NPU:人工智能时代的算力引擎
神经网络处理器(NPU)凭借专用架构优势,正在AI计算领域实现突破性发展。其采用存算一体、数据流驱动等创新设计,如华为昇腾910的达芬奇核心可实现3-5倍于GPU的计算密度。NPU在能效比、实时性方面表现突出,联发科APU690将人脸识别功耗降低82%,特斯拉FSD芯片支持毫秒级自动驾驶决策。相比GPU的通用计算架构,NPU通过MIMD、多精度适配等技术,在AI任务中展现出更高效率,如BERT训练
目录
在人工智能技术爆发式增长的今天,计算效率已成为制约技术落地的关键瓶颈。传统CPU在处理图像识别、自然语言处理等AI任务时,往往因架构限制难以满足实时性需求;GPU虽通过并行计算大幅提升了性能,却仍存在能耗过高、专用性不足等问题。在此背景下,神经网络处理器(NPU)作为专为AI设计的计算架构,正以独特的优势重塑计算产业的格局。
一、NPU的核心架构与工作原理
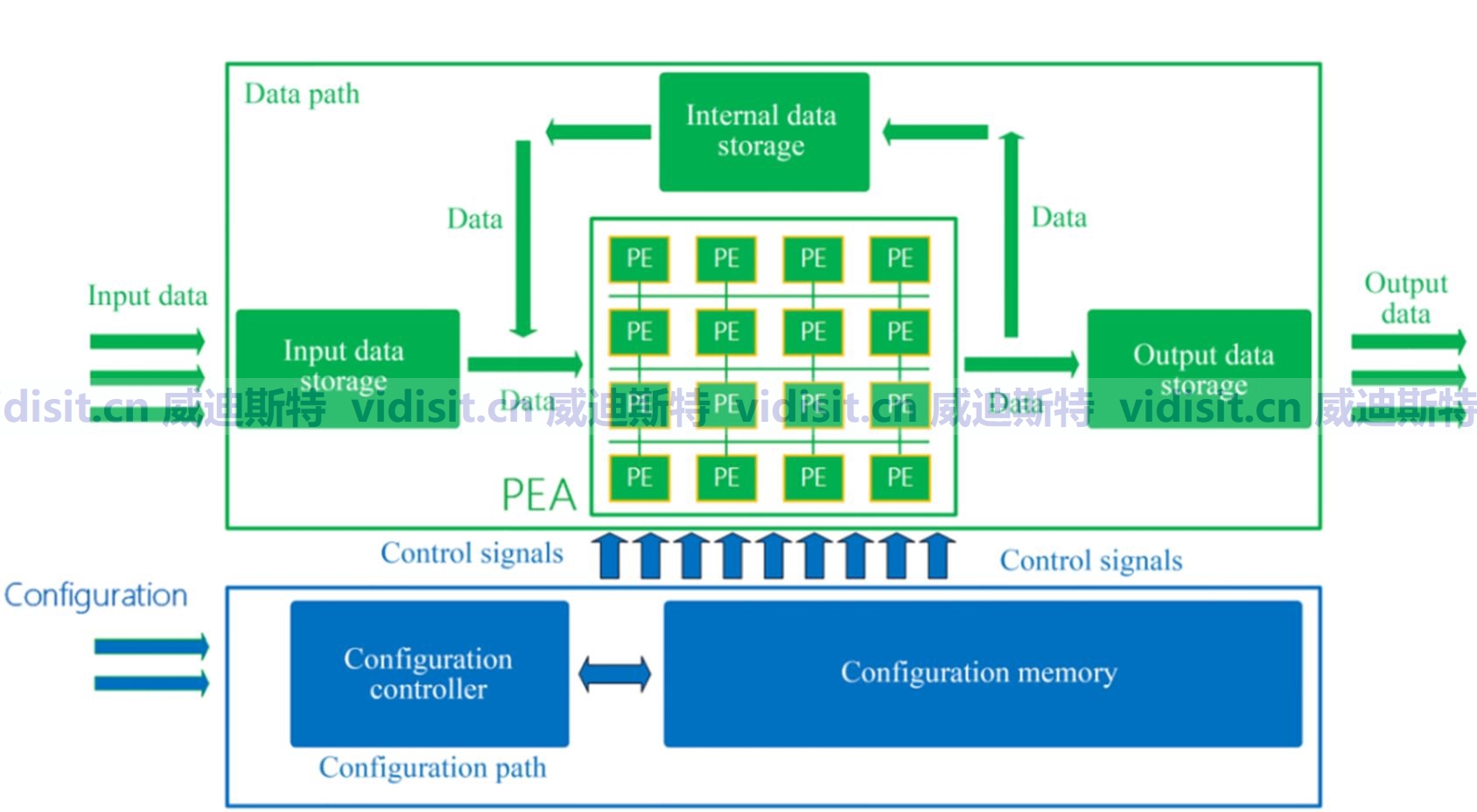
NPU的设计哲学源于对人类神经系统的模拟,其核心是通过硬件级优化实现矩阵运算的极致加速。与传统处理器采用冯·诺依曼架构不同,NPU采用数据流驱动的计算模式,将存储单元与计算单元深度融合,构建出三维堆叠的存储计算一体化结构。例如,寒武纪思元系列NPU通过“存算一体”技术,将数据搬运能耗降低至传统架构的1/10,同时通过脉动阵列架构实现每秒万亿次级别的MAC(乘加运算)操作。
在计算单元层面,NPU集成了大量专用的神经网络加速核。以华为昇腾910为例,其内置的32个达芬奇架构核心可同时处理不同精度的张量运算,支持FP16、INT8等多数据类型动态切换。这种设计使得NPU在处理卷积神经网络(CNN)时,能将计算密度提升至每平方毫米10TOPs(万亿次运算/秒),较GPU提升3-5倍。
数据流优化是NPU的另一大特色。通过编译器层面的图优化技术,NPU可将AI模型自动拆解为适合硬件执行的指令序列。以百度昆仑芯为例,其自主研发的XPU架构通过“算子融合”技术,将12个独立算子合并为1个复合指令,使ResNet-50模型的推理延迟降低至0.7毫秒,满足自动驾驶等实时场景需求。
二、NPU的技术优势与应用场景
NPU的能效比优势在端侧设备中尤为突出。联发科天玑9200芯片集成的APU 690,在执行人脸识别任务时,功耗较CPU方案降低82%,而性能提升达35倍。这种特性使得智能手机、智能摄像头等设备得以在本地完成复杂AI计算,避免数据上传云端带来的隐私风险和延迟问题。
在数据中心场景,NPU正推动AI算力进入ZFLOPS(十万亿亿次)时代。阿里平头哥含光800芯片通过3D堆叠技术集成1228亿个晶体管,在ResNet-50基准测试中达到78568 IPS/W的能效比,相当于GPU的30倍。这种高效算力支撑起淘宝“拍立淘”等亿级用户规模的实时图像搜索服务。
