CPU高负载案例
调整垃圾回收器参数:例如调整新生代与老年代的比例(-XX:NewRatio),调整Survivor区比例(-XX:SurvivorRatio)。现象:线程状态可能显示为 BLOCKED 或 WAITING(等待锁),CPU高是因为线程在用户态和内核态间频繁切换,试图获取锁。分析GC日志:使用工具(如GCeasy、GCE Viewer)分析,判断是Young GC过于频繁还是Full GC。此时需要
1. 核心排查思路与流程
当发现应用CPU利用率异常飙升(例如从30-40%升至56%或更高),应遵循以下流程进行系统性排查。整个过程的核心是:从宏观到微观,从进程到线程,从代码到根源。
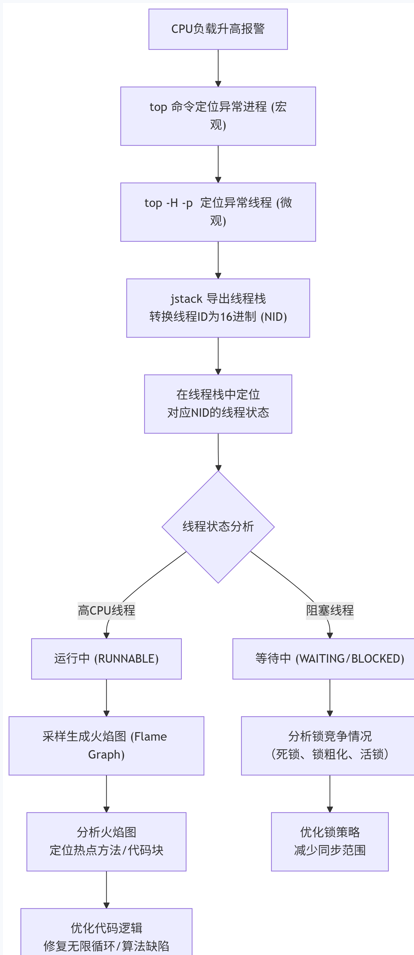
1.1 定位异常进程与线程
首先确定是哪个进程及其中的哪些线程导致了CPU过高。
- 查找资源消耗最高的进程 (宏观定位)
top查看 %CPU 和 TIME+ 列,找到持续占用CPU最高的进程,记录其 PID (例如 1)。
- 查找该进程下的资源消耗线程 (微观定位)
top -H -p <PID>
# 示例: top -H -p 1查看哪些线程(TID)占用CPU最高,记录下这些线程的 PID (这里是线程ID,称为TID)。
1.2 分析线程栈(定位问题代码)
获取高CPU线程的TID后,接下来需要查看它在执行什么代码。
- 导出Java进程的线程快照
jstack -l <PID> >> ./jstack_dump.txt
# 示例: jstack -l 1 >> ./jstack_dump.txt将把进程的所有线程状态和调用栈输出到文件。
- 转换高CPU线程的TID为十六进制
Linux中的 jstack 输出文件里,线程ID是以十六进制(HEX)表示的,称为 NID。
printf "%x\n" <TID>
# 示例:printf "%x\n" 12564 -> 3114 (注意转换后字母要小写)- 在线程快照中查找对应线程
在 jstack_dump.txt 文件中,搜索转换后的十六进制NID(如 0x3114 或 3114)。找到对应的线程,查看其调用栈(stack trace)。
- 通常,CPU高的线程会处于
RUNNABLE状态,并且会在执行某个方法或代码循环。
1.3 生成火焰图(可视化热点)
- 使用 Arthas Profiler 生成火焰图
火焰图可以非常直观地显示CPU时间花费在哪些调用链上。
-
- 连接到目标Java进程(使用
arthas-boot.jar或as.sh)
- 连接到目标Java进程(使用
# 在Arthas交互台中执行
profiler start --duration 30 --event itimer
# --duration 采样时长(秒)
# --event 采样事件,itimer或cpu(不同平台可能不同),通常用cpu即可-
- 等待采样结束后,停止并生成SVG格式的火焰图
profiler stop --format svg- 下载生成的SVG文件,用浏览器打开分析。
- 火焰图看顶层的“平顶山”,那里就是最热点的代码,是优化的重点。
- 常见原因与解决方案
根据线程栈和火焰图的分析结果,常见原因及应对策略如下:
原因一:代码中存在低效或死循环
现象:线程栈显示某个线程一直处于 RUNNABLE 状态,且停留在某个循环或方法。
解决方案:
优化算法:检查循环内的逻辑,是否存在不必要的计算或可优化的数据结构。
添加中断条件:确保循环有正确的退出条件,避免死循环。
异步化处理:如果是在处理大量数据,考虑是否可以将任务拆分或异步化,避免长时间占用CPU。
原因二:激烈的锁竞争(如 synchronized 或 ReentrantLock)
现象:线程状态可能显示为 BLOCKED 或 WAITING(等待锁),CPU高是因为线程在用户态和内核态间频繁切换,试图获取锁。
"thread-1" #prio=5 tid=0x0 nid=0x1a waiting for monitor entry [0x0]
java.lang.Thread.State: BLOCKED (on object monitor)解决方案:
减少锁粒度:缩小同步代码块的范围。
使用并发容器:如 ConcurrentHashMap 代替 Collections.synchronizedMap。
改用读写锁(ReadWriteLock):如果读多写少。
使用无锁编程(如 CAS 操作):Atomic 系列类。
原因三:频繁的GC(垃圾回收)
现象:top 看进程的 %CPU 高,但 jstack 可能找不到明显热点线程。此时需要结合GC日志判断。
排查命令:
# 查看GC情况(需提前开启GC日志或使用jstat实时查看)
jstat -gcutil <PID> 1000
# 每隔1秒输出一次GC数据,观察Eden、Old区利用率及GC次数和时间查看GC情况(需提前开启GC日志或使用jstat实时查看)
jstat -gcutil 1000
每隔1秒输出一次GC数据,观察Eden、Old区利用率及GC次数和时间
解决方案:
分析GC日志:使用工具(如GCeasy、GCE Viewer)分析,判断是Young GC过于频繁还是Full GC。
调整堆大小:-Xms, -Xmx。
调整垃圾回收器参数:例如调整新生代与老年代的比例(-XX:NewRatio),调整Survivor区比例(-XX:SurvivorRatio)。
更换GC器:如从JDK8的Parallel GC换成G1或ZGC。
- 关联知识:OOM(OutOfMemoryError)排查
CPU问题有时与内存问题相伴而生,尤其是频繁的Full GC会疯狂消耗CPU资源。
排查命令:Dump堆内存快照
jmap -dump:live,format=b,file=./heap_dump.hprof 注意:jmap 可能会触发Full GC,在生产环境使用需谨慎
分析工具:使用 Eclipse MAT 或 JProfiler 分析生成的 heap_dump.hprof 文件。
查找 Dominator Tree:找到占用内存最大的对象。
查找 Leak Suspects Report:查看工具自动分析出的内存泄漏疑点。
常见OOM原因:
内存泄漏:对象被意外引用无法被GC,如静态集合、未关闭的连接、监听器未注销等。
内存配置过小:-Xmx 设置太小,无法满足业务需求。
一次性加载过多数据:如从数据库一次性取出百万条数据到内存。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)