langchain4j-(3)-模型参数配置
LangChain4j 提供了灵活的模型参数配置方式,允许你根据不同的 AI 模型(如 OpenAI、GPT-4、Anthropic 等)设置各种参数来控制生成结果。
后面手撸代码继续在之前章节的代码上拓展
一、日志配置(Logging)
在 LangChain4j 中,日志(logging)相关参数主要用于控制是否记录模型的请求和响应信息,这对于开发调试、监控 API 调用内容以及排查问题非常有用。
将日志级别调整为debug级别,同时配置上langchain日志输出开关才能有效。
step1:修改LLMConfig类
package com.xxx.demo.config;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class LLMConfig {
@Bean(name = "qwen")
public ChatModel chatModelQwen()
{
return OpenAiChatModel.builder()
.apiKey(System.getenv("aliqwen-apikey"))
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.logRequests(true) // 日志界别设置为debug才有效
.logResponses(true)// 日志界别设置为debug才有效
.build();
}
}step2:修改YML文件
server.port=9005
spring.application.name=langchain4j-0301-parameters
# 只有日志级别调整为debug级别,同时配置以上 langchain 日志输出开关才有效
logging.level.dev.langchain4j = DEBUG step3:在控制台检查结果
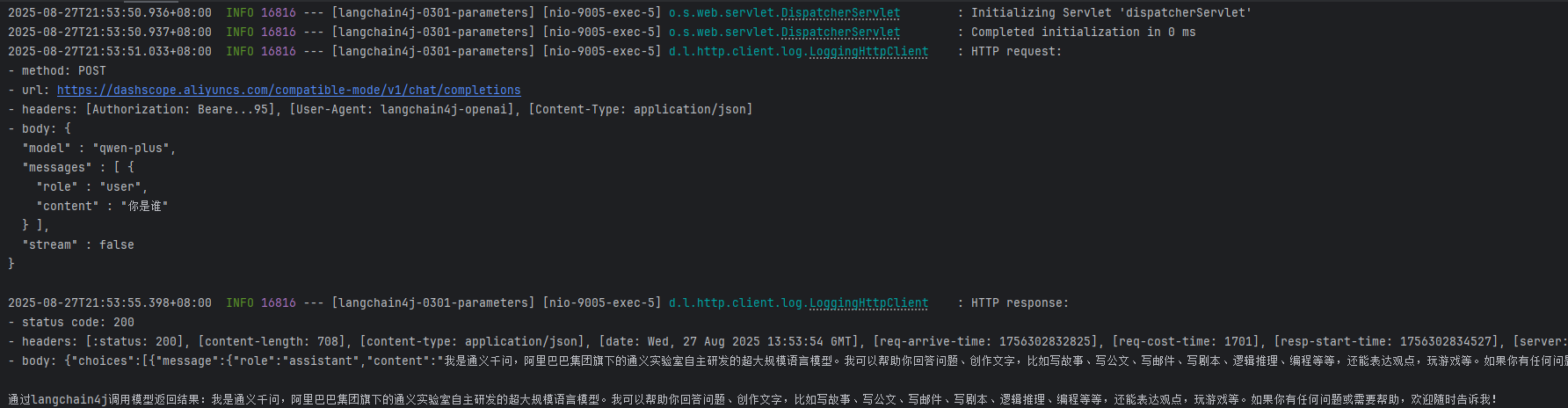
二、监控(Observability)
LangChain4j 的 Observability(可观测性)配置主要涉及日志记录、指标监控及链路追踪等方面
step1:先实现ChatModelListener
package com.xxx.demo.listener;
import cn.hutool.core.util.IdUtil;
import dev.langchain4j.model.chat.listener.ChatModelErrorContext;
import dev.langchain4j.model.chat.listener.ChatModelListener;
import dev.langchain4j.model.chat.listener.ChatModelRequestContext;
import dev.langchain4j.model.chat.listener.ChatModelResponseContext;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class TestModeLlistener implements ChatModelListener {
@Override
public void onRequest(ChatModelRequestContext requestContext)
{
// onRequest配置的k:v键值对,在onResponse阶段可以获得,上下文传递参数好用
String uuidValue = IdUtil.simpleUUID();
requestContext.attributes().put("TraceID",uuidValue);
log.info("请求参数requestContext:{}", requestContext+"\t"+uuidValue);
}
@Override
public void onResponse(ChatModelResponseContext responseContext)
{
Object object = responseContext.attributes().get("TraceID");
log.info("返回结果responseContext:{}", object);
}
@Override
public void onError(ChatModelErrorContext errorContext)
{
log.error("请求异常ChatModelErrorContext:{}", errorContext);
}
}step2:再次拓展LLMConfig类
package com.xxx.demo.config;
import com.bbchat.demo.listener.TestModeLlistener;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
@Configuration
public class LLMConfig {
@Bean(name = "qwen")
public ChatModel chatModelQwen()
{
return OpenAiChatModel.builder()
.apiKey(System.getenv("aliqwen-apikey"))
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.logRequests(true) // 日志界别设置为debug才有效
.logResponses(true)// 日志界别设置为debug才有效
.listeners(List.of(new TestModeLlistener())) //监听器
.build();
}
}step3:验证结果
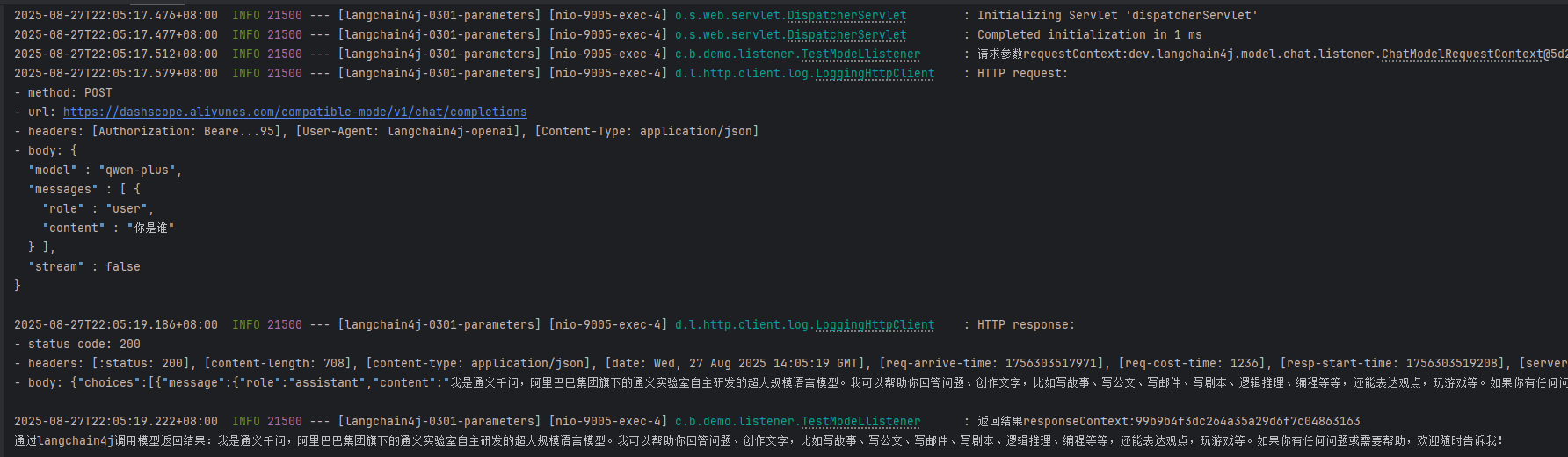
三、重试机制(Retry Configuration)
在 LangChain4j 中配置重试机制,核心是通过 RetryAssistant(重试助手)或结合底层依赖(如 OkHttp、Resilience4j 等)实现,用于解决 LLM 调用过程中的网络波动、API 限流、临时服务不可用等问题。下面代码简单做展示一下效果,更加详细的配置请大家看官网查API。
