【世界模型】Captain Safari:位姿对齐3D记忆的世界引擎(CVPR 2026)
本文提出Captain Safari——一种基于位姿条件的三维世界引擎,通过持久化记忆机制实现长距离视频生成。针对现有系统在复杂摄像机运动和户外场景中表现不佳的问题,该方法创新性地采用动态局部记忆窗口与位姿对齐检索策略:仅筛选关键场景特征构建紧凑世界表示,在保证计算效率的同时维持三维一致性。研究团队还发布了OpenSafari数据集,包含高动态无人机拍摄的复杂户外场景视频及验证轨迹。实验表明,该模

标题:Captain Safari: A World Engine with Pose-Aligned 3D Memory来源:约翰霍普金斯大学;清华大学 ;加州大学圣克鲁兹分校链接:https://johnson111788.github.io/open-safari/
文章目录
摘要
世界引擎旨在合成长镜头、三维一致性视频,支持用户通过自主控制摄像机运动对场景进行交互式探索。然而现有系统在应对激进的六自由度运动轨迹和复杂户外场景时表现欠佳:容易丧失远距离几何连贯性、偏离目标路径,或陷入过度保守的运动模式。
为此,我们推出“Captain Safari”——一种基于位姿条件的世界引擎,通过从持久化世界记忆中检索数据生成视频。该方法通过动态本地记忆机制,结合检索器获取姿态对齐的世界标记,从而沿运动轨迹进行视频生成条件化处理。这种设计使模型在执行高难度摄像机操作时,既能保持稳定的三维结构,又能精准完成复杂运动场景。
为评估该实验环境,我们精心构建了OpenSafari——一个全新的野外 FPV(第一人称视角) 数据集,其中包含具有已验证摄像机轨迹的高动态无人机视频,这些数据通过多阶段几何与运动学验证流程构建而成。在视频质量、三维一致性及轨迹跟随能力方面,Captain Safari 模型显著优于当前最先进的摄像机控制生成器:将MEt3R指标从0.3703降至0.3690,AUC@30指标从0.181提升至0.200,并实现比所有摄像机控制基线模型更低的 FVD 。更重要的是,在一项包含50名受试者、五种匿名模型的人类研究中,标注者从五个匿名模型中选择最佳结果时,67.6%的偏好结果在所有维度上均支持我们的方法。研究结果表明,姿态条件世界记忆机制是实现长时域可控视频生成的强大工具,并为未来世界引擎研究提供了具有挑战性的新基准。
一、引言
通过可控视频生成技术模拟连贯的三维世界,长期以来一直是增强现实、具身人工智能及虚拟智能体领域的基础性挑战。传统游戏引擎与物理模拟器虽能提供明确的几何结构和精准控制,但需要大量人工编写代码并消耗高昂计算资源。此外,尽管它们在特定领域可实现视觉真实感,但在捕捉现实世界特征(如自然场景)的丰富性与多样性方面仍存在不足。相比之下,现代视频扩散模型虽能从文本或图像中合成高保真、多样化的视频内容,但通常采用前馈式片段生成器架构且缺乏持续状态机制:在实现长距离三维一致性、复杂轨迹追踪及多样化场景还原方面存在明显局限[19,25]。本研究通过开发“Captain Safari”世界引擎,致力于弥合这一技术鸿沟。该引擎支持基于姿态条件的三维一致性与多样性环境建模,在通用性、多样性及交互性方面均超越了传统游戏引擎的局限性。
当代视频世界模型面临三大相互交织的挑战:
- 1.长视距一致性受限于上下文帧的时间窗口:模型常会“遗忘”远处场景或破坏空间连贯性,导致生成环境出现突兀的外观变化,从而破坏真实感与连续性[8,15,48]。
- 2.在严格三维一致性要求下实现复杂摄像机运动仍具挑战性:现有基于姿态或轨迹条件的方法通常仅适用于缓慢的近前向运动[17,35,53]。当路径涉及快速六自由度运动、强烈视差或急转弯时,模型会陷入两难选择——要么通过抑制运动并限制视角变化来保持几何结构,要么在牺牲畸变、闪烁和结构漂移代价下严格遵循预设路径。
