强化学习笔记(二):有限马尔可夫决策过程(二)
这段笔记系统地阐述了强化学习中的最优策略与最优价值函数的核心理论,围绕“智能体如何通过与环境交互来最大化长期累积奖励”这一目标展开。它首先定义了策略的优劣关系和最优策略 π的存在性,引入了最优状态价值函数 v (s) 和最优动作价值函数 q (s,a) ,并推导出它们必须满足的贝尔曼最优方程,揭示了最优价值的递归结构。
最优策略与最优价值函数
解决一个强化学习任务,本质上是找到一种能在长期运行中最大化累积奖励的策略。
对于有限 MDP,价值函数在策略之间定义了一种偏序关系,若策略 π\piπ 在所有状态下的期望回报都不小于另一策略 π′\pi'π′,即vπ(s)≥vπ′(s),∀s∈Sv_\pi(s) \geq v_{\pi'}(s), \quad \forall s \in \mathcal{S}vπ(s)≥vπ′(s),∀s∈S,则称 π\piπ 优于或等于 π′\pi'π′,记作 π≥π′\pi \geq \pi'π≥π′。同时总存在至少一个策略,它优于或等于所有其他策略,这样的策略称为最优策略,记为 π∗\pi_*π∗。可能存在多个最优策略,但它们都具有相同的长期性能。
所有最优策略共享同一个状态价值函数,称为最优状态价值函数:
v∗(s)≐maxπvπ(s),∀s∈S(3.15) v_*(s) \doteq \max_{\pi} v_{\pi}(s), \quad \forall s \in \mathcal{S} \tag{3.15} v∗(s)≐πmaxvπ(s),∀s∈S(3.15)
v∗(s)v_*(s)v∗(s) 表示从状态 sss 出发,遵循某个最优策略所能获得的最大期望回报。
所有最优策略共享同一个动作价值函数,称为最优动作价值函数:
q∗(s,a)≐maxπqπ(s,a),∀s∈S,a∈A(s)(3.16) q_*(s, a) \doteq \max_{\pi} q_{\pi}(s, a), \quad \forall s \in \mathcal{S}, a \in \mathcal{A}(s) \tag{3.16} q∗(s,a)≐πmaxqπ(s,a),∀s∈S,a∈A(s)(3.16)
q∗(s,a)q_*(s,a)q∗(s,a) 表示在状态 sss 执行动作 aaa 后,再遵循某个最优策略所能获得的最大期望回报。
q∗(s,a)=E[Rt+1+γv∗(St+1)∣St=s,At=a](3.17) q_*(s, a) = \mathbb{E}[R_{t+1} + \gamma v_*(S_{t+1}) \mid S_t = s, A_t = a] \tag{3.17} q∗(s,a)=E[Rt+1+γv∗(St+1)∣St=s,At=a](3.17)
执行动作 aaa 后的最优价值 = 即时奖励期望 + 折扣后的最优后继状态价值期望。
贝尔曼最优方程
v∗v_*v∗ 的贝尔曼最优方程
由于 v∗v_*v∗ 是某个最优策略的价值函数,它必须满足贝尔曼方程。但由于其“最优性”,该方程可以写成不依赖具体策略的形式。
v∗(s)=maxa∈A(s)q∗(s,a)=maxaE[Rt+1+γv∗(St+1)∣St=s,At=a]=maxa∑s′,rp(s′,r∣s,a)[r+γv∗(s′)](3.19) \begin{aligned} v_*(s) &= \max_{a \in \mathcal{A}(s)} q_*(s, a) \\ &= \max_a \mathbb{E} \left[ R_{t+1} + \gamma v_*(S_{t+1}) \mid S_t = s, A_t = a \right] \\ &= \max_{a} \sum_{s', r} p(s', r \mid s, a) \left[ r + \gamma v_*(s') \right] \end{aligned} \tag{3.19} v∗(s)=a∈A(s)maxq∗(s,a)=amaxE[Rt+1+γv∗(St+1)∣St=s,At=a]=amaxs′,r∑p(s′,r∣s,a)[r+γv∗(s′)](3.19)
最优状态下,价值等于所有可能动作中最大期望回报。
q∗q_*q∗ 的贝尔曼最优方程
