如何确保您的 AI 解决方案达到您的期望
按 Enter 键或单击以查看大图图片由在Unsplash上那么我们如何定义我们的评估呢?评估不是一刀切的。它们取决于用例,应与 AI 应用程序的特定目标保持一致。如果您正在构建搜索引擎,您可能会关心结果相关性。如果是聊天机器人,您可能会关心帮助性和安全性。如果是分类器,您可能关心准确性和精确度。对于具有多个步骤的系统(例如执行搜索、确定结果优先级然后生成答案的 AI 系统),通常需要评估每个步骤
令人印象深刻的图像生成。2025 年是将人工智能炒作转化为真正价值的一年。世界各地的公司都在寻找在其产品和流程中集成和利用 GenAI 的方法,以更好地为用户服务、提高效率、保持竞争力并推动增长。得益于主要提供商的 API 和预训练模型,集成 GenAI 感觉比以往任何时候都更容易。但这里有一个问题:仅仅因为集成很容易,并不意味着人工智能解决方案一旦部署就会按预期工作。
预测模型并不新鲜:作为人类,我们多年来一直在预测事物,正式地从统计数据开始。然而,GenAI 彻底改变了预测领域,原因有很多:
- 无需训练自己的模型或成为数据科学家即可构建 AI 解决方案
- 人工智能现在可以通过聊天界面轻松使用,并通过 API 集成
- 解锁许多以前做不到或真的很难做的事情
所有这些事情都让 GenAI 非常令人兴奋,但也存在风险。与传统软件甚至经典机器学习不同,GenAI 引入了新的不可预测性水平。您不是实现确定性逻辑,您使用的是经过大量数据训练的模型,希望它能够根据需要做出响应。那么,我们如何知道人工智能系统是否正在按照我们的意图做呢?我们如何知道它是否已准备好上线?答案是评估(评估),我们将在这篇文章中探讨这个概念:
- 为什么 GenAI 系统不能像传统软件甚至经典机器学习 (ML) 那样进行测试
- 为什么评估是了解人工智能系统质量的关键,而不是可选的(除非你喜欢惊喜)
- 不同类型的评估和在实践中应用它们的技术
无论您是产品经理、工程师,还是任何对人工智能工作或感兴趣的人,我希望这篇文章能帮助您了解如何批判性地思考人工智能系统质量(以及为什么评估是实现该质量的关键!
GenAI 无法像传统软件那样进行测试,甚至无法像经典 ML 那样进行测试
在传统的软件开发中,系统遵循确定性逻辑:如果 X 发生,那么 Y 就会发生——总是。除非您的平台出现问题或您在代码中引入错误......这就是您添加测试、监控和警报的原因。单元测试用于验证小代码块,集成测试用于确保组件协同工作,以及监控以检测生产中是否出现故障。测试传统软件就像检查计算器是否有效。您输入 2 + 2,您期望 4。清晰而确定,要么对,要么错。
然而,机器学习和人工智能引入了非确定性和概率。我们不是通过规则明确定义行为,而是训练模型从数据中学习模式。在 AI 中,如果 X 发生,输出不再是硬编码的 Y,而是基于模型在训练过程中学到的内容的具有一定概率的预测。这可能非常强大,但也会带来不确定性:随着时间的推移,相同的输入可能会有不同的输出,合理的输出实际上可能是不正确的,在罕见的情况下可能会出现意外行为......
这使得传统的测试方法不够充分,有时甚至不合理。计算器示例更接近于尝试评估学生在开放式考试中的表现。对于每个问题,以及回答问题的多种可能方法,提供的答案是否正确?是否高于学生应有的知识水平?学生是否编造了一切,但听起来非常有说服力?就像考试中的答案一样,人工智能系统可以进行评估,但需要一种更通用和灵活的方式来适应不同的输入、上下文和用例(或考试类型)。
在传统的机器学习 (ML) 中,评估已经是项目生命周期中既定的一部分。在贷款审批或疾病检测等狭窄任务上训练模型始终包括评估步骤——使用准确度、精确度、RMSE、MAE 等指标......这用于衡量模型的性能,比较不同模型选项,并确定模型是否足够好,可以继续部署。在 GenAI 中,这种情况通常会发生变化:团队使用已经经过训练的模型,并且已经在模型提供商内部和公共基准测试中通过了通用评估。这些模型非常擅长一般任务(例如回答问题或起草电子邮件),因此对于我们的特定用例,存在过度信任它们的风险。然而,仍然重要的是要问“这个惊人的模型是否足以满足我的用例?这就是评估的用武之地——评估实践或代是否适合您的特定用例、上下文、输入和用户。
按 Enter 键或单击以查看大图

训练和评估 — 传统 ML 与 GenAI,图片由作者提供
ML 和 GenAI 之间还有另一个很大的区别:模型输出的多样性和复杂性。我们不再返回类别和概率(例如客户归还贷款的概率)或数字(例如基于其特征的预测房价)。GenAI 系统可以返回多种类型的输出,具有不同的长度、语气、内容和格式。同样,这些模型不再需要结构化且非常确定的输入,但通常可以接受几乎任何类型的输入——文本、图像,甚至音频或视频。因此,评估变得更加困难。
按 Enter 键或单击以查看大图
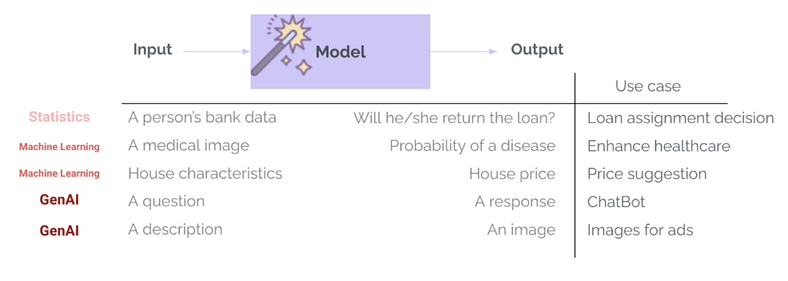
输入/输出关系 — 统计和传统 ML 与 GenAI,图片由作者提供
为什么评估不是可选的(除非你喜欢惊喜)
评估可帮助您衡量您的 AI 系统是否真的按照您想要的方式工作,系统是否已准备好上线,以及一旦上线,它是否会继续按预期运行。分解为什么评估是必不可少的:
- 质量评估:评估提供了一种结构化的方法来了解 AI 预测或输出的质量以及它们将如何集成到整个系统和用例中。响应准确吗? 有益的? 相干? 相关?
