大模型8月进展
大型验证器系统医学领域适应备注:应该是参考kimi k2的技术。但kimi k2是用于预训练,他们这个现如今,AI医疗可谓是大模型落地趋势中的垂直领域之一。它备受AI大佬以及硅谷顶尖公司关注,是最重视的落地领域——比如在开源模型gpt-oss的评测中,医疗领域的表现排在数学、代码等热门能力之前展现;GPT-5发布会上,Altman就专门花时间体现了ChatGPT在医疗问诊场景中的实际价值。深度学习
1、百川发布推理新模型,掀翻医疗垂域开源天花板
让OpenAI只领先5天,百川发布推理新模型,掀翻医疗垂域开源天花板
Baichuan-M2-32B is Baichuan AI's medical-enhanced reasoning model, the second medical model released by Baichuan. Designed for real-world medical reasoning tasks, this model builds upon Qwen2.5-32B with an innovative Large Verifier System. Through domain-specific fine-tuning on real-world medical questions, it achieves breakthrough medical performance while maintaining strong general capabilities.
大型验证器系统
- 病人模拟器:基于真实临床病例的虚拟病人系统
- 多维度验证:医疗准确性、回复完整性、后续认知度等8个维度
- 动态评分:实时生成针对复杂临床场景的自适应评估标准
医学领域适应
- 中期培训:在保留一般能力的同时注入医学知识
- 强化学习:多阶段 RL 策略优化
- 通用-专业平衡:精心平衡的医学、通用和数学综合训练数据
备注:应该是参考kimi k2的技术。但kimi k2是用于预训练,他们这个KIMI K2 技术报告: OPEN AGENTIC INTELLIGENCE_kimi k2:open agent-CSDN博客
现如今,AI医疗可谓是大模型落地趋势中讨论度最高的垂直领域之一。
它备受AI大佬以及硅谷顶尖公司关注,是OpenAI最重视的落地领域——比如在开源模型gpt-oss的评测中,医疗领域的表现排在数学、代码等热门能力之前展现;GPT-5发布会上,Altman就专门花时间体现了ChatGPT在医疗问诊场景中的实际价值。
