大模型训练推理优化(5): FlexLink —— NVLink 带宽无损提升27%
本期我们将介绍蚂蚁集团ASystem团队在大模型通信优化上的新工作FlexLink,旨在通过动态聚合多路通信(NVLink,PCIe,RDMA),在H800等典型硬件上将典型通信算子如(AllReduce, All Gather)吞吐提升最高达27%,尤其适合大模型长序列推理(Prefill阶段),及训练等通信密集的带宽bound场景。多通道并发传输:聚合NVLink,PCIe,RDMA网卡等多个
文章作者:申奥 张锐 赵军平。
系列回顾:
大模型推理显存优化系列(3):FlowMLA——面向高吞吐的DP MLA零冗余显存优化
大模型推理显存优化系列(4):eLLM-大模型推理中的弹性显存管理和优化
本期我们将介绍蚂蚁集团ASystem团队在大模型通信优化上的新工作FlexLink,旨在通过动态聚合多路通信(NVLink,PCIe,RDMA),在H800等典型硬件上将典型通信算子如(AllReduce, All Gather)吞吐提升最高达27%,尤其适合大模型长序列推理(Prefill阶段),及训练等通信密集的带宽bound场景。方案对精度无影响。
背景与挑战:被“闲置”的通信带宽
在当前的大模型并行策略中,无论是训练中的数据交换(例如EP=8),还是推理中的prefill阶段,都可能涉及机内大量的跨GPU的数据交换。
- 通信瓶颈凸显:实测表明,在单机H800运行开源模型处理64K长序列推理时,Prefill阶段通信耗时占比高达36%。字节跳动的MegaScale-MoE一文也指出,MoE模型训练中前向传播时的通信占比可达43.6%。
- 链路利用单一化:行业普遍采用固化的通信模式:节点内几乎仅依赖高速NVLink,节点间则主要走通用以太网卡及RDMA网络。这种模式虽简洁高效,却忽视了同样连接GPU的的PCIe总线及基于PCIe的RDMA网卡的潜力,导致其带宽资源被长时间闲置
-
硬件限制:中国市场上广泛部署的H800核心的NVLink互联带宽遭到了大幅削减。例如,H800的NVLink带宽仅为400 GB/s,远低于标准版H100的900 GB/s。
FlexLink思路:从单独最优到动态多路聚合,榨干硬件潜力
