arXiv 2025 | 告别训练成本!西安交大提出D3:无监督识别AI视频,准确率超98%!
本文直面当前 AI 生成视频检测器在泛化性、可解释性和效率方面的挑战。受物理世界基本运动定律的启发,本文提出了一种全新的、免训练的检测器 D3。D3 的核心思想是,真实视频和 AI 生成视频在二阶时序动态上存在本质差异。通过量化这种差异的波动性,D3 能够高效且准确地识别出 AI 的不自然平滑伪影。
本文介绍西安交通大学等机构的最新研究成果。该研究提出了 D3 ——Detection by Difference of Differences,一种创新的免训练检测方法,它利用二阶时序特征来区分真实视频和 AI 生成视频。
与依赖大规模数据训练的传统方法不同,D3 基于一个物理学洞察:真实世界物体的运动及其在特征空间中的表示在加速度层面具有更高的复杂性和波动性,而 AI 生成的视频则倾向于产生过于平滑的运动轨迹。D3 通过计算特征的二阶差分的波动性,有效地捕捉了这一根本差异,从而实现了对 AI 视频的精准检测。实验表明,D3 在四个主流基准数据集上超越了现有技术,表现出卓越的泛化能力和计算效率。
另外,我整理了CV入门必读资料包+CVPR 2020-2025论文合集,感兴趣的可以自取,希望能帮到你!

【论文标题】D3: Training-Free AI-Generated Video Detection Using Second-Order Features
【论文链接】https://arxiv.org/abs/2508.00701
【代码链接】https://github.com/Zig-HS/D3
研究背景
