AI04——RAG的基础概念
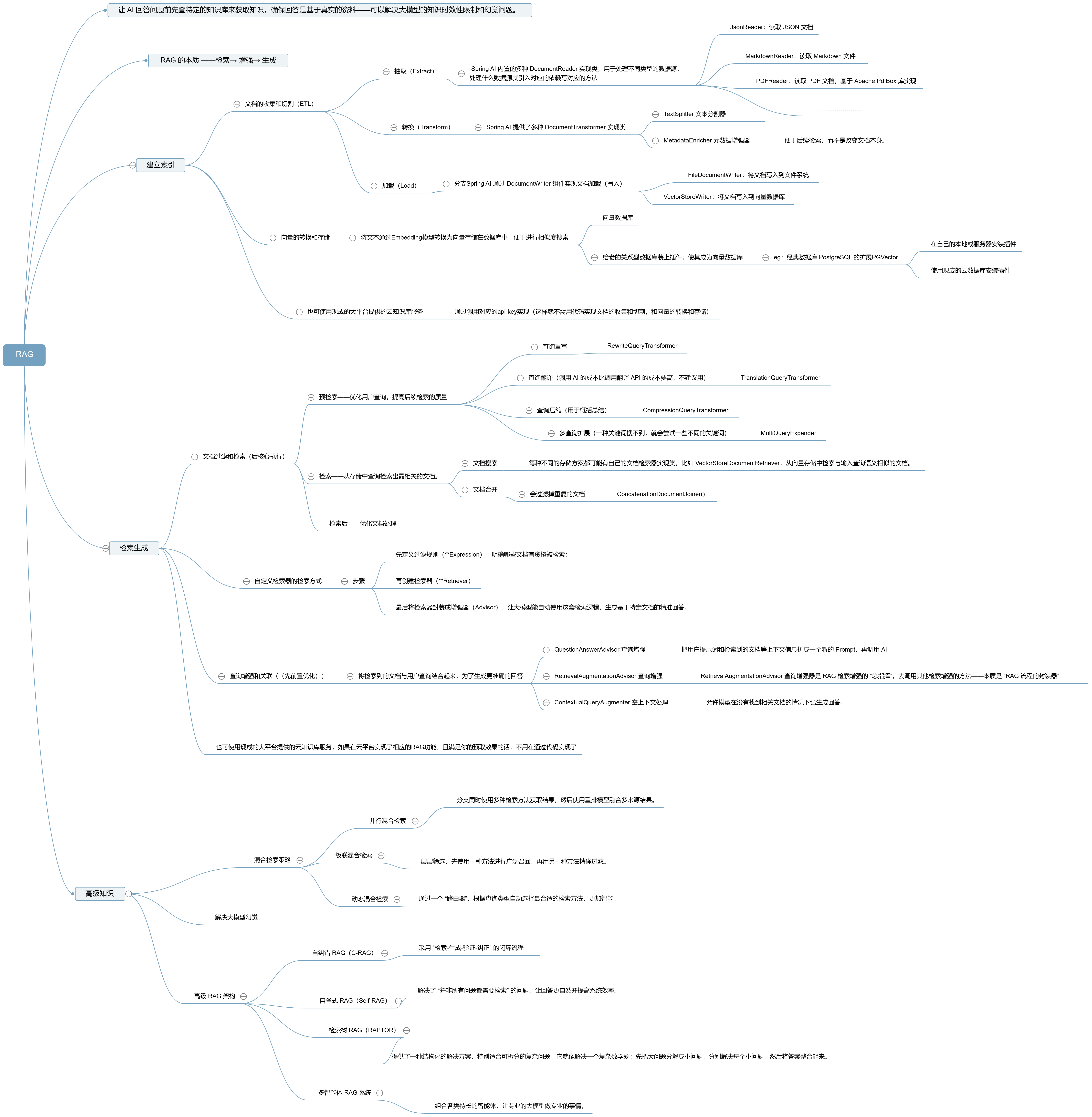
RAG的基础概念
RAG可以解决大模型的知识时效性限制和幻觉问题。 简单来说,RAG 就像给 AI 配了一个 “小抄本”,让 AI 回答问题前先查一查特定的知识库来获取知识,确保回答是基于真实资料而不是凭空想象。
RAG 技术实现主要为 4 个核心步骤:
-
文档收集和切割
-
向量转换和存储
-
文档过滤和检索
-
查询增强和关联
完整工作流程

RAG相关技术的基础概念
Embedding 和 Embedding 模型

向量数据库
向量数据库是专门存储和检索向量数据的数据库系统。通过高效索引算法实现快速相似性搜索
召回/Rank 模型(排序模型)
召回是信息检索中的第一阶段,是从大规模数据集中粗略的快速筛选出可能相关的内容
Rank 模型(排序模型)负责对召回阶段筛选出的候选集进行精确排序,考虑多种特征评估相关性。

混合检索策略
混合检索策略结合多种检索方法的优势(关键词检索、语义检索),可以提高搜索效果。
文档收集和切割 - ETL
文档收集和切割阶段,我们要对自己准备好的文档进行处理,然后保存到向量数据库中。这个过程俗称 ETL(抽取、转换、加载)
ETL 的 3 大核心组件,按照顺序执行:
-
DocumentReader:读取文档,得到文档列表
-
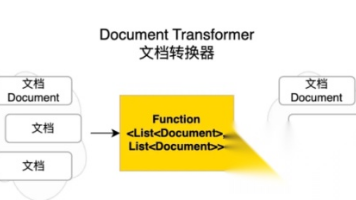
DocumentTransformer:转换文档,得到处理后的文档列表
-
DocumentWriter:将文档列表保存到存储中(可以是向量数据库,也可以是其他存储)
抽取(Extract)
Spring AI 通过 DocumentReader 组件实现文档抽取(通常把文档加载到内存中)。
DocumentReader 接口实现了 Supplier<List<Document>> 接口,主要负责从各种数据源读取数据并转换为 Document 对象集合。
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return get();
}
}
实际开发中,我们可以直接使用 Spring AI 内置的多种 DocumentReader 实现类,用于处理不同类型的数据源:
-
JsonReader:读取 JSON 文档
-
TextReader:读取纯文本文件
-
MarkdownReader:读取 Markdown 文件
-
PDFReader:读取 PDF 文档,基于 Apache PdfBox 库实现
-
PagePdfDocumentReader:按照分页读取 PDF
-
ParagraphPdfDocumentReader:按照段落读取 PDF
-
HtmlReader:读取 HTML 文档,基于 jsoup 库实现
例如
// 从 classpath 下的 JSON 文件中读取文档
@Component
class MyJsonReader {
private final Resource resource;
MyJsonReader(@Value("classpath:products.json") Resource resource) {
this.resource = resource;
}
// 基本用法
List<Document> loadBasicJsonDocuments() {
JsonReader jsonReader = new JsonReader(this.resource);
return jsonReader.get();
}
// 指定使用哪些 JSON 字段作为文档内容
List<Document> loadJsonWithSpecificFields() {
JsonReader jsonReader = new JsonReader(this.resource, "description", "features");
return jsonReader.get();
}
// 使用 JSON 指针精确提取文档内容
List<Document> loadJsonWithPointer() {
JsonReader jsonReader = new JsonReader(this.resource);
return jsonReader.get("/items"); // 提取 items 数组内的内容
}
}
转换(Transform)
Spring AI 通过 DocumentTransformer 组件实现文档转换。
文档转换是保证 RAG 效果的核心步骤,将大文档合理拆分为便于检索的知识碎片
Spring AI 提供了多种 DocumentTransformer 实现类,可以简单分为 3 类。
TextSplitter 文本分割器
TextSplitter 是文本分割器的基类,提供了分割单词的流程方法,对抽取的原始数据进行清洗、格式转换、拆分、整合等处理
TokenTextSplitter
TokenTextSplitter 是其实现类,基于 Token 的文本分割器。 TokenTextSplitter 提供了两种构造函数选项:
-
TokenTextSplitter():使用默认设置创建分割器。 -
TokenTextSplitter(int defaultChunkSize, int minChunkSizeChars, int minChunkLengthToEmbed, int maxNumChunks, boolean keepSeparator):使用自定义参数创建分割器,通过调整参数,可以控制分割的粒度和方式,适应不同的应用场景。
@Component
class MyTokenTextSplitter {
public List<Document> splitDocuments(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter();
return splitter.apply(documents);
}
public List<Document> splitCustomized(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter(1000, 400, 10, 5000, true);
return splitter.apply(documents);
}
}
MetadataEnricher 元数据增强器
元数据增强器的作用是为文档补充更多的元信息,便于后续检索,而不是改变文档本身。
-
KeywordMetadataEnricher:使用 AI 提取关键词并添加到元数据
-
SummaryMetadataEnricher:使用 AI 生成文档摘要并添加到元数据。不仅可以为当前文档生成摘要,还能关联前一个和后一个相邻的文档,让摘要更完整。
@Component
class MyDocumentEnricher {
private final ChatModel chatModel;
MyDocumentEnricher(ChatModel chatModel) {
this.chatModel = chatModel;