- 误差量化:评估有助于量化错误的百分比、类型和大小。事情出错的频率是多少?哪些类型的错误更频繁地发生(例如误报、幻觉、格式错误)?
- 风险缓解:帮助您在有害或有偏见的行为到达用户之前发现并防止它,从而保护您的公司免受声誉风险、道德问题和潜在监管问题的影响。
生成式人工智能具有自由的输入输出关系和长文本生成,使评估变得更加关键和复杂。当事情出错时,他们可能会出错。我们都看过有关聊天机器人提供危险建议、模型生成有偏见的内容或人工智能工具产生虚假事实的幻觉的头条新闻。
“人工智能永远不会完美,但通过评估,您可以降低尴尬的风险——这可能会让您付出金钱、信誉或在 Twitter 上的病毒式传播。“
如何定义评估策略?
按 Enter 键或单击以查看大图

图片由 akshayspaceship 在 Unsplash 上
那么我们如何定义我们的评估呢?评估不是一刀切的。它们取决于用例,应与 AI 应用程序的特定目标保持一致。如果您正在构建搜索引擎,您可能会关心结果相关性。如果是聊天机器人,您可能会关心帮助性和安全性。如果是分类器,您可能关心准确性和精确度。对于具有多个步骤的系统(例如执行搜索、确定结果优先级然后生成答案的 AI 系统),通常需要评估每个步骤。这里的想法是衡量每个步骤是否有助于达到总体成功指标(并通过此了解迭代和改进的重点)。
常见的评估领域包括:
- 正确性和幻觉:输出是否真实?他们是在编造事情吗?
- 关联:内容是否与用户的查询或提供的上下文一致?
- 安全性、偏见和毒性
- 格式: 输出是否采用预期格式(例如,JSON,有效的函数调用)?
- 安全性、偏见和毒性:系统是否生成有害、有偏见或有毒的内容?
- 特定于任务的指标。 例如,在分类任务中,衡量准确性和精确度等指标,在摘要任务中测量 ROUGE 或 BLEU,在代码生成任务中,正则表达式和执行,无需错误检查。
你实际上如何计算评估?
一旦知道要测量什么,下一步就是设计测试用例。这将是一组示例(示例越多越好,但始终平衡价值和成本),其中您有:
- 输入示例:系统投入生产后的真实输入。
- 预期输出(如果适用):基本事实或理想结果的示例。
- 评价方法:评估结果的评分机制。
- 分数或通过/失败:评估测试用例的计算指标
根据您的需求、时间和预算,您可以使用多种技术作为评估方法:
- 统计得分者喜欢嵌入之间的 BLEU、ROUGE、METEOR 或余弦相似性 — 适合将生成的文本与参考输出进行比较。
- 传统的 ML 指标,例如 准确度、精密度、召回率和 AUC — 最适合使用标记数据进行分类。
- 法学硕士作为法官 使用大型语言模型对输出进行评分(例如,“这个答案正确且有帮助吗?当标记数据不可用或评估开放式生成时特别有用。
- 基于代码的评估 使用正则表达式、逻辑规则或测试用例执行来验证格式。
包起来
让我们用一个具体的例子将所有内容放在一起。想象一下,您正在构建一个情绪分析系统,以帮助您的客户支持团队确定传入电子邮件的优先级。
目标是确保最紧急或最负面的信息得到更快的响应——理想情况下,减少挫败感、提高满意度并减少客户流失。这是一个相对简单的用例,但即使在这样输出有限的系统中,质量也很重要:错误的预测可能会导致随机确定电子邮件的优先级,这意味着您的团队在一个需要花钱的系统上浪费时间。
那么,您如何知道您的解决方案是否具有所需的质量呢?你评估。以下是在此特定用例中可能与评估相关的一些示例:
- 格式验证: 用于预测电子邮件情绪的 LLM 调用的输出是否以预期的 JSON 格式返回?这可以通过基于代码的检查来评估:正则表达式、模式验证等。
- 情绪分类准确性: 系统是否正确地对一系列文本(短文本、长文本、多语言文本)的情绪进行分类?这可以使用传统的 ML 指标使用标记数据进行评估,或者,如果标签不可用,则使用 LLM-as-a-judge。
解决方案上线后,还需要包含与解决方案的最终影响更相关的指标:
- 优先级有效性: 支持代理是否真的被引导到最关键的电子邮件?优先级是否与预期的业务影响保持一致?
- 最终业务影响随着时间的推移,该系统是否减少了响应时间、降低了客户流失率并提高了满意度分数?
评估是确保我们在生产中构建有用、安全、有价值且用户就绪的 AI 系统的关键。 因此,无论您使用的是简单的分类器还是开放式聊天机器人,请花时间定义“足够好”的含义(最低可行质量)——并围绕它构建评估来衡量它!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)