hashmap面试题
hash冲突
概念
链地址法(Chaining):将所有产生冲突的输入存储在同一个链表或其他数据结构中。
解决方式
链地址法(Chaining):将所有产生冲突的输入存储在同一个链表或其他数据结构中。
HashMap的插入流程
通过高性能hash取余算法计算出插入位置,然后为插入的键值对生成链表节点,如果数组当前位置为空就直接插入,如果当前数组不为空,首先对当前数组上的元素做判重,判重算法是插入元素的hash值和原先map中已有的元素key的hash值重复,且这两个key的地址一样或通过equals比较返回true,如果被判为重复,则会用新值替换旧值并把旧值返回
如果插入数组位置已经形成红黑树,那么就把元素插入到红黑树里
如果插入数组位置不为空且已经形成链表,那么采用尾插法,通过遍历这条链表获取到链表尾,然后通过链表尾的next指针完成插入,如果发下链表元素大于8就对当前链表进行树化
如果插入的是一个全新的节点,那么map的size++,如果超过阈值会触发扩容
HashMap的底层数组长度为何总是2的n次方
public int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
运算性能高且能有效避免hash冲突
通过上诉代码可知,数据长度是用来插入key的hash值来做与运算的,效果上等价于 hash % (n - 1),但计算机运算性能远高于 % 号
通过这种算法计算出的插入位置具备充分的随机性,原因是HashMap中的哈希算法,在原hashCode的基础上,通过(h = key.hashCode()) ^ (h >>> 16)得出最终结果,原因是由于hashCode底层算法,生成hashCode的时候会在某些位上呈规律性分布,不做处理可能会导致hash聚集,而通过右移运算符移位16位则是保证这个key的hashCode的二进制数的第16位与高16位共同参与运算,是的插入元素的位置分布更均匀,降低hash冲突概率
扩容时使用
对于一个数组槽位只有一个节点的元素,还是通过老算法来计算
newTab[e.hash & (newCap - 1)] = e;
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