随着 Sora 等先进视频生成技术的发展,高保真 AI 视频的制作变得空前简单,引发了公众对虚假信息传播的广泛担忧。然而,现有的检测方法大多依赖深度学习框架,通过在大量真假视频上进行训练来学习区分特征。
这些方法存在一些固有局限性:1) 泛化能力差:对于训练集中未出现过的新型生成模型,检测性能会显著下降。2) 缺乏可解释性:深度模型通常像一个黑箱,其决策依据不够明确,难以提供令人信服的解释。3) 训练成本高:需要收集和标注大规模数据集,训练过程耗时耗力。研究发现,现有方法对视频中的时序伪影探索不足,特别是未能从更根本的物理或动态规律层面分析其差异。
为了解决这些问题,本文从牛顿力学中的二阶动态系统汲取灵感,提出了一个全新的、免训练的检测范式。
核心贡献
本研究贡献可总结如下:
- 提出全新理论视角:创新性地引入牛顿力学思想,将视频内容的时序变化类比为物理运动,并提出真实视频与 AI 视频在二阶动态特征上存在根本性差异。
- 设计免训练检测器 D3:基于上述理论,提出了一种名为 D3 (Detection by Difference of Differences) 的检测方法。它通过计算二阶中心差分特征的波动性来量化视频的“自然程度”,完全无需训练。
- 实现SOTA性能:在 GenVideo、VideoPhy、EvalCrafter、VidProM 四个大型公开数据集上的大量实验证明,D3 的泛化性能和鲁棒性均超越了现有的先进方法,并且计算效率极高。
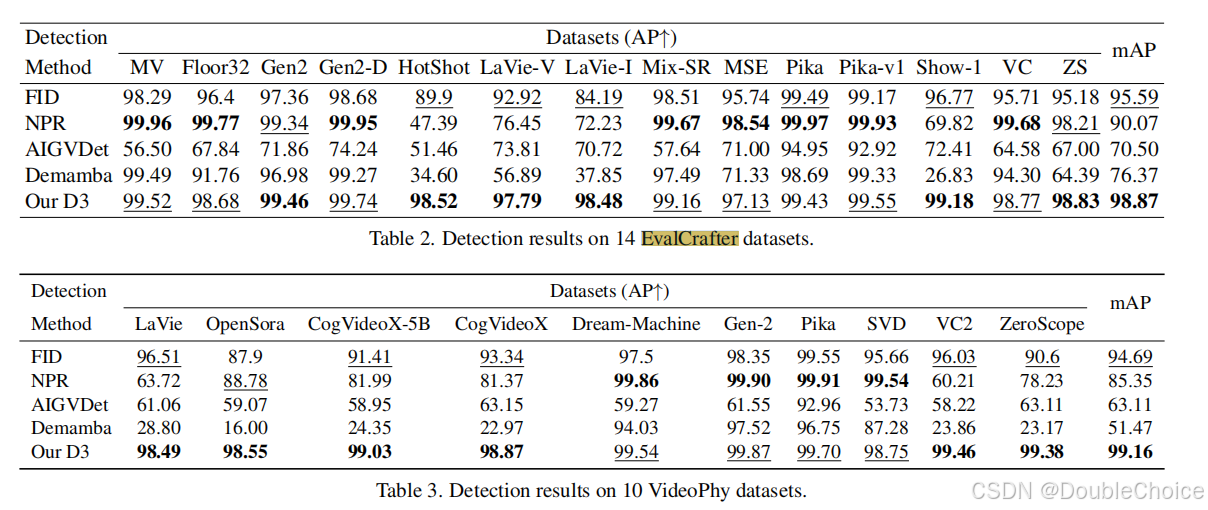
方法解析
图为 D3 方法的整体框架。该框架无需任何训练,仅通过一个简单的推理流程即可完成检测。它主要包括三个步骤:零阶特征提取、一阶特征计算和二阶特征计算与量化。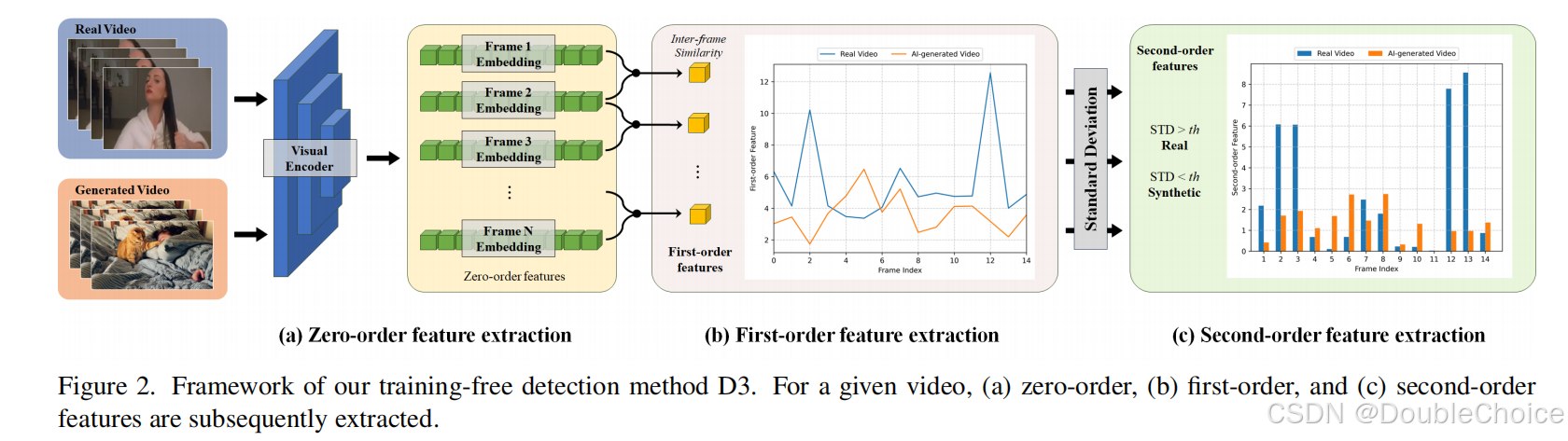