深度学习之父Hinton也一直笃信AI医疗的价值,前不久在中国的首次公开演讲中,也再次提到了AI对医疗行业的深远影响。
可以明显感受到,大模型+医疗,正在成为一种全球共识。
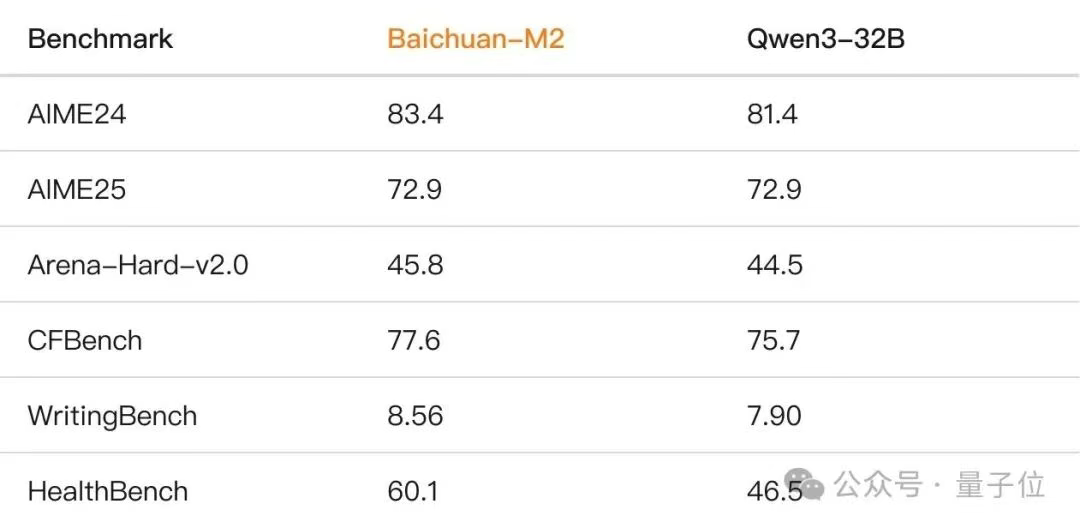
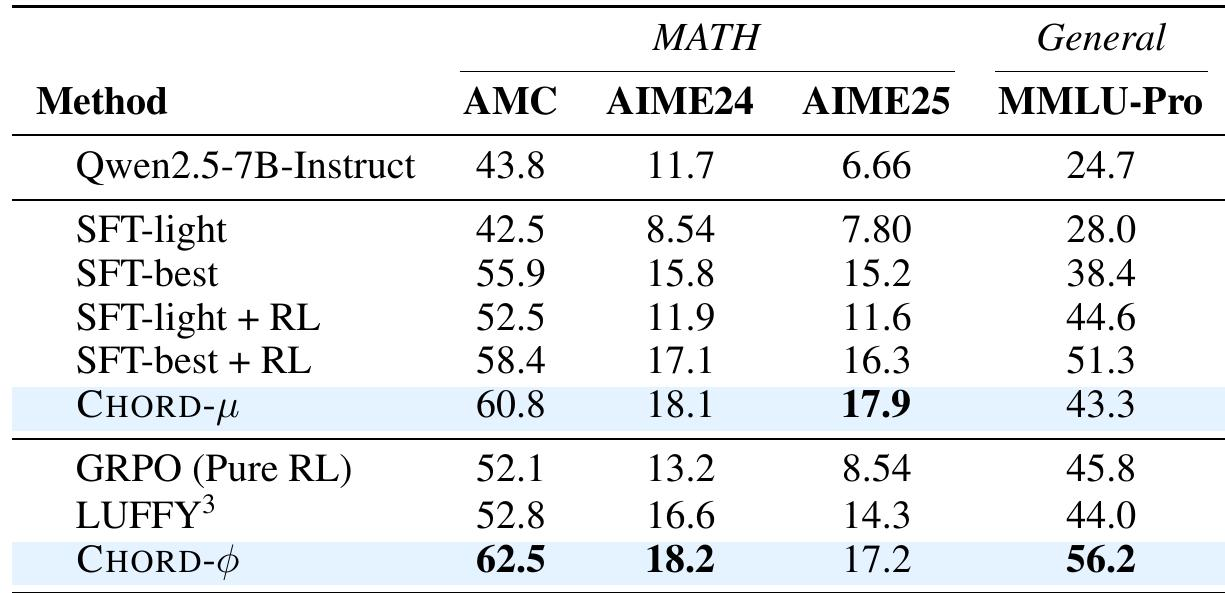
Baichuan-M2是百川开源发布的第二个医疗增强模型。这是一个推理模型,为真实世界的医疗推理任务设计。
参数量32B,但在各项基准中都超越了比自己大数倍的开源/闭源模型。
HealthBench是由OpenAI今年发布的一个医疗健康领域评估测试集,数据集中包含5000条多轮对话,模拟模型与个人用户或医疗专业人士之间的真实交流。这些对话跨越多语言、多背景(如急诊、临床数据解读、全球健康等)。
M2在数学、指令遵循、写作等通用能力不降反增,各种基准都超过了Qwen3-32B,这意味着它还可以被用于医疗以外的其他领域。
在具体训练策略上,Baichuan-M2引入中期训练(Mid-Training),没有直接进行后训练。这样是为了让模型在保持通用能力同时,轻量化提高医疗领域能力。
为此,团队构建了多源高质量医疗语料,包含精选的高权威性公共医学教材、临床专著、药品知识库以及最新发布的诊疗指南和真实病例。
数据合成阶段主要强化两个维度:
-
结构化表达:基于知识保真原则,对原始医学文本进行结构化改写,提升表达的逻辑性和流畅度,同时严格控制改写幻觉的引入。
-
深度推理增强:在知识密集段落和关键结论处,自适应插入深度思维笔记,包括知识关联分析、批判性反思、论证验证、案例推演等认知过程,让模型学会“像医生一样思考”。
为了兼顾通用和专业医疗能力,训练数据配比也很讲究——高质量医疗数据:其他通用数据:数学推理数据=2:2:1。
并且引入领域自约束训练机制,引入KL约束保持输出分布稳定,防止过拟合医疗数据。
备注:应该还是SFT,只是参考邱锡鹏老师团队发现SFT与DPO破壁统一:内隐奖励作为桥梁
这篇文章,增加了一些约束,我理解可以使用DFT替代。另外需要将知识复述作为一个任务微调。
然后在强化学习部分,百川采用多阶段强化学习策略(Multi-Stage RL),即分阶段培养模型的能力,比如先培养基础推理、再培养医疗&通用推理、最后培养医学多轮交互能力。
这样能让每一步的奖励信号更清晰,不被其他能力混淆;模型学到的能力也更稳定,更能应对不同数据类型。
在具体算法上,Baichuan-M2采用了改进版的GRPO算法,应该就是DAPO.