自动驾驶领域对NPU的实时性要求达到毫秒级。特斯拉FSD芯片内置的NPU核心可在45纳秒内完成一次决策循环,其双冗余设计确保即使单个核心故障,系统仍能保持99.999%的可用性。这种可靠性使得L4级自动驾驶成为可能,目前已在特斯拉Model S/X等车型上实现城市道路自主导航。
三、NPU与GPU的架构差异与性能对比
NPU与GPU的竞争本质是专用计算与通用计算的路线之争。从架构层面看,GPU采用SIMT(单指令多线程)架构,通过数千个流处理器并行执行相同指令,这种设计在处理图形渲染等规则计算时效率极高。但面对AI任务中大量不规则的稀疏矩阵运算,GPU需要频繁调度不同线程,导致30%-50%的计算资源被浪费在数据搬运和同步上。
NPU则采用MIMD(多指令多数据)架构,每个计算核心可独立执行不同指令流。以英伟达A100 GPU与华为昇腾910的对比为例,在执行BERT-base模型训练时,A100需要128个SM单元协同工作,而昇腾910的32个达芬奇核心可并行处理不同层的计算任务,使得数据复用率提升4倍,最终在相同功耗下实现1.8倍的性能优势。
在存储子系统方面,GPU的GDDR6显存带宽虽高达1.5TB/s,但其冯·诺依曼架构导致计算单元需频繁访问显存,形成典型的“存储墙”瓶颈。NPU通过片上SRAM缓存将常用权重参数本地化存储,寒武纪MLU370-X8芯片的288MB缓存可容纳整个ResNet-50模型的参数,使得内存访问次数减少90%,能效比因此提升3倍。
在精度适配能力上,GPU主要支持FP32/FP16等高精度计算,而NPU通过可配置数据通路技术,可动态切换从INT1到FP64的多种精度模式。这种灵活性使得NPU在处理语音识别等对噪声敏感的任务时,可采用INT4量化将模型体积压缩75%,而准确率损失不足1%,这是GPU难以实现的。
四、结语
NPU的崛起标志着计算架构进入“专用化”新纪元。其通过模拟生物神经网络的存储计算一体化设计,在能效比、实时性、精度适配等关键指标上实现对传统架构的超越。尽管GPU在通用计算领域仍具优势,但面对AI算力需求每年增长10倍的指数级趋势,NPU的专用化路线正成为破解“算力危机”的核心方案。随着3D封装、光子计算等技术的融合,未来的NPU将突破物理极限,为自动驾驶、智慧医疗等颠覆性应用提供更强有力的算力支撑。在这场计算革命中,NPU与GPU的竞合关系,终将推动整个半导体产业向更高效、更智能的方向演进。
文章正下方可以看到我的联系方式:鼠标“点击” 下面的 “威迪斯特-就是video system 微信名片”字样,就会出现我的二维码,欢迎沟通探讨。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)