「LangChain 学习笔记」LangChain大模型应用开发:基于文档的问答
本文介绍了如何利用大语言模型构建基于文档的问答系统。通过整合外部文档数据,系统可以生成更专业和个性化的回答。文章详细说明了实现步骤:1) 初始化语言模型;2) 使用CSVLoader加载文档数据;3) 选择HuggingFaceEmbeddings进行文本向量化;4) 创建内存向量存储并执行相似性搜索;5) 构造提示词获取回答;6) 使用RetrievalQA链实现端到端问答。该方法有效解决了大语
「LangChain大模型应用开发」 系列文章目录:
目录
使用大语言模型构建一个能够回答关于给定文档和文档集合的问答系统是一种非常实用和有效的应用场景。与仅依赖模型预训练知识不同,这种方法可以进一步整合用户自有数据,实现更加个性化和专业的问答服务。
例如,我们可以收集某公司的内部文档、产品说明书等文字资料,导入问答系统中。然后用户针对这些文档提出问题时,系统可以先在文档中检索相关信息,再提供给语言模型生成答案。
这样,语言模型不仅利用了自己的通用知识,还可以充分运用外部输入文档的专业信息来回答用户问题,显著提升答案的质量和适用性。构建这类基于外部文档的问答系统,可以让语言模型更好地服务于具体场景,而不是停留在通用层面。这种灵活应用语言模型的方法值得在实际使用中推广。
基于文档问答的这个过程,我们会涉及 LangChain 中的其他组件,比如:嵌入模型(Embedding Models)和向量储存(Vector Stores),本章让我们一起来学习这部分的内容。
为什么要学习这两个组件?
由于语言模型的上下文长度限制,直接处理长文档具有困难。为实现对长文档的问答,我们可以引入向量嵌入(Embeddings)和向量存储(Vector Store)等技术:
首先,使用文本嵌入(Embeddings)算法对文档进行向量化,使语义相似的文本片段具有接近的向量表示。其次,将向量化的文档切分为小块,存入向量数据库,这个流程正是创建索引(index)的过程。向量数据库对各文档片段进行索引,支持快速检索。这样,当用户提出问题时,可以先将问题转换为向量,在数据库中快速找到语义最相关的文档片段。然后将这些文档片段与问题一起传递给语言模型,生成回答。
通过嵌入向量化和索引技术,我们实现了对长文档的切片检索和问答。这种流程克服了语言模型的上下文限制,可以构建处理大规模文档的问答系统。
1. 初始化模型
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
api_key="你的API keu", # 我这里使用千帆
base_url="https://qianfan.baidubce.com/v2",
model="ernie-3.5-8k",
temperature=0
)2. 导入数据
首先,需要准备文档数据。在这个例子中,我们使用一个产品目录的 CSV 文件作为数据源,该文件包含了多个产品的描述和信息。通过 LangChain 的 CSVLoader 模块,我们可以方便地加载文档并将其转换为可查询的格式。
在实际应用中,文档通常存储在 CSV、JSON 或其他格式中。在这里,我们使用 CSV 文件格式。以下代码展示了如何使用文档加载器(Document loaders)加载 CSV 文件,更多其他文档加载器请参考:文档加载器 | 🦜️🔗 LangChain --- Document loaders | 🦜️🔗 LangChain。
from langchain.document_loaders import CSVLoader
file = 'data/OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file, encoding='utf-8')
docs = loader.load()
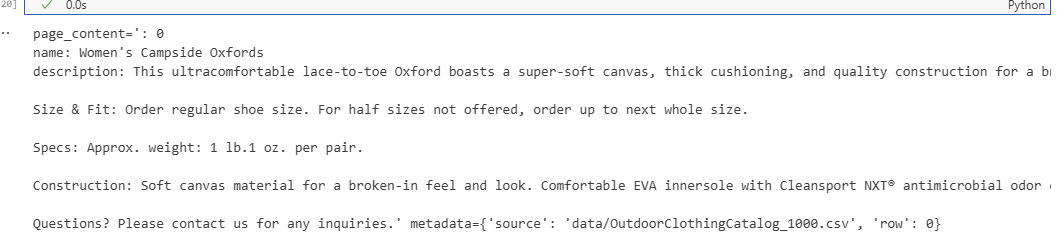
print(docs[0])
结果如下图所示,可以看到成功获取到了第一条数据。
3. 文本向量嵌入模型
这里选取合适的嵌入模型和向量存储类型(参考官方文档:Vector stores | 🦜️🔗 LangChain)。这里选择HuggingFaceEmbeddings,因为有的是商业 API,一些是开源的,请参考文档:(【LangChain】LangChain 中支持的嵌入(embedding)模型_langchain embedding-CSDN博客)。