同时团队还基于基于Eagle-3训练了MTP版本,单用户场景下token吞吐可获得74.9%%的提升。
目前,百川已经和北京儿童医院、北京市海淀区卫健委等展开合作,实际落地儿科大模型、AI医生等。
2、GPT-OSS
从零开始写 llm 的百万粉丝作者来点评下 gpt-oss ,还详细地对比了qwen3,干货很多且客观,建议食用
3、人大&百度提出ReasonRank:让LLM学会在排序中“思考”
人大&百度提出ReasonRank:让LLM学会在排序中“思考”
这个思路与意图择优相似,先SFT后强化,响应时间需要1.8s。
4、推荐:先SFT后RL但是效果不佳?你可能没用好“离线专家数据”!
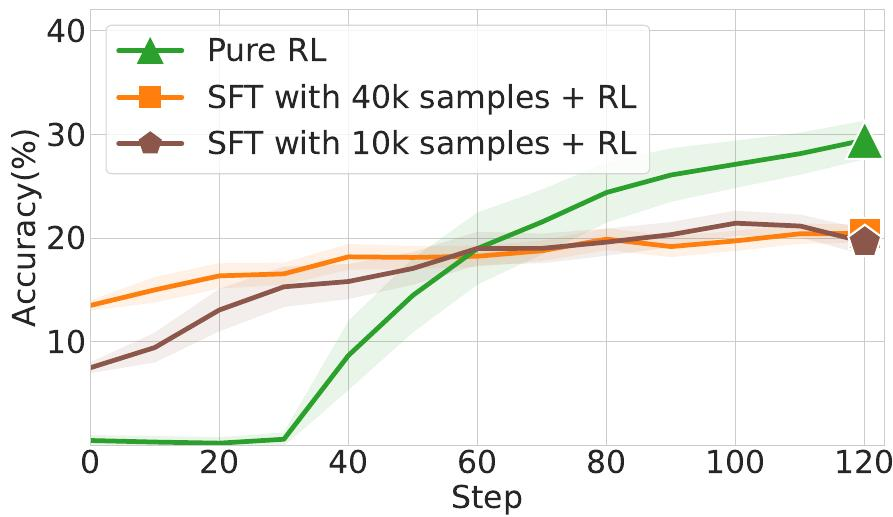
提到提升大模型能力,SFT(监督微调)再接 RL(强化学习)的范式是一套常见操作。但在各种场景实践后,你可能会发现事情并没有那么简单。
作为大模型从业者或者研究人员的你,大概率也遇到过以下困境之一:
-
越学越差: 手里的有些 SFT 业务数据,但微调后再接 RL,模型性能不升反降,甚至不如直接 RL。到底是 SFT “火候”过了,还是数据本身有问题?
