大模型之原理篇——参数精度、显存占用公式
网上资料很详细,但是也过于详细了,我简单说下显存占用的原理和公式。
写在前面
网上资料很详细,但是也过于详细了,我简单说下显存占用的原理和公式
大模型的参数精度
要计算显存占用公式,得先了解下FP16、FP32、BF16、FP8占用的字节数,8代表一字节、16代表2字节、32代表4字节。这里以最常用的FP16举例。
FP16
下图时fp16的数据格式,第一个是正负符号的标示符,绿色部分是5位指数位,红色是10位尾数(有效精度)位。

公式如下,注意指数位是二进制的指数位,小数位用了10个bite。
指数位的15由来:但为了指数位能够表示负数,在指数的基础上引入了一个偏置值,在二进制16位浮点数中,偏置值是 15,这个偏置值确保了指数位可以表示从-14到+15的范围。
计算流程:比如a=10.0621,先将a转换位二进制的浮点数b,再把b写成指数形式(2^a * 1.01011...),然后套到下面的公式中就行.
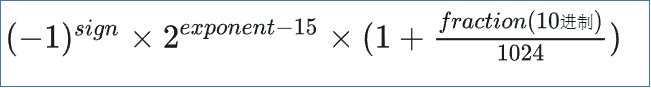
最大取值为65504,最小取值为-65504.
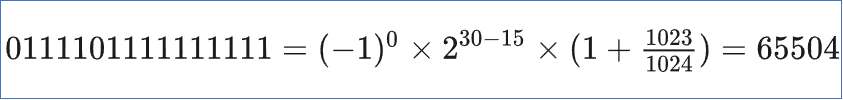
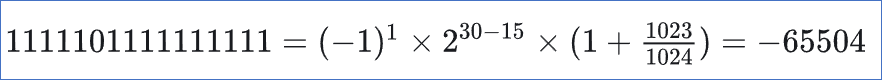
可能还是不直观,让qwen举个例子就能很好说明怎么计算的了。

大模型显存占用公式及原理
模型占用
假设LLM的参数量是N,默认用FP16进行存储这些参数,由于FP16存储一个参数用了两个字节,所以推理需要消耗2N。所以如果只推理不训练,只需要2N显存即可。
全量微调训练占用
先假设全量微调
梯度下降
公式如下所示,可以看到更新每个参数需要额外的一个关于参数的梯度,BF16的情况下需要2N
![]()
Adam优化器
这里需要更新动量m和参数v,在FP16的情况下是2X2N,但是由于优化器部分要求精度很高,一般是采用FP32进行存储参数,所以这部分一般是2X4N=8N
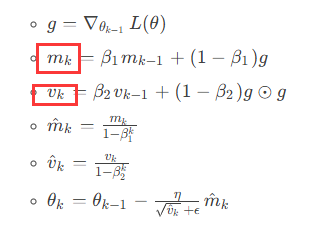
前向计算,激活值
假设Batchsize是B,每个Batchsize中的token数为L,每个token的激活值数量是V,那么这部分需要2BLV
汇总
全量微调显存占用为
2N(模型占用) + 2N(梯度下降) + 8N(Adam优化器) + 2BLV(激活值) = 12N + 2BLV
例如7B的模型,全量至少需要84G显存(没算激活值和其他的因素)
LORA微调占用
LORA微调情况下,2N模型占用还是必须的,只是后面的参数全都变小

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)