Nature正刊 | 图像生成不依赖数字算力!浙大校友将光引入AI模型,用光子计算革新AIGC
本研究提出光学生成模型,结合浅层数字编码器(将高斯噪声映射为相位种子)与全光衍射解码器,受扩散模型启发实现目标分布图像生成,图像合成阶段(除照明与种子生成外)无算力消耗。实验验证其在MNIST、Fashion-MNIST等多数据集及梵高风格艺术品的单色/彩色生成性能,与数字模型相当;通过快照/迭代模式、参数分析及能耗对比,证实其高能效与可扩展性优势,为生成式AI提供非数字依赖新路径。

陈世锜博士在学术与技术研究中持续深耕光学领域:其博士阶段于浙江大学期间,便与团队合作研发多项计算光学成果,并成功应用于国产手机设备,实现了光学技术在消费电子领域的落地;当前其以博士后身份在美国加州大学洛杉矶分校开展研究时,进一步结合自身积累的光学技术基础,提出一种受扩散模型启发的光学生成模型。相关研究成果以“Optical generative models”为题,于当地时间8月27日发表于《Nature》期刊。
1. 【导读】

论文标题:Optical generative models
作者:Shiqi Chen1,2,3, Yuhang Li1,2,3, Yuntian Wang1,2,3, Hanlong Chen1,2,3 & Aydogan Ozcan1,2,3
作者机构:加州大学洛杉矶分校
论文来源:Nature | Vol 644 | 28 August 2025 | 903
论文链接:https://doi.org/10.1038/s41586-025-09446-5
资源链接:训练和测试代码可通过Zenodo获取,链接为https://zenodo.org/records/15446687;相关补充材料链接为https://doi.org/10.1038/s41586-025-09446-5(含方法、补充参考资料、源数据等)
2. 【论文速读】
陈世锜博士、Aydogan Ozcan等研究者提出光学生成模型,该模型受扩散模型启发,通过浅层快速数字编码器将随机噪声映射为相位图案(即光学生成种子),再经联合训练的自由空间可重构解码器以全光学方式处理这些种子,生成符合目标数据分布的全新图像。除照明功率和编码器生成随机种子外,图像合成过程不消耗计算资源。实验中,该模型成功光学生成手写数字、时尚产品、蝴蝶、人脸及梵高风格艺术品的单色与彩色图像,分别匹配MNIST、Fashion-MNIST、Butterflies-100、Celeb-A及梵高画作数据集分布,整体性能可与基于数字神经网络的生成模型媲美。研究通过可见光实验验证手写数字与时尚产品图像生成,并利用单色及多波长照明生成梵高风格艺术品,为高能效、可扩展的推理任务及AI生成内容领域的光学与光子学应用奠定基础。
3.【背景及相关工作】
3.1 研究背景
- 生成模型应用广泛但数字模型存在瓶颈