-
原地踏步:费尽心力搭建了 RL 训练管线,却发现模型提升有限,效果还不如用同样的数据做蒸馏 SFT 来得直接。
-
顾此失彼:SFT 后,虽然目标任务性能提升了,但模型的通用能力却明显下降,不得不在两者之间艰难取舍。
如果这些场景让你感到熟悉,问题很可能出在你使用的“离线专家数据(Off-policy Expert Data)”上。针对这一挑战,通义实验室 Trinity-RFT 团队提出 CHORD 框架——通过动态融合 SFT 与 RL,让模型学会“取其精华”,实现从模仿到超越的跃迁。
✅ arXiv:https://arxiv.org/abs/2508.11408(或点击文末阅读原文)
✅ GitHub仓库:https://github.com/modelscope/Trinity-RFT/tree/main/examples/mix_chord
SFT 过轻或者过重都会对后续的 RL 表现有明显的影响。如果 SFT 训练不足就被中断进入 RL,模型就像刚刚被打乱解题思路的学生,带着被扰乱的策略去探索,自然效果不佳;而如果SFT做得过重,模型则会对专家范例死记硬背,思维僵化,丧失了 RL 阶段最需要的探索能力与灵活性,后续训练也就无法带来提升。如何平稳地吸收新知识,同时不丢失原有的灵活性,是一个巨大的难题。
对 SFT 的控制失衡是导致后续 RL 效果不佳的关键。我们认为如何解决这一问题的关键在于我们看待 SFT 和 RL 的方式。与其将它们视为两个独立的训练阶段,不如从一个更统一的视角出发:SFT 与 RL 的结合是 On-Policy 与 Off-Policy 训练的融合。