- 3.现有方法对复杂户外场景的表征不足。多数研究聚焦于结构化约束场景(如室内导览、驾驶场景或房地产视频),且鲜有模型在真实 FPV 场景中进行压力测试——这类场景中摄像机需在建筑物、植被和复杂地形间穿梭,并承受显著视差[6,23,63,64]。因此,那些在简化场景中表现优异的方法,在面对真正多样化复杂户外场景时往往难以保持几何结构与外观特征。
为解决这些问题,Captain Safari通过持续维护世界状态的持久化概念,在强视差环境下实现长期三维一致性。由于存储和传播完整长期状态存在计算成本过高问题,我们开发了智能检索机制——仅筛选并整合最具信息量的场景线索,从而在不产生过高计算开销的情况下提供精准几何引导。关键在于该检索机制具备位姿感知能力: 根据目标相机pose,系统会构建位姿对齐的世界先验,引导生成过程精准追踪激进的摄像机运动轨迹,同时在复杂环境中保持三维结构的一致性。
此外,为弥补复杂户外场景布局与剧烈摄像机运动带来的数据缺口,我们精心打造了OpenSafari数据集—— 这是一个包含高动态 FPV 无人机视频的大规模数据集,所有摄像机姿态均经过验证。现有研究多聚焦于结构化受限场景(如室内导览、驾驶实录或房地产视频),即便是户外数据集也普遍呈现缓慢的近前向运动特征。相比之下,OpenSafari收录的野外 FPV 飞行视频展现出三大特征:在崎岖地形中穿梭于建筑物与植被间的动态轨迹、显著的视差效应、快速的六自由度机动动作以及剧烈的视角切换。结合经过验证的摄像机运动轨迹,这些视频呈现了多样化的复杂户外场景与长距离运动轨迹,对模型在保持三维一致性的同时精准追踪复杂机动动作提出了严峻挑战。
二、相关工作
- 三维一致的世界模型
早期的图像到三维重建方法通过多视角一致性或隐式场间接重构几何结构,但在大规模视角变化时往往难以保持结构连贯性[14,22,46,54]。近期研究将三维推理机制融入生成过程:DiffusionGS[5]在扩散去噪器中引入高斯点扩散技术,既确保视角一致性又实现单阶段可扩展三维生成;GenEx[24]与EvoWorld[43]将该思路从静态重建拓展至动态世界构建,基于物理先验生成可探索的360°全景环境。与这些生成式重建方法互补的是,Geometry Forcing[47]和Memory Forcing[15]通过将训练信号与几何监督及时空记忆显式耦合,确保长周期运行过程中的结构一致性。与此同时,Wonderland[21]、WonderWorld[55]、WonderTurbo[27]、relic[11]及WorldPlay[37]等开放世界模型进一步整合几何索引记忆或自适应记忆机制,以维持交互过程中的持续世界状态。然而这些方法仍采用隐式片段边界记忆或显式维护庞大点云数据集[49],而我们的解耦检索器则在固定成本下保持条件结构的紧凑性。
- 像机控制的视频生成
早期的T2V/I2V模型通过隐式学习相机运动,难以可靠地重复显式轨迹[12,45,65]。近期研究如CameraCtrl[10]将相机参数视为显式条件,通过编码相机外参和轨迹或强制路径约束来提升可控性和精度[2,26,44,51,59]。MotionPrompting[9]通过点轨迹条件化实现组合控制,MotionPro[60]采用路径对齐损失函数降低旋转和平移误差;无训练控制方法则通过拟合轻量级点云并采用噪声布局先验进行转向去噪实现[12]。场景保留几何先验进一步增强了片段级一致性。Cami2V[61]将相机姿态视为物理先验并利用极线约束和多视角约束;RealCam-I2V[20]通过DepthAnything v2[52]恢复度量深度以重建尺度稳定的场景;PoseTraj[17]采用姿态感知预训练获得旋转对齐运动。相较于纯参数条件化,这些先验方法能有效减少片段内布局漂移,并在视角变化时更好地保持局部几何结构。此外,最新研究将相机控制与世界建模相结合: CVD [18]、Cavia[50]和WoVoGen[23]通过共享场景表征联合合成多视角多轨迹视频,强制实现跨路径一致性。与此同时,基于显式可渲染三维表示(如3DGS)进行条件化的方法能够锚定几何结构、提升跨视图三维一致性及路径遵循性[16,30,34,56,57]。然而这些方法通常仅构建一次性三维场景,而我们的创新在于将长视距相机控制与跨轨迹共享的持久姿态索引世界记忆相结合。
