大模型推理提速 | 什么是大模型的注意力机制?Flash Attention内存优化和MQA/GQA加速推理
在开始优化之前,我们先用一个生活化的例子理解注意力机制。假设你在嘈杂的咖啡厅里和朋友聊天。你的大脑会自动专注朋友的声音(关注重要信息),过滤掉背景音乐和其他对话(忽略不重要信息),结合聊天的情况动态调整话题(注意力动态分配)。大模型的注意力机制本质上在做同样的事情。在处理一句话时,决定应该关注哪些词,忽略哪些词。但是传统的注意力机制有一个致命缺陷,二次方复杂度,即O(n²)的性能噩梦。让我们用数字
当你向ChatGPT提问时,是否好奇过它为什么能在几秒内处理成千上万个单词,并给出连贯的回答?这背后的秘密就藏在注意力机制的性能优化中。
想象一下,如果你是一个同时处理1000个学生作业的老师,传统方法需要你逐一对比每个学生与其他所有学生的答案——这意味着要进行100万次比较!但聪明的老师会想出更高效的方法,这就是我们今天要揭秘的故事。
一、传统注意力的内存和速度问题
1. 什么是大模型的注意力机制?
在开始优化之前,我们先用一个生活化的例子理解注意力机制。
假设你在嘈杂的咖啡厅里和朋友聊天。你的大脑会自动专注朋友的声音(关注重要信息),过滤掉背景音乐和其他对话(忽略不重要信息),结合聊天的情况动态调整话题(注意力动态分配)。
大模型的注意力机制本质上在做同样的事情。在处理一句话时,决定应该关注哪些词,忽略哪些词。
但是传统的注意力机制有一个致命缺陷,二次方复杂度,即O(n²)的性能噩梦。
让我们用数字说话感受下二次方复杂度。
- 100个词的句子:需要 100² = 10,000 次计算
- 1,000个词的文章:需要 1,000² = 1,000,000 次计算
- 10,000个词的长文档:需要 10,000² = 100,000,000 次计算
这就像是一个班级里每个学生都要和其他所有学生握手一样,人数越多,握手次数呈指数级增长。
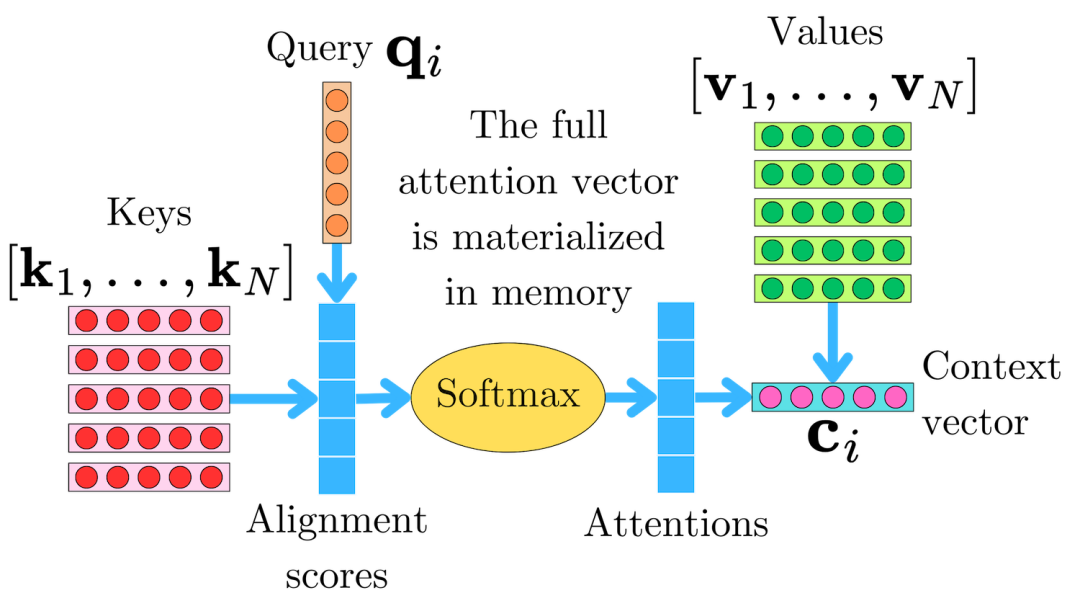
2. 注意力机制O(n²) 复杂度会带来什么问题?