from langchain_huggingface import HuggingFaceEmbeddings
#因为文档比较短了,所以这里不需要进行任何分块,可以直接进行向量表征,后面遇到长文档回来补充
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")4. 基于向量嵌入模型创建并查询向量存储
这里使用DocArrayInMemorySearch(使用教程参考:DocArray InMemorySearch | 🦜️🔗 LangChain --- DocArray InMemorySearch | 🦜️🔗 LangChain)。DocArrayInMemorySearch 是 Docarray 提供的一种文档索引,将文档存储在内存中。对于小型数据集,这是一个很好的起点,因为你可能不想启动一个数据库服务器。
from langchain.vectorstores import DocArrayInMemorySearch
db = DocArrayInMemorySearch.from_documents(docs, embeddings)
query = "Please suggest a shirt with sunblocking"
# 通过 index.vectorstore 访问底层的向量存储对象
docs = db.similarity_search(query)
print("找到的文档数量:",len(docs))
print("第一个文档",docs[0])
找到的文档数量: 4
第一个文档 page_content=': 255
name: Sun Shield Shirt by
description: "Block the sun, not the fun – our high-performance sun shirt is guaranteed to protect from harmful UV rays.
Size & Fit: Slightly Fitted: Softly shapes the body. Falls at hip.
Fabric & Care: 78% nylon, 22% Lycra Xtra Life fiber. UPF 50+ rated – the highest rated sun protection possible. Handwash, line dry.
Additional Features: Wicks moisture for quick-drying comfort. Fits comfortably over your favorite swimsuit. Abrasion resistant for season after season of wear. Imported.
Sun Protection That Won't Wear Off
Our high-performance fabric provides SPF 50+ sun protection, blocking 98% of the sun's harmful rays. This fabric is recommended by The Skin Cancer Foundation as an effective UV protectant.' metadata={'source': 'data/OutdoorClothingCatalog_1000.csv', 'row': 255}我们可以看到一个返回了四个结果。输出的第一结果是一件关于防晒的衬衫,满足我们查询的要求。
5. 使用查询结果构造提示来回答问题
from IPython.display import display, Markdown #在jupyter显示信息的工具
#合并获得的相似文档内容
qdocs = "".join([docs[i].page_content for i in range(len(docs))])
#将合并的相似文档内容后加上问题(question)输入
#这里问题是:以Markdown表格的方式列出所有具有防晒功能的衬衫并总结
response = llm.invoke(f"{qdocs} Question: Please list all your shirts with sun protection in a table in markdown and summarize each one.")