q∗(s,a)=E[Rt+1+γmaxa′q∗(St+1,a′) | St=s,At=a]=∑s′,rp(s′,r∣s,a)[r+γmaxa′q∗(s′,a′)](3.20) \begin{aligned} q_*(s, a) &= \mathbb{E} \left[ R_{t+1} + \gamma \max_{a'} q_*(S_{t+1}, a') \,\middle|\, S_t = s, A_t = a \right] \\ &= \sum_{s', r} p(s', r \mid s, a) \left[ r + \gamma \max_{a'} q_*(s', a') \right] \end{aligned} \tag{3.20} q∗(s,a)=E[Rt+1+γa′maxq∗(St+1,a′) St=s,At=a]=s′,r∑p(s′,r∣s,a)[r+γa′maxq∗(s′,a′)](3.20)
区别于普通贝尔曼方程:这里对未来取最大值而非策略期望。
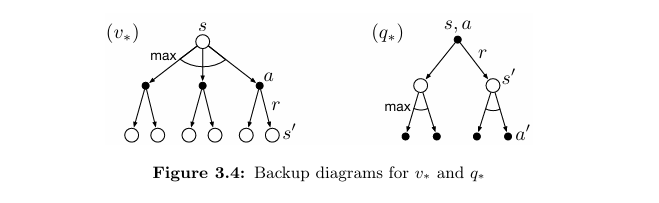
与普通备份图类似,但选择点增加弧线;弧线表示:此处取最大值,而非期望(Eπ\mathbb{E}_\piEπ)。
唯一解与最优策略的构造
对于有限 MDP,贝尔曼最优方程 (3.19) 有唯一解。它是一个包含 n=∣S∣n = |\mathcal{S}|n=∣S∣ 个方程和 nnn 个未知数(每个状态的 v∗(s)v_*(s)v∗(s))的非线性方程组。若动态函数 ppp 已知,原则上可通过数值方法求解。
一旦求得 v∗v_*v∗,最优策略可通过贪心策略(greedy policy)构造:对每个状态 sss,选择使贝尔曼最优方程中最大值成立的动作:
π∗(a∣s)>0仅当a∈argmaxa′∑s′,rp(s′,r∣s,a′)[r+γv∗(s′)] \pi_*(a|s) > 0 \quad \text{仅当} \quad a \in \arg\max_{a'} \sum_{s',r} p(s',r|s,a') [r + \gamma v_*(s')] π∗(a∣s)>0仅当a∈arga′maxs′,r∑p(s′,r∣s,a′)[r+γv∗(s′)]
任何仅以非零概率选择这些动作的策略都是最优策略。
“贪心”通常指仅考虑短期收益的策略;但 v∗v_*v∗ 已经包含了所有未来最优行为的长期奖励;因此,基于 v∗v_*v∗ 的一步前瞻贪心选择,实际上就是长期最优选择。
v∗v_*v∗ 将长期最优决策“压缩”为每个状态的局部值。
拥有 q∗q_*q∗ 则可使决策更简单:智能体无需知道环境动态 ppp;无需计算后继状态价值;只需对每个状态 sss,选择:
a∗=argmaxaq∗(s,a) a^* = \arg\max_a q_*(s, a) a∗=argamaxq∗(s,a)
因为q∗q_*q∗ 缓存了所有一步搜索的结果,是最直接的最优动作指南
上文案例
网格世界
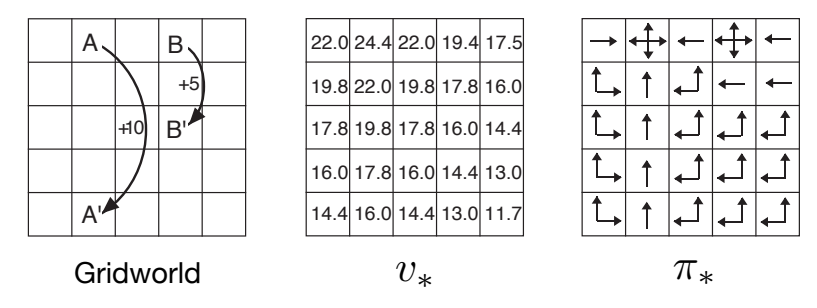
图 3.5: 网格世界的最优解
- 左图:任务结构(同图 3.2)
- 中图:最优状态价值函数 v∗v_*v∗
- 右图:最优策略(箭头表示最优动作,多个箭头表示多个动作同优)
易见:
- AAA 和 BBB 附近价值高
- 边缘区域价值低(避免撞墙)
- 从任意位置出发,策略引导朝向 AAA 或 BBB
回收机器人
状态:high (h), low (l)
动作:search (s), wait (w), recharge (re)
简写期望奖励:rs=rsearch, rw=rwaitr_s = r_{\text{search}},\ r_w = r_{\text{wait}}rs=rsearch, rw=rwait
v∗(h)v_*(h)v∗(h) 的贝尔曼最优方程
v∗(h)=max{选择 search:α[rs+γv∗(h)]+(1−α)[rs+γv∗(l)]选择 wait:1⋅[rw+γv∗(h)]}=max{rs+γ[αv∗(h)+(1−α)v∗(l)],rw+γv∗(h)} \begin{aligned} v_*(h) &= \max \left\{ \begin{array}{l} \text{选择 search:} \quad \alpha [r_s + \gamma v_*(h)] + (1 - \alpha) [r_s + \gamma v_*(l)] \\ \text{选择 wait:} \quad 1 \cdot [r_w + \gamma v_*(h)] \end{array} \right\} \\ &= \max \left\{ r_s + \gamma [\alpha v_*(h) + (1 - \alpha) v_*(l)],\quad r_w + \gamma v_*(h) \right\} \end{aligned} v∗(h)=max{选择 search:α[rs+γv∗(h)]+(1−α)[rs+γv∗(l)]选择 wait:1⋅[rw+γv∗(h)]}=max{rs+γ[αv∗(h)+(1−α)v∗(l)],rw+γv∗(h)}