}
// 关键词元信息增强器
List<Document> enrichDocumentsByKeyword(List<Document> documents) {
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(this.chatModel, 5);
return enricher.apply(documents);
}
// 摘要元信息增强器
List<Document> enrichDocumentsBySummary(List<Document> documents) {
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryType.PREVIOUS, SummaryType.CURRENT, SummaryType.NEXT));
return enricher.apply(documents);
}
}
ContentFormatter 内容格式化工具
用于统一文档内容格式。比较小fw
加载(Load)
Spring AI 通过 DocumentWriter 组件实现文档加载(写入)。
Spring AI 提供了 2 种内置的 DocumentWriter 实现:
1)FileDocumentWriter:将文档写入到文件系统
@Component
class MyDocumentWriter {
public void writeDocuments(List<Document> documents) {
FileDocumentWriter writer = new FileDocumentWriter("output.txt", true, MetadataMode.ALL, false);
writer.accept(documents);
}
}
2)VectorStoreWriter:将文档写入到向量数据库
@Component
class MyVectorStoreWriter {
private final VectorStore vectorStore;
MyVectorStoreWriter(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
public void storeDocuments(List<Document> documents) {
vectorStore.accept(documents);
}
}
ETL 流程示例
// 抽取:从 PDF 文件读取文档
PDFReader pdfReader = new PagePdfDocumentReader("knowledge_base.pdf");
List<Document> documents = pdfReader.read();
// 转换:分割文本并添加摘要
TokenTextSplitter splitter = new TokenTextSplitter(500, 50);
List<Document> splitDocuments = splitter.apply(documents);
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryType.CURRENT));
List<Document> enrichedDocuments = enricher.apply(splitDocuments);
// 加载:写入向量数据库
vectorStore.write(enrichedDocuments);
// 或者上述使用链式调用
vectorStore.write(enricher.apply(splitter.apply(pdfReader.read())));
相关知识点
文档的质量决定了 AI 回答能力的上限,因此,文档处理是 RAG 系统中最基础也最重要的环节。
优化原始文档
可以把准备好的文档和以下的条件给ai,让ai帮助优化文档
在知识完整的前提下,我们要注意 3 个方面:
1)内容结构化:
-
原始文档应保持排版清晰、结构合理,如案例编号、项目概述、设计要点等
-
文档的各级标题层次分明,各标题下的内容表达清晰
-
列表中间的某一条之下尽量不要再分级,减少层级嵌套
2)内容规范化:
-
语言统一:确保文档语言与用户提示词一致(比如英语场景采用英文文档),专业术语可进行多语言标注
-
表述统一:同一概念应使用统一表达方式(比如 ML、Machine Learning 规范为“机器学习”),可通过大模型分段处理长文档辅助完成
-
减少噪音:尽量避免水印、表格和图片等可能影响解析的元素
3)格式标准化:
-
优先使用 Markdown、DOC/DOCX 等文本格式(PDF 解析效果可能不佳),可以通过百炼 DashScopeParse 工具将 PDF 转为Markdown,再借助大模型整理格式
-
如果文档包含图片,需链接化处理,确保回答中能正常展示文档中的插图,可以通过在文档中插入可公网访问的 URL 链接实现
文档切片与元数据标注
元信息——为文档添加丰富的结构化信息,形成多维索引,便于后续向量化处理和精准检索。
-
本地向量存储:强制使用编码实现的文档切片与元信息的添加(
MyTokenTextSplitter)。 -
云平台向量存储:自动使用云平台的切片能力,与元信息的添加,编码切片逻辑不生效。
最佳文档切片策略是 结合智能分块算法和人工二次校验。
编码实现的文档切片与元信息的两种方式
1.在把文件解析为Document对象时,并添加最基础的元数据(如filename、status,这些元数据与 “加载行为” 强相关)。
/**
* 应用文档加载器——将相关的 Markdown 格式知识文档加载到系统中,作为 AI 模型的知识来源
*/
@Slf4j
@Component
public class LoveAppDocumentLoader {
//用spring内置的资源解析类——用构造函数的方法注入
private final ResourcePatternResolver resourcePatternResolver;//这是 Spring 提供的资源解析器,用于加载类路径下的资源
//通过构造函数注入ResourcePatternResolver对象
public LoveAppDocumentLoader(ResourcePatternResolver resourcePatternResolver) {
this.resourcePatternResolver = resourcePatternResolver;
}
//Document Spring AI 框架 中定义的一个特定类,。在 Spring AI中,各种文档读取器都会将文件内容解析为 List<Document> 格式,以便统一处理不同类型的文档。
public List<Document> loadMarkdowns(){
List<Document> allDocuments =new ArrayList<>();
//加载多篇markDown文档
try {
//通过resourcePatternResolver.getResources()方法加载资源
