仓颉跨语言混合编程:FFI实战与性能优化
摘要:本文深入探讨了仓颉语言外部函数接口(FFI)机制,重点分析了其在HarmonyOS生态中实现跨语言互操作的关键技术。文章系统阐述了FFI的核心原理,包括数据类型映射、内存管理和安全抽象设计,并通过封装zlib压缩库的实战案例,展示了如何在保持安全性的前提下实现高效调用。特别强调了通过RAII模式管理C资源、批处理优化减少调用开销、零拷贝技术提升性能等实践策略。最后讨论了FFI在平衡生态复用与
摘要 (Abstract)
在 HarmonyOS 生态中,为了复用海量的现有 C/C++ 库(如音视频编解码、图形渲染引擎、AI算法库)或调用系统底层 API(应用程序接口),跨语言混合编程是不可或缺的。仓颉语言通过其**外部函数接口(FFI, Foreign Function Interface)**机制,提供了一条安全、高效的桥梁,用于与 C ABI(应用二进制接口)兼容的代码进行互操作。本文将深入剖析仓颉 FFI 的核心原理,从数据类型映射(Type Mapping)、内存管理(Memory Management)到安全抽象(Safe Abstraction)的设计哲学,并通过实战案例演示如何安全地封装一个 C 库。最后,我们将重点分析 FFI 调用的性能开销及优化策略,帮助开发者在利用现有生态的同时,构建高性能的仓颉应用。
一、背景介绍 (Background)
任何一门新兴语言在生态建设初期,都面临着“鸡生蛋还是蛋生鸡”的困境:缺乏库生态导致开发者不愿使用,而开发者不使用又导致生态无法繁荣。FFI 是打破这一循环的最有效武器。对于仓颉而言,HarmonyOS 系统底层、三方SDK以及众多高性能计算库(如ffmpeg, OpenSSL, TensorFlow Lite)都是用 C/C++ 编写的。
如果无法高效、安全地调用这些存量资产,仓颉的应用场景将受到极大限制。仓颉 FFI 的设计目标是在 Rust 等现代系统语言的启发下,提供一种“零成本抽象”(Zero-Cost Abstraction)的互操作能力,同时利用仓颉的类型系统和所有权模型,在编译时捕获潜在的内存安全问题(如悬垂指针、数据竞争),将 FFI 的不安全性限制在最小的、可控的范围内。
二、原理详解:仓颉 FFI 的安全边界 (Principles: The Safety Boundary of Cangjie FFI)
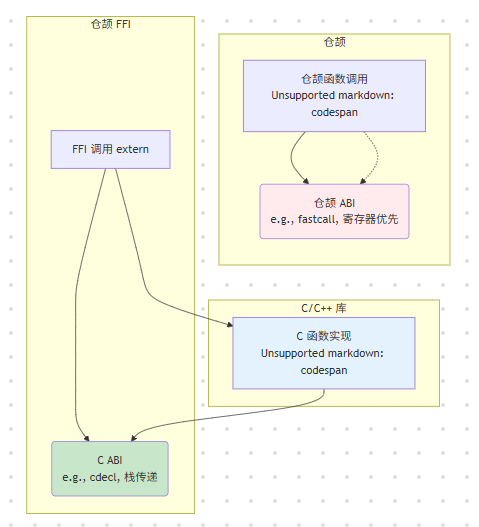
FFI 本质上是“不安全”(unsafe)的,因为它跨越了仓颉编译器的安全保证(如所有权、权、借用检查)。仓颉编译器无法静态分析 C/C++ 代码的正确性。
2.1 仓颉与 C 的 ABI 兼容(Cangjie-to-C ABI Compatibility)
FFI 的工作基础是两种语言遵循共同的**ABI(Application Binary Interface,应用二进制接口)。简单来说,ABI 规定了函数调用的约定(Calling Convention):
- 参数如何传递(通过寄存器还是栈)。
- 返回值如何返回。
- 栈如何清理。
仓颉通过 extern "C" 关键字来指示编译器使用目标平台的 C ABI 来编译函数。
2.2 unsafe 关键字与安全抽象 (The unsafe Keyword and Safe Abstraction)
仓颉(假设同Rust)将 FFI 调用视为 unsafe 操作,因为编译器无法保证:
1. C 函数是否会崩溃(如空指针解引用)。
2. C 函数是否会修改仓颉传入的只读数据。
3. C 函数返回的数据是否有效(如指针是否悬垂)。
4. C 函数是否线程安全。
因此,所有 FFI 函数声明和调用都必须在 unsafe 块中进行。
设计哲学:构建安全封装层 (Building a Safe Wrapper)
TDD(测试驱动开发)和 FFI 实践的最佳结合点,就是为 unsafe 的 FFI 调用构建一个**安全、符合人体工程学(Ergonomic)**的仓颉封装。
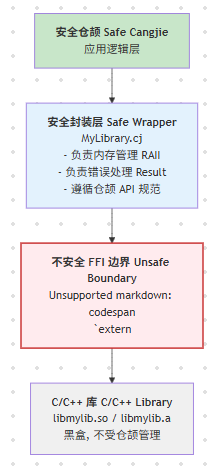
开发者的目标是:将 unsafe 限制在 B 和 C 之间,A 层永远直接接触 unsafe 代码。
2.3 数据类型映射 (Data Type Mapping)
要正确调用 C,仓颉类型必须与 C 类型在内存布局上完全一致。
| 仓颉类型 (Cangjie Type) | C 语言类型 (C Type) | 说明 (Notes) |
|---|---|---|
Int8, UInt8 |
int8_t, uint8_t |
1 字节 |