再次拓展LLMConfig
package com.xxx.demo.config;
import com.bbchat.demo.listener.TestModeLlistener;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
@Configuration
public class LLMConfig {
@Bean(name = "qwen")
public ChatModel chatModelQwen()
{
return OpenAiChatModel.builder()
.apiKey(System.getenv("aliqwen-apikey"))
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.logRequests(true) // 日志界别设置为debug才有效
.logResponses(true)// 日志界别设置为debug才有效
.listeners(List.of(new TestModeLlistener())) //监听器
.maxRetries(2)// 重试机制共计2次
.build();
}
}四、超时机制(timeout)
继续拓展LLMConfig
package com.xxx.demo.config;
import com.bbchat.demo.listener.TestModeLlistener;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.time.Duration;
import java.util.List;
@Configuration
public class LLMConfig {
@Bean(name = "qwen")
public ChatModel chatModelQwen()
{
return OpenAiChatModel.builder()
.apiKey(System.getenv("aliqwen-apikey"))
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.logRequests(true) // 日志界别设置为debug才有效
.logResponses(true)// 日志界别设置为debug才有效
.listeners(List.of(new TestModeLlistener())) //监听器
.maxRetries(2)// 重试机制共计2次
.timeout(Duration.ofSeconds(2))//向大模型发送请求,2s没有响应将中断请求并提示reqquest time out
.build();
}
}找一个大模型思考肯定超过2s问题测试一下即可见效果
五、流式输出(Response Streaming)
流式输出(StreamingOutput)是一种逐步返回大模型生成结果的技术,生成一点返回一点,允许服务器将响应内容。分批次实时传输给客户端,而不是等待全部内容生成完毕后再一次性返回。
这种机制能显著提升用户体验,尤其适用于大模型响应较慢的场景(如生成长文本或复杂推理结果)
step1:修改一下我们的pom文件,确认下langchain4j原生maven坐标三件套
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
</dependency>step2:修改下yml文件
server.port=9005
spring.application.name=langchain4j-0301-parameters
# 只有日志级别调整为debug级别,同时配置以上 langchain 日志输出开关才有效
logging.level.dev.langchain4j = DEBUG
# 设置响应的字符编码,避免流式返回输出乱码
server.servlet.encoding.charset=utf-8
server.servlet.encoding.enabled=true
server.servlet.encoding.force=truestep3:ChatAssistant接口
package com.xxx.demo.service;
import reactor.core.publisher.Flux;
public interface ChatAssistant {
String chat(String prompt);
Flux<String> chatFlux(String prompt);
}step4:重写LLMConfig
package com.xxx.demo.config;
import com.bbchat.demo.listener.TestModeLlistener;
import com.bbchat.demo.service.ChatAssistant;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.chat.StreamingChatModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.model.openai.OpenAiStreamingChatModel;
import dev.langchain4j.service.AiServices;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
@Configuration
public class LLMConfig {
/*
普通对话接口
*/
@Bean(name = "qwen")
public ChatModel chatModelQwen()
{
return OpenAiChatModel.builder()
.apiKey(System.getenv("aliqwen-apikey"))
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.logRequests(true) // 日志界别设置为debug才有效