Resource[] resources = resourcePatternResolver.getResources("classpath:document/*.md");//classPath:为设置从类路径下加载文档
for (Resource resource : resources) {
//得到文件名
String filename = resource.getFilename();
// 提取文档倒数第 3 和第 2 个字作为标签
String status = filename.substring(filename.length() - 6, filename.length() - 4);
//指定了如何加载读取Markdown文件
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()//创建MarkdownDocumentReaderConfig配置对象:
.withHorizontalRuleCreateDocument(true) //withHorizontalRuleCreateDocument(true):设置通过水平分隔线 (---) 分割文档
.withIncludeCodeBlock(false)//是否包含代码块
.withIncludeBlockquote(false)//是否包含引用格式
.withAdditionalMetadata("filename", filename)//将文件名存入元数据,为文档加元数据-————给文档内容附加一些额外的描述性信息(不属于文档的内容),但能帮助后续处理(如检索、过滤、溯源等)更高效地进行。
.withAdditionalMetadata("status",status)//从文件名中提取的状态,为文档添加状态
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);
allDocuments.addAll(reader.get());
//reader.get():读取并解析 Markdown 文件,返回Document对象列表
//allDocuments.addAll():将解析得到的文档添加到总文档列表中
}
} catch (IOException e) {
log.error("MarkDowns error", e);
}
return allDocuments;
}
}
2.另一种是载后的数据处理”,与 “加载文档” 本身是独立的流程步骤。(更好)
@Component
/**
* 自定义基于token的切词器(基于编码实现)——不建议自定义去切分,切的不好
*/
class MyTokenTextSplitter {
//第一种拆分方式——使用默认配置的 Token 分割器拆分文档。
public List<Document> splitDocuments(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter();
return splitter.apply(documents);
}
//第二种拆分方式——自定义配置的 Token 分割器拆分文档
public List<Document> splitCustomized(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter(200, 100, 10, 5000, true);
return splitter.apply(documents);
}
}
/**
* 基于ai的文档元信息增强器(为文档补充元信息)-利用 AI 聊天模型为文档自动添加关键词元信息,属于 RAG 流程中文档预处理的一环
*/
@Component
public class MyKeywordEnricher {
@Resource
private ChatModel dashscopeChatModel;
List<Document> enrichDocuments(List<Document> documents) {
//传入两个参数:
//this.dashscopeChatModel:用于生成关键词的 AI 聊天模型。
//指定为每个文档生成的关键词数量。
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(this.dashscopeChatModel, 5);
return enricher.apply(documents);// 对输入的文档列表进行增强处理,返回添加了关键词元数据的文档列表。
}
}
/**
* 把加载好的文档写入基于内存的向量数据库
* 向量数据库配置(初始化基于内存的向量数据库 Bean)
*/
@Configuration//标识该类为 Spring 的配置类,Spring 会扫描并加载其中的配置
public class LoveAppVectorStoreConfig {
//引入刚刚的文档加载器
//加载原始知识库文档(比如本地的 Markdown 文件),这些文档是向量数据的 “来源”,而非 “存储方式”。
@Resource
private LoveAppDocumentLoader loveAppDocumentLoader;
//引入自定义的切词器
@Resource
private MyTokenTextSplitter myTokenTextSplitter;
//引入文档元信息增强器
@Resource
private MyKeywordEnricher myKeywordEnricher;
@Bean//创建一个 Bean 对象,并将其放入 Spring 容器中
//VectorStore(向量存储接口)
VectorStore loveAppVectorStore(EmbeddingModel dashscopeEmbeddingModel) {
//SimpleVectorStore.builder(dashscopeEmbeddingModel):SimpleVectorStore是基于内存的实现,传入嵌入模型(用于文本向量化)
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel)
.build();
// 1. 加载文档(基础加载和拆分)
List<Document> documents = loveAppDocumentLoader.loadMarkdowns();//调用刚刚注入的loveAppDocumentLoader中的loadMarkdowns()方法,获取所有解析后的文档列表
//2. (可选)切分文档(按Token粒度)
// List<Document> splitCustomized = myTokenTextSplitter.splitCustomized(documents);
//3. 增强元信息(添加AI生成的关键词)
List<Document> enrichDocuments = myKeywordEnricher.enrichDocuments(documents);
// 4. 存入向量库
