联邦学习论文分享:PrE-Text: Training Language Models onPrivate Federated Data in the Age of LLMs
1.客户端设置(Private clients setup)总共有N 个用户设备(客户端),每个客户端 i 拥有一个语言数据集 Di,里面包含若干语言样本。训练客户端 Ctrain:数据可以用于训练模型或生成合成数据。测试客户端 Ctest:数据完全不可见,仅用于最终评估模型性能。假设每个客户端数据集 Di 都是从某个分布 D^ 独立抽取的。2.模型类型划分on-device models(设
摘要
-
背景问题:
-
在用户设备上训练模型(on-device training),以保护分布式的用户隐私数据,联邦学习,数据不出客户端。
-
但是这种方式有很多缺点:
-
用户设备算力和存储不足以训练大模型;
-
训练过程需要大量通信(服务端与客户端之间的通信)和计算;
-
调试和部署难度大。
-
-
-
提出的方法:
-
PrE-Text 能生成差分隐私保护的 合成文本数据。
-
这些数据可以替代真实用户数据来训练模型,从而避免直接在设备上训练。
-
引言
1. 研究背景

-
在很多应用中(如手机键盘自动补全、大语言模型的指令跟随),如果能用私有用户数据来训练模型,性能会显著提升。
-
但用户数据敏感,需要用算法保证隐私。
-
联邦学习 (Federated Learning, FL) + 差分隐私 (DP) (合称 DP-FL)是常见方案:在用户设备上训练模型,再将梯度或模型更新上传到服务器聚合。
2. 现有问题(on-device / DP-FL 的缺陷)
-
用户设备算力和存储有限,难以训练 大语言模型 (LLMs),毕竟现在LLM的性能很好。
-
客户端训练需要高通信和高计算成本。
-
难以部署和调试,需要大量基础设施投入。
3. 新思路:差分隐私合成数据 (DP Synthetic Data)
-
新范式:让中央服务器利用私有客户端数据生成 差分隐私合成文本数据,然后在服务器端微调预训练语言模型。
-
好处:
-
不受设备算力限制,可直接在大模型上用;
-
调试方便,训练过程可观察;
-
不需要复杂的端上训练基础设施;
-
合成数据可反复使用而 不增加额外隐私开销(DP 的后处理性质)。
-
4. 现有方法的不足
-
现有的 DP 合成文本数据的质量太差,不能用来有效训练 LLM。
-
有工作(Lin et al., 2023)提出 Private Evolution (PE),在图像领域能生成高质量的 DP 合成图像,但没解决文本问题。
5. 本文贡献:PrE-Text 方法
-
提出算法 PrE-Text:
-
改造 PE,使之能用于文本生成。
-
用 mask-filling 模型(如 BERT、BART)替代图像领域的扩散模型。
-
生成初步 DP 文本后,用大型语言模型(在公共数据上训练的)进行后处理扩增,从而得到更多高质量合成数据(依旧不增加隐私成本)。
-
-
实验验证:
-
小模型(可部署在设备端):在隐私预算 ϵ=1.29 和 ϵ=7.58 下,PrE-Text 合成数据训练的小模型性能 大于 on-device 训练的模型,同时通信成本降低约 100倍,计算降低 6倍,训练轮次减少 9倍。
-
大模型(只能在服务器端运行的 LLM):在 PrE-Text 合成数据上微调后,比不微调的预训练 LLM 性能更好。