三、Captain Safari
1.世界几何的隐式记忆
- 问题设置 (Problem Setup)
- 输入:视频 V V V 被表示为帧序列,每个时刻 t t t 对应一个相机位姿 C = { ( R t , T t ) } t = 0 T C = \{(R_t, T_t)\}_{t=0}^T C={(Rt,Tt)}t=0T。
- 存储库 ( M \mathcal{M} M):通过预训练的几何编码器,获取每一帧的“3D感知存储特征” ( m t m_t mt),构成全局存储库。
- 目标:给定文本提示 p p p、相机位姿 C C C 和目标时间步 T = [ t 0 , t 1 ] \mathcal{T}= [t_0, t_1] T=[t0,t1]内,合成一段既符合文本描述 p p p、又遵循给定轨迹,且在3D空间上与历史观测的特征池( M \mathcal{M} M)在空间逻辑上无缝对接的视频片段 V ^ T \hat{V}_{\mathcal{T}} V^T。
- 局部世界存储 (Local World Memory)
为了降低计算开销并避免长距离干扰,系统不直接读取整个全局存储库,而是定义了一个局部窗口 [ k s , k e ] [k_s, k_e] [ks,ke]:
- t 0 − L ≤ k s ≤ t 0 t_0 - L \le k_s \le t_0 t0−L≤ks≤t0:定义了记忆窗口的起点 k s k_s ks。它允许回溯到当前 Clip 起点 t 0 t_0 t0 之前的 L L L 步。这相当于设定了时序上的“感受野”,确保当前段能“看”到之前的环境。
- max ( k s , t 0 ) + 1 ≤ k e ≤ min ( k s + L , t 1 ) \max(k_s, t_0) + 1 \le k_e \le \min(k_s + L, t_1) max(ks,t0)+1≤ke≤min(ks+L,t1):定义了记忆窗口终点 k e k_e ke。约束条件极其精妙:既保证了窗口总长度不超过 L L L(控制了显存占用),又强制要求历史窗口的末端必须与当前 Clip 的起点 t 0 t_0 t0 产生重叠或相切。

这种设计使得相邻的生成clip自然地共享了一部分“世界状态底座”。就像链条一样,通过局部特征的 Overlapping,间接地完成了全局时序的连续性传递。
- 核心创新:基于位姿的隐式寻址 (Pose-retrieved)
隐式世界表(Implicit world table) :{ p τ , m τ , 1 : M ) p_τ , m_{τ,1:M}) pτ,mτ,1:M)} τ _τ τ。构建time step τ τ τ 的特征库。其打破了传统视频模型强依赖 时间索引(Time indices) 的惯性,将过去的观测解耦为 Where(位姿 Token p τ p_{\tau} pτ,由相机外参提取。)和 What(3D 视觉特征 Token m τ , 1 : M m_{\tau, 1:M} mτ,1:M)。这两者在局部窗口内构成了一张静态的、非结构化的 3D 字典
基于交叉注意力的空间投影 ( Cross-Attention 寻址):为生成目标帧 t t t ,提取对应相机位姿 p t p_t pt,映射为一个 Query 向量 q t q_t qt,结合可学习参数得到检索 Query Q t Q_t Qt 。公式2: w t = Agg ( CrossAttn ( Q t , X ~ mem ) ) w_t = \text{Agg}(\text{CrossAttn}(Q_t, \tilde{X}^{\text{mem}})) wt=Agg(CrossAttn(Qt,X~mem))