FlexLink的核心思想是打破固化模式,化“单选题”为“多选题”。我们在NVLINK的基础上,将所有可用的通信链路视为一个统一的、可聚合的带宽资源池。通过协同使用这些链路,实现总通信吞吐的最大化。 因此,FlexLink的核心设计包括:
- 多通道并发传输:聚合NVLink,PCIe,RDMA网卡等多个物理上独立的传输通道,将一次大的通信传输操作,拆分到多个链路并发执行,以提高总带宽。
- 动态负载划分: FlexLink采用了两阶段的负载均衡和划分:通过感知硬件拓扑,简单,轻量地在初始化的时候,tuning各个链路的负载比例以及适合各个链路的chunk大小。并且在运行时通过实时的负载特征,对于各个链路的负载进行实时调整。
- CPU内存中转优化:针对利用PCIe进行卡间通信(需通过Host Memory中转)的场景,FlexLink通过流水线化通信过程,通信组GPU的NUMA节点感知,以及优化Host Memory的访问路径和CPU执行开销,有效提升PCIe卡间通信效率。
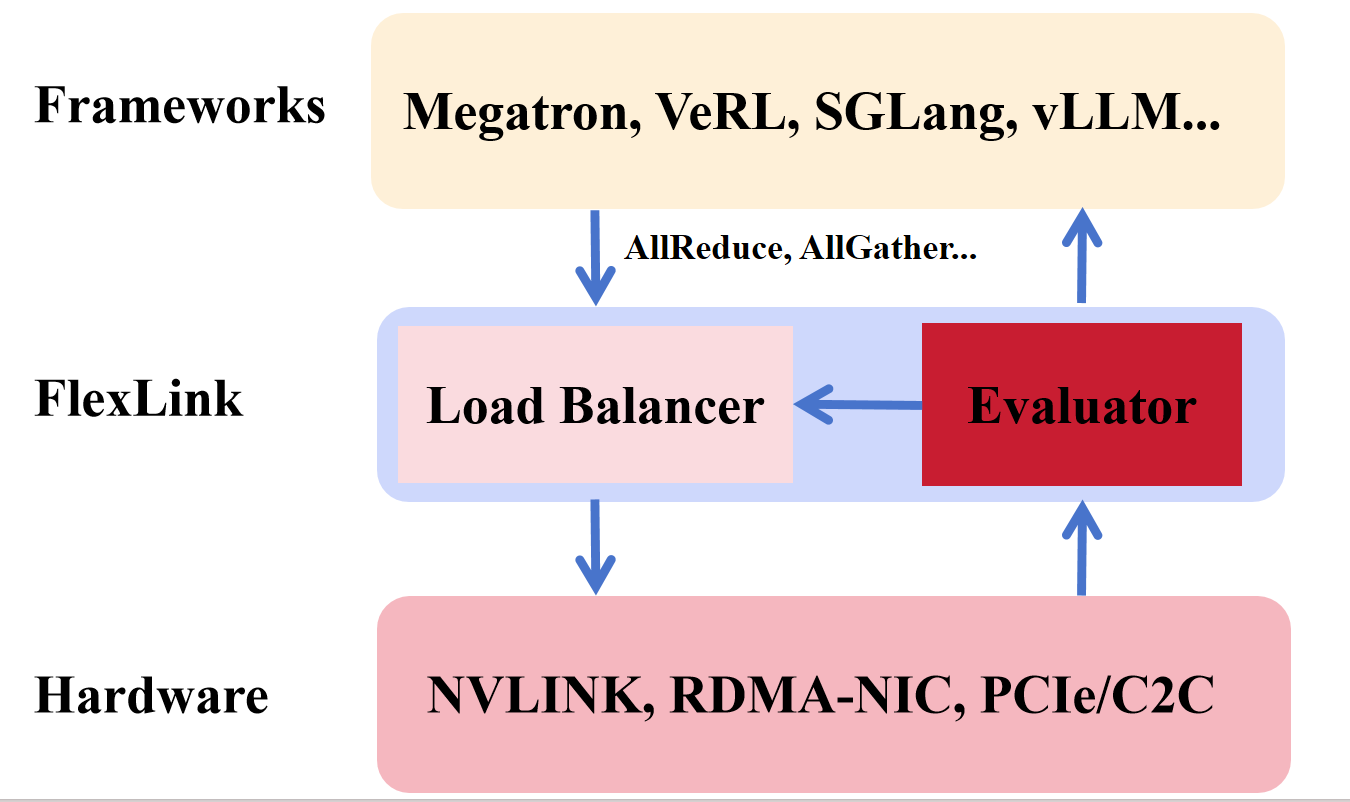
图1: FlexLink设计图
FlexLink关键设计:两阶段自适应负载均衡简介
如何让带宽相对较慢的PCIe和RDMA网卡在分担负载的同时,避免拖累高速NVLink-----这是实现增益的关键。
我们尝试通过两阶段负载均衡机制来解决这一问题。
- 初始化阶段: 基于硬件信息建模,设定初始负载比例。随后在短时间内进行微调(按步长转移负载),监测链路性能偏序关系变化。若关系反转(如慢链路变快),则减半步长并迭代优化,数秒内收敛到较优状态。
- 运行时阶段: 在固定时间窗口内Evaluator采集各链路传输速率数据, 并反馈给Load Balancer:
- 识别当前窗口内最有可能的最慢与最快链路。
- 计算平均速率差,若超过阈值,则从慢链路向快链路转移负载份额。
- 特别地,若NVLink并非最慢链路,则采用差异化阈值进行更积极的份额转移,确保其高效利用。
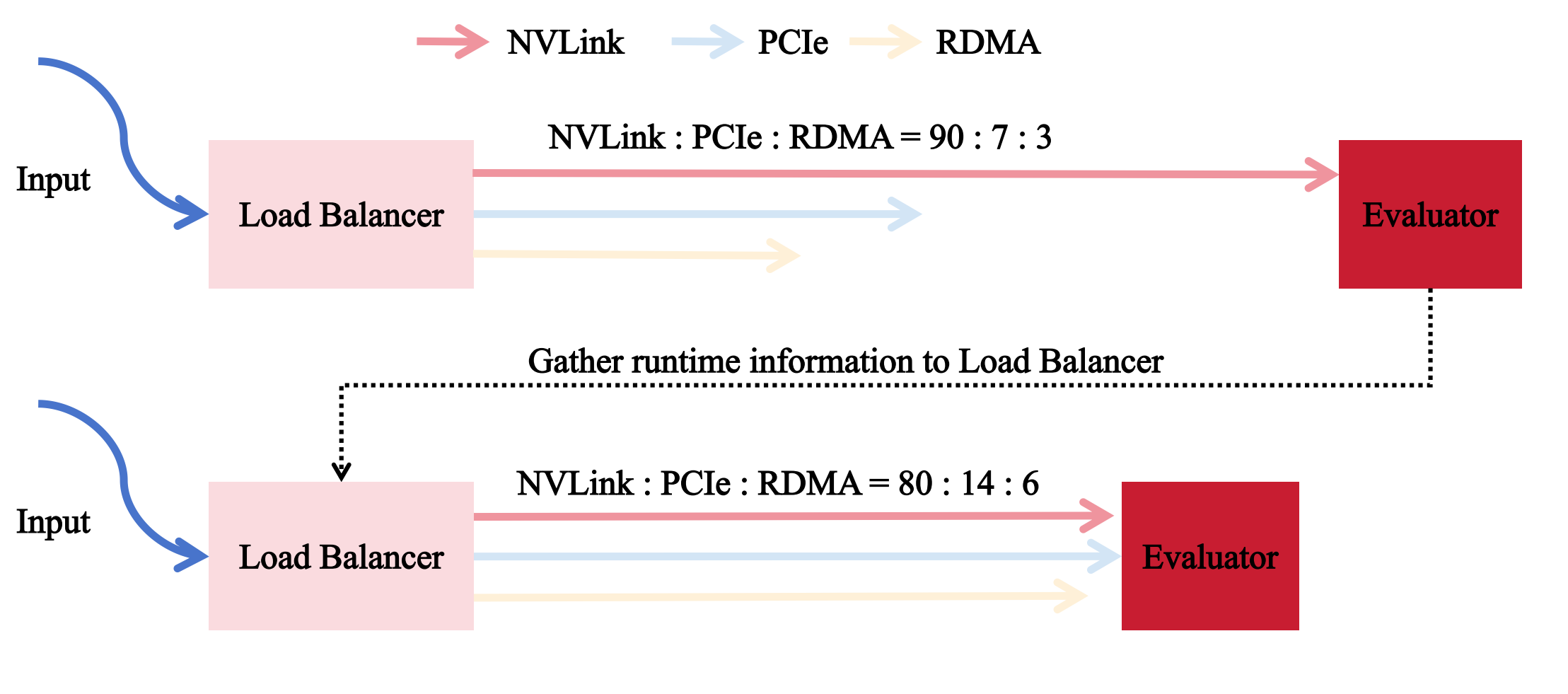
图2: 基于Load Balancer和Evaluator进行运行时负载均衡
FlexLink初步结果对比
硬件环境:H800 SXM *8(单机,NVLink 400GB/s,PCIe 5.0, 8块ConnectX-6网卡 (800Gbps双向)。
软件版本:CUDA 12.4,GPU Driver 535,NCCL 2.27.3,NVSHMEM 3.2.5。