生成模型已覆盖图像/视频合成、自然语言处理、分子设计等多领域,然而数字生成模型规模持续扩大,导致其在快速、高能效的可扩展推理上面临挑战,需消耗大量算力、内存且推理时间长,同时模型的碳足迹问题也日益凸显。 - 现有优化方案不足,需新路径突破
尽管已有研究尝试通过模型压缩、加速等方式降低数字生成模型的规模与功耗,但仍难以平衡性能、效率与扩展性,亟需开发替代技术架构以实现高能效、可扩展的生成式AI模型。
3.2 相关工作
- 数字生成模型技术基础
- 主流数字生成模型如生成对抗网络(GAN)、变分自编码器(VAE)、去噪扩散概率模型(DDPM)等,已能生成高质量合成内容(如逼真图像、类人文本),其中DDPM因生成质量高,被本研究用作“教师模型”指导光学生成模型训练。
- 大语言模型(LLM)、嵌入式智能等生成式AI技术虽推动多领域应用,但均依赖庞大数字算力,难以突破能效与速度瓶颈。
- 光学计算与光子学在AI中的前期探索
- 已有研究聚焦光学网络在计算成像、噪声过滤、数据分类等任务的应用,如衍射深度神经网络(D2NN)、集成光子芯片加速卷积计算等,验证了光学系统在快速信息处理上的潜力。
- 部分工作尝试光学扩散模型用于图像生成,但尚未实现“从随机噪声直接光学生成符合目标分布的全新图像”,且缺乏对多波长、迭代式生成等场景的系统探索。
- 光学生成模型的技术创新基础
- 前期光学模型多依赖自由空间传播或简单调制,本研究创新性结合浅层数字编码器(将噪声映射为相位种子)与可重构衍射解码器(全光学处理种子生成图像),突破传统光学模型“非生成性”局限,同时借鉴扩散模型的噪声调度机制,实现与数字模型可比的生成性能。
4.【研究方法论】
4.1 Snapshot image generation(快照光学生成)
4.1.1 核心架构与流程
- 双模块协同工作
快照光学生成模型包含浅层数字编码器与自由空间可重构衍射解码器:- 数字编码器:将随机二维高斯噪声(输入服从 N ( 0 , I ) N(0,I) N(0,I)分布)映射为二维相位图案,即“光学生成种子”,编码器含3个全连接层,前两层后接非线性激活函数(LeakyReLU,斜率0.2)。
- 衍射解码器:与编码器联合训练,优化后保持静态,通过光的自由空间传播全光学处理生成种子,最终在图像传感器上输出符合目标数据分布的图像。
- 关键物理过程建模
- 相位图案构建:将数字编码器输出的二维实信号 H ( L d ) H^{(L_d)} H(Ld)归一化到 [ 0 , 2 π ] [0,2\pi] [0,2π]范围,公式为 ϕ ( x , y ) = ( α π ( H ( L d ) + 1 ) ) / 2 \phi(x,y)=\left(\alpha \pi\left(\mathcal{H}^{\left(L_d\right)}+1\right)\right)/2 ϕ(x,y)=(απ(H(Ld)+1))/2,其中 α \alpha α为控制相位动态范围的系数(默认设为2.0)。