只有理解了这一点,我们才能跳出“先做 A 再做 B”的固定框架,让 SFT 的“专家指导”与 RL 的“自我探索”像和弦(CHORD)一样,和谐地融合在一起。🎶
为了实现 SFT 与 RL 的和谐相融,我们提出了 CHORD 框架。我们将 SFT 从一个独立的预处理阶段,转变为 RL 训练全程中一个动态加权的辅助目标。通过对 SFT Loss 进行持续、动态的加权与控制,模型得以在模仿专家与自我探索之间找到平衡。
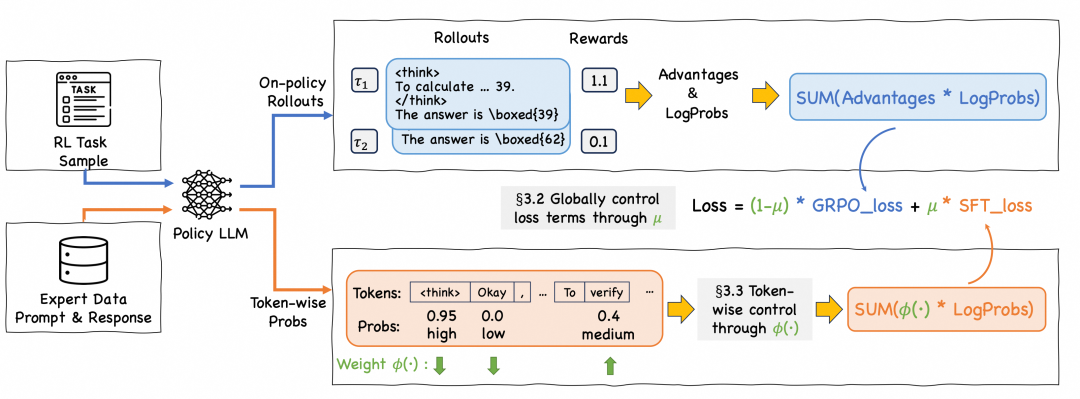
我们的混合损失函数,将在线策略的 RL 损失和离线策略的 SFT 损失结合起来。
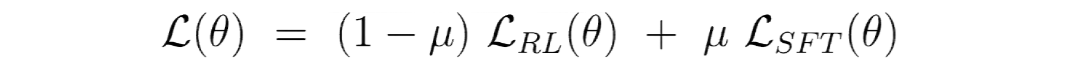
要控制 SFT 数据影响力,就可以直接运用这个全局平衡系数 µ。告别“硬切换”,拥抱“软过渡”。
而我们通过对 µ 的动态衰减策略,就实现了从模仿到探索的软过渡。
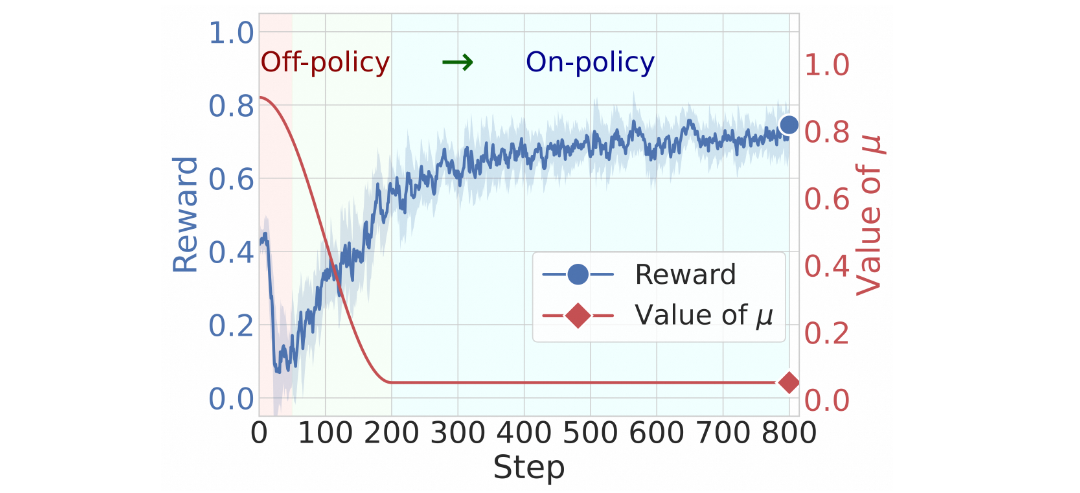
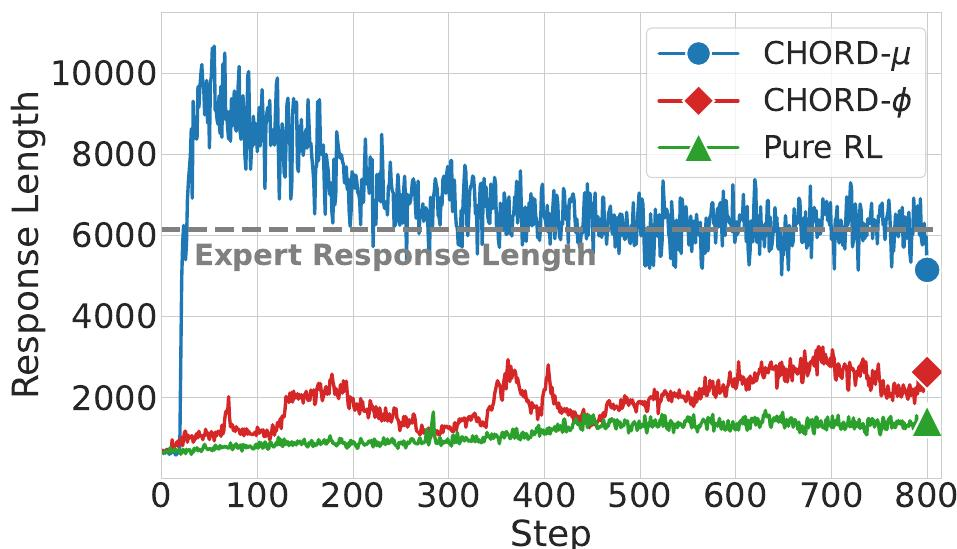
我们为模型设计了一条从模仿到探索软过渡的学习路径:首先,将 µ 设为较高值,让模型优先通过 SFT 吸收离线专家数据中的知识与推理模式;接着,随着模型对专家模式的逐渐适应,我们平滑地降低 µ 值,将学习重心从模仿 SFT 数据逐步转移到 RL 的探索优化上;最终,µ 衰减并稳定在一个低值,模型便能专注于 RL 的自我探索,同时有效避免对 SFT 数据的过拟合。