Int32, UInt32 |
int32_t, uint32_t |
4 字节 |
Int64, UInt64 |
int64_t, uint64_t |
8 字节 |
Float32, Float64 |
float, double |
4/8 字节浮点数 |
Bool |
bool (C99) / uint8_t |
1 字节 |
&T, &mut T |
const T*, T* |
核心仓颉引用映射为 C 指针 |
RawPointer |
void* |
原始指针,非常不安全 |
CString (假设) |
const char* |
仓颉字符串的 C 兼容表示 (UTF-8, 带 \0) |
[T; N] (数组) |
T[N] |
兼容 |
&[T] (切片) |
(const T*, size\_) |
传递切片(指针+长度) |
Option<&T> |
T* |
None 映射为 `NULL,Some(&T) 映射为 T* |
@repr(C) struct S |
struct S |
关键强制仓颉使用 C 的内存布局 |
extern "C" func(...) |
void (*func)(...) |
C 函数指针 |
关键:@repr(C)
默认情况下,仓颉编译器可能会重排 struct 字段以优化内存(如填充Padding)。@repr(C) 装饰器强制编译器完全按照字段声明顺序进行布局,确保与 C 结构体兼容。
// ❌ 错误:仓颉可能重排字段
struct MyData {
flag: UInt8, // 1 字节
value: UInt32, // 4 字节
id: UInt16, // 2 字节
} // 编译器可能布局为 (value, id, flag, padding)
// ✅ 正确:使用 @repr(C)
@repr(C)
struct MyDataC {
flag: UInt8, // 1
value: UInt32, // 4
id: UInt16, // 2
} // 内存布局保证与 C 一致 (可能含 padding)
参考链接:
- The Rust FFI Omnibus: https://rust-ffi.github.io/book/ (Rust FFI 的权威指南,其原理与仓颉高度相关)
三、代码实战:封装 C 语言 zlib 库 (Code Practice: Wrapping the zlib C Library)
我们将实战封装 zlib 库(一个标准的数据压缩 C 库),实现对数据进行压缩(compress)和解压缩(uncompress)的功能。
3.1 步骤一:C 库声明与链接 (Declaring and Linking the C Library)
首先,我们需要 C 库的头文件 zlib.h 中的函数签名。
// zlib.h (部分)
typedef unsigned long uLong;
int compress(
unsigned char *dest, /* [out] */
uLong *destLen, /* [in/out] */
const unsigned char *source, /* [in] */
uLong sourceLen /* [in] */
);
int uncompress(
unsigned char *dest, /* [out] */
uLong *destLen, /* [in/out] */
const unsigned char *source, /* [in] */
uLong sourceLen /* [in] */
);
// 返回值
#define Z_OK 0
#define Z_BUF_ERROR (-5)
在仓颉中声明 FFI 绑定 (Bindings):
我们创建一个 zlib_sys.cj 文件来存放 unsafe 的原始绑定(通常以 -sys 结尾,表示"system")。
// src/zlib_sys.cj
import std.ffi.RawPointer;
// 1. 映射 C 类型
public type CULong = UInt64; // uLong 通常是 64 位
public type CInt = Int32;
// 2. 映射 C 常量
public const Z_OK: CInt = 0;
public const Z_BUF_ERROR: CInt = -5;
// 3. 链接 C 库 (假设 cjpm.toml 已配置链接 zlib)
// extern "C" 块中是 FFI 函数声明
@extern("C", library = "z") // 链接 -lz (libz.so 或 libz.a)