-
发现:可以在 联邦场景下 用私有数据 微调大语言模型,而不需要把模型放到用户设备上。
-
前提知识
数学基础
-
邻近数据集 (Neighboring datasets)
-
在联邦学习场景中,如果两个数据集只在 一个用户的数据 上不同(比如 X 比 X′ 多了一个用户,或少了一个用户),就称它们为“邻近数据集”。
-
这里采用的是 用户级差分隐私 (user-level DP) 的定义,而不是样本级。
-
-
差分隐私 (Differential Privacy, DP)
-
定义了一个随机算法 A 的 (ϵ, δ)-DP 条件:在任意邻近数据集 X 和 X′ 上,输出落在某个集合 E 的概率不会相差太大(差异受 ϵ 和 δ 控制)。
-
这是保证隐私的核心数学定义。
-
-
高斯机制 (Gaussian Mechanism)
-
本文采用高斯机制来实现 DP:在要发布的统计量上加入合适规模的高斯噪声。
-
噪声大小与 查询的敏感度 有关。
-
-
L2 敏感度 (L2 sensitivity)
-
定义了函数 g 的 L2 敏感度,即在任意两个邻近数据集上,g(X) 和 g(X′) 的输出差的最大 L2 范数。
-
敏感度决定了要加多少噪声才能满足 DP。
-
问题定义
1. 客户端设置(Private clients setup)
-
总共有 N 个用户设备(客户端),每个客户端 i 拥有一个语言数据集 Di,里面包含若干语言样本。
-
将客户端划分为两类:
-
训练客户端 Ctrain:数据可以用于训练模型或生成合成数据。
-
测试客户端 Ctest:数据完全不可见,仅用于最终评估模型性能。
-
-
假设每个客户端数据集 Di 都是从某个分布 D^ 独立抽取的。
2. 模型类型划分
-
on-device models(设备端模型):能放在用户设备上运行的小模型,即客户端模型。
-
on-server models(服务器端模型):太大,无法放在客户端设备上的大模型(比如 LLMs),只能部署在服务端。
3. 服务端设置(Server setup)
-
服务器有 预训练好的 LLMs(例如 LLaMA 系列),这些模型只在 公开数据 上训练过。
-
服务器的目标是利用客户端数据(在隐私保护下)来提升这些模型。
4. 任务
-
聚焦于 语言建模任务(next-token prediction):给定前面一段文本,预测下一个 token。
-
最终目标:得到一个在 测试客户端 Ctest 上表现良好 的语言模型。
5. 隐私假设
-
假设服务器是 honest-but-curious(诚实但好奇):
-
它会按照协议操作,但会尝试推断用户隐私,然后可能会记住这些隐私信息。
-
-
使用 安全聚合 (secure aggregation):服务器看不到单个客户端的上传,只能看到加总后的结果。
-
客户端在上传前会加上 差分隐私噪声,避免服务器通过聚合结果反推出单个用户数据。
-
目标是学习一个 满足 (ϵ, δ)-差分隐私(用户级 DP) 的语言模型。
算法
核心思想
-
公共大模型本身有一定概率生成和私有数据相似的样本。
-
因此,可以通过一个 多轮的私有引导过程,逐步把生成模型“推向”用户私有数据分布,从而生成 DP 合成数据。
-
相比原始 PE(主要用于图像),PrE-Text 的改进包括:
-