公式 (2) 实际上是用 Transformer 的注意力机制模拟了显式 3D 渲染中的**“视角投影” (View Projection)**。网络通过计算“当前目标视角”与“历史观测视角”在空间高维语义上的相似度,动态地加权聚合出当前视角下应该看到的 3D 特征 w t w_t wt。
2.记忆检索与条件化
2.1 记忆的联合编码与空间锚定:将局部的历史观测构建为 空间先验“特征池”
X ^ τ = [ ϕ p ( p τ ) , ϕ m ( m τ , 1 ) , … , ϕ m ( m τ , M ) ] ( 3 ) \hat{X}_{\tau} = [\phi_p(p_{\tau}), \phi_m(m_{\tau, 1}), \dots, \phi_m(m_{\tau, M})](3) X^τ=[ϕp(pτ),ϕm(mτ,1),…,ϕm(mτ,M)](3) 这里使用可学习的嵌入层 ϕ p \phi_p ϕp 和 ϕ m \phi_m ϕm,将相机位姿 p τ p_{\tau} pτ(通常源自 SE(3) 变换矩阵)和 3D 感知特征 m τ m_{\tau} mτ 映射到同一个联合隐空间中。
X ~ τ = MemEnc ( X ^ τ ) ( 4 ) \tilde{X}_{\tau} = \text{MemEnc}(\hat{X}_{\tau})(4) X~τ=MemEnc(X^τ)(4) 3D RoPE位置编码 防止 Transformer 往往丢失空间结构,强制网络理解特征的三维空间拓扑关系
公式 (5) 全局记忆池构建:将局部时间窗 [ k s , k e ] [k_s, k_e] [ks,ke] 内的所有编码特征拼接,形成待检索的记忆池 X ~ mem \tilde{X}^{\text{mem}} X~mem:

2.2 位姿感知的隐式检索与渲染:基于目标视角,抓取当前视角应该看到的特征。
Q ^ t = [ q t , r 1 , … , r M ] ( 6 ) \hat{Q}_t = [q_t, r_1, \dots, r_M] (6) Q^t=[qt,r1,…,rM](6)为了生成目标时间步 t t t 的帧, 提取目标位姿 q t q_t qt,并将其与 M M M 个可学习的 query tokens ( r 1 … r M r_1 \dots r_M r1…rM) 拼接 (类似于 DETR 中的 Object Queries)
Q t = QryEnc ( Q ^ t ) Q_t = \text{QryEnc}(\hat{Q}_t) Qt=QryEnc(Q^t) Y t = Q t + CrossAttn ( Q t , X ~ mem ) Y_t = Q_t + \text{CrossAttn}(Q_t, \tilde{X}^{\text{mem}}) Yt=Qt+CrossAttn(Qt,X~mem)
目标查询 Q t Q_t Qt 作为 Query,去访问记忆池 X ~ mem \tilde{X}^{\text{mem}} X~mem (作为 Keys 和 Values)。网络计算目标位姿与历史观测位姿的高维相似度,动态聚合出当前视角下的特征。残差连接保证了梯度的稳定
w t = [ w t , 1 , … , w t , M ] ( 9 ) w_t = [w_{t,1}, \dots, w_{t,M}] (9) wt=[wt,1,…,wt,M](9) 从 Y t Y_t Yt 中截取出对应的 token,即目标位姿 t t t 下对齐好的世界特征 w t w_t wt。训练时用一个线性头将 w t w_t wt 映射回原空间去重建目标帧 。这迫使 Cross-Attention 真正学习到多视图几何中的透视投影关系。
2.3. 记忆条件化的 DiT 生成:将上述隐式3D 先验特征,注入DiT去噪
W T = ϕ w ( w t ) ∈ R M × D ( 10 ) W_{\mathcal{T}} = \phi_w(w_t) \in \mathbb{R}^{M \times D}(10) WT=ϕw(wt)∈RM×D(10)
