基于AI视觉的具身智能机械臂实验室搭建方案
搭建基于AI视觉的具身智能机械臂实验室,需整合机械臂硬件、视觉感知系统、AI算法平台及实验环境,实现自主抓取、物体识别、动态避障等任务。核心模块包括机械臂控制、多模态传感器融合、实时视觉处理与强化学习框架。
🏡博客主页: virobotics(仪酷智能):LabVIEW深度学习、人工智能博主
🎄所属专栏:『LabVIEW深度学习实战』
📑推荐文章:『LabVIEW人工智能深度学习指南』
🍻本文由virobotics(仪酷智能)原创🥳欢迎大家关注✌点赞👍收藏⭐留言📝订阅专栏
文章目录
🧩实践目标
Hello,大家好,这里是virobotics(仪酷智能),一个深耕于LabVIEW和人工智能领域的开发工程师。今天我们一起来看一下具身智能机械臂AI视觉实验室方案,通过机械臂+AI视觉+小组制教学模式,实现:
- 人工智能通识认知:跨专业机器人认知教育
- 专项模块训练:聚焦三大核心领域:
- 人工智能基础
- 机器视觉
- 机械臂控制
- 场景化应用:结合千余种图像处理算子,自由组合模块模拟生活/商业/工业场景
🧭核心能力培养
- 新技术学习与创新能力
- 主流AI框架应用能力
- AI系统部署运维能力
- 技术集成与场景应用能力
- 数据处理与模型训练能力
- AI产品推广与技术培训能力
🎈核心设备配置
1. 六轴具身智能机械臂套件
是一款面向AI教育场景的具身智能机械臂,由示教臂和操作臂组成。通过先进的遥操作协同算法,将示教器的动作精确映射到操作臂,是机械臂控制、模仿学习和端到端大模型(VLA)研究的理想入门平台。操作臂采用标准6自由度设计,全长为900mm,臂展可达750mm,可选配高清摄像头。配备自主研发的串口总线舵机与航空级零部件,确保稳定可靠的运行性能,第一第二第三关节均采用双舵机驱动,强力型末端负载可达1000g。示教臂采用类似尺寸设计,配备专用扳机,支持精准的动作采集与遥操作。系统集成专业的玄雅SparkMind 具身算法平台,实现视觉、控制与机械的无缝融合。用户可以轻松实现坐标控制、运动规划、碰撞检测等功能。结合Sparkling在线学习平台,我们提供机械臂仿真、正逆运动学原理、视觉算法、模仿学习等系统化课程内容。作为一款专业的AI教育平台,灵动系列在软硬件设计上注重易用性与实用性,并且完全开源,支持二次开发。配备详细的中文教程和技术支持,为AI和具身智能学习者提供一个理想的实践平台。
技术参数:
| 特性 | 参数 |
|---|---|
| 自由度 | 6DOF |
| 臂展 | 750mm |
| 末端负载 | 1000g |
| 重复定位精度 | 1.0mm |
| 控制方式 | 位置控制 |
| 编程支持 | ROS1/ROS2/Python |
| 材质 | 铝型材、高强度PLA、树脂和ABS等材料 |
| 电压 | 12V |
| 连续工作时间 | 4h |
| 微处理器 | STM32 |
| 电机类型 | 串口总线舵机(UART/串口通讯协议) |