.logResponses(true)// 日志界别设置为debug才有效
.listeners(List.of(new TestModeLlistener())) //监听器
// .maxRetries(2)// 重试机制共计2次
// .timeout(Duration.ofSeconds(2))//向大模型发送请求,2s没有响应将中断请求并提示reqquest time out
.build();
}
/*
流式对话接口
*/
@Bean
public StreamingChatModel streamingChatModel(){
return OpenAiStreamingChatModel.builder()
.apiKey(System.getenv("aliqwen-apikey"))
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
}
@Bean
public ChatAssistant chatAssistant(StreamingChatModel streamingChatModel){
return AiServices.create(ChatAssistant.class, streamingChatModel);
}
}step5:写一个新的controller,分别调用一下就能体验流式输出了。
|
接口地址 |
核心逻辑 |
返回类型 |
适用场景 |
|---|---|---|---|
|
|
直接调用 |
|
前端需要流式接收文本(如 SSE) |
|
|
直接调用 |
|
后端调试(无前端交互) |
|
|
调用自定义 |
|
高内聚场景(业务逻辑封装) |
package com.xxx.demo.controller;
import com.bbchat.demo.service.ChatAssistant;
import dev.langchain4j.model.chat.StreamingChatModel;
import dev.langchain4j.model.chat.response.ChatResponse;
import dev.langchain4j.model.chat.response.StreamingChatResponseHandler;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
@Slf4j
public class StreamingChatModelController {
@Resource //直接使用 low-level LLM API
private StreamingChatModel streamingChatLanguageModel;
@Resource //自己封装接口使用 high-level LLM API
private ChatAssistant chatAssistant;
// http://localhost:9005/chatstream/chat?prompt=天津有什么好吃的
@GetMapping(value = "/chatstream/chat")
public Flux<String> chat(@RequestParam("prompt") String prompt)
{
return Flux.create(stringFluxSink -> {
streamingChatLanguageModel.chat(prompt, new StreamingChatResponseHandler()
{
@Override
public void onPartialResponse(String s)
{
stringFluxSink.next(s);
}
@Override
public void onCompleteResponse(ChatResponse completeResponse)
{
stringFluxSink.complete();
}
@Override
public void onError(Throwable throwable)
{
stringFluxSink.error(throwable);
}
});
});
}
@GetMapping(value = "/chatstream/chat2")
public void chat2(@RequestParam(value = "prompt", defaultValue = "北京有什么好吃") String prompt)
{
System.out.println("---come in chat2");
streamingChatLanguageModel.chat(prompt, new StreamingChatResponseHandler()
{
@Override
public void onPartialResponse(String partialResponse)
{
System.out.println(partialResponse);
}
@Override
public void onCompleteResponse(ChatResponse completeResponse)
{
System.out.println("---response over: "+completeResponse);
}
@Override
public void onError(Throwable throwable)
{
throwable.printStackTrace();
}
});
}
@GetMapping(value = "/chatstream/chat3")
public Flux<String> chat3(@RequestParam(value = "prompt", defaultValue = "南京有什么好吃") String prompt)
{
System.out.println("---come in chat3");
return chatAssistant.chatFlux(prompt);
}
}
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)