- 光场传播:采用角谱法建模光在自由空间的传播,公式为 O ( x , y ) = P f d ( U ( x , y ) ) = F − 1 { F { U ( x , y ) } M ( f x , f y ; d ; n ) } \mathcal{O}(x,y)=\mathcal{P}_{f}^{d}(\mathcal{U}(x,y))=\mathcal{F}^{-1}\{\mathcal{F}\{\mathcal{U}(x,y)\} \mathcal{M}\left(f_x,f_y;d;n\right)\} O(x,y)=Pfd(U(x,y))=F−1{F{U(x,y)}M(fx,fy;d;n)},其中 M ( f x , f y ; d ; n ) \mathcal{M}(f_x,f_y;d;n) M(fx,fy;d;n)为自由空间传递函数,满足:
M ( f x , f y ; d ; n ) = { 0 , f x 2 + f y 2 > n 2 λ 2 exp { j k d 1 − ( 2 π f x n k ) 2 − ( 2 π f y n k ) 2 } , f x 2 + f y 2 ≤ n 2 λ 2 \mathcal{M}\left(f_x,f_y;d;n\right)= \begin{cases}0, & f_x^2+f_y^2>\frac{n^2}{\lambda^2} \\ \exp\left\{jk d\sqrt{1-\left(\frac{2\pi f_x}{nk}\right)^2-\left(\frac{2\pi f_y}{nk}\right)^2}\right\}, & f_x^2+f_y^2\leq\frac{n^2}{\lambda^2}\end{cases} M(fx,fy;d;n)=⎩ ⎨ ⎧0,exp{jkd1−(nk2πfx)2−(nk2πfy)2},fx2+fy2>λ2n2fx2+fy2≤λ2n2
( j = − 1 j=\sqrt{-1} j=−1, λ \lambda λ为照明波长, k = 2 π / λ k=2\pi/\lambda k=2π/λ为波数, n n n为介质折射率)。 - 解码层调制:解码层作为纯相位调制器,对入射光场的调制公式为 σ ( x , y ) = P m ϕ ( l 0 ) ( U ( x , y ) ) = U ( x , y ) ⋅ exp ( j ϕ ( l 0 ) ( x , y ) ) \sigma(x,y)=\mathcal{P}_{m}^{\phi^{(l_0)}}(\mathcal{U}(x,y))=\mathcal{U}(x,y)\cdot\exp\left(j\phi^{(l_0)}(x,y)\right) σ(x,y)=Pmϕ(l0)(U(x,y))=U(x,y)⋅exp(jϕ(l0)(x,y)),其中 ϕ ( l 0 ) ( x , y ) \phi^{(l_0)}(x,y) ϕ(l0)(x,y)为第 l 0 l_0 l0层解码层的相位调制值。
4.1.2 训练策略
- 教师模型预训练