How To Construct Self-Attention Mechanisms For Arbitrary Long Sequences
(1)首先是计算速度灾难。 短句子(50个词)可能0.01秒就处理完成,但长文章(2,000个词)可能需要几分钟,超长文档(10,000个词)可能需要几小时甚至处理不了。
(2)其次是内存消耗爆炸。 100个词需要记住10,000个关系大约消耗20MB内存,2,000个词需要记住4,000,000个关系消耗约8GB内存,4,000个词需要记住16,000,000个关系消耗约32GB内存。这就是为什么你的电脑处理长文档时会卡死!
内存使用量 = 序列长度² × 隐藏维度 × 精度字节数
一个2048长度的序列,在fp16精度下就需要:
2048² × 1024 × 2 字节 ≈ 8.6GB 内存!
(3)然后是成本飙升。 以ChatGPT为例,处理100个词成本1美分,处理1,000个词成本不是10美分而是1美元(100倍增长),处理10,000个词成本达到100美元(10,000倍增长)!这就是为什么很多AI服务对输入长度有严格限制。
(4)最后是现实的硬件限制。 一张高端显卡(RTX 4090)只有24GB显存,处理4,000个词的文档就可能用完所有显存,想处理10,000个词需要几十张显卡并行工作。所以你看到GPT-3.5最多处理4,000个词(约3页纸),GPT-4最多处理8,000-32,000个词。