我们发现,即使有了平滑的 µ 衰减,模型最终还是会变成专家的“影子”——它的推理模式、回答风格都趋于被同化。这说明,它学会了模仿,却没学会超越。而我们的目标,不是训练一个只会模仿的“复读机”,而是让模型把专家的经验当成“引导”,而非“模板”。
要实现这一点,仅有宏观的全局调控是不够的,我们必须深入到每一个 Token 的细粒度层面。
为此,我们提出使用精巧的 Token 级权重函数 ϕ(·):
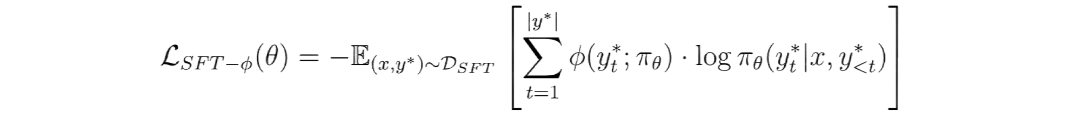
对 SFT 数据中每一个 Token 的“学习价值” 来进行评估。
-
这个 Token 与模型当前认知相悖?(Token 生成概率 p 趋近 0)
ϕ 会认为其学习价值低。这可以防止模型受到过于不同数据的冲击,避免了因“水土不服”而导致的策略剧烈波动。
-
这个 Token 模型已经很熟悉了?(Token生成概率p趋近1)
ϕ 会认为其学习价值低,从而大幅降低其在损失函数中的权重。这避免了在已知知识上死记硬背过拟合,也避免了模型 RL 训练过程的“熵坍塌”(模型对现有方式变得过分自信而失去探索能力)。 -
这个 Token 让模型感到“似懂非懂”?(Token生成概率处于中间值)
这正是学习的“甜点区”!ϕ 会赋予其较高的学习权重,引导模型集中精力攻克这些自身相对不确定,对模型来说最富信息量、最能带来提升的部分。
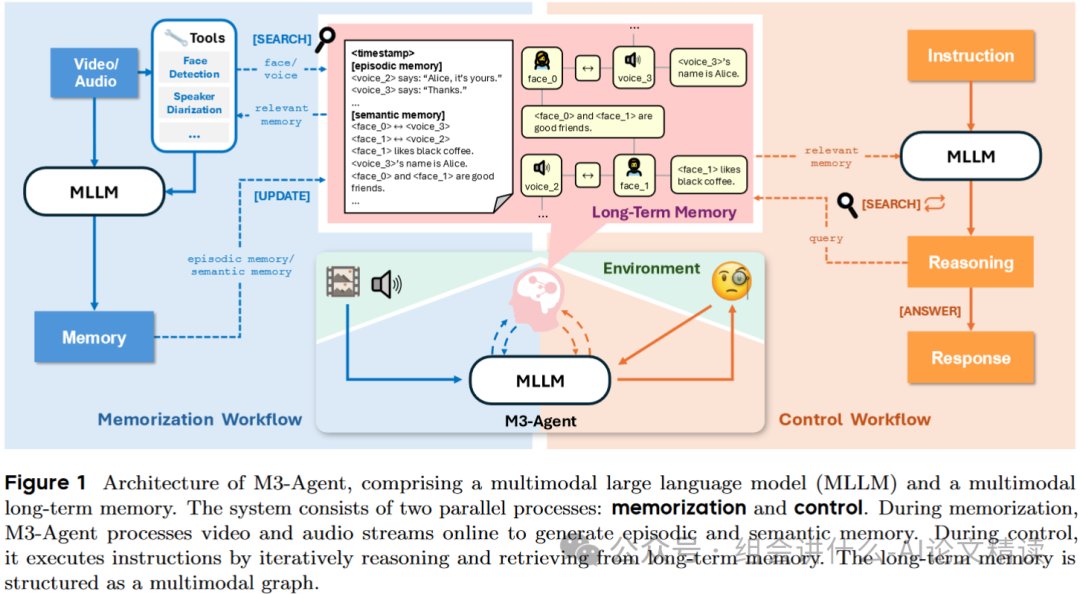
5、字节跳动发布M3-Agent:当AI拥有了“记忆”,世界将如何被重塑?