先训练基于去噪扩散概率模型(DDPM)的“教师数字生成模型”以学习目标数据分布,训练中总时间步 T = 1000 T=1000 T=1000,噪声调度系数 β t \beta_t βt为线性函数(从 1 × 10 − 4 1\times10^{-4} 1×10−4( t = 1 t=1 t=1)到 0.02 0.02 0.02( t = T t=T t=T))。 - 光学生成模型联合训练
以教师模型生成的“噪声-图像”数据对为指导,优化目标函数为 L ( θ ) = min θ { M S E ( O t e a c h e r , S O m o d e l ) + γ K L ( p t e a c h e r ∥ p m o d e l θ ) } \mathcal{L}(\theta)=\min_{\theta}\left\{MSE\left(\mathcal{O}_{teacher},S\mathcal{O}_{model}\right)+\gamma KL\left(p_{teacher}\parallel p_{model}^{\theta}\right)\right\} L(θ)=minθ{MSE(Oteacher,SOmodel)+γKL(pteacher∥pmodelθ)},其中 M S E MSE MSE为均方误差, K L KL KL为KL散度, S S S为数字编码器预测的缩放因子, γ \gamma γ为经验系数(设为 1 × 10 − 4 1\times10^{-4} 1×10−4)。
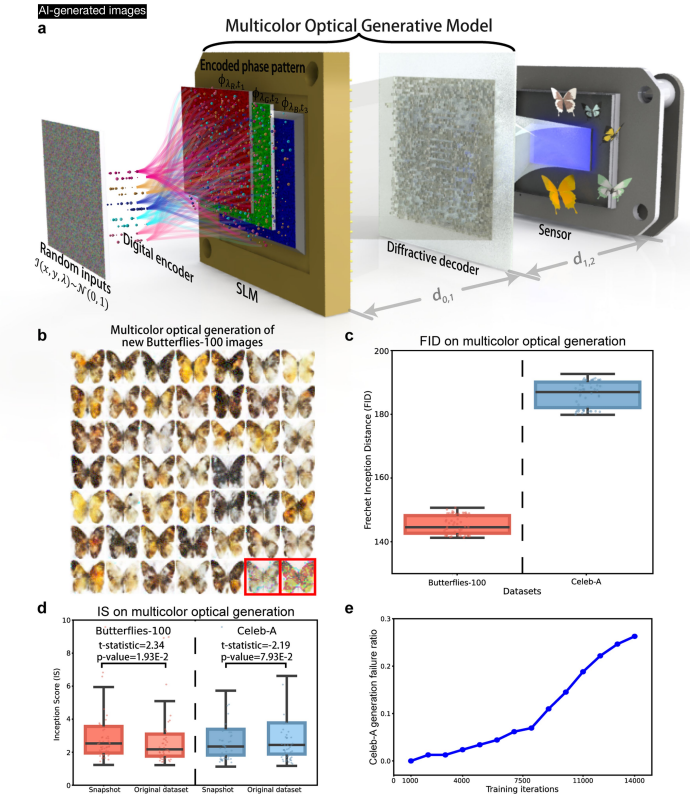
4.1.3 多波长扩展(彩色生成)
针对RGB三通道(波长 λ R , λ G , λ B \lambda_R,\lambda_G,\lambda_B λR,λG,λB),数字编码器为每个波长生成对应的相位种子并依次加载到空间光调制器(SLM),衍射解码器对所有波长共享同一优化状态,最终通过数字融合得到彩色图像,解码层相位调制随波长的调整公式为 ϕ ( l 0 ) ( x , y , λ ) = λ c e n t r e ( n λ − 1 ) λ ( n λ c e n t r e − 1 ) ϕ ( l 0 ) ( x , y , λ c e n t r e ) \phi^{(l_0)}(x,y,\lambda)=\frac{\lambda_{centre}\left(n_{\lambda}-1\right)}{\lambda\left(n_{\lambda_{centre}}-1\right)}\phi^{(l_0)}\left(x,y,\lambda_{centre}\right) ϕ(l0)(x,y,λ)=λ(nλcentre−1)λcentre(nλ−1)ϕ(l0)(x,y,λcentre),其中 λ c e n t r e \lambda_{centre} λcentre为中心波长, n λ n_{\lambda} nλ为解码器材料随波长变化的折射率。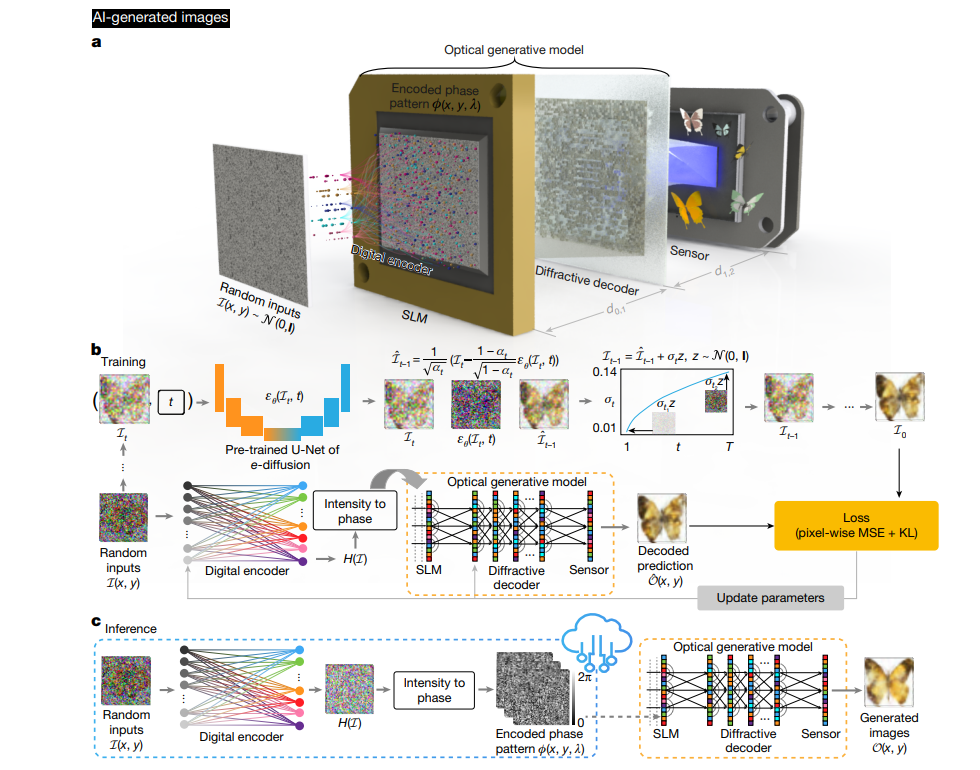