对于数组槽位上的链表元素,则是根据e.hash & oldCap的结果值来判断,oldCap是2的n次方,比如oldCap是32,那么这个二进制数就是10000,所以这个结果取值最终只有2个可能,即0和1,主要是看e.hash的二进制数的从右往左数第五位是0还是1,所以通过这个机制,巧妙的将原先数组上的链表元素划分为了两个链表loHead和loTail,这两个链表的元素按概率来看是1:1的,loHead链表插入扩容数组的原位置,hiHead则是被分配到了newTab[j + oldCap]上,即在原位置基础上挪动了oldCap,保证扩容高效性的同时,使得链表一分为二并且分散开,防止长链表出现
hashMap扩容
扩容流程
参考上面
扩容时机
当HashMap中的元素数量超过了当前数组容量与负载因子的乘积(即容量 * 负载因子)时,会触发扩容操作。默认情况下,负载因子为0.75。
扩容的意义(好处 & 坏处)
扩容通过增加底层数组的大小降低了hash冲突的概率,且把原先的链表红黑树一分为二,从而提高了查询和插入的效率
扩容是一项耗费资源的操作,因为它需要创建新的数组并重新分配所有旧元素
实际开发中的启发
设计应用程序时应适当设置初始容量和负载因子以减少扩容次数。
hashMap线程安全问题
读写异常 - 快速失败机制
HashMap迭代器,在初始化的时候,会根据hashmap这个数组链表的结构,生成迭代器,迭代器本质就是一个指针而已,迭代器的主要作用就是遍历,且只能是单向遍历,试想在遍历的时候如果本线程或者其它删除或者插入了元素,如果是插入到了已经遍历过的区域,那么当前遍历的数据就是不准确的脏数据了,所以禁止在迭代器遍历过程中去写数据
写写异常 - 数据覆盖
多个线程并发的写入,碰巧计算插入的是同一个数组位置,第一个线程判断完当前插入位置是null了,在执行插入的时候时间片耗尽,另一个线程插入这个位置元素的时候判断值为null没问题,然后直接插入,当第一个线程重新被分配到时间片后重新执行插入操作,会被直接覆盖
写写异常 - 计数覆盖
同样是插入完毕,当前size = 10,做++size的时候,第一个线程时间片耗尽,另一个线程成功++size后size = 11 第一个线程分配到时间片后继续++size,此时线程中读取的size依然是10,更新到11,即第二个线程的size++操作被覆盖
扩容时异常(jdk7头插法导致的)
jdk8新特征
结构升级
JDK 1.8 之前是由“数组+链表”组成,JDK 1.8,底层是由“数组+链表+红黑树”组成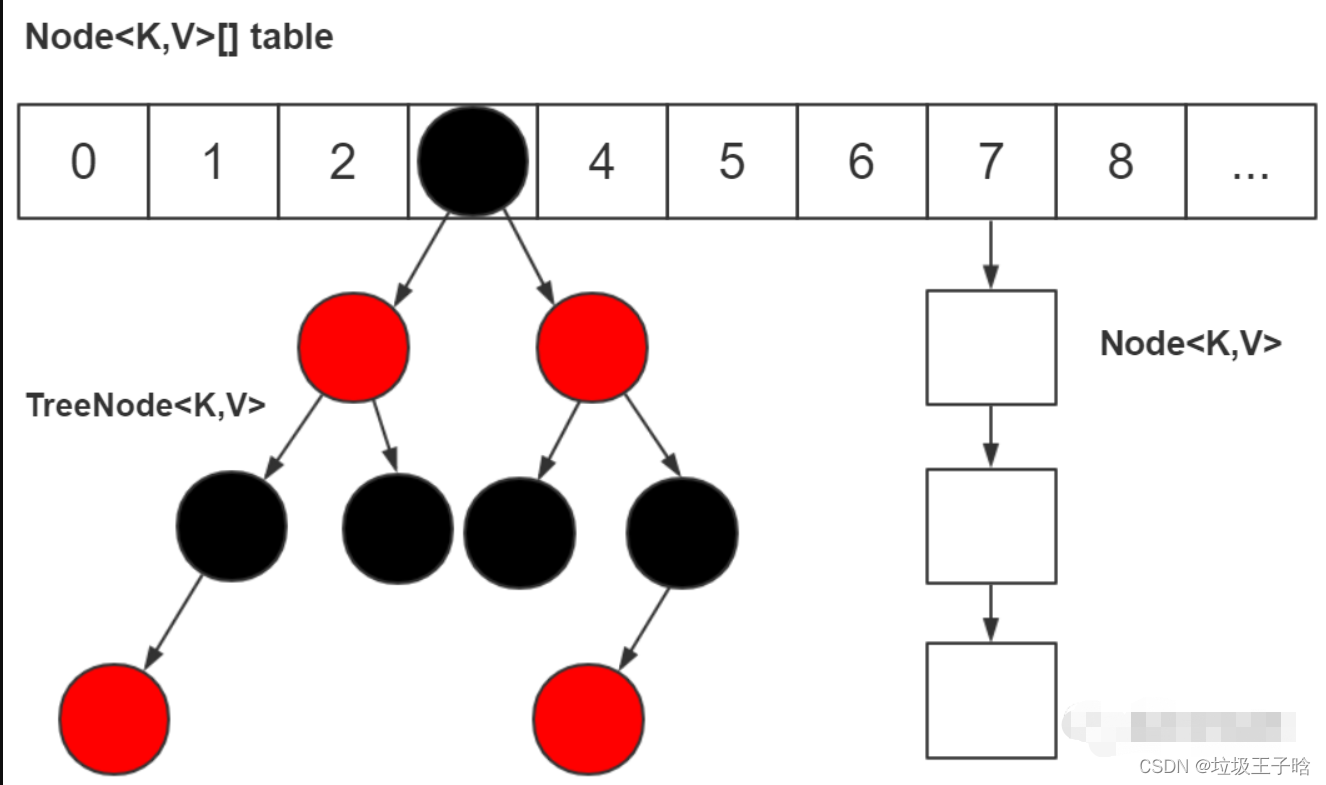
结构优化目的:优化了 hash 冲突较严重时,链表过长的查找性能:O(n) -> O(logn)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)