simpleVectorStore.add(enrichDocuments );//将文档添加到向量数据库中,内部会通过传入的EmbeddingModel将文档内容转换为向量
return simpleVectorStore;
}
}
向量转换和存储

VectorStore
向量存储的基本操作,简单来说就是 “增删改查”:
-
添加文档到向量库
-
从向量库删除文档
-
基于查询进行相似度搜索
-
获取原生客户端(用于特定实现的高级操作)
SearchRequest 类构建请求条件
Spring AI 提供了 SearchRequest 类,用于构建相似度搜索请求:
SearchRequest request = SearchRequest.builder()
.query("搜索的查询文本")
.topK(5) // 返回最相似的5个结果
.similarityThreshold(0.7) // 相似度阈值,0.0-1.0之间
.filterExpression("category == 'web' AND date > '2025-05-03'") // 过滤表达式
.build();
List<Document> results = vectorStore.similaritySearch(request);
SearchRequest 提供了多种配置选项:
-
query:搜索的查询文本
-
topK:返回的最大结果数,默认为4
-
similarityThreshold:相似度阈值,低于此值的结果会被过滤掉
-
filterExpression:基于文档元数据的过滤表达式,语法有点类似 SQL 语句,需要用到时查询 官方文档 了解语法即可
向量存储的工作原理
在向量数据库中,查询与传统关系型数据库有所不同。向量库执行的是相似性搜索,而非精确匹配。
-
嵌入转换:当文档被添加到向量存储时,Spring AI 会使用嵌入模型(如 OpenAI 的 text-embedding-ada-002)将文本转换为向量。
-
相似度计算:查询时,查询文本同样被转换为向量,然后系统计算此向量与存储中所有向量的相似度。
-
相似度度量:常用的相似度计算方法包括:
-
余弦相似度:计算两个向量的夹角余弦值,范围在-1到1之间
-
欧氏距离:计算两个向量间的直线距离
-
点积:两个向量的点积值
-
过滤与排序:根据相似度阈值过滤结果,并按相似度排序返回最相关的文档
Spring AI 支持多种向量数据库实现
对于每种 Vector Store 实现,我们都可以参考对应的官方文档进行整合,开发方法基本上一致:先准备好数据源 => 引入不同的整合包 => 编写对应的配置 => 使用自动注入的 VectorStore 即可。
Spring AI Alibaba 已经集成了阿里云百炼平台,如果可以直接使用阿里云百炼平台提供的 云知识库的 API,这样的话就无需手动处理向量的转换与存储细节。
基于 PGVector 实现向量存储
PGVector 是经典数据库 PostgreSQL 的扩展,为 PostgreSQL 提供了存储和检索高维向量数据的能力。
给老的关系数据库加上该插件,使得开发的成本的更低,更被喜欢使用
首先我们准备 PostgreSQL 数据库,并为其添加扩展。有 2 种方式,,可以参考下列文章实现:
-
Linux服务器快速安装PostgreSQL 15与pgvector向量插件实践——第一种是在自己的本地或服务器安装
-
宝塔 PostgreSQL 安装 pgvector 插件实现向量存储—— 第二种是使用现成的云数据库
创建PostgreSQL 数据库并安装PGVector 的插件
下面我们的例子以现成的云数据库为例
进入阿里云官网的——云数据库 RDS PostgreSQL 版
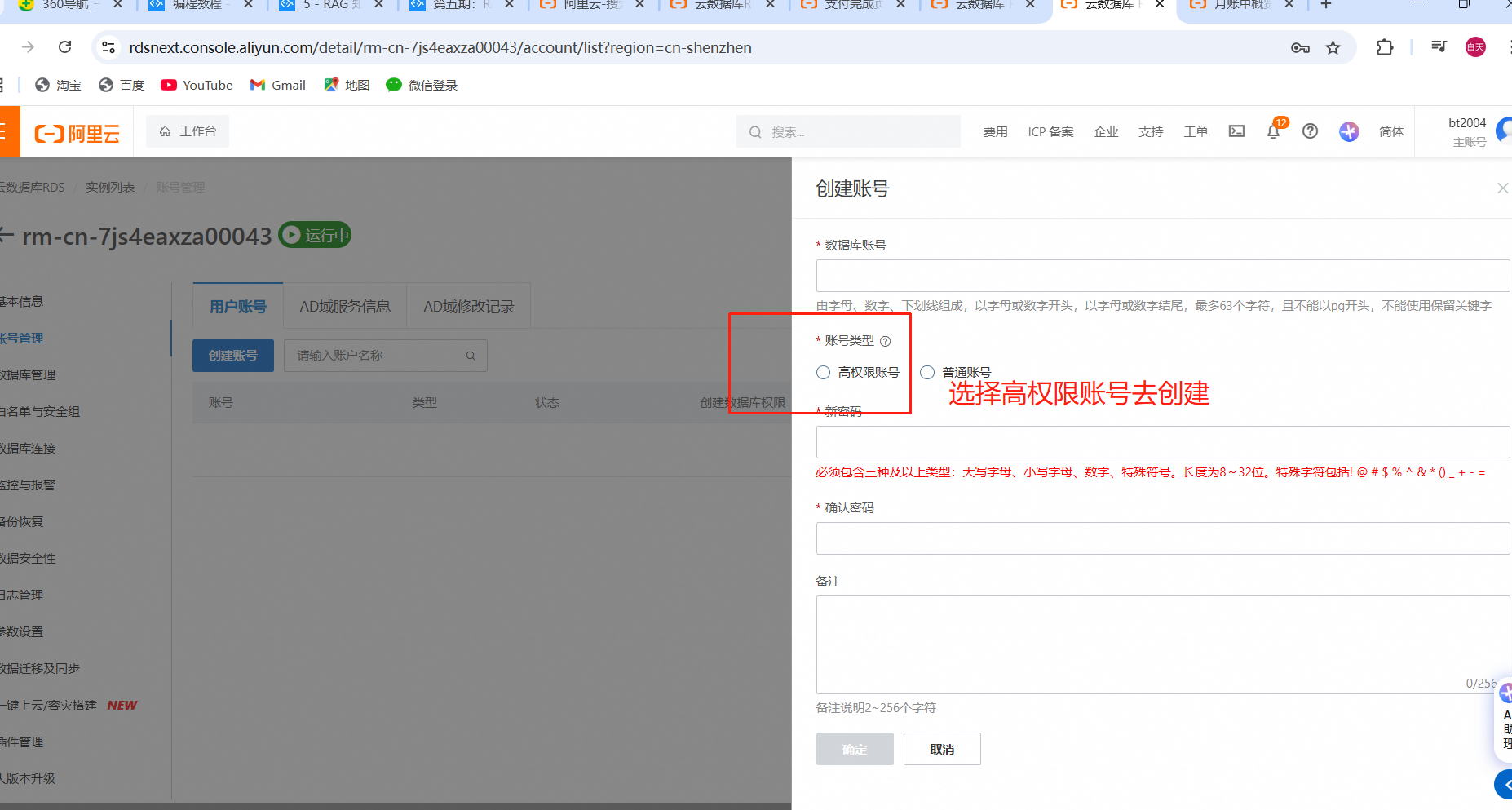
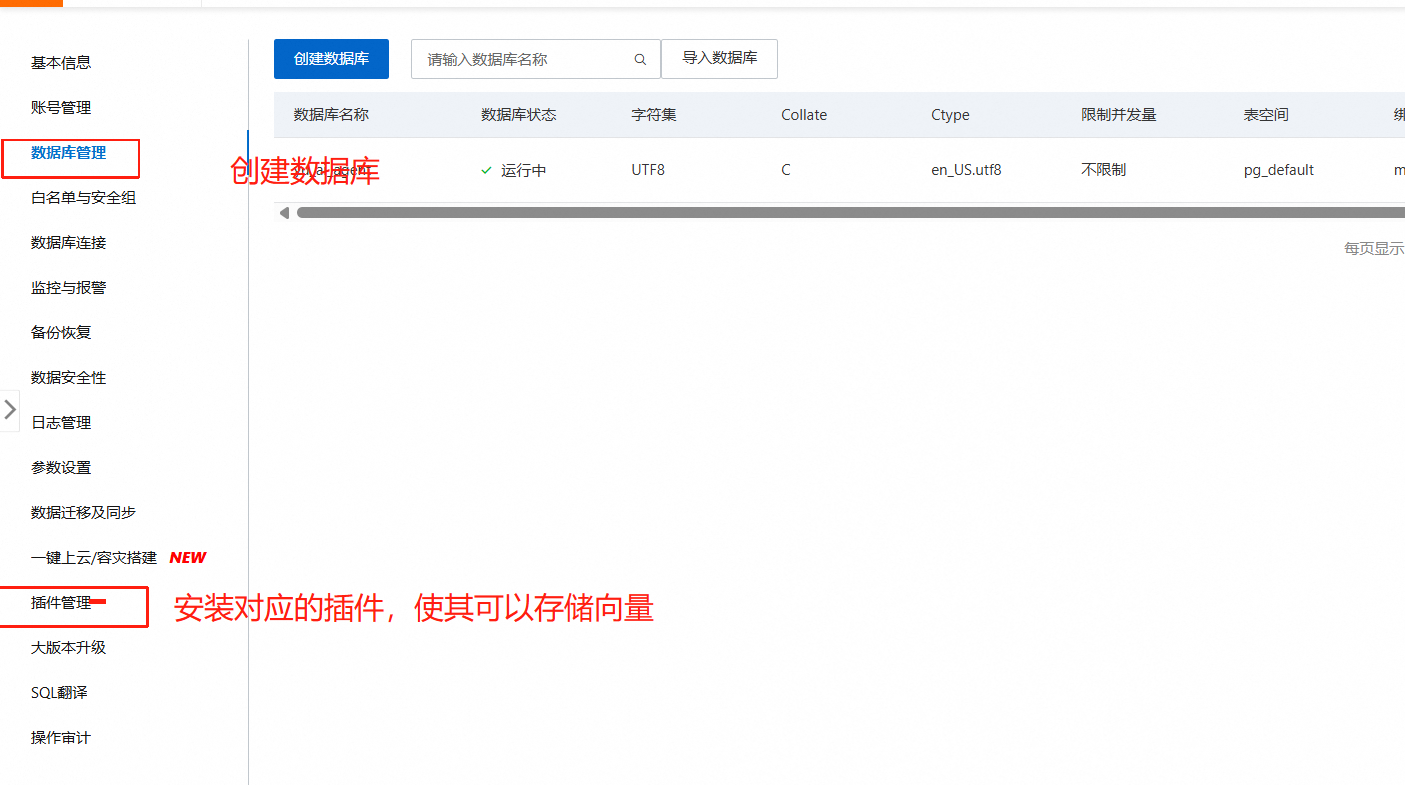
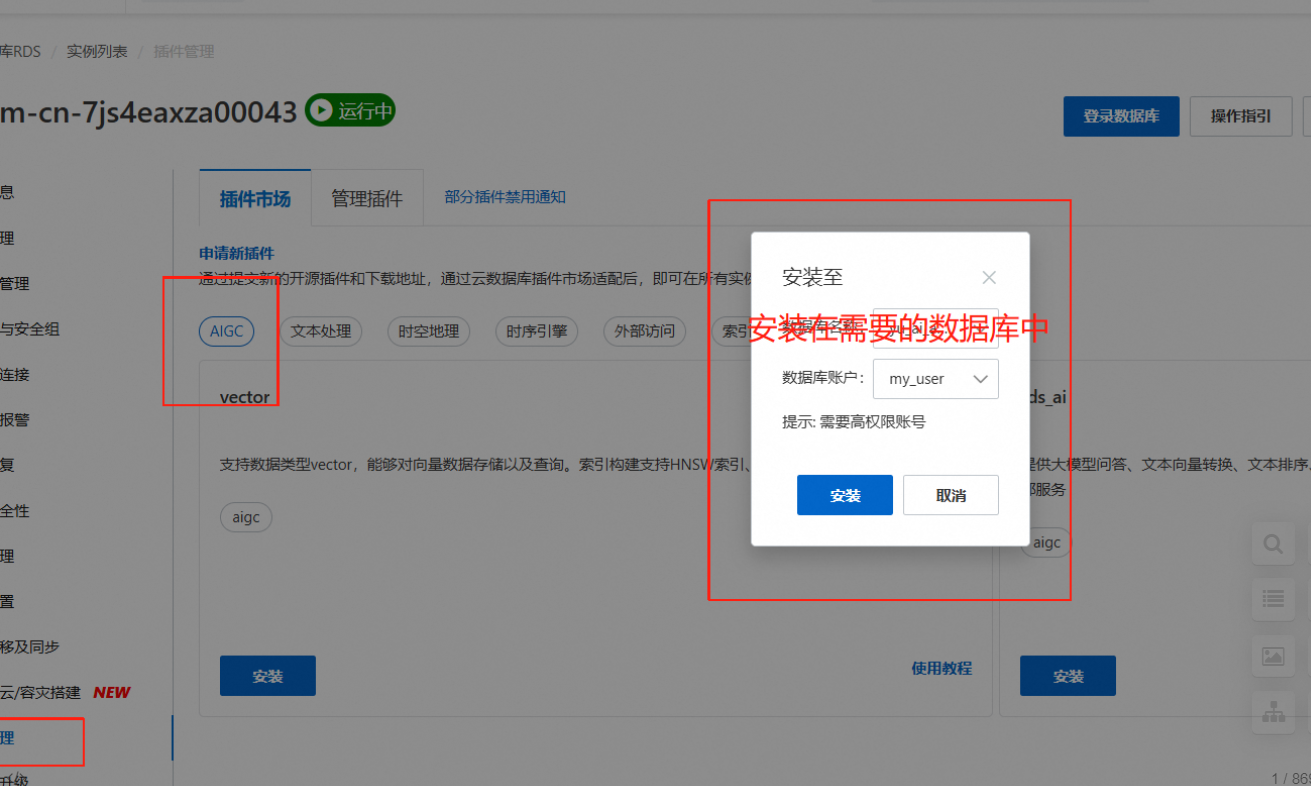
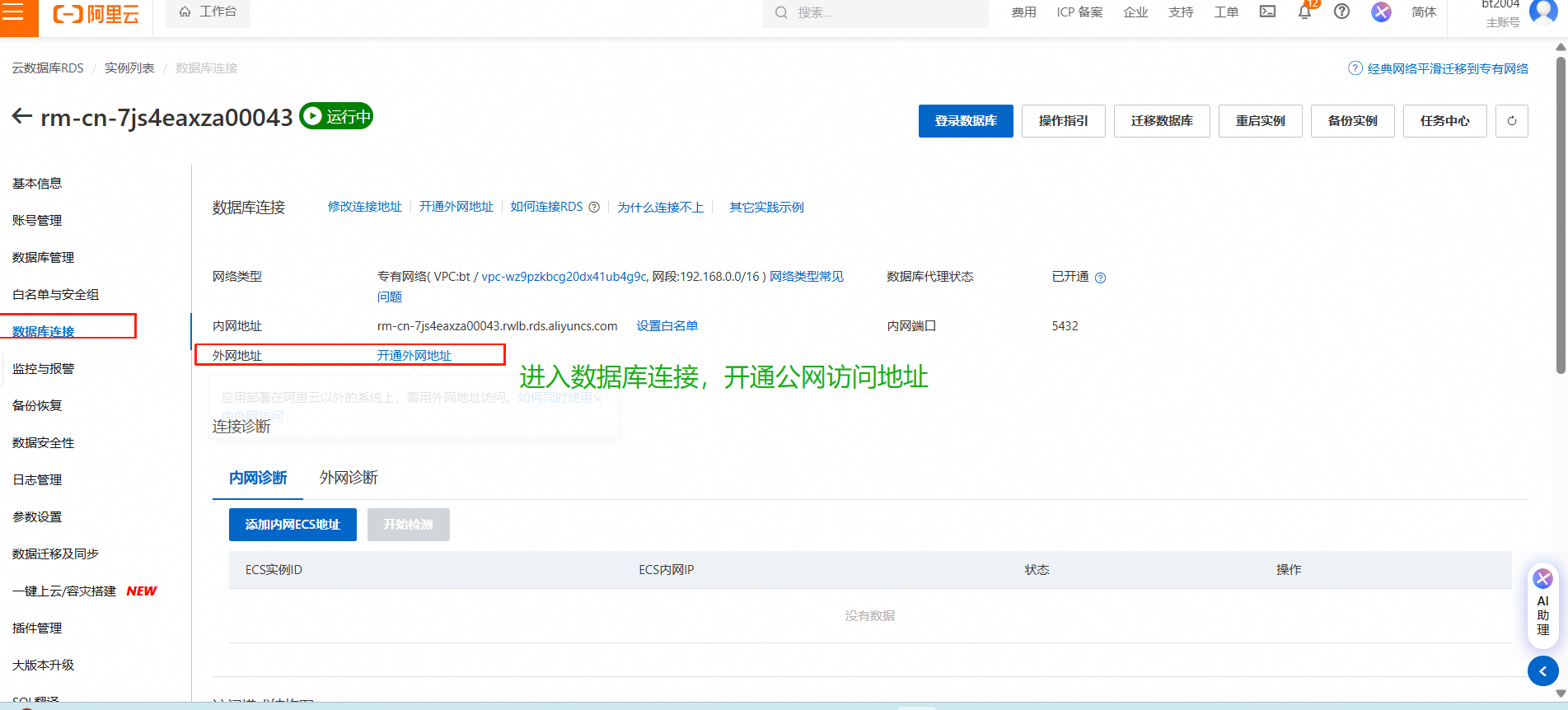
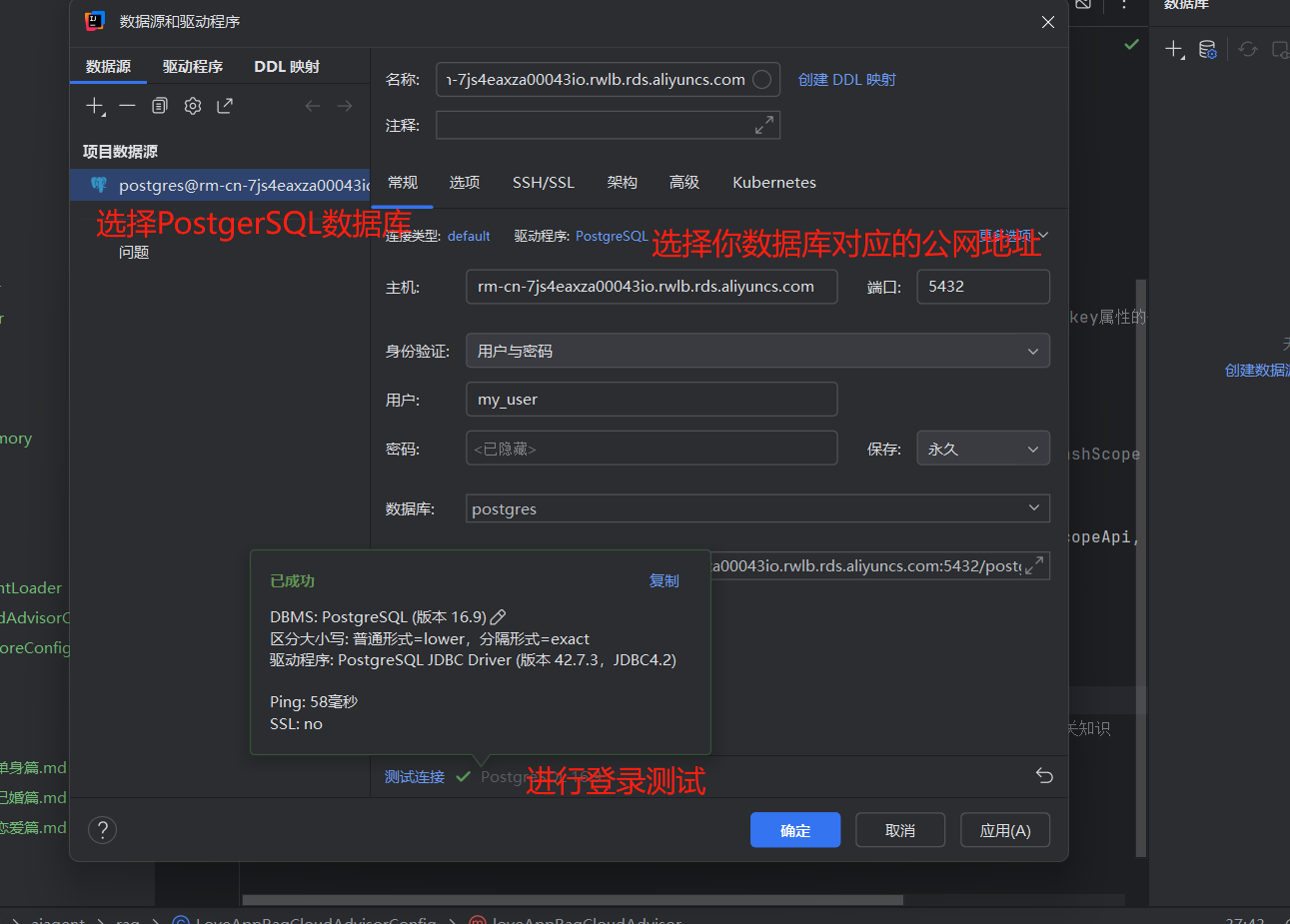 也可也选择在云控制台登录数据库,进行测试
也可也选择在云控制台登录数据库,进行测试 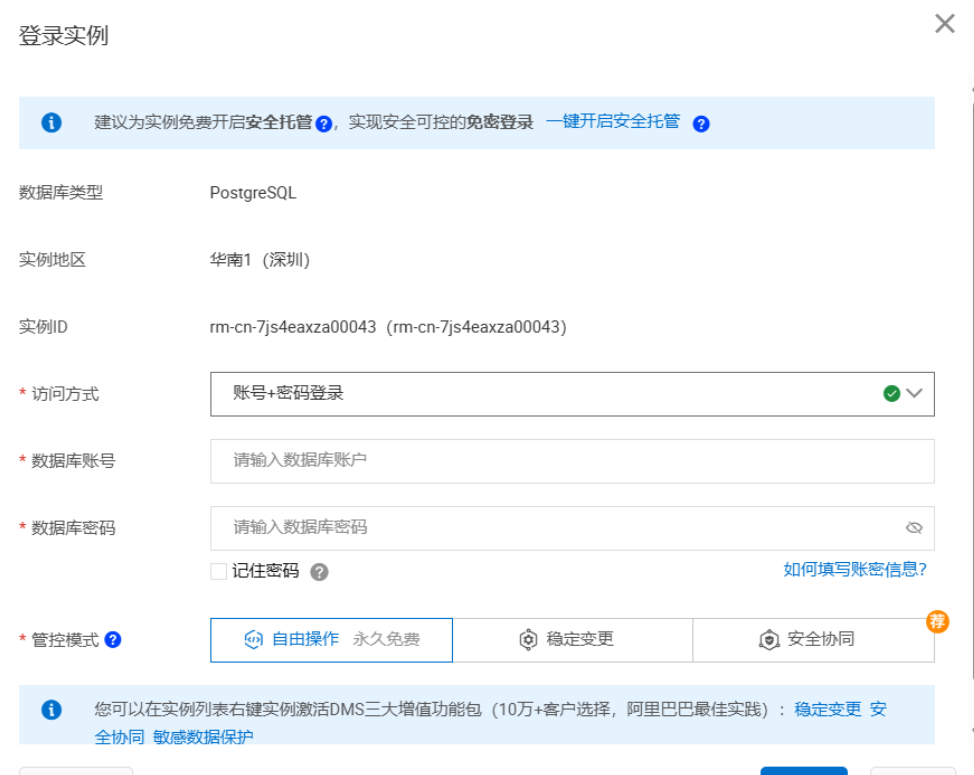
在不用后一定要先删除库,在暂停实例,避免持续扣费!!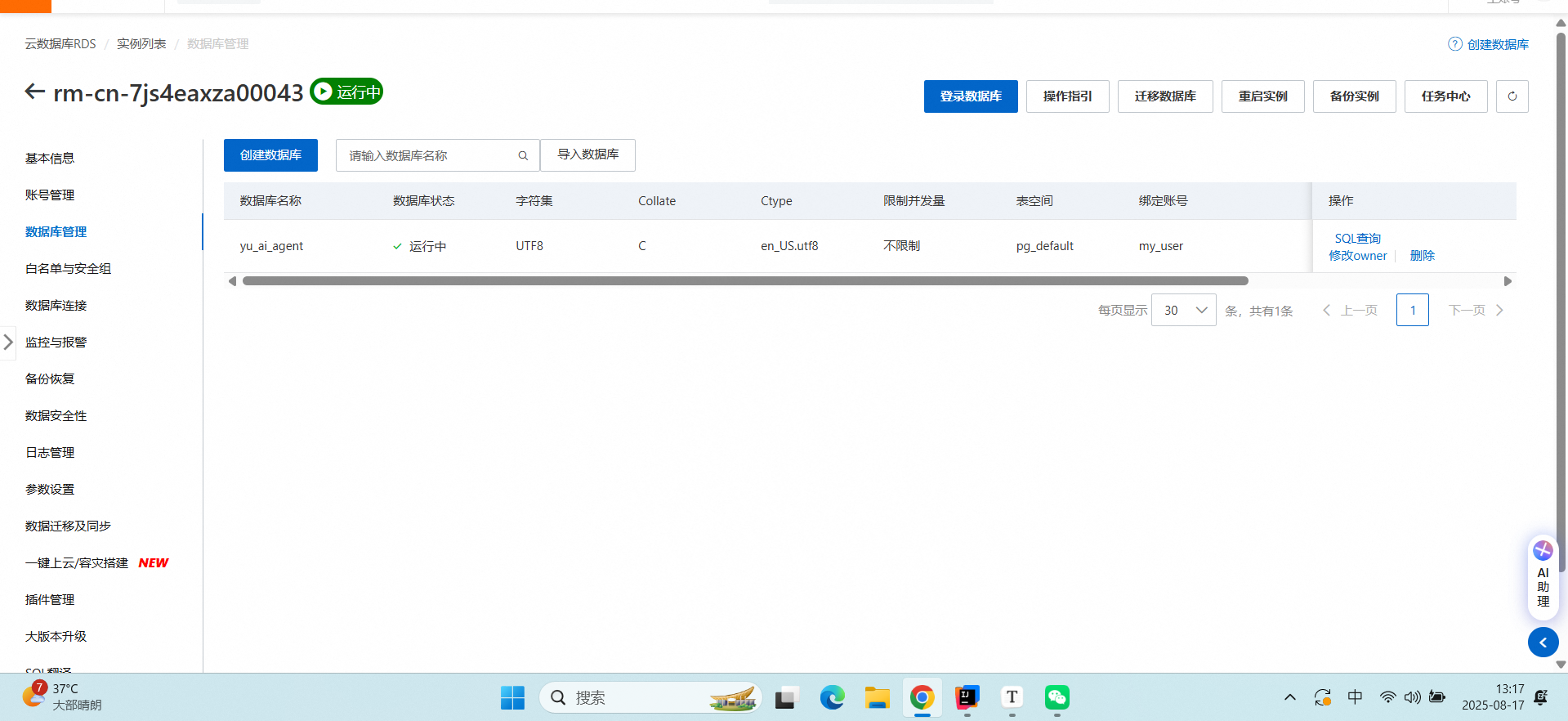
 在创建好数据库后,编写配置,建立数据库连接:
在创建好数据库后,编写配置,建立数据库连接:
先引入依赖,整合 PGVector
参考 Spring AI 官方文档 ,版本号可以在 Maven 中央仓库 查找:
自动整合 PGVector
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pgvector</artifactId>
<version>1.0.0-M7</version>
</dependency>
手动整合 PGVector
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store</artifactId>
<version>1.0.0-M6</version>
</dependency>
编写配置文件,连接数据库
spring:
datasource:
url: jdbc:postgresql://改为你的公网地址:端口号/数据库名
username: 改为你的用户名
password: 改为你的密码
#向量数据库的一些配置(保存到向量数据库中的索引类型,向量的维度,使用的相似度检测方法,单次最多检索多少)
ai:
vectorstore:
pgvector:
index-type: HNSW
dimensions: 1536
distance-type: COSINE_DISTANCE
max-document-batch-size: 10000 # Optional: Maximum number of documents per batch
自动注入VectorStore ,系统会自动创建库表:
VectorStore 依赖 EmbeddingModel 对象,如果同时引入了 Ollama 和 阿里云 Dashscope 的依赖,有两个 EmbeddingModel 的 Bean,Spring 不知道注入哪个,就会报
@Autowired
VectorStore vectorStore;//VectorStore 是 Spring AI 提供的向量存储抽象接口,定义了向量数据库的通用操作(如添加文档、检索相似文档等)。
// 创建文档列表
List<Document> documents = List.of(//List.of(...) 创建了一个包含 3 个 Document 对象的列表,准备批量存入向量数据库。
new Document("文档的内容1", Map.of("meta1", "meta1")),// Map.of,存储文档的附加信息(如来源、标签、创建时间等),方便后续检索时过滤或展示