字节跳动发布M3-Agent:当AI拥有了“记忆”,世界将如何被重塑?
想象一下,你家里的机器人助手,每天清晨都能看到你。第一天,它看到你喝咖啡;第二天,它又看到你喝咖啡;第三天……当你问它“我早上喜欢喝什么?”时,它却一脸茫然。这就是当前大多数AI Agent的现状——它们拥有惊人的瞬时理解能力,却患有严重的“金鱼记忆症”。
它们的“世界”被一个名为“上下文窗口”(Context Window)的狭窄囚笼所限制。每一次交互都是一次“重启”,它们无法将今天的“爱丽丝”与昨天的“爱丽丝”联系起来,更无法从“每天都喝咖啡”这个重复的行为中,提炼出“爱丽丝喜欢喝咖啡”这一条宝贵的知识。这种无法积累经验、形成长期记忆的缺陷,是阻碍AI从一个“工具”进化为一个真正“伙伴”的根本瓶颈。
这引出了一个直指通用人工智能核心的终极拷问:我们能否创造一个AI,让它像人类一样,拥有一个持续不断、自动更新的长期记忆系统?让记忆不再是“塞进去”的数据库,而是从连续的生命体验中“生长出来”的知识森林? 这篇来自字节跳动Seed团队的石破天惊之作——M3-Agent,正是对这一宏伟蓝图的勇敢探索。
核心观点一览:
-
双系统认知架构:
M3-Agent首创“记忆”与“控制”并行系统,模拟人类认知,让AI能对流式视听信息进行7x24小时不间断的被动学习和主动推理。 -
人本主义记忆模型: 模仿人脑,不仅记录“发生了什么”的情景记忆,更能提炼“这意味着什么”的语义记忆,实现从原始经验到结构化知识的升华。
-
实体为心的知识图谱:
M3-Agent创新地以“实体”为核心构建多模态记忆图谱,将同一人物的面孔、声音与事实牢固绑定,从根本上解决了长期身份一致性的核心难题。 -
强化学习驱动的“思考链”: 摒弃传统单轮RAG,通过强化学习训练出能进行多轮“思考-搜索”的策略模型,让AI真正学会如何为解决复杂问题而“思考”。
总结如下:
1、需要以知识图谱,实体为中心进行存储。每一个知识需要高度总结提炼,未来还需要遗忘
2、基于强化学习训练出边检索边思考的能力。只有认为当前知识能回答问题了,才回答,否则输入需要搜索的内容。
3、记录器,对于每天的对话进行总结归纳。
6、字节Seed:Pass@k作为reward可以有效平衡探索与利用
当前最主流的 RLVR 设置,如 DeepSeek-R1,其优化目标是最大化 Pass@1。在训练中,这通常表现为:只要 个答案中至少有一个是正确的(即 ),就认为这是一次成功的 rollout,并以此为基础进行学习。
这种设置存在以下几个关键问题:
-