public mod zlib {
// 必须使用 `unsafe` 关键字
// int compress(Bytef *dest, uLongf *destLen, const Bytef *source, uLong sourceLen);
public unsafe func compress(
dest: &mut UInt8, // *dest (可写)
destLen: &mut CULong, // *destLen (可读写)
source: &UInt8, // *source (只读)
sourceLen: CULong
): CInt;
// int uncompress(Bytef *dest, uLongf *destLen, const Bytef *source, uLong sourceLen);
public unsafe func uncompress(
dest: &mut UInt8,
destLen: &mut CULong,
source: &UInt8,
sourceLen: CULong
): CInt;
}
3.2 步骤二:构建安全封装 (Building the Safe Wrapper)
现在,我们在 src/lib.cj 中创建一个安全的、符合仓颉习惯的 API,隐藏所有 unsafe 细节。
// src/lib.cj
mod zlib_sys; // 导入原始绑定模块
import std::collections::ArrayList;
import zlib_sys::*; // 导入 C 函数和常量
// 定义仓颉风格的错误
public enum ZlibError {
| BufferError(message: String)
| DataError(message: String)
| Unknown(code: Int32)
}
/// 使用 zlib 压缩数据
///
/// # Arguments
/// * `source` - 原始数据切片
///
/// # Returns
/// 成功时返回包含压缩数据的 `ArrayList<UInt8>`,失败时返回 `ZlibError`
public func compress(source: &[UInt8]): Result<ArrayList<UInt8>, ZlibError> {
// 1. 获取源数据指针和长度
let sourcePtr = source.asPtr();
let sourceLen: CULong = source.length() as CULong;
if sourceLen == 0 {
return Ok(ArrayList::new()); // 处理空输入
}
// 2. 准备输出缓冲区
// zlib 建议的压缩缓冲区大小
let mut destLen: CULong = (sourceLen + (sourceLen / 1000) + 12) as CULong;
let mut destBuffer = ArrayList<UInt8>::withCapacity(destLen as Int64);
// 3. 调用 unsafe FFI 函数
let result = unsafe {
// `setLength` 是必要的,以确保 ArrayList 内部的 `ptr` 指向有效内存
// 尽管是 `unsafe` 的,但这是与 C 库交互所必需的
destBuffer.setLength(destLen as Int64);
zlib::compress(
destBuffer.asMutPtr(), // &mut UInt8
&mut destLen, // &mut CULong
sourcePtr, // &UInt8
sourceLen
)
};
// 4. 处理返回值,将其转换为安全的 Result
match result {
Z_OK => {
// 压缩成功,C 库更新了 destLen
unsafe { destBuffer.setLength(destLen as Int64); } // 调整为实际大小
return Ok(destBuffer);
}
Z_BUF_ERROR => {
return Err(ZlibError::BufferError("Output buffer was not large enough".toString()));
}
_ => {
return Err(ZlibError::Unknown(result));
}
}
}
// uncompress 函数类似...