new Document("文档的内容2"),
new Document("文档的内容3", Map.of("meta2", "meta2")));
//将上面创建的文档列表存入向量数据库
vectorStore.add(documents);
// 检索与查询相似的文档
List<Document> results = this.vectorStore.similaritySearch(SearchRequest.builder()
.query("Spring")// 查询文本
.topK(5).build());// 返回最相似的前5条结果
手动注入VectorStore
引入手动初始PGVector的依赖
然后编写配置类自己构造 PgVectorStore,不用 Starter 自动注入:
//创建配置类-自动初始化bean
//是配置并创建基于 PostgreSQL 的 PgVector 向量存储(向量数据库)实例,用于 RAG(检索增强生成)场景中的知识库向量管理。
@Configuration //@Configuration:Spring 注解,标识这是一个配置类,用于定义 Bean(组件)的创建逻辑。
public class PgVectorVectorStoreConfig {
@Resource
private LoveAppDocumentLoader loveAppDocumentLoader;
@Bean
public VectorStore pgVectorVectorStore(JdbcTemplate jdbcTemplate, EmbeddingModel dashscopeEmbeddingModel) {
//构建 PGVector 向量存储实例
VectorStore vectorStore = PgVectorStore.builder(jdbcTemplate, dashscopeEmbeddingModel)//jdbcTemplate(数据库连接)和 dashscopeEmbeddingModel(文本转向量的模型)
.dimensions(1536) // Optional: defaults to model dimensions or 1536
.distanceType(COSINE_DISTANCE) // Optional: defaults to COSINE_DISTANCE
.indexType(HNSW) // Optional: defaults to HNSW
.initializeSchema(true) // Optional: defaults to false
.schemaName("public") // 连接数据库的名字
.vectorTableName("vector_store") // 向量表名称
.maxDocumentBatchSize(10000) // Optional: defaults to 10000
.build();
// 加载文档
//通过loveAppDocumentLoader.loadMarkdowns()加载文档
//并通过vectorStore.add(documents)将文档转换为向量后存入 PgVector 数据库。
List<Document> documents = loveAppDocumentLoader.loadMarkdowns();
vectorStore.add(documents);
return vectorStore;
}
}
并且启动类要排除掉自动加载 在启动类加上
@SpringBootApplication(exclude = PgVectorStoreAutoConfiguration.class)
文档过滤和检索
简单来说,就是把整个文档过滤检索阶段拆分为:检索前、检索时、检索后。
-
在预检索阶段,接收用户的原始查询,输出增强的用户查询。
-
在检索阶段,使用增强的查询从知识库中搜索相关文档,涉及多个检索源的合并为一组相关文档。
-
在检索后阶段,对检索到的文档进行进一步处理,包括排序、选择最相关的子集以及压缩文档内容,输出经过优化的文档集。
预检索:优化用户查询,提高后续检索的质量
查询转换 - 查询重写
编码实现
RewriteQueryTransformer 使用大语言模型对用户的原始查询进行改写,使其更加清晰和详细。
/**
*查询重写器
*/
@Component
public class QueryRewriter {
//QueryTransformer是 Spring AI 定义的查询转换接口,负责对原始查询进行处理
private final QueryTransformer queryTransformer;
public QueryRewriter(ChatModel dashscopeChatModel) {
//创建ChatClient.Builder(聊天客户端构建器)
ChatClient.Builder builder = ChatClient.builder(dashscopeChatModel);
// 创建查询重写转换器
queryTransformer = RewriteQueryTransformer.builder()//构建查询重写器的具体实现
.chatClientBuilder(builder)//将聊天客户端构建器传入,使其具备调用 AI 模型进行查询重写的能力。
.build();
}
/**
* 执行查询重写
* @param prompt
* @return
*/
public String doQueryRewrite(String prompt) {
//Query是 Spring AI 中用于承载查询信息的专用类
Query query = new Query(prompt);
// 执行查询重写
Query transformedQuery = queryTransformer.transform(query);
// 输出重写后的查询
return transformedQuery.text();
}
}
应用查询重写器:
@Resource
private QueryRewriter queryRewriter;
public String doChatWithRag(String message, String chatId) {
// 查询重写
String rewrittenMessage = queryRewriter.doQueryRewrite(message);
ChatResponse chatResponse = chatClient
.prompt()
.user(rewrittenMessage)//传入查询重写后的结果
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
return content;
}
也可以通过云平台实现相应的RAFG功能
如果在云平台实现了相应的RAG功能,且满足你的预取效果的话,不用在通过代码实现了
在云服务中,可以开启 多轮会话改写 功能
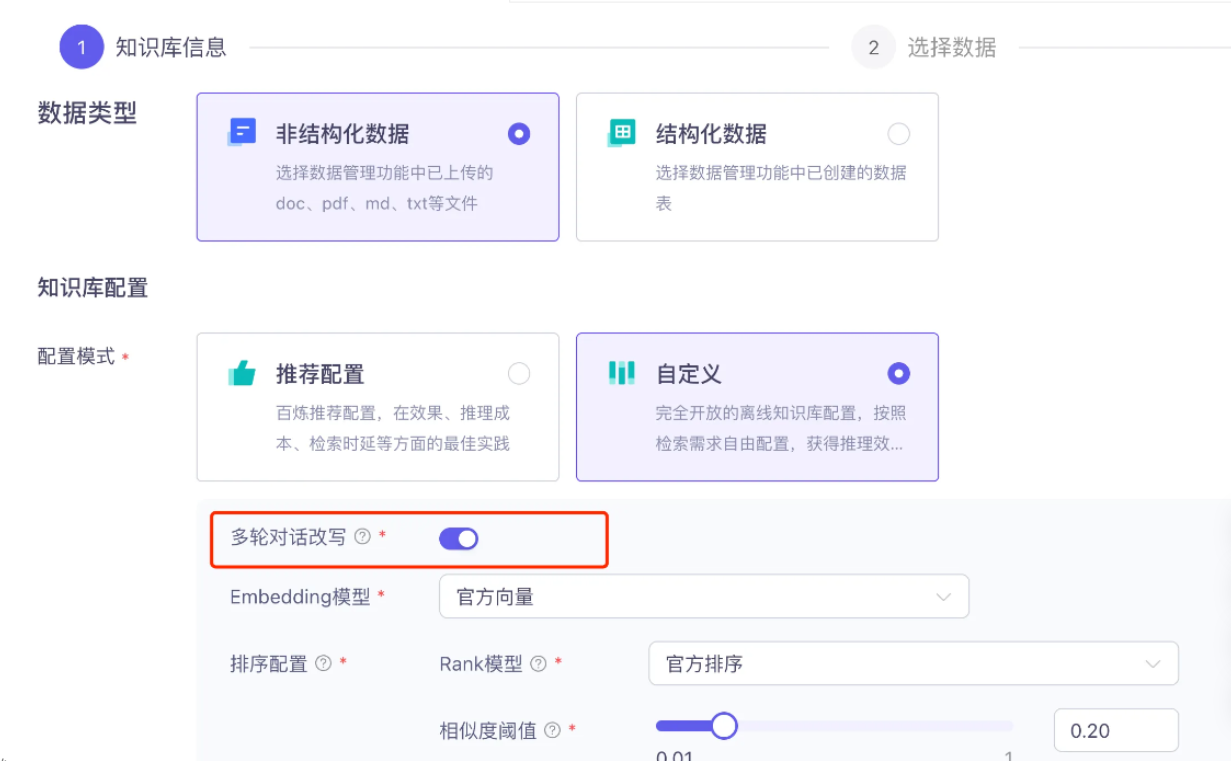
实现原理

也可以通过构造方法的 promptTemplate 参数自定义该组件使用的提示模板。