适配文本领域(用 mask-filling 替代 diffusion);
-
利用整个进化过程的所有迭代结果,而不只是最后一轮;
-
增加后处理扩展(post-processing),用 LLM 扩充 DP 种子数据。
-
算法流程
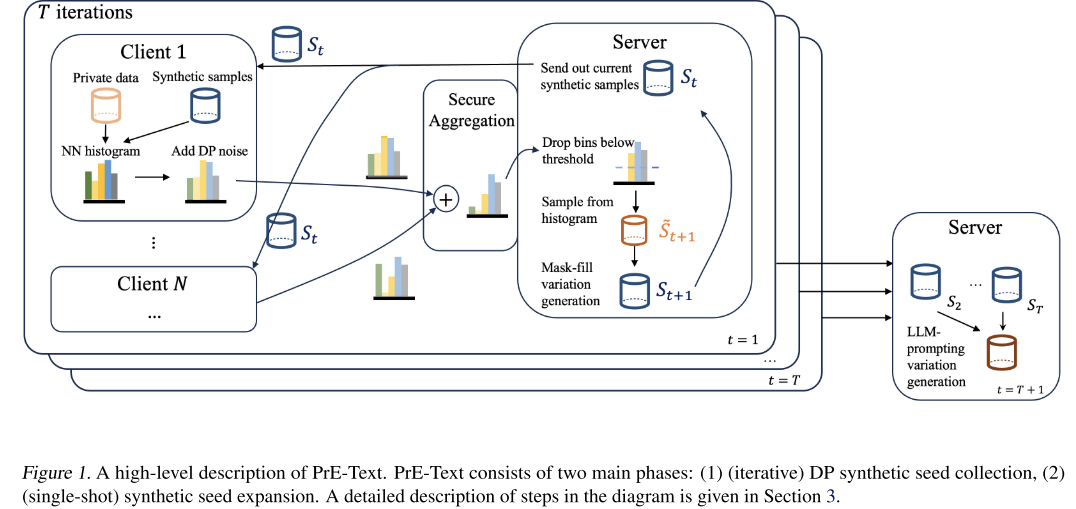


-
初始样本生成 (Population)
-
从公开数据或公共生成模型中采样,得到初始合成样本集 S1。
-
保证这些样本不含用户隐私。
-
-
客户端投票 (Clients vote)
-
在第 t 轮,将合成样本 St 发给所有客户端。
-
每个客户端比较这些样本与自己私有数据的相似度(基于 embedding 距离),并生成直方图投票。
-
Lookahead 技巧:对每个样本生成 K 个变体,再计算平均 embedding,提高相似度评估的鲁棒性。
-
隐私保护步骤:
a) 向直方图添加 DP 噪声;
b) 用安全聚合合并所有客户端直方图;
c) 通过阈值过滤掉主要是噪声的样本(丢弃样本)。
-
-
样本选择 (Surviving samples)
-
根据聚合投票结果,采样出新的合成样本集 St+1′。
-
高得票的样本被更大概率保留。
-
-
生成变体 (Variation)
-
对 St+1′ 的样本进行多次 mask-filling:
-
随机遮蔽部分 token;
-
用 RoBERTa-large 补全;
-
重复 W 步,得到新的变体样本集 St+1。
-
-
-
更高效地利用迭代 (Use iterates efficiently)
-
不仅使用最后一轮的 St,而是保留每一轮的 St′。
-
将所有轮次的 St′ 合并,作为最终的 DP 种子集。
-
-
后处理扩展 (Expand with LLMs)
-
发现 DP 种子数据质量不足以直接微调 LLM,于是加入扩展步骤:
-
选取 DP 种子集中的 3 个样本作为参考;
-
用 LLaMA-2-7B 生成风格相似的新样本;
-
这样得到更大、更高质量的合成语料。
-
-
由于差分隐私具有 后处理性质,这一步不会增加隐私泄露风险
-
什么是直方图
举个例子:假设服务器生成了 5 条候选句子:
-
s1: "I love pizza"
-
s2: "The stock market fell"
-
s3: "Good morning"
-
s4: "Let’s play football"
-
s5: "Quantum computing is hard"
而我的私有数据主要是日常聊天,比如 "Good night", "Good morning", "See you"。
那么我客户端的直方图可能是:
-
s1 = 0(我的数据里没人说过类似的)
-
s2 = 0
-
s3 = 10(和我数据里 "Good morning" 很像)
-
s4 = 2(有点像聊天习惯)
-
s5 = 0
所以我的直方图就是:
hi=[0,0,10,2,0]h
为什么要加噪声?
这个直方图其实已经包含隐私:
-
如果我投了很多票给 "Good morning",就说明我私有数据里经常出现类似的句子。
-
如果服务器直接看到这个直方图,就可能推断我的聊天习惯。
解决办法:
-
在上传前,每个客户端在直方图上加 高斯噪声,比如:
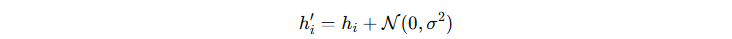
-