通过 MLP ϕ w \phi_w ϕw 将特征投影到 DiT 潜空间所需的维度 D D D 。 Z ( l + 1 ) = Z l + CrossAttn ( Z l , W T , W T ) ( 11 ) Z^{(l+1)} = Z^l + \text{CrossAttn}(Z^l, W_{\mathcal{T}}, W_{\mathcal{T}}) (11) Z(l+1)=Zl+CrossAttn(Zl,WT,WT)(11) 在 DiT 的第 l l l 层,视频潜变量(时空 Token 序列 Z l Z^l Zl)在完成 Self-Attention 之后,必须经过一层 Cross-Attention。在这里, Z l Z^l Zl 充当 Query,而我们准备好的 3D 一致性特征 W T W_{\mathcal{T}} WT 充当 Keys 和 Values。
四、Open Safari
1.视频数据清洗
现有基于相机条件的数据集与我们的目标场景并不匹配。
- RealEstate10K[63]主要收录缓慢移动、以室内场景为主的房地产漫游视频,其运动轨迹平缓且场景清晰近乎静态;
- Minecraft[4]则是采用简化几何结构和引擎限制动态的合成体素世界。
这两种数据集均无法捕捉具有强烈视差、显著高程变化及复杂户外布局的野外6自由度无人机飞行场景,这些场景对三维视觉的长视距一致性提出了严苛要求。
自建OpenSafari数据集——包含经过验证的相机轨迹,专门针对具有 FPV 风格的无人机视频场景。其基于AirVuz1和YouTube2平台收集的 FPV 风格无人机视频构建Safari- FPV ,并仅保留通过严格多阶段预处理流程的片段。如图3所示,具体流程包括:

- (i)下载每个URL对应的最高可用分辨率,剔除分辨率低于目标值的源视频;
- (ii)将所有视频标准化为720p分辨率、24帧/秒帧率及固定16:9中心裁剪比例,去除黑边和黑边框以确保后续相机估计基于清晰视野进行;
- (iii)通过场景检测获取单次拍摄片段;
- (iv)采用均匀时间切片法将片段分割为固定时长的T个视频。
随后基于运动特征,筛选视频(单诊断标准):通过RAFT算法[39]估算光流幅值:运动量过小的视频会被剔除,而具有稳定连贯运动的视频则被保留,以突出信息量丰富且视差特征显著的运动轨迹,而非静态画面。仅满足运动约束条件的视频才会进入最终数据集。由此构建的大型野外无人机视频语料库,专门针对几何感知型轨迹跟随视频生成的性能压力测试需求进行定制化优化。
2.相机轨迹重建
每个视频使用 hloc 以4帧/秒的帧率估算相机的内参和外参:具体采用 COLMAP 的增量映射器结合简单径向相机模型重建SfM模型,随后导出相机参数作为初始轨迹。
为获取可直接部署的数据,我们对每条重建轨迹应用了三阶段验证与修正流程。
- 首先,数据库检查利用SfM统计量(内点计数与比率)来标记潜在不可靠的过渡点。
- 随后,几何校验通过存储的关键点与匹配结果重新分析可疑配对,重新计算本质矩阵并设定对称极线误差阈值。
- 最后,运动学校验利用基于稳健MAD(均方绝对偏差)的评分标准,对位姿序列进行分析,检测平移突变、旋转跳跃、正向翻转及高阶平滑性违规等异常运动模式。
所有过渡决策结果会被整合成一个二元坏索引,该索引将驱动严格的策略执行。若不良过渡现象分布稀疏且集中化,我们将实施针对性修正方案:通过线性插值法确定摄像机中心位置,并对旋转角度施加 SLERP(插值角度存在上限限制),视频边界处可选择性进行外推处理。修正后的片段将依据相同的数据库验证标准、几何参数校验及运动学分析准则进行二次验证。若二次验证通过,轨迹数据将被导出至最终数据集。若坏索引分布过于密集、违规程度过于严重,或修正轨迹仍无法通过验证,则整段视频将被直接丢弃。
最终生成的OpenSafari系统将高动态范围的野外 FPV 无人机视频与严格验证的摄像机运动轨迹相结合。该系统突破传统基准测试框架,通过强化6自由度运动捕捉、增强视差效果及复杂户外场景布局,并实施严格的几何与运动学验证,从而成为摄像机可控视频生成的高难度测试平台。