核心优势:
- 双臂协同:示教臂+操作臂实时动作映射
- 开源生态:全面开放ROS控制代码和接口
- 高精度运动:曲线平滑算法实现无震荡启停
- 视觉扩展:支持高清/广角/传感器摄像头接入
- 教育支持:SparkMind平台提供正逆运动学/视觉算法/模仿学习课程
2. 深度摄像头
可为各种应用提供高质量的深度。它的宽视野非常适合机器人或增强现实和虚拟现实等应用,在这些应用中,尽可能多地看到场景至关重要。这款小型摄像头的射程可达 10 米,可轻松集成到任何解决方案中,并配备我们的英特尔实感 SDK 2.0 和跨平台支持。
技术参数:
| 特性 | 参数 |
|---|---|
| 长度 × 深度 × 高度 | 90 毫米 × 25 毫米 × 25 毫米 |
| 理想范围 | 0.3 m 至 3 m |
| 深度技术 | 立体 |
| 深度视场 (FOV) | 87° × 58° |
| 最小深度距离 (Min-Z),最大分辨率 | ~28 cm |
| 深度输出分辨率 | 高达 1280 × 720 |
| 深度精度 | 2 m 处 <2%¹ |
| 深度帧速率 | 高达 90 fps |
| 图像传感器技术 | Global Shutter |
| RGB 帧分辨率 | 1920 × 1080 |
| RGB 传感器 FOV (H × V) | 69° × 42° |
| RGB 帧率 | 30 fps |
| RGB 传感器分辨率 | 2 MP |
| RGB 传感器技术 | 卷帘快门 |
| 摄像头模块 | Intel RealSense 模块 D430 + RGB 摄像头 |
| 视觉处理器板 | Intel RealSense Vision Processor D4 |
| 连接器 | USB-C* 3.1 Gen 1* |
应用场景:
- 机器人环境感知
- 增强/虚拟现实
- 三维场景重建
⚒️AI软件生态
1. AI Vision Toolkit for GPU
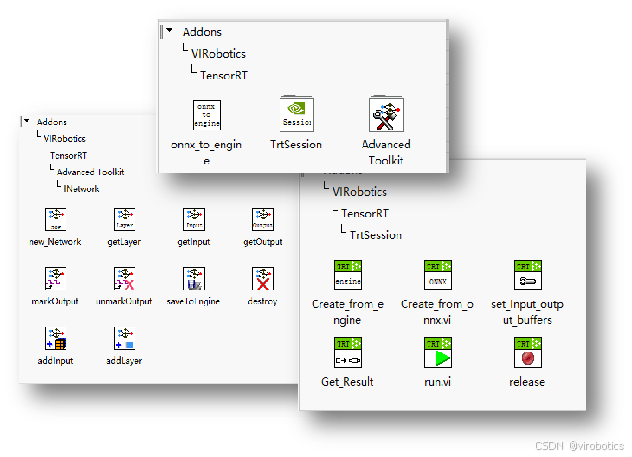
可接入相机,做各种图像处理,可将模型转化为tensorRT模型,优化模型并实现毫秒级推理。可最大限度利用GPU资源。可实现分类、分割、检测、OCR、序列等AI模型。
- 轻松配置各种USB以及网络相机,高速采集图像,完成多种传统图像处理;
- 直接的模型转换:可将Onnx模型(部分)转换至FP32、FP16或Int8的tensorRT模型(.trt或.engine);
- 极速推理接口:加载tensorRT模型,并进行极速推理(速度为Onnx-tensorRT的2~5倍);
- 自定义图层网络:面向资深玩家,可使用INetworkDefinition高级工具实现自己创建网络、查看或编辑已有的Onnx网络;
- 多个系统完整实战模型范例:
- 传统图像处理范例:包括颜色空间转换、DFT变换、多种图像滤波器;二值化、图像阈值处理、直线检测、圆检测、轮廓检测和处理、角点检测、相机标定、手眼标定、SIFT特征点匹配、模板匹配、边缘轮廓检测等