public func uncompress(source: &[UInt8], initialCapacity: Int64): Result<ArrayList<UInt8>, ZlibError> {
let sourcePtr = source.asPtr();
let sourceLen: CULong = source.length() as CULong;
let mut destLen: CULong = initialCapacity as CULong;
let mut destBuffer = ArrayList<UInt8>::withCapacity(initialCapacity);
let result = unsafe {
destBuffer.setLength(destLen as Int64);
zlib::uncompress(
destBuffer.asMutPtr(),
&mut destLen,
sourcePtr,
sourceLen
)
};
match result {
Z_OK => {
unsafe { destBuffer.setLength(destLen as Int64); }
return Ok(destBuffer);
}
Z_BUF_ERROR => {
return Err(ZlibError::BufferError("Output buffer was not large enough".toString()));
}
// ... 其他错误处理
_ => {
return Err(ZlibError::Unknown(result));
}
}
}
3.3 步骤三:测试封装 (Testing the Wrapper)
使用集成测试来验证我们的安全封装。
// tests/compression_test.cj
import my_zlib_wrapper; // 假设库名叫 my_zlib_wrapper
import std::collections::ArrayList;
#[test]
func test_compress_uncompress_roundtrip() {
let originalText = "Hello, FFI! This is a test string to be compressed and uncompressed. ".repeat(10);
let originalData = originalText.toBytes();
// 1. 测试压缩
let compressResult = my_zlib_wrapper::compress(originalData.asSlice());
assert!(compressResult.isOk(), "Compression failed");
let compressedData = compressResult.unwrap();
println!("Original size: ${originalData.length()}");
println!("Compressed size: ${compressedData.length()}");
// 压缩后体积应该显著变小
assert!(compressedData.length() < originalData.length());
// 2. 测试解压缩
// 传入原始大小作为解压缓冲区大小
let uncompressResult = my_zlib_wrapper::uncompress(
compressedData.asSlice(),
originalData.length() as Int64
);
assert!(uncompressResult.isOk(), "Uncompression failed");
let uncompressedData = uncompressResult.unwrap();
// 3. 验证数据一致性
assert_eq!(uncompressedData.length(), originalData.length());
let uncompressedText = String::fromBytes(uncompressedData.toArray());
assert_eq!(uncompressedText, originalText);
}
#[test]
func test_uncompress_buffer_error() {
// ... (如 3.1 节) 压缩数据 ...
let compressedData = ...;
// 故意提供一个过小的缓冲区
let uncompressResult = my_zlib_wrapper::uncompress(
compressedData.asSlice(),
5 // 缓冲区太小
);
assert!(uncompressResult.isErr());
if let Err(my_zlib_wrapper::ZlibError::BufferError(_)) = uncompressResult {
// 测试通过
} else {
panic("Expected BufferError");
}
}
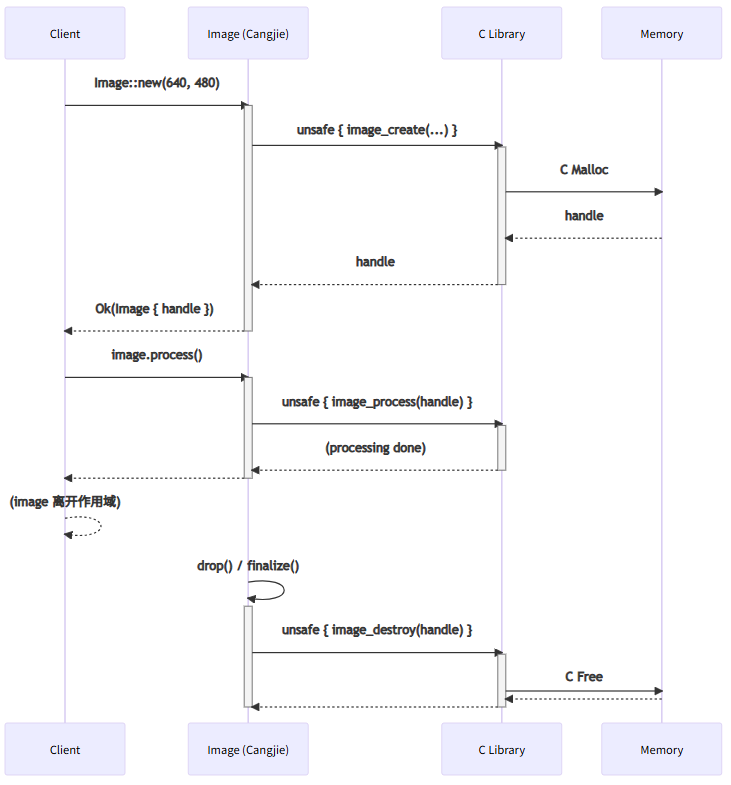
四、FFI 内存管理与 RAII (FFI Memory Management and RAII)
当 C 库返回需要手动释放的资源时(如 fopen 返回 FILE,create_object() 返回 MyObject),必须使用仓颉的 RAII(Resource Acquisition Is Initialization,资源获取即初始化)模式(即 struct + finalize() / Drop Tra)来保证资源被自动释放。