4.2 Iterative optical generative models(迭代光学生成模型)
4.2.1 核心原理与流程
- 迭代式噪声还原机制
借鉴DDPM的马尔可夫噪声过程,从初始高斯噪声( I T ∼ N ( 0 , I ) I_T\sim N(0,I) IT∼N(0,I))出发,通过 T T T个时间步迭代还原目标数据分布:- 每个时间步 t t t:将上一步传感器记录的强度图像 I ˉ t \bar{I}_t Iˉt添加设计方差的高斯噪声,作为当前步输入 I t − 1 I_{t-1} It−1;
- 输入经浅层数字编码器(含时间步信息嵌入)和衍射解码器(设5层解码层,层间距20mm)处理,直接预测去噪样本,最终在 t = 0 t=0 t=0输出目标图像。
- 关键公式与损失函数
- 噪声分布建模:时间步 t t t的噪声样本 I t I_t It服从 I t ∼ N ( α ‾ t I 0 , 1 − α ‾ t I ) \mathcal{I}_t\sim\mathcal{N}\left(\sqrt{\overline{\alpha}_t}\mathcal{I}_0,\sqrt{1-\overline{\alpha}_t}I\right) It∼N(αtI0,1−αtI),其中 α ‾ t \overline{\alpha}_t αt为扩散过程的累积噪声系数;
- 均值估计: q ( I t − 1 ∣ I t , I 0 ) q(I_{t-1}|I_t,I_0) q(It−1∣It,I0)的均值 m t − 1 , t m_{t-1,t} mt−1,t服从 m t − 1 , t ∼ N ( I t α t , 1 − α t α t ( 1 − α ‾ t ) I ) m_{t-1,t}\sim\mathcal{N}\left(\frac{\mathcal{I}_t}{\sqrt{\alpha_t}},\frac{1-\alpha_t}{\sqrt{\alpha_t\left(1-\overline{\alpha}_t\right)}}I\right) mt−1,t∼N(αtIt,αt(1−αt)1−αtI);
- 损失函数: L ( θ ) = min θ m o d e l E t ∼ [ 1 , T ] , I 0 ∼ p d a t a ( T ) [ ∥ S N R t I 0 − O θ m o d e l ( I t , t ) ∥ 2 ] \mathcal{L}(\theta)=\min_{\theta_{model}}E_{t\sim[1,T],I_0\sim p_{data}(\mathcal{T})}\left[\left\|SNR_t\mathcal{I}_0-\mathcal{O}_{\theta_{model}}\left(\mathcal{I}_t,t\right)\right\|^2\right] L(θ)=minθmodelEt∼[1,T],I0∼pdata(T)[∥SNRtI0−Oθmodel(It,t)∥2],其中 