v∗(l)v_*(l)v∗(l) 的贝尔曼最优方程
v∗(l)=max{search:βrs−3(1−β)+γ[(1−β)v∗(h)+βv∗(l)]wait:rw+γv∗(l)recharge:γv∗(h)} v_*(l) = \max \left\{ \begin{array}{l} \text{search:} \quad \beta r_s - 3(1 - \beta) + \gamma [(1 - \beta) v_*(h) + \beta v_*(l)] \\ \text{wait:} \quad r_w + \gamma v_*(l) \\ \text{recharge:} \quad \gamma v_*(h) \end{array} \right\} v∗(l)=max⎩
⎨
⎧search:βrs−3(1−β)+γ[(1−β)v∗(h)+βv∗(l)]wait:rw+γv∗(l)recharge:γv∗(h)⎭
⎬
⎫
对任意 0≤γ<10 \leq \gamma < 10≤γ<1,0≤α,β≤10 \leq \alpha, \beta \leq 10≤α,β≤1,存在唯一解 (v∗(h),v∗(l))(v_*(h), v_*(l))(v∗(h),v∗(l))
显式求解与近似方法
虽然理论上可通过求解贝尔曼最优方程得到最优策略,但极少直接实用,因为依赖以下三个理想假设:
| 假设 | 是否常成立 | 说明 |
|---|---|---|
| 1. 环境动态 ppp 已知 | 很少 | 需要完整模型 |
| 2. 足够计算资源 | 常不成立 | 状态空间巨大时不可行 |
| 3. 马尔可夫性质成立 | 通常假设成立 | 本书基础 |
3.7 最优性与近似
理论上,实现最优策略意味着智能体表现完美。但在实际任务中,达到最优极为罕见。 最优性是一个理想化的理论目标,实践中我们追求的是“足够好”的近似解。
即使满足以下理想条件,求解最优仍面临巨大挑战:
| 挑战 | 说明 |
|---|---|
| 计算资源限制 | 单个时间步内可执行的计算量有限 |
| 内存限制 | 无法存储所有状态的价值或策略 |
| 状态空间爆炸 | 实际任务的状态数远超计算机存储能力 |
例如国际象棋状态数巨大,远超当前算力可穷举范围。即使拥有完整环境模型(即知道所有规则和转移概率),也无法直接求解贝尔曼最优方程智能体必须在有限时间内做出决策,不能等待“全局最优解”。
强化学习的一个关键特性是其在线学习能力,智能体在与环境交互中逐步学习,可以将学习资源集中在高频出现的状态上,对极少访问的状态,允许次优决策,不影响整体性能。 “在重要状态上做得好”比“在所有状态上都最优”更实用
总结
- 强化学习的基本范式
通过与环境交互来学习如何行为以实现目标
智能体-环境交互流程:
-
时间步:$ t = 0, 1, 2, \dots $
-
每步发生:
St→agentAt→environmentRt+1,St+1 S_t \xrightarrow{\text{agent}} A_t \xrightarrow{\text{environment}} R_{t+1}, S_{t+1} StagentAtenvironmentRt+1,St+1 -
形成轨迹:
S0,A0,R1,S1,A1,R2,… S_0, A_0, R_1, S_1, A_1, R_2, \dots S0,A0,R1,S1,A1,R2,…
- 三大核心信号
| 信号 | 含义 | 作用 |
|---|---|---|
| 状态 StS_tSt | 当前情境的表示 | 决策的基础 |
| 动作 AtA_tAt | 智能体的选择 | 实现目标的手段 |
| 奖励 Rt+1R_{t+1}Rt+1 | 标量反馈信号 | 定义目标(“你想要什么”) |
智能体-环境边界:任何不能被智能体任意改变的事物都属于环境
- 策略(Policy)
-
定义:从状态到动作选择概率的映射