查询转换 - 查询翻译
不太建议使用这个查询器,因为调用 AI 的成本远比调用第三方翻译 API 的成本要高,如自己有样学样定义一个 QueryTransformer去调用ai。
Query query = new Query("hi, who is coder yupi? please answer me");
QueryTransformer queryTransformer = TranslationQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder)
.targetLanguage("chinese")
.build();
Query transformedQuery = queryTransformer.transform(query);
查询转换 - 查询压缩
类似于概括总结。适用于对话历史较长且后续查询与对话上下文相关的场景。
Query query = Query.builder()
.text("编程导航有啥内容?")
.history(new UserMessage("谁是程序员鱼皮?"),
new AssistantMessage("编程导航的创始人 codefather.cn"))
.build();
QueryTransformer queryTransformer = CompressionQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder)
.build();
Query transformedQuery = queryTransformer.transform(query);
查询扩展 - 多查询扩展
理解为我们在网上搜东西的时候,可能一种关键词搜不到,就会尝试一些不同的关键词。,有助于检索额外的上下文信息并增加找到相关结果的机会。 多查询扩展技术可以扩大检索范围,提高相关文档的召回率。
MultiQueryExpander queryExpander = MultiQueryExpander.builder()
.chatClientBuilder(chatClientBuilder)//将聊天客户端构建器传入,生成扩展查询的大模型客户端构建器
.numberOfQueries(3)
.build();
List<Query> queries = queryExpander.expand(new Query("要查询的问题"));
默认情况下,会在扩展查询列表中包含原始查询。可以在构造时通过 includeOriginal 方法改变这个行为: MultiQueryExpander queryExpander = MultiQueryExpander.builder() .chatClientBuilder(chatClientBuilder) .includeOriginal(false) .build();
检索:提高查询相关性
检索模块负责从存储中查询检索出最相关的文档。
文档搜索
每种不同的存储方案都可能有自己的文档检索器实现类,比如 VectorStoreDocumentRetriever,从向量存储中检索与输入查询语义相似的文档。
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.7)
.topK(5)
.filterExpression(new FilterExpressionBuilder()
.eq("type", "web")
.build())
.build();
List<Document> documents = retriever.retrieve(new Query("问题"));
上述代码中的 filterExpression 可以灵活地指定过滤条件。当然也可以通过构造 Query 对象的 FILTER_EXPRESSION 参数动态指定过滤表达式:
Query query = Query.builder()
.text("问题")
.context(Map.of(VectorStoreDocumentRetriever.FILTER_EXPRESSION, "type == 'boy'"))
.build();
List<Document> retrievedDocuments = documentRetriever.retrieve(query);
文档合并
会过滤掉重复的文档
示例代码如下:
Map<Query, List<List<Document>>> documentsForQuery = ... DocumentJoiner documentJoiner = new ConcatenationDocumentJoiner(); List<Document> documents = documentJoiner.join(documentsForQuery);
看源码发现,其实就是把 Map 展开为二维列表、再把二维列表展开成文档列表,最后进行去重。

检索后:优化文档处理
查询增强和关联
负责将检索到的文档与用户查询结合起来,为 AI 提供必要的上下文,从而生成更准确、更相关的回答。
QuestionAnswerAdvisor 查询增强
当用户问题发送到 AI 模型时,Advisor 会查询向量数据库来获取与用户问题相关的文档,并将这些文档作为上下文附加到用户查询中。
ChatResponse response = ChatClient.builder(chatModel) .build().prompt() .advisors(new QuestionAnswerAdvisor(vectorStore)) .user(userText) .call() .chatResponse();
我们可以通过建造者模式配置更精细的参数,比如文档过滤条件:
var qaAdvisor = QuestionAnswerAdvisor.builder(vectorStore) // 相似度阈值为 0.8,并返回最相关的前 6 个结果 .searchRequest(SearchRequest.builder().similarityThreshold(0.8d).topK(6).build()) .build();
此外,QuestionAnswerAdvisor 还支持动态过滤表达式,可以在运行时根据需要调整过滤条件:spDTaO9GSSfSkKxSKZcQEwrlFnHdInWVZ0So6+LDDQ8=
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(QuestionAnswerAdvisor.builder(vectorStore)//问答检索增强(QuestionAnswerAdvisor),让模型回答时自动从向量存储(vectorStore)中检索相关文档作为参考
.searchRequest(SearchRequest.builder().build())
.build())
.build();
// 在运行时更新过滤表达式
String content = this.chatClient.prompt()
.user("看着我的眼睛,回答我!")
.advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, "type == 'web'"))
.call()
.content();
QuestionAnswerAdvisor 的实现原理很简单,把用户提示词和检索到的文档等上下文信息拼成一个新的 Prompt,再调用 AI:
RetrievalAugmentationAdvisor 查询增强
Spring AI 提供的另一种 RAG 实现方式,它基于 RAG 模块化架构(检索前,中,后),提供了更多的灵活性和定制选项。 RetrievalAugmentationAdvisor 查询增强器可以理解为是 RAG 检索增强的 “总指挥”,去调用其他检索增强的方法
RetrievalAugmentationAdvisor 支持高级的 RAG 流程,比如结合查询转换器:
我们配置了 VectorStoreDocumentRetriever 文档检索器,用于从向量存储中检索文档。然后将这个 Advisor 添加到 ChatClient 的请求中,让它处理用户的问题。
/// 1. 开始构建 RetrievalAugmentationAdvisor(初始化总指挥) Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder() // 2. 配置“检索前查询转换工具”:注入 RewriteQueryTransformer .queryTransformers(RewriteQueryTransformer.builder() // 2.1 为查询转换器配置 ChatClient(用于调用大模型辅助重写查询) .chatClientBuilder(chatClientBuilder.build().mutate()) .build()) // 3. 配置“核心文档检索工具”:注入 VectorStoreDocumentRetriever .documentRetriever(VectorStoreDocumentRetriever.builder() // 3.1 设置检索相似度阈值(低于0.5的文档将被过滤) .similarityThreshold(0.50) // 3.2 指定向量存储(文档数据的存储位置) .vectorStore(vectorStore) .build()) // 4. 完成总指挥的构建 .build(); //使用 “总指挥” 执行检索增强查询 String answer = chatClient.prompt() // 5.1 将“总指挥”加入对话流程 .advisors(retrievalAugmentationAdvisor) // 5.2 传入用户原始问题 .user(question) // 5.3 执行查询并获取结果 .call() // 5.4 提取回答内容 .content();
上述代码中,我们添加了一个 RewriteQueryTransformer,它会在检索之前重写用户的原始查询(和查询重写同理),使其更加明确和详细,从而显著提高检索的质量
// 1. 配置查询增强工具(检索前)
RewriteQueryTransformer queryRewriter = RewriteQueryTransformer.builder()//将原始查询重写
.chatClientBuilder(chatClientBuilder.build().mutate())
.build();
// 2. 配置文档检索工具(核心检索)
VectorStoreDocumentRetriever retriever = VectorStoreDocumentRetriever.builder()//优化后的查询”,从向量存储(VectorStore)中检索出与查询最相关的文档(通过向量相似度计算实现)。
.vectorStore(vectorStore)
.similarityThreshold(0.5)
.build();
// 3. 用 Advisor 整合所有工具(总指挥)
Advisor advisor = RetrievalAugmentationAdvisor.builder()
.queryTransformers(queryRewriter)
.documentRetriever(retriever)
.build();
// 4. 直接使用,无需关心中间流程
String answer = chatClient.prompt()
.advisors(advisor)
.user("Spring AI 如何实现 RAG?")
.call()
.content();
ContextualQueryAugmenter 空上下文处理
默认情况下,RetrievalAugmentationAdvisor 不允许检索的上下文为空。当没有找到相关文档时,它会指示模型不要回答用户查询。这是一种保守的策略,可以防止模型在没有足够信息的情况下生成不准确的回答。
但在某些场景下,我们可能希望即使在没有相关文档的情况下也能为用户提供回答,比如即使没有特定知识库支持也能回答的通用问题。可以通过配置 ContextualQueryAugmenter 上下文查询增强器来实现。示例代码如下:
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder() .documentRetriever(VectorStoreDocumentRetriever.builder() .similarityThreshold(0.50) .vectorStore(vectorStore) .build()) .queryAugmenter(ContextualQueryAugmenter.builder() .allowEmptyContext(true) .build()) .build();
通过设置 allowEmptyContext(true),允许模型在没有找到相关文档的情况下也生成回答。
如果不使用自定义处理器,或者未启用 “允许空上下文” 选项,系统在找不到相关文档时会默认改写用户查询 userText:——改写成默认的输出,我不知道 我们也可以自定义处理逻辑,来运用工厂模式创建一个自定义的 ContextualQueryAugmenter:
/**
* 工厂类——“将对象的创建交给专门的类来处理”,从而提高代码的灵活性、可维护性和复用性。
* 创建 “上下文查询增强器”——限制 AI 的回答范围,确保其只处理相关的查询:
* 用户的问题与恋爱无关时,系统检索不到相关上下文(触发 “空上下文”),
* 增强器会阻止 AI 随意回答,而是返回预设的提示词内容(“抱歉,我只能回答恋爱相关的问题...”)。
*/
public class LoveAppContextualQueryAugmenterFactory {