S N R t = α ‾ t / α t SNR_t=\sqrt{\overline{\alpha}_t}/\sqrt{\alpha_t} SNRt=αt/αt为分布转换系数, O θ m o d e l ( I t , t ) \mathcal{O}_{\theta_{model}}(I_t,t) Oθmodel(It,t)为模型输出特征。
4.2.2 推理过程
推理阶段从 t = T t=T t=T的高斯噪声开始,每个时间步按公式 I t − 1 = ( O m o d e l ( I t , t ) − 0.5 ) × 2 + σ t z \mathcal{I}_{t-1}=\left(\mathcal{O}_{model}\left(\mathcal{I}_t,t\right)-0.5\right)\times2+\sigma_t z It−1=(Omodel(It,t)−0.5)×2+σtz更新输入( z ∼ N ( 0 , I ) z\sim N(0,I) z∼N(0,I), t > 1 t>1 t>1时 z = 0 z=0 z=0; σ t 2 = ( 1 − α ‾ t − 1 ) β t / ( 1 − α ‾ t ) \sigma_t^2=(1-\overline{\alpha}_{t-1})\beta_t/(1-\overline{\alpha}_t) σt2=(1−αt−1)βt/(1−αt)),迭代 T T T次后在传感器平面得到最终生成图像。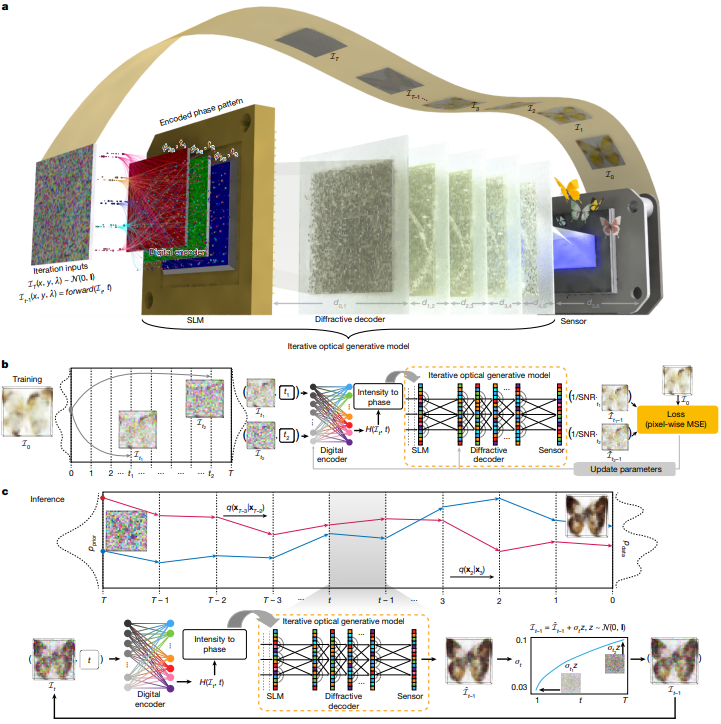
4.3 实验验证方法
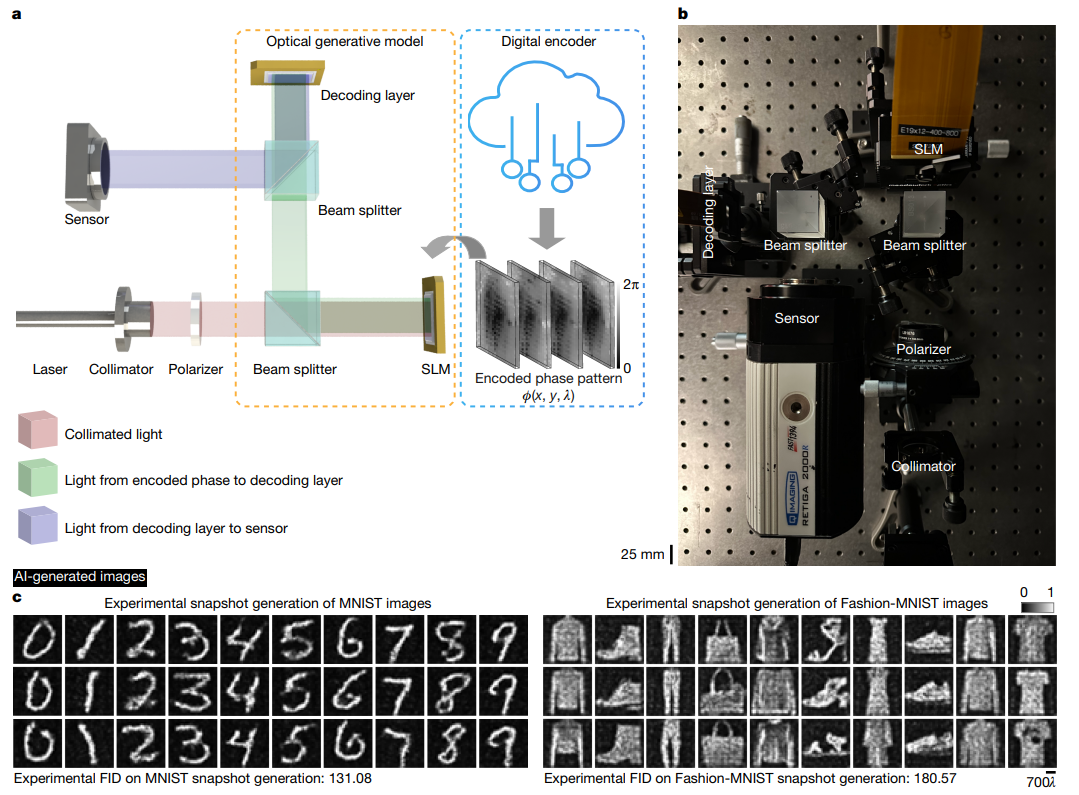
4.3.1 硬件搭建
-
核心设备
- 光源:可见光激光器(单色生成用520nm,彩色生成用450nm、520nm、638nm);
- 调制器:两个SLM(Meadowlark XY Phase Series,像素间距8μm;HOLOEYE PLUTO-2.1,像素间距8μm),分别用于加载生成种子和衍射解码相位;
- 传感器:QImaging Retiga-2000R相机(像素间距7.4μm,分辨率1600×1200)。
-
光路参数
SLM到衍射解码器距离 d 0 , 1 = 120.1 d_{0,1}=120.1 d0,1=120.1mm,解码器到传感器距离 d 1 , 2 = 96.4 d_{1,2}=96.4 d1,2=96.4mm,生成种子、解码层、传感器的分辨率分别为320×320、400×400、320×320(低分辨率任务)或1000×1000、1000×1000、640×640(高分辨率梵高风格生成)。
4.3.2 性能评估指标
-
定量指标
- inception得分(IS):衡量生成图像多样性,生成与原始数据集同等数量图像计算,结合 t t t检验( P < 0.05 P<0.05 P<0.05为差异显著);
