NExT: Teaching Large Language Models toReason about Code Execution
人类开发者的一项基本技能是理解和推理程序的执行过程。例如,程序员可以通过用自然语言在脑海中模拟代码执行来进行调试和修复代码 debug and repair code(即所谓的"橡皮鸭调试" "rubber duck debugging")。然而,代码的大语言模型(LLMs)通常仅基于程序的表面文本形式进行训练,因此可能缺乏对程序运行时语义的理解。但这些方法都需要特定的任务架构或者人工制作的
abstract
核心问题
人类开发者的一项基本技能是理解和推理程序的执行过程。例如,程序员可以通过用自然语言在脑海中模拟代码执行来进行调试和修复代码 debug and repair code(即所谓的"橡皮鸭调试" "rubber duck debugging")。
然而,代码的大语言模型(LLMs)通常仅基于程序的表面文本形式进行训练,因此可能缺乏对程序运行时语义的理解。
研究难点
该问题面临两大挑战:
- 执行跟踪的有效整合(Effective integration of execution traces):如何将程序执行信息融入LLMs的推理过程
- 合成数据生成(Synthetic data generation):开发无需人工标注的高质量训练数据生成方法
相关工作
相关工作包括:
- Program synthesis systems: Rely on specialized neural architectures to model execution states.
(程序合成系统:依赖专用神经架构建模执行状态) - Neural program interpreters: Mimic execution using learned data flow representations.
(神经程序解释器:通过学习数据流表示模拟执行) - Execution trace-driven repair methods: Focus on pairing traces with variable states.
(基于执行跟踪的修复方法:侧重于将跟踪与变量状态配对)
但这些方法都需要特定的任务架构或者人工制作的模板。
NExT方法
我们的方法NExT(自然化执行调整)通过以下创新解决上述问题:
-
Self-training for rationale generation:
自我训练推理生成:利用单元测试的弱监督自举生成执行感知理由数据集 -
Compact execution trace representation:
紧凑的执行跟踪表示:将变量状态编码为内联代码注释,例如#(3)n=1,在保持代码结构的同时增强可读性 -
Chain-of-Thought prompting:
思维链提示:提示LLMs生成自然语言理由与代码修复,实现可解释推理
实验设计
实验在两个程序修复基准数据集上进行:
- MBPP-R: 基于MBPP的10,047个修复任务数据集
- HEFix+: 基于HumanEval构建的更严格评估集
结果与分析
主要发现:
-
Improved fix rates:
- PaLM 2-L+NExT achieves 26.1% absolute improvement on MBPP-R and 14.3% on HEFix+.
(PaLM 2-L+NExT在MBPP-R上绝对提升26.1%,在HEFix+上提升14.3%) - Fixes generated by NExT are verified to pass all test cases.
- PaLM 2-L+NExT achieves 26.1% absolute improvement on MBPP-R and 14.3% on HEFix+.
-
Enhanced rationale quality:
- Automated metrics show 6.3-6.5% improvement in proxy evaluation (smaller LMs guided by NExT-generated rationales).
(代理评估显示小型LLM在NExT生成理由下的修复率提升6.3-6.5%) - Human raters prefer NExT rationales for their clarity in explaining bugs and suggesting fixes.
- Automated metrics show 6.3-6.5% improvement in proxy evaluation (smaller LMs guided by NExT-generated rationales).
-
Generalization capability:
- NExT maintains 40.8% fix rate when execution traces are absent at test time (21.8% higher than baseline).
(测试时无执行跟踪时保持40.8%修复率,较基线提升21.8%)
- NExT maintains 40.8% fix rate when execution traces are absent at test time (21.8% higher than baseline).