然后通过 安全聚合 把所有客户端的直方图加起来,服务器只看到“全体用户合计的模糊投票结果”,而不会知道某个用户投了多少票。
举个例子理解:
可以把 PrE-Text 想象成一个“进化选拔赛”:
-
我们想生成一些“假数据”(合成文本),它们要长得尽可能像用户的真实数据,但不能泄露隐私。
-
这个过程就像一场选拔赛:
-
先随便找一些“候选人”(初始文本,来源于公开数据或模型随机生成)。
-
把这些候选人交给所有用户“秘密投票”:哪个看起来最像他们自己的数据。
-
投票加上隐私噪声 → 聚合到服务器 → 得出“优胜候选人”。
-
优胜候选人再“变异”生成新的一批候选人。
-
重复多轮,逐渐得到越来越像真实数据的“假数据”,但始终保证差分隐私。
-
第 1 步:初始化(Population)
-
先准备一批 初始文本(比如随机生成的句子,或从公共数据抓的句子)。
-
这些文本完全不包含私有数据。
第 2 步:用户投票(Voting)
-
把这些文本发送给所有用户。
-
每个用户检查这些文本里,哪些句子最像自己手机里的私有数据(但用户不会把数据交出去)。
-
用户把“相似度”记成一个直方图:哪个生成的句子更像,就投票更多。
保护隐私的方法:
-
用户的直方图要加 差分隐私噪声(避免服务器直接猜到用户数据)。
-
然后所有用户的直方图用 安全聚合加起来,服务器只能看到合计投票数,而不是谁投了什么。
第 3 步:筛选样本(Selection)
-
服务器根据聚合直方图,挑选“得票高”的句子,作为“幸存者”。
-
这些幸存句子就是目前最像私有数据的候选人。
第 4 步:生成变体(Variation)
-
对这些幸存句子进行 “变异”:
-
随机遮住一部分词(MASK)。
-
用一个预训练好的填空模型(RoBERTa)来补全。
-
反复多次,就得到一堆稍有变化的新句子。
-
-
这样可以产生新的候选人,进入下一轮比赛。
第 5 步:多轮进化(Iterates)
-
不只是最后一轮的候选人有用,每一轮产生的候选人都有价值。
-
所以我们把每一轮的结果都保存下来,合并成一个 DP 种子集。
第 6 步:后处理扩展(Expand with LLM)
最后会得到
-
种子集里的句子质量还不够高,不能直接训练大模型。
-
所以我们用一个强大的 开源 LLM(比如 LLaMA-2-7B) 来扩展:
-
给 LLM 三个 DP 种子句子,让它“写一段风格相似的句子”。
-
这样 LLM 可以生成数量更大、质量更高的合成数据集。
-
-
由于差分隐私有 后处理不损害隐私的性质,这一步不会增加隐私风险。
-
一个高质量的 差分隐私合成文本数据集。
-
这个数据可以用来:
-
训练小模型(部署在手机上);
-
微调大模型(运行在服务器端)。
-
-
整个过程中用户隐私始终得到保护。
实验
设置
1. 使用的模型
-
RoBERTa-large 用来做 mask-filling(生成变体)。
-
all-MiniLM-L6-v2 用来算文本 embedding(距离计算)。
-
DistilGPT2 用来评估方法(实验主力小模型,也就是说服务端不仅有用于生成合成数据的大模型,也有专门用于任务的大模型)。
-
LLaMA-2-7B 用来做 DP 种子扩展(生成更多的高质量合成数据)。
2. 数据集
-
基础数据:c4-English (c4-en)。
-
从里面构造了三个子集作为 私有分布式数据:
-
JOBS(招聘类文本)
-