print(response)
display(Markdown(response.content))
结果为

6. 使用检索问答链来回答问题
通过LangChain创建一个RetrievalQA检索问答链,对检索到的文档进行问题回答。检索问答链的输入包含以下内容:
- llm: 语言模型,进行文本生成。
- chain_type:传入链类型。
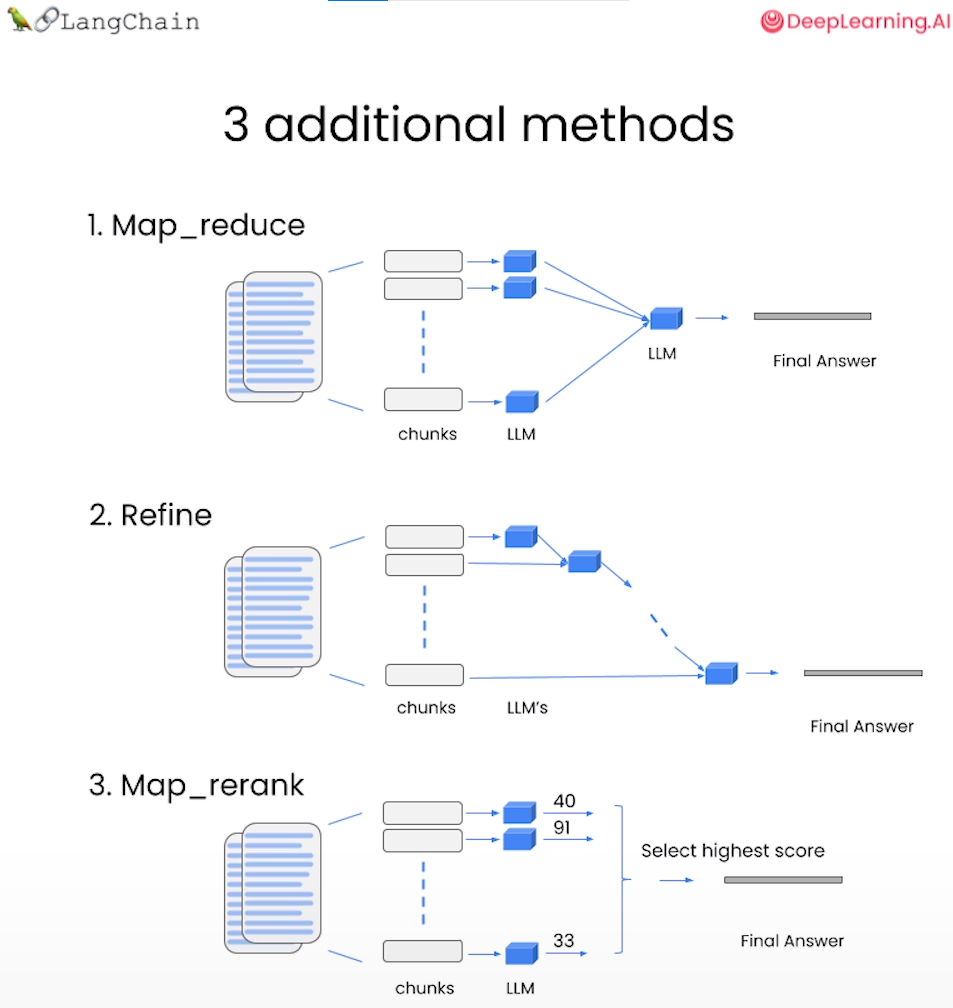
- Map Reduce :将所有块与问题一起传递给语言模型,获取回复,使用另一个语言模型调用将所有单独的回复总结成最终答案,它可以在任意数量的文档上运行。可以并行处理单个问题,同时也需要更多的调用。它将所有文档视为独立的。
- Refine :用于循环许多文档,实际上它是用迭代实现的,它建立在先前文档的答案之上,非常适合用于合并信息并随时间逐步构建答案,由于依赖于先前调用的结果,因此它通常需要更长的时间,并且基本上需要与Map Reduce一样多的调用。
- Map Re-rank :对每个文档进行单个语言模型调用,要求它返回一个分数,选择最高分,这依赖于语言模型知道分数应该是什么,需要告诉它,如果它与文档相关,则应该是高分,并在那里精细调整说明,可以批量处理它们相对较快,但是更加昂贵。
- Stuff : 将所有内容组合成一个文档。(案例使用这个)
from langchain.chains import RetrievalQA
#基于向量储存,创建检索器
retriever = db.as_retriever()
qa_stuff = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
verbose=True
)
query = "Please list all sunblocking shirts in a Markdown table format and summarize the description for each shirt."
#创建一个查询并在此查询上运行链
response = qa_stuff.invoke(query)
display(Markdown(response["result"]))

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)