- yolov5\v6\v7\v8\v9\v10\v11\v12、yolox、ppyoloe等系列yolo模型;
- yolov5\v7\v8\v11\v12-pose人体关键点姿态检测模型范例;
- yolov5\v8\v11\v12-seg实例分割模型范例;
- yolov8\v11\v12-obb旋转目标检测模型范例;
- yolov8\v11\v12-cls分类模型范例;
- torchvision中的图像分类、目标检测模型范例;
- deeplabv3和deeplabv3+语义分割模型范例;
2. AI一键训练工具包
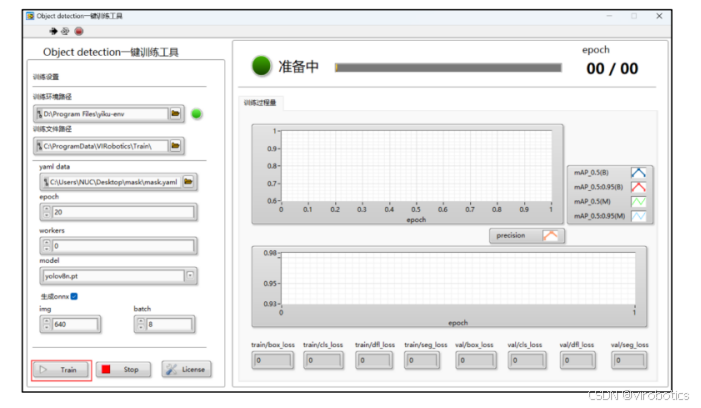
- 一体化:标注训练一体化,可高效训练;
- 环境免安装:用户不需要再手动配置环境,也不需要担心环境不兼容问题,该工具包
已经包含免安装环境,可直接使用; - 高效节时:标签文件自动生成,点击开始即可开始训练;
- 操作简单:即使一个从来没有做过训练的人都可以使用,无需学习太多深度学习知识,
可以让用户有更多时间专注于业务本身。 - 拿来即用:生成的模型可直接在推理加速工具包中进行部署。
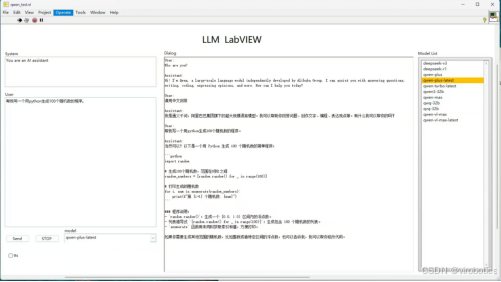
3. LLM Toolkit for LabVIEW
LabVIEW大语言模型工具包。可使用LabVIEW调用OpenAI接口的大语言模型LLM和VLM。包括但不局限于:
- Deepseek/Deepseek VL
- Qwen 3.0/Qwen 2.5/QwQ/QvQ/Qwen VL
- chatgpt
- Stable diffusion
- Ollama中LLm和VLM模型
- 语音识别、语音合成
支持流式输出、历史记录保存、Agent调用、多模态模型调用。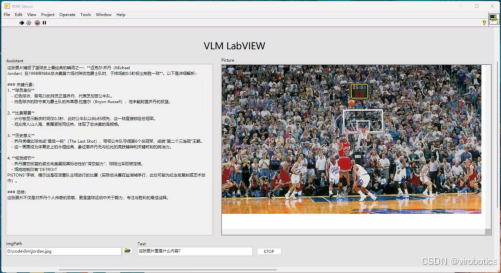
🪜具身智能解决方案
1.项目简介
OpenVLA(Open Vision-Language-Action)是由斯坦福大学、加州大学伯克利分校、Google DeepMind 和丰田研究院等机构联合开发的开源视觉-语言-动作(VLA)模型。该模型拥有 70 亿参数,预训练数据来自 Open X-Embodiment 数据集中的 97 万个机器人操作轨迹,旨在为通用机器人操作策略设定新的技术前沿。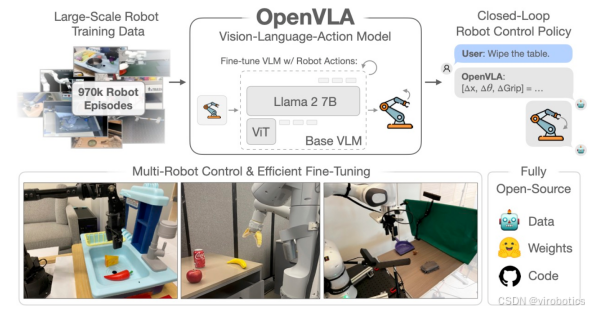
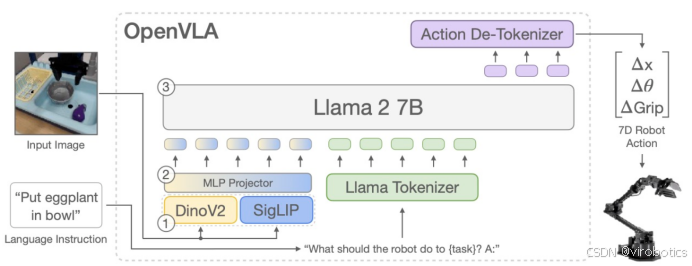
2.模型架构
- 视觉编码器:融合了 DINOv2 和 SigLIP 的特征,用于将图像输入映射为图像补丁嵌入。
- 投影器:将视觉编码器的输出嵌入映射到大型语言模型的输入空间。
- 语言模型主干:基于 Llama 2 的 70 亿参数语言模型,用于预测标记化的输出动作,这些动作随后被解码为可直接在机器人上执行的连续动作。