FORUMS(论坛)
-
MICROBLOG(微博/短文本)
-
-
另一个私有数据集:CODE(编程问答)。
-
私有数据分给 1250 个客户端,并留出一部分做测试集。
-
初始合成样本来自 c4-en 的另一部分(确保和私有数据不重叠)。
-
还特别说明:避免数据污染(contamination) 很难,因为很多 LLM 训练数据没透明记录,这在 LLM 研究里是个未解决难题。
3. 实验任务
-
任务:语言建模(LM task)
-
指标:cross-entropy loss 和 accuracy
-
场景:
-
小模型(部署在设备上)
-
大模型(部署在服务器上)
-
4. 对比基线方法
分四类:
-
ε = 0 的基线(不使用私有数据,只用公开数据)
-
c4-only:DistilGPT2 在 c4-en 的公开子集上微调。
-
Expand-only:在 c4-only 的基础上,再用 Expand 扩展成 200 万样本微调。
-
-
ε = ∞ 的基线(完全忽略隐私约束,上界性能)
-
Expand-private:在公开数据 (c4-only) + 私有数据(扩展到 200 万样本)上微调。
-
-
On-device 训练基线(传统的私有联邦学习方法)
-
DP-FedAvg
-
DP-FTRL(TreeRestart 变体)
这两个是目前最常用的设备端差分隐私优化方法。
-
-
文本级差分隐私方法(Text-to-text privatization)
-
DP-Prompt (Utpala et al., 2023)
-
思路:客户端自己运行 LLM,把原始文本做 DP 处理(比如私有改写),直接发给服务器。
-
缺点:文本没法做安全聚合,所以需要加更大噪声,效果差。
-
实验一
1. 实验场景
-
场景:用户不直接把数据发给服务器,而是保留一个小模型在设备端推理。
-
小模型:DistilGPT2(82M 参数)。
-
PrE-Text 流程:
-
生成 200 万条合成数据。
-
先在公开数据(c4-only)上微调 DistilGPT2。
-
再用 PrE-Text 生成的合成数据上继续微调。
-
-
对比对象:前面实验部分提到的所有 baselines(c4-only / Expand-only / Expand-private / DP-FedAvg / DP-FTRL / DP-Prompt)。
2. 实验结果
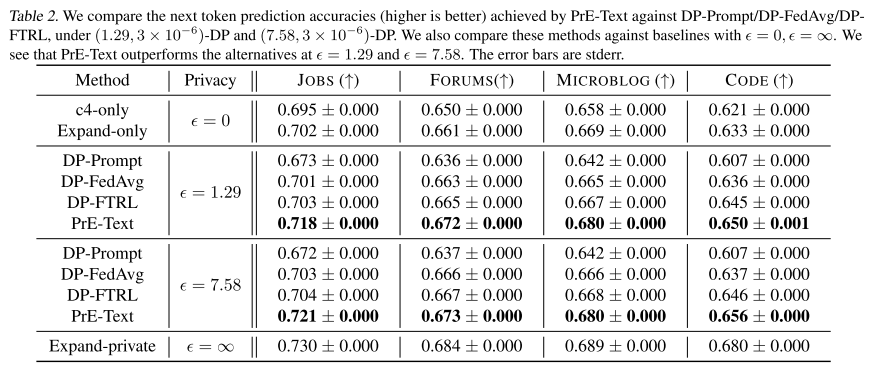
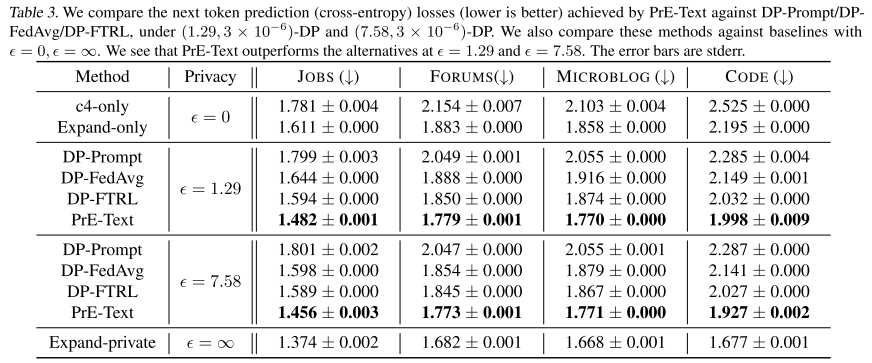
-
PrE-Text 在 ε = 1.29 和 ε = 7.58 的隐私预算下,都优于其他隐私方法。
-
合理性检查:
-
比 ε = 0 的基线(不用私有数据)好。
-
比 ε = ∞ 的上界(无隐私约束)差。
-
-
结论:
-
在实际可用的隐私水平下,PrE-Text 优于传统的 on-device DP 训练方法。
-
随着合成数据生成方法的改进,PrE-Text 可能会变得更强。
-
3. 效率对比(PrE-Text vs. DP-FL)
主要分 通信成本 和 计算成本 两方面:
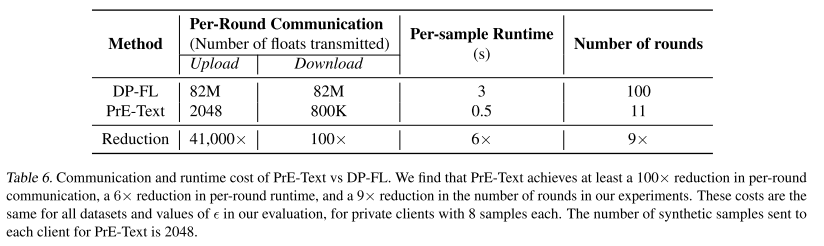
(1) 通信成本
-
DP-FL(传统方法):
-