用户体验直接受影响, 等待时间长,费用昂贵,经常报错超出长度限制,即使能处理长文档理解质量也会下降。
这就是为什么急需优化注意力机制!
二、Flash Attention内存优化和MQA/GQA加速推理
1. 大模型的Flash Attention如何进行内存优化?
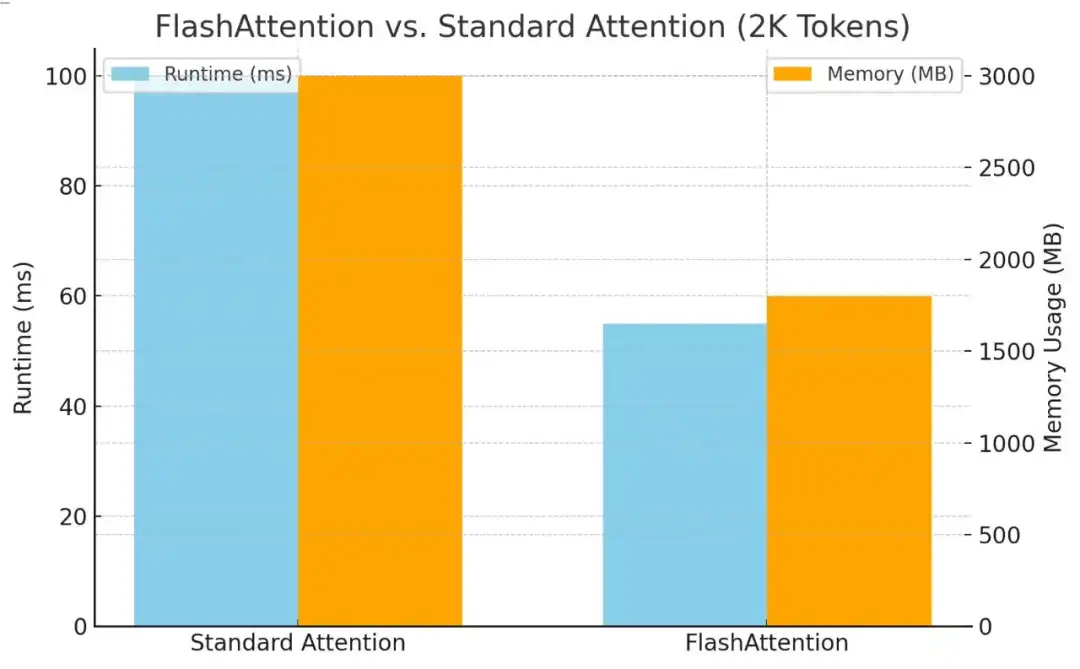
Flash Attention是一种优化大模型注意力机制的算法,通过分块计算的方式解决了传统注意力在处理长序列时内存需求爆炸的问题。它将原本需要同时处理的大矩阵分解为小块逐一计算,使内存使用从平方级别降为线性级别。
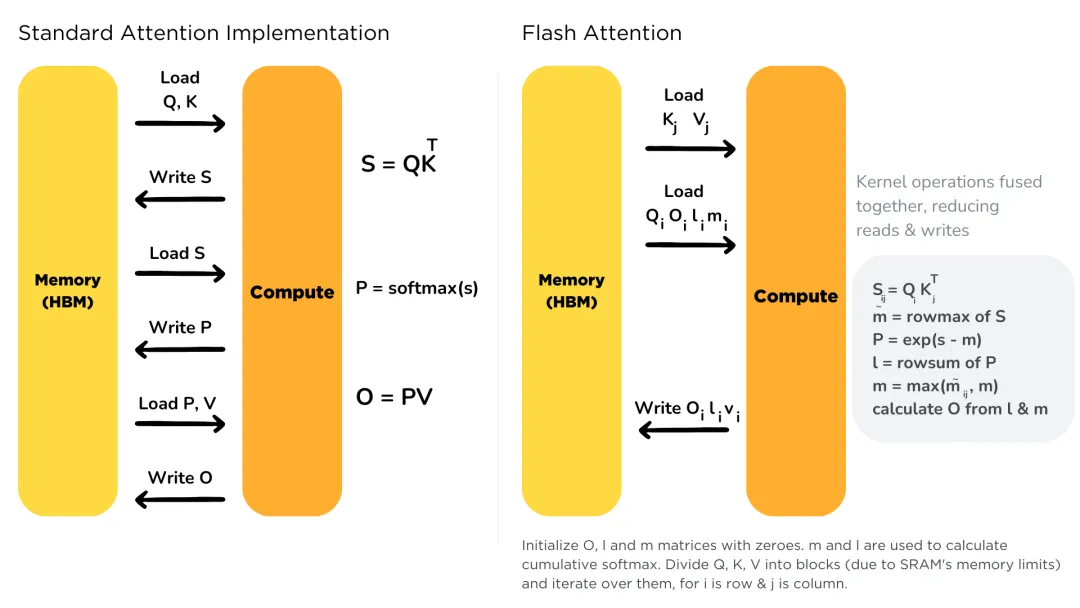
回到开篇,老师需要同时批改1000个学生作业。
(1)传统方法(标准注意力):需要把1000份作业摊在桌子上同时进行比较,这时没有足够大的桌子满足需求,可能需要租个体育馆。
这时传统注意力需要将整个注意力矩阵加载到GPU内存中,对于长序列,内存需求爆炸式增长,导致大量时间浪费在内存读写上。
(2)Flash Attention方法:每次只需要拿10份作业到桌子上,处理完这10份,再拿下一批,这时候用普通办公桌就够了。
而Flash Attention进行创新,通过分块处理将大的注意力计算分解为小块,每次只处理一小部分,边计算边更新结果,这样就不需要存储完整的注意力矩阵。
2. 大模型的MQA/GQA如何实现推理加速?