负载情况:AllReduce: input=output=256MB;AllGather: input=256MB, output = worldsize * input,我们选择256MB以充分体现带宽瓶颈的场景。
关注指标:Input / Duration (GB/s)。
|
通信方式 |
卡数 |
NCCL基线 |
FlexLink |
PCIe+RDMA 贡献 |
带宽提升比例 |
|
|
AllReduce |
2卡 |
139 GB/s |
175 GB/s |
36 GB/s |
26% |
|
|
AllReduce |
4卡 |
98 GB/s |
118 GB/s |
20 GB/s |
20 % |
|
|
AllReduce |
8卡 |
107 GB/s |
109 GB/s |
2 GB/s |
2 % |
|
|
AllGather |
2卡 |
132 GB/s |
161 GB/s |
29 GB/s |
22 % |
|
|
AllGather |
4卡 |
49 GB/s |
62 GB/s |
13 GB/s |
27% |
|
|
AllGather |
8卡 |
21 GB/s |
26 GB/s |
5 GB/s |
24% |
|
实验结果表明:
- 在 2卡,4卡H800环境下,对于AllReduce算子(256MB输入),FlexLink带来了20%和26%的提升,在8卡场景下,由于AllReduce的通信链路相比AllGather较长,延迟增加更明显,导致性能提升(2%)相对有限。
- 对于AllGather算子(256MB输入),在2卡、4卡场景下提升达22%以及27%;在8卡场景下,虽然通信延迟增加带来一定挑战,FlexLink仍实现了24% 的有效提升。
- PCIe与RDMA链路成功分担了18%-22% 的总通信负载,有效利用了闲置带宽。
小结
FlexLink通过动态启用多链路聚合、结合初始化粗粒度负载均衡与运行时细粒度自适应调整,有效的提升了系统可用带宽。其价值不仅限于H800。对于同样面临卡间通信带宽限制的其它硬件平台,理论上均可基于该方法进一步提升。
进一步工作:
- 我们将适时进行开源推理框架的集成,敬请期待!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)