1. 零阶特征提取
首先,使用一个预训练的视觉编码器逐帧提取输入视频的特征。这一步将视频的像素内容转换成高维度的特征向量序列 F 0 = { F 1 , F 2 , . . . , F T } F_0 = \{F_1, F_2, ..., F_T\} F0={F1,F2,...,FT}。这些特征被称为零阶特征,可以看作是视频在每一时刻的位置快照。
2. 一阶特征计算
计算相邻帧特征之间的差异,以得到一阶特征。这通常通过计算连续特征向量 F k F_k Fk 和 F k + 1 F_{k+1} Fk+1 之间的 L2 距离或余弦相似度来实现。这一步得到的一阶特征序列可以类比为视频内容的“速度”,反映了内容随时间的变化率。
F 1 ( k ) = d i s ( F k , F k + 1 ) Δ t F_1(k) = \frac{dis(F_k, F_{k+1})}{\Delta t} F1(k)=Δtdis(Fk,Fk+1)
3. 二阶特征计算与量化
这是 D3 方法的核心。作者使用二阶中心差分公式来近似计算一阶特征的变化率,从而得到二阶特征,这可以类比为视频内容的加速度。
F 2 ( k ) = F 1 ( k ) − F 1 ( k − 1 ) Δ t F_2(k) = \frac{F_1(k) - F_1(k-1)}{\Delta t} F2(k)=ΔtF1(k)−F1(k−1)
根据物理直觉,真实视频的“加速度”曲线波动更剧烈、更混乱,而 AI 生成视频则更平坦、更规律。
最后,通过计算这个二阶特征序列的标准差来量化其波动性。