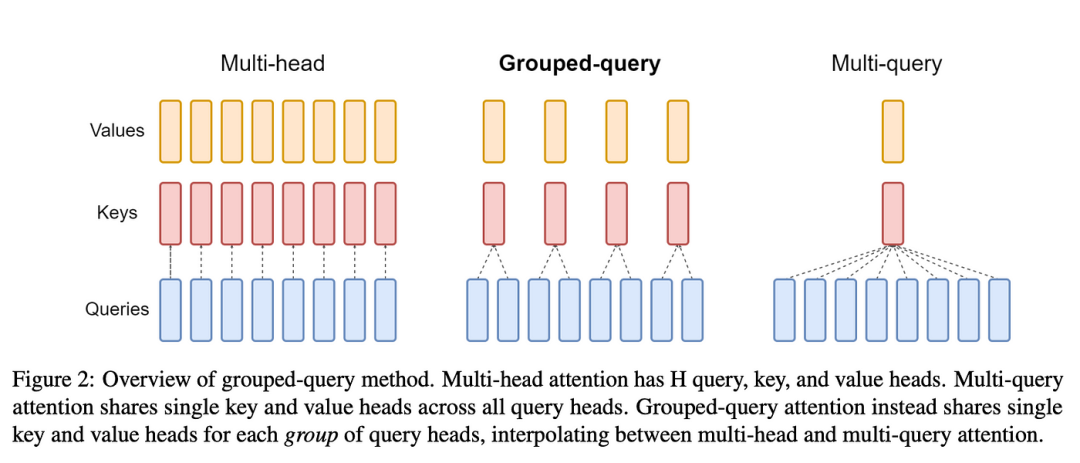
MQA(多查询注意力)和GQA(分组查询注意力)是两种优化大模型推理速度的技术。它们通过让多个注意力头共享Key-Value矩阵的方式,大幅减少内存使用和计算量,从而实现推理加速。MQA让所有头共享KV,GQA则采用分组共享的策略。
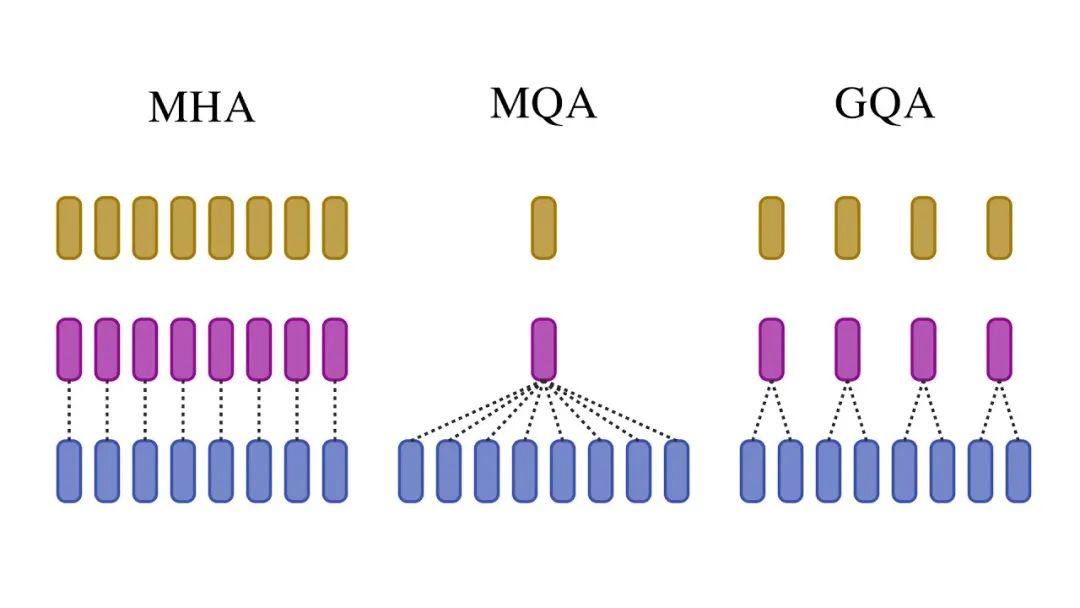
想象一下,图书馆里有8个读者需要查找资料。
(1)传统多头注意力(MHA)方法:8个读者,每人都要一份完整的图书目录和索引,需要8套完整资料,占用大量存储空间。
这时传统MHA为每个注意力头都维护独立的Query、Key、Value矩阵,内存消耗随头数线性增长,在推理时需要为所有头分别计算和存储KV对。
(2)多查询注意力(MQA)方法:8个读者共享一份图书目录和索引,每人只保留自己的查询记录,存储需求大幅减少。
而MQA进行创新,所有注意力头共享同一套Key-Value矩阵,只有Query矩阵独立维护。
(3)分组查询注意力(GQA):将8个读者分成2-3组,每组共享一套资料,既节省存储又保持一定的多样性。
GQA将多个Query头分组,每组共享一套Key-Value矩阵,在MHA和MQA之间找到最佳平衡点,既减少了内存使用,又保持了较好的模型质量。实际测试中,MQA推理速度提升1.3-1.8倍,GQA提升1.2-1.5倍但质量损失更小。
Value矩阵,在MHA和MQA之间找到最佳平衡点,既减少了内存使用,又保持了较好的模型质量。实际测试中,MQA推理速度提升1.3-1.8倍,GQA提升1.2-1.5倍但质量损失更小。
三、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献146条内容
已为社区贡献146条内容

所有评论(0)