public static ContextualQueryAugmenter createInstance() {
//定义当系统无法检索到相关上下文时的固定响应
PromptTemplate emptyContextPromptTemplate = new PromptTemplate("""
你应该输出下面的内容:
抱歉,我只能回答恋爱相关的问题,别的没办法帮到您哦
""");
return ContextualQueryAugmenter.builder()
.allowEmptyContext(false)//false表示不允许 “空上下文” 情况,当检索不到与恋爱相关的内容时,不会直接生成回答,而是使用预设的提示词模板。
.emptyContextPromptTemplate(emptyContextPromptTemplate)//指定当出现空上下文时使用的提示词模板
.build();
}
}
给检索增强生成 Advisor 应用自定义的 ContextualQueryAugmenter:
RetrievalAugmentationAdvisor.builder() .documentRetriever(documentRetriever) .queryAugmenter(LoveAppContextualQueryAugmenterFactory.createInstance()) .build();
检索器配置
检索器配置是影响检索质量的关键因素,主要包括三个方面:相似度阈值、返回文档数量和过滤规则。
使用云平台直接配置
云平台提供了更便捷的配置界面,参考文档:
通过编程实现
写一个工厂类 ,根据用户查询需求生成对应的 advisor:
/**
* 创建自定义检索顾问的工厂——根据状态过滤状态不一样的文档
*/
@Slf4j
public class LoveAppRagCustomAdvisorFactory {
public static Advisor createLoveAppRagCustomAdvisor(VectorStore vectorStore, String status) {//vectorStore 向量存储(能存储向量并支持相似度检索和过滤),status 文档的状态标签
//过滤指定的文档——只检索元数据与参数status相等的文档。
Filter.Expression expression = new FilterExpressionBuilder()
.eq("status", status)
.build();
//创建文档检索器,检索器的配置——VectorStoreDocumentRetriever是springAi内置的
//向量存储的文档检索器——DocumentRetriever
DocumentRetriever documentRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.filterExpression(expression) // 过滤条件
.similarityThreshold(0.5) // 相似度阈值
.topK(3) // 返回文档数量
.build();
return RetrievalAugmentationAdvisor.builder()//创建并返回 RAG 检索增强顾问
.documentRetriever(documentRetriever)//指定文档检索器——自定义文档过滤条件
.queryAugmenter(LoveAppContextualQueryAugmenterFactory.createInstance())//传入设置的查询增强器,优化用户的原始查询
.build();
}
}
-
先定义过滤规则(
filterExpression),明确哪些文档有资格被检索; -
再创建检索器(
documentRetriever),将过滤规则、向量存储、检索参数(阈值、数量)绑定到一起,形成完整的检索逻辑; -
最后将检索器封装成增强器(
Advisor),让大模型能自动使用这套检索逻辑,生成基于特定文档的精准回答。
filterExpression 是 documentRetriever 的一个配置项,用于限制检索器的检索范围。
chatClient.advisors( LoveAppRagCustomAdvisorFactory.createLoveAppRagCustomAdvisor( loveAppVectorStore//向量存储实例,增强器从这里检索文档作为大模型的上下文 , "筛选条件" ) )
.builder()建造者模式(基础知识点)
建造者模式提供的方法
documentRetriever(...) 方法——设置 “文档检索器” 组件
queryAugmenter(...) 方法——设置 “查询增强器” 组件
RAG 高级知识
混合检索策略
并行混合检索
同时使用多种检索方法获取结果,然后使用重排模型融合多来源结果。
级联混合检索
层层筛选,先使用一种方法进行广泛召回,再用另一种方法精确过滤。
动态混合检索
通过一个 “路由器”,根据查询类型自动选择最合适的检索方法,更加智能。
大模型幻觉
大模型有时会 胡说八道
大模型的本质——基于已经输出的词,预测下一个词的概率
减少幻觉的方式
1.引入外部知识源,基于检索到的最新、准确的信息来回答问题。 2.“引用标注” 机制,让模型明确指出信息来源于哪个文档的哪个部分——文档预处理:为每个片段添加唯一标识与元数据 3.可以采用“思维链”提高推理透明度,通过引导模型一步步思考,我们能够更好地观察其推理过程,及时发现可能的错误。 4.优化提示词 5.用事实验证模型 检查生成内容的准确性,给回答去打分
高级 RAG 架构
自纠错 RAG(C-RAG)
C-RAG 采用 “检索-生成-验证-纠正” 的闭环流程:先检索文档,生成初步回答,然后验证回答中的每个事实陈述,发现错误就立即纠正并重新生成。这种循环确保了最终回答的高度准确性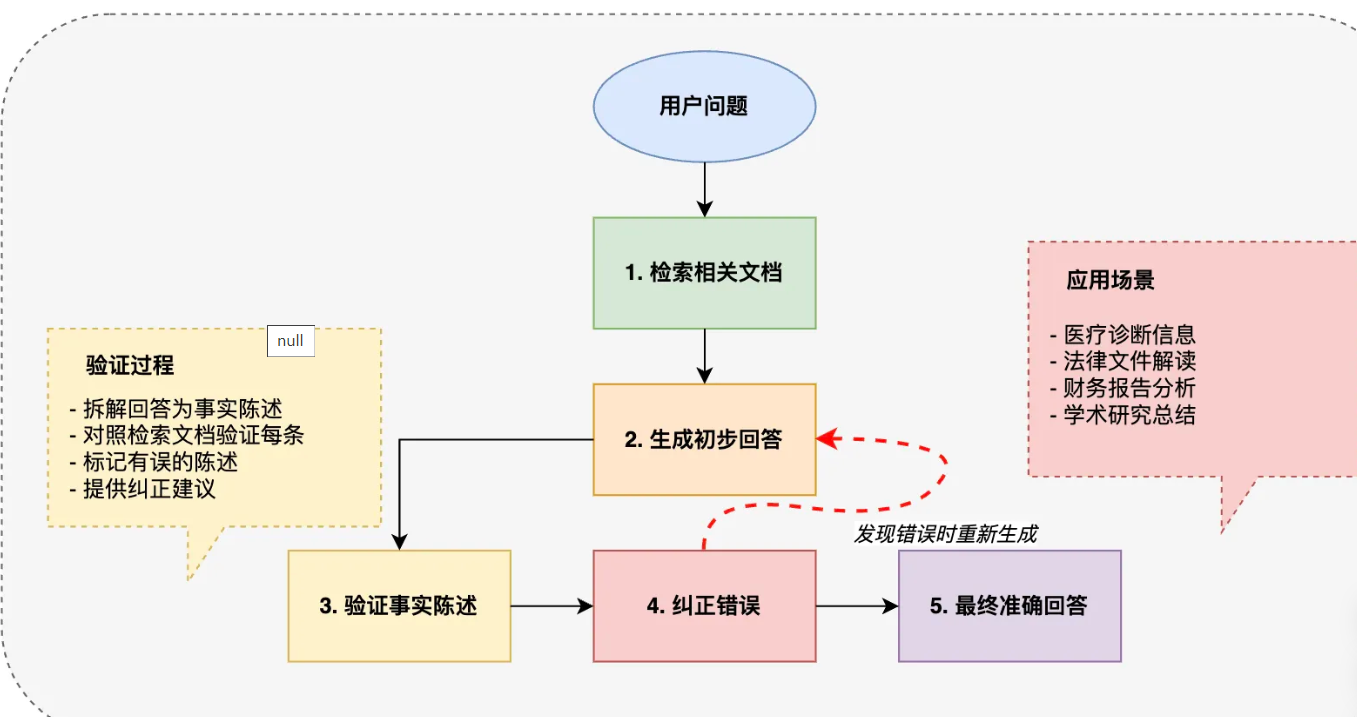
自省式 RAG(Self-RAG)
解决了 “并非所有问题都需要检索” 的问题,让回答更自然并提高系统效率。
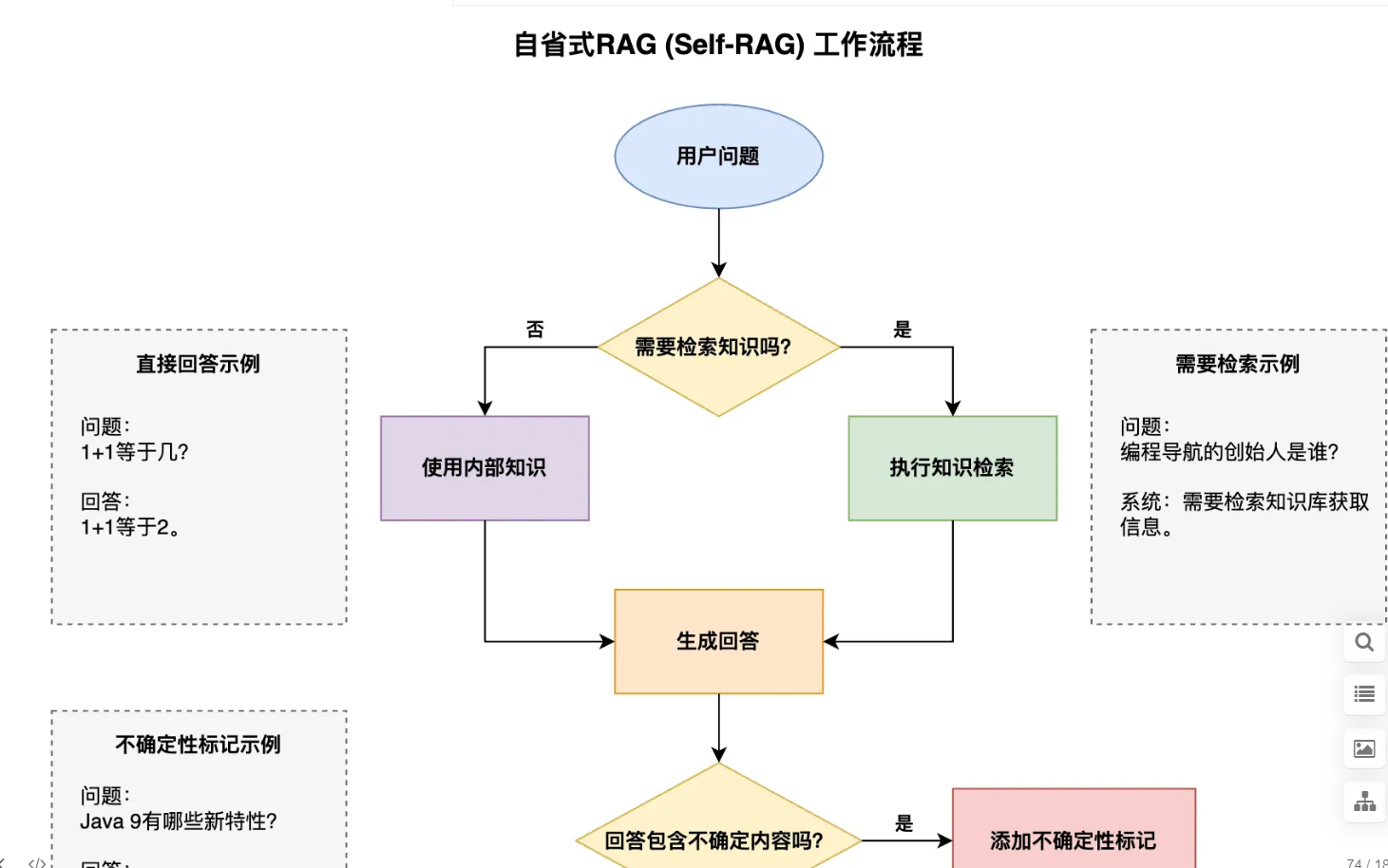
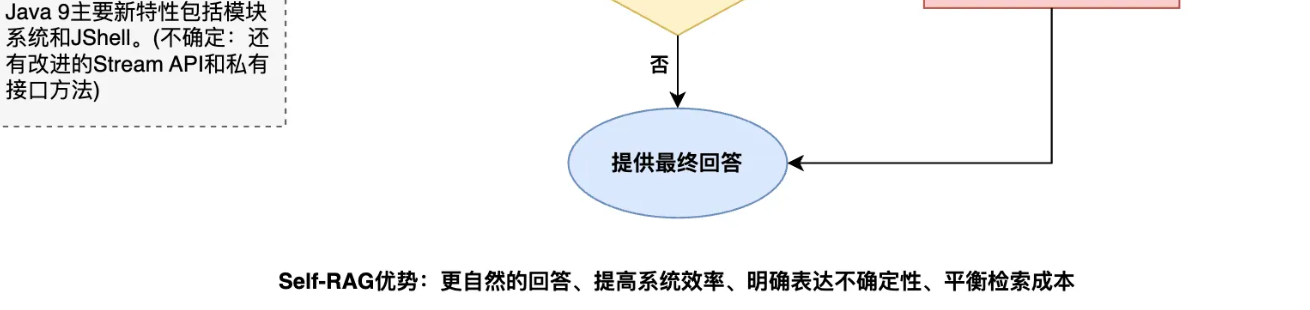
检索树 RAG(RAPTOR)
提供了一种结构化的解决方案,特别适合可拆分的复杂问题。它就像解决一个复杂数学题:先把大问题分解成小问题,分别解决每个小问题,然后将答案整合起来。
多智能体 RAG 系统
组合拥有各类特长的智能体,通过明确的通信协议交换信息,实现复杂任务的协同处理。也就是让专业的大模型做专业的事情。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)