π(a∣s)=Pr{At=a∣St=s} \pi(a|s) = \Pr\{A_t = a \mid S_t = s\} π(a∣s)=Pr{At=a∣St=s} -
目标:通过经验不断改进策略,使其趋向最优
- 回报(Return)——智能体的目标
智能体的目标是最大化期望回报 $ \mathbb{E}[G_t] $
回报定义因任务类型而异:
| 任务类型 | 回报定义 | 公式 |
|---|---|---|
| 回合制任务(Episodic) | 有限步内奖励总和 | $ G_t = \sum_{k=0}^{T-t-1} R_{t+k+1} $ |
| 持续性任务(Continuing) | 折扣无限和 | $ G_t = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} $ |
统一记号:可通过引入吸收状态(absorbing state)将两类任务统一为折扣形式
约束:$ T = \infty $ 与 $ \gamma = 1 $ 不能同时成立,否则回报可能发散
- 价值函数(Value Functions)
价值函数衡量状态或动作的“长期好坏”,基于期望回报。
| 类型 | 定义 | 公式 |
|---|---|---|
| 状态价值函数 vπ(s)v_\pi(s)vπ(s) | 遵循策略 π\piπ 时,从状态 sss 出发的期望回报 | $ v_\pi(s) = \mathbb{E}_\pi[G_t \mid S_t = s] $ |
| 动作价值函数 qπ(s,a)q_\pi(s,a)qπ(s,a) | 执行动作 aaa 后遵循 π\piπ 的期望回报 | $ q_\pi(s,a) = \mathbb{E}_\pi[G_t \mid S_t = s, A_t = a] $ |
- 最优价值函数与最优策略
| 概念 | 定义 | 公式 |
|---|---|---|
| 最优状态价值函数 v∗(s)v_*(s)v∗(s) | 所有策略中最大的状态价值 | $ v_*(s) = \max_\pi v_\pi(s) $ |
| 最优动作价值函数 q∗(s,a)q_*(s,a)q∗(s,a) | 所有策略中最大的动作价值 | $ q_*(s,a) = \max_\pi q_\pi(s,a) $ |
| 最优策略 π∗\pi_*π∗ | 达到 v∗v_*v∗ 或 q∗q_*q∗ 的任意策略 | 存在且不唯一 |
任何关于 v∗v_*v∗ 或 q∗q_*q∗ 贪心的策略都是最优策略
- 贝尔曼最优方程(Bellman Optimality Equations)
最优价值函数满足以下自洽方程:
v∗v_*v∗ 的贝尔曼最优方程:
v∗(s)=maxa∑s′,rp(s′,r∣s,a)[r+γv∗(s′)](3.19) v_*(s) = \max_{a} \sum_{s', r} p(s', r \mid s, a) \left[ r + \gamma v_*(s') \right] \tag{3.19} v∗(s)=amaxs′,r∑p(s′,r∣s,a)[r+γv∗(s′)](3.19)
q∗q_*q∗ 的贝尔曼最优方程:
q∗(s,a)=∑s′,rp(s′,r∣s,a)[r+γmaxa′q∗(s′,a′)](3.20) q_*(s, a) = \sum_{s', r} p(s', r \mid s, a) \left[ r + \gamma \max_{a'} q_*(s', a') \right] \tag{3.20} q∗(s,a)=s′,r∑p(s′,r∣s,a)[r+γa′maxq∗(s′,a′)](3.20)
这些方程原则上可求解最优价值函数,但实践中常因计算/内存限制而不可行
- 知识假设分类
| 类型 | 智能体是否知道环境模型? | 说明 |
|---|---|---|
| 完全知识问题 | 是 | 拥有完整的动态函数 $p(s’,r |
| 不完全知识问题 | 否 | 必须通过交互经验学习模型或直接学习策略 |
即使在“完全知识”下,也可能因计算限制而无法求解最优
- 近似是必然选择
| 原因 | 说明 |
|---|---|
| 状态空间过大 | 无法为每个状态单独存储价值 |
| 计算时间有限 | 无法在每一步完成完整搜索 |
| 现实任务复杂 | 马尔可夫性可能不完全成立 |
因此,强化学习的核心是:**如何有效地近似最优策略

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)