趋于保守,抑制探索:模型为了最大化获得正奖励的概率,会倾向于生成它最有把握的那个答案的变体。假设模型已经找到一个有 80% 把握的解法 A,同时它也知道一个可能通往更优解、但目前只有 30% 把握的解法 B。在 Pass@1 的驱动下,模型会不断地微调和重复解法 A,因为它能稳定地带来奖励。而尝试解法 B 风险太高,一旦失败,就会得到负奖励,从而抑制了这条探索路径。
-
陷入局部最优:上述的保守策略直接导致模型陷入局部最优。整个训练过程变成了对已知“最优解”的不断“利用”,而通往全局最优解的桥梁——“探索”——却被斩断了。从图 1 中可以看到,Vanilla RLVR 的 Pass@1 准确率在几百步训练后就进入了平台期,正是这一现象的体现。
-
对“有价值的失败”惩罚过重:在复杂的推理任务中,很多时候一个错误的答案可能包含了大量正确的推理步骤,只是在最后一步出错。例如,一道复杂的数学题,可能公式都列对了,只是最后计算错误。在 Pass@g1 训练中,这个答案和另一个完全胡乱猜测的答案一样,都会被赋予负奖励。这使得模型无法从这些“差一点就成功”的宝贵经验中学习,阻碍了其能力的提升。
正是意识到了 Pass@1 训练的这些内在局限,论文作者们开始思考,能否有一种奖励机制,能够从根本上鼓励模型生成更多样化、更具探索性的答案?答案就是 Pass@k。
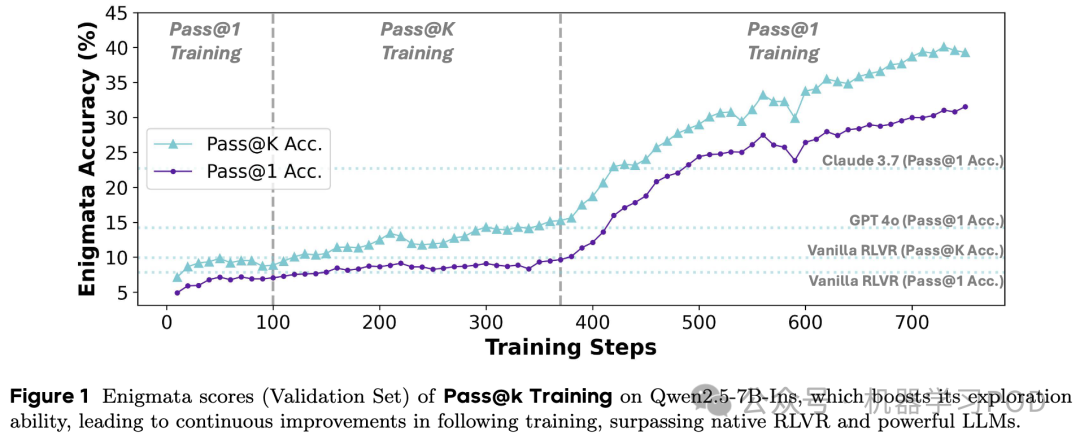
Pass@k 训练
Pass@k 的核心理念是:在 次尝试内,只要有一次成功,就算成功。将这个理念转化为 RLVR 的奖励函数,就意味着我们不再评估单个答案,而是评估一组答案。
核心思想
与 Pass@1 训练不同,Pass@k 训练的奖励对象是一个包含 个答案的组(group)。 对于一个组 ,其奖励被定义为:
也就是说,只要这个组里至少有一个答案是正确的,整个组就会被赋予正奖励 。然后,这个组的奖励(或更准确地说,是优势值)会平等地分配给组内的所有 个成员。
这种机制带来了深刻的改变:
-
容忍错误:即使一个答案本身是错误的,但只要它和一个正确的答案被分在同一组,它也能分享到正向的激励。这极大地降低了模型进行探索的“试错成本”。
-
鼓励多样性:为了最大化组奖励,一个“聪明”的模型会意识到,生成 个高度相似的答案是不划算的。更好的策略是生成 个覆盖不同解题思路的、多样化的答案,这样“瞎猫碰上死耗子”的概率才会最大。这就从机制上激励了模型的探索行为。
接下来,我们来看看作者是如何将这个简单的思想,一步步优化成一个高效、稳定的训练算法的。
7、其他进展
《Qwen-Image:MMDiT图像基础模型》:阿里通义团队发布的开源图像基础模型Qwen-Image,参数量20B,在复杂文本渲染和精确图像编辑领域实现了重大突破,对中文文本的处理尤为出色。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)