1. introduction
人类开发者能够通过自然语言模拟代码执行(如橡皮鸭调试法)理解程序行为,而现有代码大语言模型(LLMs)仅基于程序表面文本训练,缺乏对运行时语义(如变量状态、异常传播)的深层理解,导致复杂任务(如程序修复)表现受限。
程序修复任务的挑战:
- 程序修复需结合运行时信息(如变量值、控制流)定位错误,但传统LLMs难以直接利用这些信息。
- 现有方法(如基于测试用例的修复)依赖大量人工标注或规则设计,缺乏灵活性和可解释性。
研究的难点:
-
执行跟踪的利用难题
- 程序执行跟踪包含丰富的中间状态(如每行代码执行后的变量值),但如何将其转化为LLMs可理解的推理线索是核心挑战。
- 直接将完整跟踪信息作为输入会导致上下文过长(token爆炸),且干扰模型对代码结构的关注。
-
无监督/弱监督训练数据生成
- 传统方法依赖人工标注执行跟踪与修复方案的对应关系,成本高昂。
- 需要设计自动生成高质量训练数据的方法,无需手动标注执行跟踪与修复逻辑的关联。
NExT方法的核心思想
-
自然化执行跟踪
- 将执行跟踪信息内嵌为代码注释(如
#(3) n=1),既保留原始代码结构,又提供关键变量状态的直观视图。
- 将执行跟踪信息内嵌为代码注释(如
for n in list: # (3) n=1; (5) n=2; ...
if n % 2 == 0: # (4) even_list=[1]
...2.自我训练框架
- 利用弱监督信号(单元测试结果) 生成合成训练数据:
- 从基础LLM采样候选修复方案及自然语言理由;
- 通过测试用例验证方案正确性;