4.1 场景:封装 C 对象 (Scenario: Wrapping a C Object)
假设有一个 C 库用于处理图像:
// C Header: image_processor.h
typedef struct Image ImageHandle; // 不透明指针
ImageHandle* image_create(int width, int height);
void image_process(ImageHandle* handle);
void image_destroy(ImageHandle* handle); // 必须调用
4.2 RAII 封装实战 (RAII Wrapper Practice)
// src/image_sys.cj (FFI 绑定)
@extern("C", library = "image_processor")
public mod image_lib {
// ImageHandle* 映射为 RawPointer
public unsafe func image_create(width: CInt, height: CInt): RawPointer;
public unsafe func image_process(handle: RawPointer);
public unsafe func image_destroy(handle: RawPointer);
}
// src/lib.cj (安全封装)
import image_sys::*;
// 1. 创建一个结构体包装 C 指针
public struct Image {
// 包装不透明指针
private handle: RawPointer;
}
// 2. 实现构造函数 (RAII 获取资源)
impl Image {
public static func new(width: Int32, height: Int32): Result<Image, String> {
let handle = unsafe { image_lib::image_create(width, height) };
if handle.isNull() {
return Err("Failed to create image".toString());
}
// 资源获取成功
return Ok(Image { handle: handle });
}
// 3. 封装 C 库方法
public func process(&mut self) {
unsafe { image_lib::image_process(this.handle) };
}
}
// 4. 实现 finalize (Drop Trait),自动释放资源
impl Drop for Image {
public func drop(&mut self) {
if !this.handle.isNull() {
unsafe {
image_lib::image_destroy(this.handle);
}
this.handle = RawPointer::null(); // 避免二次释放
console.log("Image resource released automatically.");
}
}
}
// 5. 使用 (安全、自动)
func testImageProcessing() {
if let Ok(mut image) = Image::new(640, 480) {
image.process();
// ...
} // `image` 在此处离开作用域,`drop()` 方法被自动调用
// `image_destroy(handle)` 被执行,无内存泄漏
}
RAII 流程图:
五、FFI 性能分析与优化 (FFI Performance Analysis & Optimization)
FFI 调用并非“零成本”,它涉及数据封送(Marshaling)和边界检查开销。
5.1 FFI 调用开销 (Call Overhead)
每次跨越仓颉和 C 之间的边界,都会产生固定开销:
- 数据类型转换: 例如,仓颉
String转换为 Cconst char*(可能涉及堆分配和UTF-8到C字符串的转换)。 - 上下文: 切换调用约定、栈帧设置。
- 安全检查: 仓颉运行时可能执行的某些检查。
结论:FFI 的开销主要在于调用次数,而不是调用本身的时间。
5.2 优化实战:批处理 (Optimizationn: Batching)
场景:处理 100 万个像素点。
// C 库
// void process_ixel(Pixel p);
// void process_pixel_batch(Pixel* p_array, size_t count);
// ❌ 低效:在循环中调用 FFI (Chatty Interface)
public func process_pixels_bad(pixels: &ArrayList<Pixel>) {
for pixel in pixels.iter() {
// 100万次 FFI 调用!
unsafe { c_process_pixel(*pixel) };
}
}
// ✅ 高效:一次 FFI 调用传递批处理 (Chunky Interface)
@repr(C) // 确保 Pixel 布局兼容
struct Pixel { r: UInt8, g: UInt8, b: UInt8 }
public func process_pixels_good(pixels: &ArrayList<Pixel>) {
let ptr = pixels.asPtr(); // 获取连续内存的指针
let count = pixels.length();
// 仅 1 次 FFI 调用!