- Fréchet inception距离(FID):衡量生成图像与原始数据分布的一致性,批量大小200,重复计算100次;
- CLIP得分:评估文本-图像对齐度(针对梵高风格生成,参考文本为“Van Gogh style painting of {architecture, plants, person}”)。
-
分类器验证
训练3组二分类器(基于卷积神经网络):分别用100%标准MNIST数据、50%标准+50%光学生成数据、100%光学生成数据训练,在标准MNIST测试集上评估准确率,验证光学生成图像的有效性。
5.【实验结果】
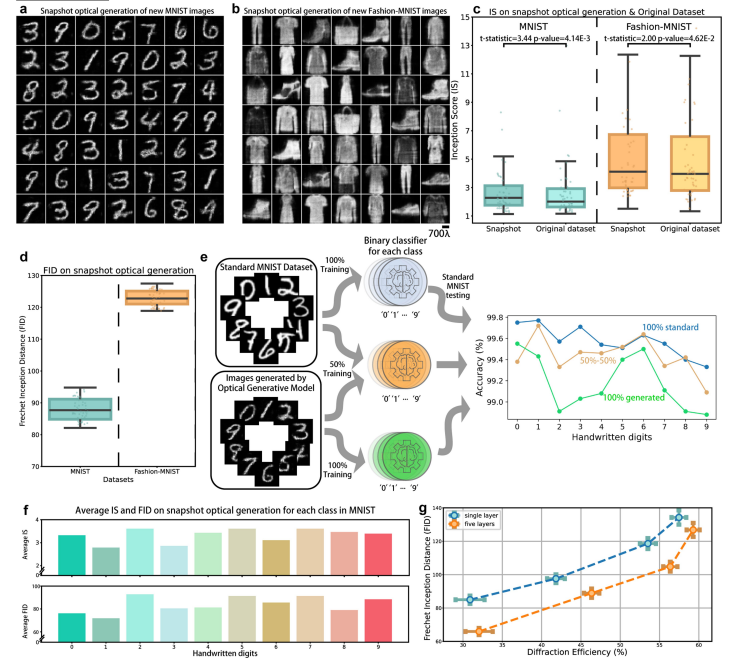
5.1 快照光学生成:手写数字与时尚产品图像验证
- 实验设置
基于可见光(520nm激光)搭建自由空间系统,用两个SLM分别加载“光学生成种子”(经浅层数字编码器处理的相位图案)与静态衍射解码器,传感器捕获输出图像,光路参数为 d 0 , 1 = 120.1 d_{0,1}=120.1 d0,1=120.1mm、 d 1 , 2 = 96.4 d_{1,2}=96.4 d1,2=96.4mm。 - 生成性能
- 针对MNIST(手写数字)和Fashion-MNIST(时尚产品)数据集,成功生成符合目标分布的全新图像,实验FID分别为131.08(MNIST)和180.57(Fashion-MNIST);
- 训练3组二分类器验证:用100%光学生成数据训练的分类器在标准MNIST测试集上准确率达99.18%,仅比100%标准数据训练的模型低0.4%,证明生成图像保留目标数据核心特征。
5.2 快照光学生成:高分辨率梵高风格艺术品
-
单色生成
采用520nm激光照明,数字编码器含580M可训练参数,生成1000×1000分辨率的单色梵高风格图像,实验结果与含1.07B参数、1000步推理的数字DDPM“教师模型”输出高度一致,同时能生成教师模型未涵盖的多样化作品(如独特建筑、植物风格)。
-
多色生成
依次用450nm(蓝)、520nm(绿)、638nm(红)激光照明,同一衍射解码器共享优化状态,生成图像经数字融合得到RGB彩色作品;虽存在轻微色差,但整体分辨率(640×640)与语义一致性(CLIP得分28.25,接近教师模型的28.72)表现优异。
-
解码方式对比
衍射解码器相较于自由空间解码优势显著:自由空间解码在部分场景完全失效(CLIP得分<10-15),而衍射解码器可稳定生成高质量图像,即使增大SLM-解码器距离导致数值孔径相关的分辨率轻微下降,仍保持生成稳定性。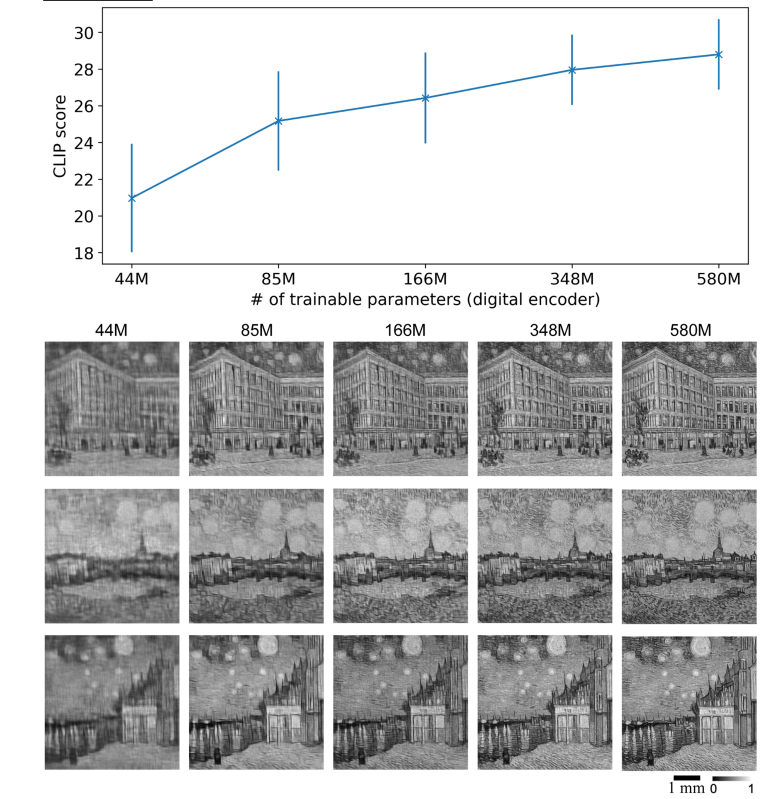

5.3 光学生成模型关键参数影响实验
- 相位编码范围与解码器位深
- 相位编码范围为 [ 0 , 2 π ] [0,2\pi] [0,2π]时生成质量最优,若缩小至 [ 0 , π / 2 ] [0,\pi/2] [0,π/2],FID显著升高;