每轮客户端要下载 + 上传一个 DistilGPT2 模型(82M 参数 差不多 82M 浮点数)。
-
-
PrE-Text:
-
每轮下载:最多 2048 个 embedding 向量(384维)差不多 80 万浮点数。
-
每轮上传:最多 2048 个浮点数(直方图)。
-
-
对比结果:
-
下载开销:PrE-Text 至少 100倍 更省。
-
上传开销:PrE-Text 41,000倍 更省。
-
而且 PrE-Text 迭代轮数少 9倍。
-
综合起来,通信成本至少降低 100倍。
-
(2) 客户端计算成本
-
DP-FL:
-
训练 DistilGPT2,每个样本需要 3 秒(CPU-only)。
-
-
PrE-Text:
-
客户端只做 embedding 推理(最近邻计算),每个样本 小于 0.5 秒。
-
-
对比结果:
-
每轮计算成本 PrE-Text 至少快 6倍。
-
再加上迭代轮数少 9倍,总体效率更高。
-
-
注意:这虽然增加了服务器端计算量,但通常 服务器算力更充足,比占用用户设备更可接受。
实验二
1. 研究场景
-
考虑 模型太大无法放在用户设备上 的情况(例如 LLaMA-2-7B),只能在服务器端训练和推理。
-
用户数据仍是私有的,不能直接上传,因此需要先生成 差分隐私合成数据(DP synthetic data),再用它来微调服务器端 LLM。
2. 实验设置
-
使用 LLaMA-2-7B 作为下游模型(替代之前的 DistilGPT2)。
-
生成 5 万条合成数据(不是 200万,原因是大模型微调计算开销太大)。
-
微调方法:
-
使用 LoRA(低秩适配),rank=4,α=8
-
优化器:AdamW
-
学习率:0.0002
-
batch size = 512
-
微调 1 个 epoch
-
-
对比基线:
-
零样本 LLaMA-2-7B(不微调,只在私有测试集上评估)。
-
Expand-private (ε = ∞):在没有隐私约束的情况下,用私有数据扩展 5 万条样本,然后微调。
-
不考虑 on-device baselines(因为设备装不下)。
-
不比较 DP-Prompt(之前实验效果太差,甚至不如 ε=0 baseline)。
-
3. 实验结果
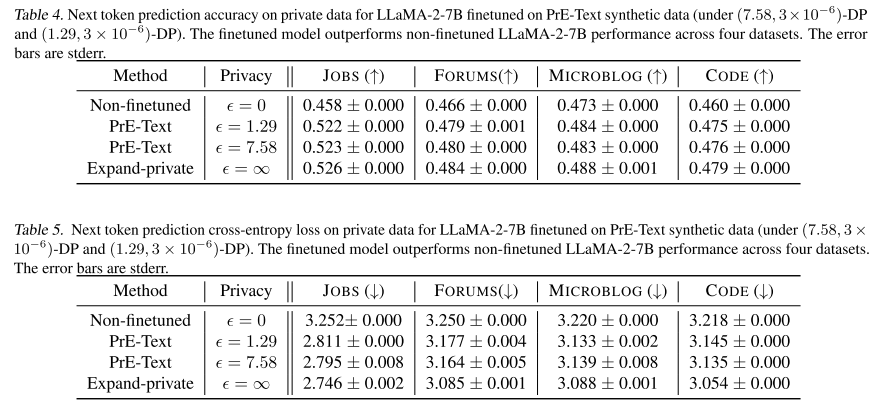
-
PrE-Text 合成数据微调的 LLaMA-2-7B 优于零样本 LLaMA-2-7B。
-
说明:PrE-Text 提供了一种 在联邦学习场景下,隐私合规地微调大规模 LLM 的新方法。
-
贡献:这是 首次展示 如何在隐私约束下,对无法放在设备上的大模型(LLM)进行联邦场景下的微调。
-
意义:
-
目前大模型厂商已经逐渐 耗尽公开训练数据。
-
PrE-Text 提供了一条新路径:合成隐私数据 到 微调大模型 到 合理利用私有用户数据。
-
实验三
1. 实验目的
-
研究 合成数据量多少 对 PrE-Text 最终模型性能的影响。
-
使用的设置:
-
下游模型:DistilGPT2
-
隐私预算:ε = 7.58
-
数据集:4 个私有数据集(JOBS、FORUMS、MICROBLOG、CODE)
-
合成数据规模:从 5万到200万 不等
-
其他实验设置与前面 on-device 实验相同,只是 batch size 按比例缩放。
-
2. 实验结果