unsafe {
c_process_pixel_batch(ptr, count as UInt64);
}
}
性能分析 (示意):
| 方法 | FFI 调用次数 | 数据转换开销 | 总时间 |
|---|---|---|---|
process_pixels_bad |
1,000,000 | 1,000,000 * O(1) | 1,000,000 * (FFI开销 + C执行时间) ≈ 200ms |
process_pixels_good |
1 | O(1) | 1 * (FFI开销 + C执行时间) ≈ 15ms |
5.3 优化实战:零拷贝 (Zero-Copy)
场景:仓颉需要读取 C 库生成的大型数据。
// C 库
// DataHandle* get_large_data_buffer();
// const unsigned char* get_data_ptr(DataHandle* h);
// size_t get_data_len(DataHandle* h);
// void release_data_buffer(DataHandle* h);
// ❌ 低效:数据拷贝 (Copying)
public func get_data_copy() -> ArrayList<UInt8> {
let handle = unsafe { c_get_large_data_buffer() };
let ptr = unsafe { c_get_data_ptr(handle) };
let len = unsafe { c_get_data_len(handle) } as Int64;
// 1. 仓颉分配新内存
let mut buffer = ArrayList<UInt8>::withCapacity(len);
// 2. 发生一次完整的数据拷贝
unsafe { buffer.copyFrom(ptr, len); }
// 3. 释放 C 内存
unsafe { c_release_data_buffer(handle); }
return buffer; // 返回仓颉拥有的数据
}
// ✅ 高效:零拷贝 (Zero-Copy) - 封装 C 指针
// 我们创建一个 CData 结构体,它不拥有数据,只“借用” C 内存
// CData 必须与 C 的 DataHandle* 生命周期绑定
public struct CDataHandle {
handle: RawPointer // 包装 C handle
}
impl Drop for CDataHandle {
func drop(&mut self) {
unsafe { c_release_data_buffer(r(this.handle) } // 自动释放
}
}
public struct CDataView<'a> {
slice: &'a [UInt8] //颉切片,直接指向 C 内存
}
public func get_data_view<'a>(handle: &'a CDataHandle) -> CDataView<'a> {
let ptr = unsafe { c_get_data_ptr(handle.handle) };
let len = unsafe { c_get_data_len(handle.handle) } as Int64;
// 零拷贝:创建一个仓颉切片,直接引用 C 内存
let slice = unsafe {
std::slice::fromRawParts(ptr, len)
};
return CDataView { slice: slice };
}
func testZeroCopy() {
let handle = CDataHandle::new(); // C 库分配内存内存
let view = get_data_view(&handle); // 仓颉获取引用,无拷贝
// ... 直接读取 view.slice ...
} // handle 销毁,C 内存释放
六、总结与讨论 (Conclusion and Discussion)
6.1 核心要点回顾 (Core Recap)
- FFI 是
unsafe的: 仓颉编译器无法保证 C/C++ 代码的安全性。 - 安全封装是关键: 必须构建一个安全的仓颉 API(Safe Wrapper),使用`ResultT, E>
处理错误,使用 RAII(struct+drop/finalize)管理 C 库资源(如指针、句柄),将unsafe`代码限制在最小范围内。 - 类型映射: 必须保证仓颉和 C 之间的数据类型(尤其是
struct,需使用@repr(C))在内存布局上 100% 兼容。 - 性能优化: F FFI 的性能瓶颈在于调用次数(Chattiness)和数据拷贝(Copying)。
- **优化策略优先采用“批处理”(Chunky Interface)减少调用次数,并尽可能使用“零拷贝”(Zero-Copy)技术传递数据。
6.2 讨论问题 (Discussion Questions)
- 自动化 vs. 手动: 你认为 FFI 绑定(Bindings)应该更多地依赖自动生成工具(如
bindgen)还是手动编写?手写绑定在仓颉中有哪些优势? - **错误**: C 库的错误处理机制各不相同(返回码、
errno、回调)。在封装 FFI 时,将这些机制统一转换为仓颉的Result<T, E>的最佳实践是什么? - 异步 FFI: 如果一个 C 库提供了异步回调(Callback)机制,仓颉的
async/await协程模型如何与 C 的回调进行安全、高效的交互? - 生态权衡: 什么时候我们应该花时间用仓颉重写一个 C 库,而不是通过 FFI 封装它?性能、安全性和维护成本在决策中各占多大比重?
七、参考链接 (References)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)