- 解码器位深降低(如4位 vs 8位)会导致生成图像细节丢失,将位深限制纳入训练可提升模型适配性,即使仅3个离散相位水平(0、 2 π / 3 2\pi/3 2π/3、 4 π / 3 4\pi/3 4π/3),仍能成功生成目标图像。
- 衍射效率与解码器层数
- 单解码层模型的衍射效率平均可达41.8%(FID轻微上升);5层解码层模型在相同衍射效率下FID更低(如效率50%时FID≈100),证明深层解码器可平衡能效与生成质量。
- 潜空间插值验证
对两个随机噪声输入进行线性插值( J γ = γ J 1 + ( 1 − γ ) J 2 \mathcal{J}^\gamma=\gamma\mathcal{J}^1+(1-\gamma)\mathcal{J}^2 Jγ=γJ1+(1−γ)J2, γ ∈ [ 0 , 1 ] \gamma\in[0,1] γ∈[0,1]),生成图像呈现平滑过渡(如从手写数字“5”逐步变为“3”),且全程保持 digit-like 特征,表明模型学习到连续、规整的潜空间表示。
5.4 迭代光学生成模型实验补充
- 多色图像生成性能
针对Butterflies-100和Celeb-A数据集,5层解码层的迭代模型生成图像背景更清晰、细节更丰富,FID较快照多色生成降低15%-20%,且训练全程无模式崩溃(mode collapse),因迭代过程将分布映射拆分为独立高斯过程。 - 无数字编码器适配性
移除数字编码器后,仅通过SLM实现强度-相位转换与传感器光电转换,仍能生成多色人脸图像,但FID升高约30%、IS降低12%,证明数字编码器可提升生成性能与多样性,但模型核心光学机制不依赖编码器。
6.【总结展望】
6.1 总结
本研究提出光学生成模型,结合浅层数字编码器(将高斯噪声映射为相位种子)与全光衍射解码器,受扩散模型启发实现目标分布图像生成,图像合成阶段(除照明与种子生成外)无算力消耗。实验验证其在MNIST、Fashion-MNIST等多数据集及梵高风格艺术品的单色/彩色生成性能,与数字模型相当;通过快照/迭代模式、参数分析及能耗对比,证实其高能效与可扩展性优势,为生成式AI提供非数字依赖新路径。
6.2 展望
未来可从三方面推进:一是硬件优化,用被动静态衍射解码器(如双光子聚合制作)替代SLM,降低成本能耗;二是功能扩展,开发空间/光谱复用并行生成、三维图像生成,适配AR/VR场景;三是落地应用,研发轻量化系统用于边缘计算、隐私通信;同时解决光学对齐误差等问题,推动光学技术在AI生成内容领域的实用化。
关注下方《AI前沿速递》🚀🚀🚀
各种重磅干货,第一时间送达
码字不易,欢迎大家点赞评论收藏

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 23
23 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)