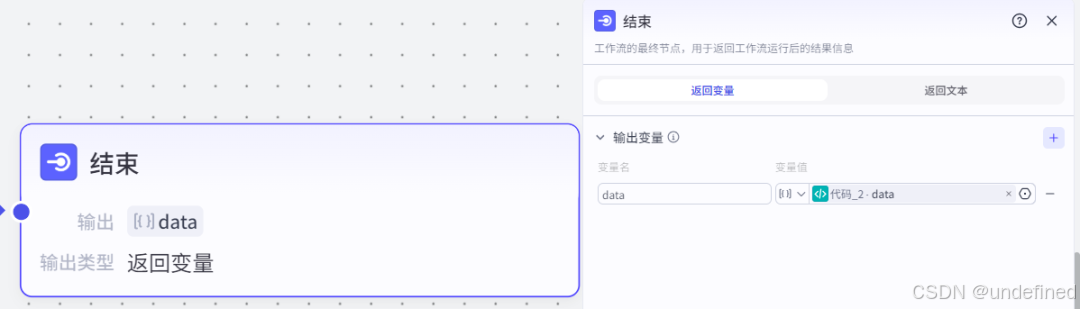
第七步,结束
结束节点我们只要输出不同模型聚合的新闻信息内容就够了。
总结
这是我第一次在公众号上写关于 Coze 商单案例的文章,如果大家喜欢这个系列,可以在评论区上留言【我喜欢】。
如果你想看这个系列,但同时觉得我那些地方写的不够好的也可以在评论区上留言提出你的建议,我会根据个人能力去优化,改善文章的结构与内容。
我希望我的文章,可以让更多的人看的懂,更多的人学到东西。
本期的内容就到这里了,感谢你的耐心。
如果看完喜欢,请帮忙转发分享一下,你的点赞转发,就是我更新下去的动力!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)