实验
训练方案。两阶段训练方案:首先使用姿态对齐的记忆标记 m t m_t mt预热位姿条件记忆检索器,随后通过LoRA[13]联合训练检索器与DiT模型进行端到端优化。记忆交叉注意力机制从对应上下文交叉注意力权重初始化,其余新层采用标准初始化方法。
数据集构建。通过1秒步长提取重叠视频片段,共获得51,997个训练样本。基于多样性轨迹过滤器剔除近似静态运动片段后,最终保留11,481个训练片段。另构建包含787个非重叠片段的测试集用于评估。每个片段使用Qwen2.5-VL-7B[3]生成单一描述性标题,并将其作为文本条件输入。
配置与标注。从总时长为15秒的视频中以24帧/秒的帧率生成5秒时长的片段。相机位姿与记忆特征以4帧/秒的采样率进行采集。选择末端姿态 p t 1 p_{t_1} pt1作为查询点,因其代表了漂移效应通常累积的最远视角,从而在整个轨迹中强化几何约束。记忆窗口长度限制为L=5秒。采用Wan2.2-Fun-5BControl-Camera模型[41]作为基础DiT模型,其隐藏维度D=3072。检索器与DiT模型分别经过1次和5次训练周期。检索器在推理阶段也会被使用,为简化流程并保证可复现性, M M M直接基于真实视频构建。三维感知记忆特征提取自StreamVGGT模型[66],选取第4、11、17、23层特征,每层特征包含782个标记 。将四层特征拼接后,每帧生成M=4×782个记忆标记,总记忆标记量 d m = 1024 d_m=1024 dm=1024。
指标。视频质量 采用 FVD [40]和 LPIPS [58]作为参考标准。三维一致性 采用MEt3R[1]指标,该指标通过匹配时间步长和重建速率对真实视频与生成视频进行计算,其中重建速率用于衡量成功注册到恢复三维模型中的帧所占百分比[31,32]。轨迹跟随性能评估,报告相机重定位精度(AUC[42])及展平相机姿态间的余弦相似度。生成视频评估采用与数据集整理完全相同的SfM模型堆栈,未设置独立重定位模块。为解决单目尺度模糊问题,我们通过将首帧固定为原点并采用单位旋转进行标准化处理,确保AUC与CosSim指标能有效评估相对外部参数。
基准模型。选取了几种具有代表性的相机可控视频生成模型进行对比分析,包括Geometry Forcing[47]、Real-CamI2V[20,61]以及Wan2.2-5BControl-Camera模型[41],这些模型分别涵盖了几何约束、重建驱动和大规模扩散式方法在轨迹引导视频合成领域的应用。
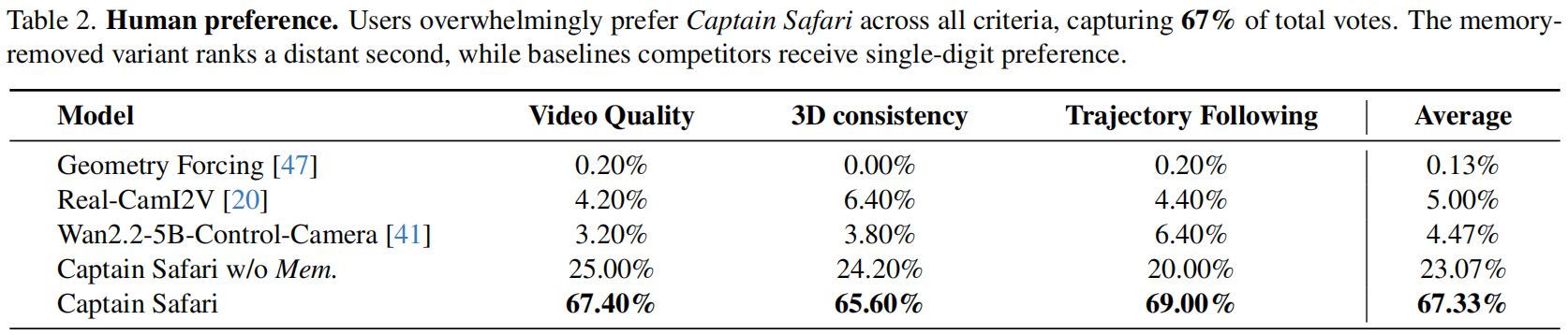
人类实验研究。我们开展了包含50名受试者的人体实验研究。每位受试者需观看10组案例视频,每组案例包含真实视频(GT视频)及五段匿名模型生成视频(包含三种基准模型、本研究模型及其消融变体)。针对每个案例,受试者需根据视频质量、三维一致性及轨迹跟随度三个标准选出最佳视频。本研究共收集了50×10×3=1,500份人类偏好投票数据。
我们从视频质量、3D一致性及轨迹跟随三个维度对Captain Safari进行评估。在这些指标上,我们的方法始终优于OpenSafari平台上的当代摄像机控制视频生成器:
- 表1数据显示,在复杂机动场景下,其3D一致性与精准跟踪能力获得显著提升,同时保持了出色的感知质量。

- 表2大规模人类研究表明,在五组对比实验中Captain Safari获得了67%的评分,这说明其改进效果具有显著的感知优势。
- 定性对比分析(图4和图5)进一步证实,该系统在长距离路径中能保持稳定的几何结构,并在复杂户外场景中精准遵循6自由度摄像机的急转弯动作。



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 7
7 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)