3.训练数据与设施
- 数据集:使用 Open X-Embodiment 数据集,涵盖了广泛的任务、场景和机器人形态。
- 训练设施:在一个由 64 个 A100 GPU 组成的集群上训练了 15 天,总计使用了 21,500 个 A100 小时。
4.性能评估
OpenVLA 在多个机器人平台上进行了"开箱即用"的控制评估,包括 Bridge V2 的 WidowX 设置和 RT 系列论文中的 Google Robot。结果显示,OpenVLA 在 29 个任务和多种机器人形态上,其绝对任务成功率比封闭模型 RT-2-X(55B)高出 16.5%,同时参数数量减少了 7 倍。
5.适应性与微调
OpenVLA 支持通过参数高效的微调快速适应新的机器人配置。例如,在 Franka-Tabletop 和 Franka-DROID 两个领域中,OpenVLA 展示了其在新任务和机器人设置中的快速适应能力。
6.开源资源
- 项目主页:https://openvla.github.io/
- 代码库:https://github.com/openvla/openvla
- 模型下载:https://huggingface.co/openvla/openvla-7bHugging Face
🎯总结
以上就是今天要给大家分享的内容,希望对大家有用。如有笔误,还请各位及时指正,欢迎大家关注博主。我是virobotics(仪酷智能),我们下篇文章见~
如您想要探讨更多关于LabVIEW与人工智能技术,欢迎加入我们的技术交流群:974600160。进群请备注:CSDN
更多内容可查看:
- 仪酷智能官网:https://www.virobotics.net/
- 微信公众号:仪酷智能科技
- B站:仪酷智能
- 邮箱:info@virobotics.net
如果文章对你有帮助,欢迎✌关注、👍点赞、✌收藏、👍订阅专栏
推荐阅读
【YOLOv5】LabVIEW+TensorRT的yolov5部署实战(含源码))
【YOLOv5】手把手教你使用LabVIEW ONNX Runtime部署 TensorRT加速,实现YOLOv5实时物体识别(含源码)
【YOLOv8】实战一:手把手教你使用YOLOv8实现实时目标检测
【YOLOv8】实战二:YOLOv8 OpenVINO2022版 windows部署实战
【YOLOv8】实战三:基于LabVIEW TensorRT部署YOLOv8
【YOLOv9】实战一:在 Windows 上使用LabVIEW OpenVINO工具包部署YOLOv9实现实时目标检测(含源码)
【YOLOv9】实战二:手把手教你使用TensorRT实现YOLOv9实时目标检测(含源码)
👇技术交流 · 一起学习 · 咨询分享,请联系👇

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)