σ ( F 2 ) = 1 T − 3 ∑ i = 2 T − 1 ( F 2 ( i ) − F 2 ‾ ) 2 \sigma(F_2) = \sqrt{\frac{1}{T-3} \sum_{i=2}^{T-1} (F_2(i) - \overline{F_2})^2} σ(F2)=T−31i=2∑T−1(F2(i)−F2)2
这个标准差值 σ ( F 2 ) \sigma(F_2) σ(F2) 就是最终的检测分数。设置一个简单的阈值,即可判断视频是真实的还是 AI 生成的。
实验验证
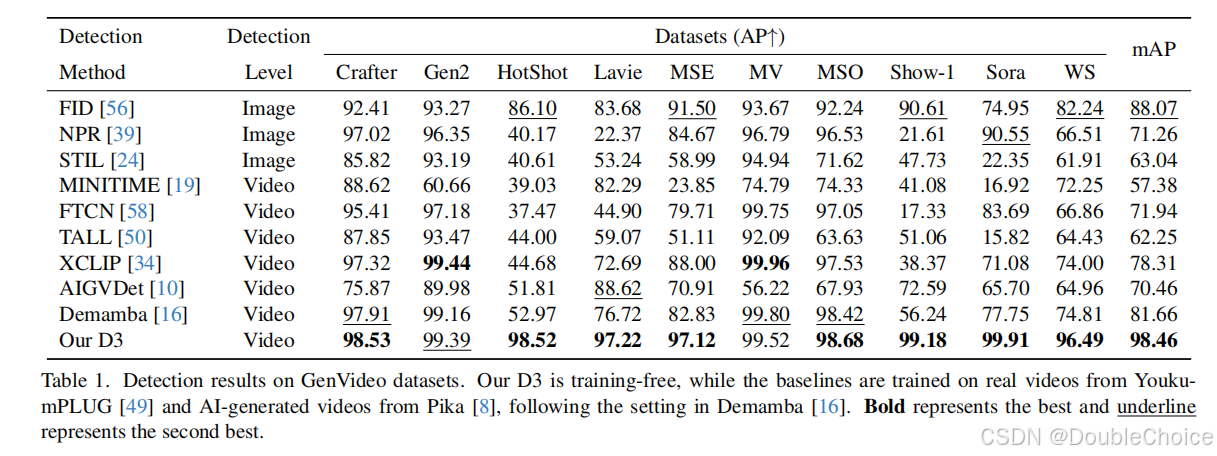
D3 在 GenVideo 数据集上取得了全面领先的性能,mAP达到 98.46%,显著超越了包括 DeMamba和 FID在内的所有基线方法。值得注意的是,D3 是完全免训练的,而其他基线方法大多需要在大规模数据上进行训练。
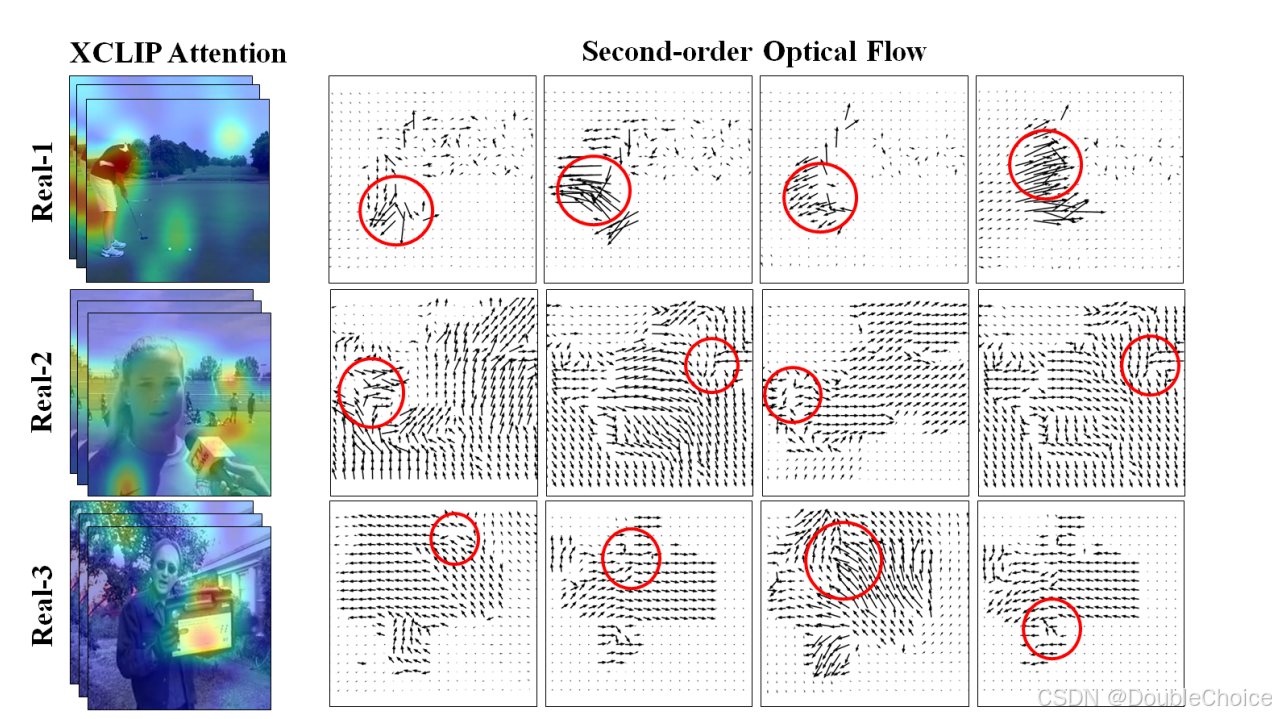
此外,D3 在计算效率上优势明显。D3 无需训练,其推理时间主要来自特征提取,在 XCLIP-B/16 主干上处理 1000 个视频样本仅需 56 秒,远低于需要训练和复杂推理的同类方法。这种高效性使其非常适合在资源受限的场景下进行大规模部署。在另外三个更具挑战性的数据集上,D3 同样展现了其强大的泛化能力和鲁棒性。
总结
本文直面当前 AI 生成视频检测器在泛化性、可解释性和效率方面的挑战。受物理世界基本运动定律的启发,本文提出了一种全新的、免训练的检测器 D3。D3 的核心思想是,真实视频和 AI 生成视频在二阶时序动态上存在本质差异。通过量化这种差异的波动性,D3 能够高效且准确地识别出 AI 的不自然平滑伪影。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)