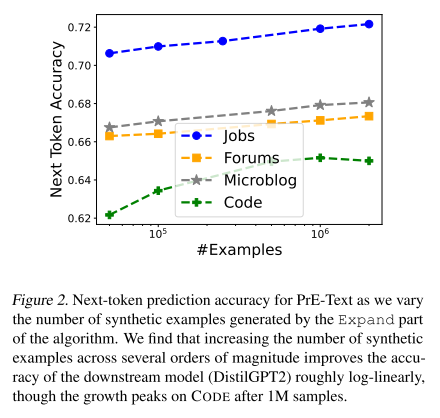
-
总体趋势:
-
模型质量 大致随合成数据量增加而 log 线性提升(对数线性关系),和之前研究 (Honovich et al., 2022) 一致。
-
-
特殊情况:
-
在 CODE 数据集 上,性能在 100万样本左右开始 边际收益递减,在 200万样本时甚至下降。
-
-
结论:
-
最佳的合成数据量 依赖于具体数据集,并不是越多越好。
-
相关工作
1. DP Federated Learning (差分隐私联邦学习)
-
基本思路:模型参数发到用户本地 再 用户在私有数据上训练 再 上传差分隐私化的更新 再 服务器聚合。
-
优化方向:
-
随机打乱(shuffle)来增强隐私 (Bonawitz et al., 2016; Girgis et al., 2021)。
-
先在公开数据上预训练 (Xu et al., 2023c),或者选择最合适的公开数据来预训练 (Hou et al., 2023)。
-
改进 DP-FL 本身(如不依赖随机抽样)。
-
-
挑战:大模型训练越来越受关注,但大部分方法(如让用户训练模型子模块,或者仅调小部分参数)依然要求客户端 存储和推理大模型,这对设备负担很大。
-
相关尝试:有研究尝试用基础模型生成合成数据来辅助训练小模型,但没考虑隐私问题。
2. Synthetic Data (合成数据)
-
趋势:越来越多研究用合成数据训练语言模型。
-
常见做法是设计 prompt 让 ChatGPT 生成数据,再用这些数据微调开源模型(如 LLaMA),来模拟 ChatGPT 的能力。
-
但这些工作 只关注性能提升,没有隐私保证。
-
-
在图像领域:常用 dataset distillation(数据集蒸馏) 方法,也被改进用于联邦场景。
3. DP Synthetic Data (差分隐私合成数据)
-
图像领域:主流方法是用 GAN 或扩散模型 + DP-SGD 来生成 DP 数据。
-
文本领域:
-
Tang et al. (2023) 用 ChatGPT 生成 DP 文本,但需要把私有数据上传到服务器,不符合更严格的威胁模型。
-
Xie et al. (2024) 提出了 private evolution 方法生成 DP 文本,目标是提升数据质量,而本文则关注 DP 合成数据与 on-device 训练的关系。
-
也有研究探索 central-DP(模型开发者直接持有私有数据)下的 LLM 微调。
-
-
最新进展:
-
一些工作探索在 central DP 场景下用 DP 合成数据微调 LLM (Yue et al., Kurakin et al., Yu et al., Ding et al.)。
-
在 federated setting 场景下,Wang et al. (2023a) 和 Wu et al. (2024) 提出:先用 LLM 生成合成数据,再做相关性筛选,然后仍通过 DP-FL 微调。
-
他们提升了预测准确率,但仍然依赖 DP-FL 步骤。
-
-
区别与贡献:
-
这些方法通常是 DP-FL + 合成数据过滤。
-
本文的方法是 直接用 DP 合成数据替代 DP-FL,从而大幅降低客户端负担。
-
两类方法是 互补的,可以结合。
-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)