- 保留通过验证的样本(理由+修复代码)微调模型。
- 通过多轮迭代逐步提升理由质量和修复成功率。
3.思维链推理与执行感知
- 提示LLM结合执行跟踪生成可解释的修复理由(如“变量
n未按预期递增”),而非仅输出修复代码。 - 通过自然语言推理建立执行状态与修复逻辑的因果联系。
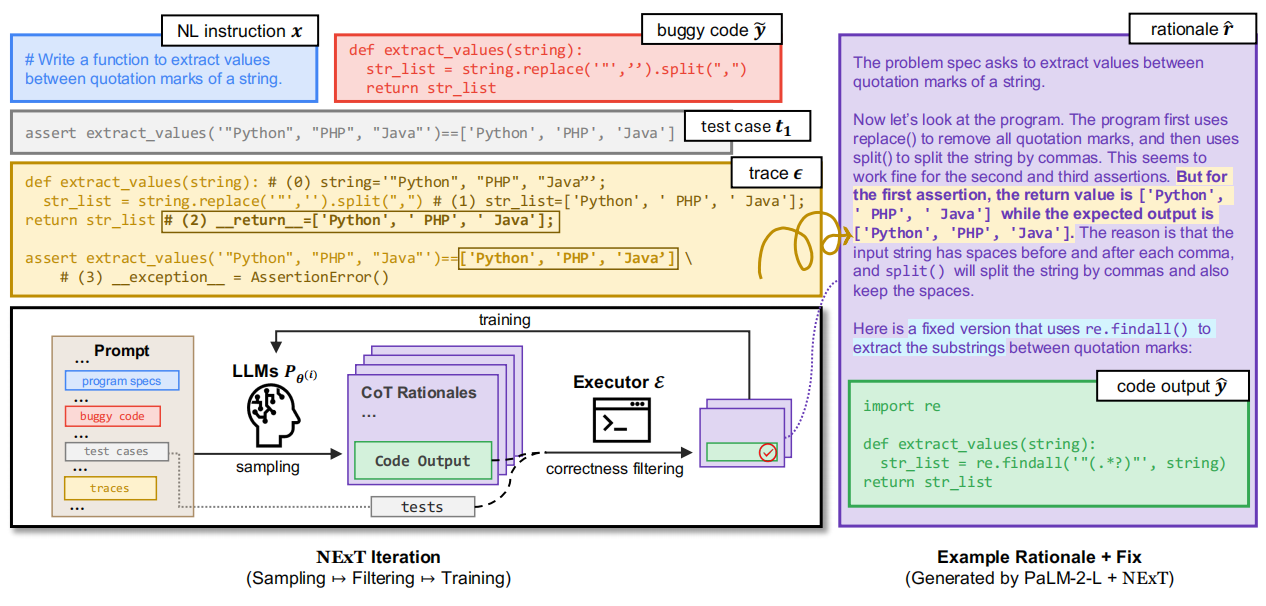
如图1,NEXT编译并调试代码的流程。
2. Task: Program Repair with Traces
3. Preliminary Study: Can LLMs reason with program traces in natural language?
4. NExT: Naturalized Execution Tuning
NExT概述
NExT的核心是一个基于自我训练的迭代框架,旨在通过合成数据提升LLMs的推理能力。具体流程如下:
-
采样理由与修复方案
- 在每次迭代中,从当前模型生成自然语言理由(rationales)和修复代码(fixes)。
- 首轮迭代使用少量示例提示(few-shot prompting),后续迭代采用零样本提示(zero-shot prompting)。
-
过滤候选解
- 使用单元测试结果过滤无效候选解:仅保留通过所有测试的修复方案及其对应理由。
- 通过测试的样本被加入训练集,用于下一轮模型微调。
-
模型微调
- 使用过滤后的数据更新模型参数,最大化生成目标理由和修复代码的概率。
- 每轮迭代后,选择在验证集上表现最佳的模型检查点。

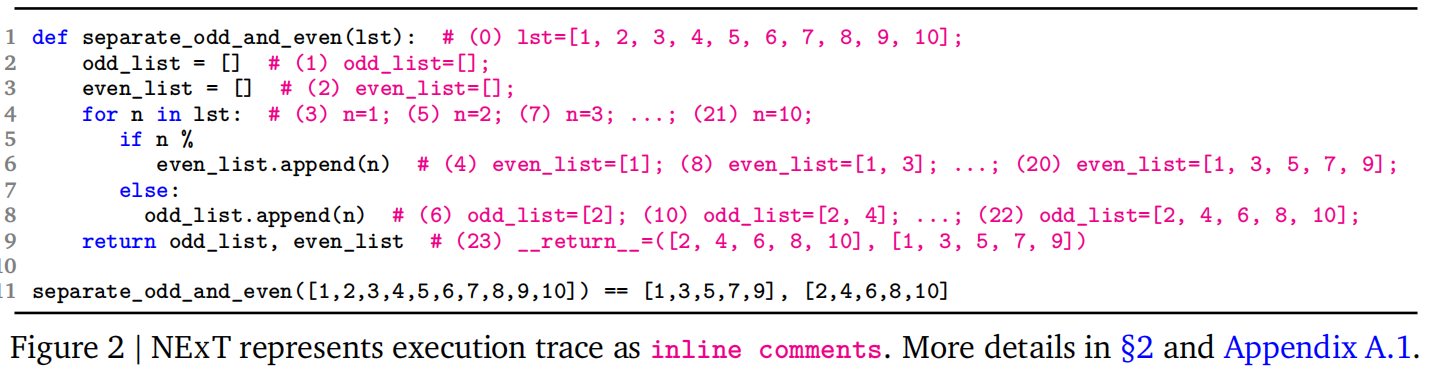
Inline Trace Representation
为降低上下文长度并保持代码结构,NExT提出内联跟踪表示法:
-
变量状态编码
- 仅记录与前一状态不同的变量,使用Python
init函数语法(如#(3) n=1)。 - 对循环中的重复状态进行压缩(如
...表示中间迭代)。
- 仅记录与前一状态不同的变量,使用Python
-
跟踪嵌入代码
- 将变量状态作为内联注释附加到对应代码行后,避免破坏原始代码结构。
- 示例:
for n in list: # (3) n=1; (5) n=2; ... if n % 2 == 0: # (4) even_list=[1] ...
Chain-of-Thought Reasoning with Execution
NExT通过以下设计将执行跟踪融入思维链(CoT)推理:
-
提示工程
- 在输入中拼接任务指令、错误代码、测试用例和执行跟踪(见图1)。
- 要求模型生成自然语言理由(如错误原因、修复策略)和修复代码。
-
动态推理监控
- 通过执行跟踪验证生成的理由是否与实际运行时行为一致(如检测虚假异常声明)。
- 若理由与跟踪矛盾(如声称“变量未定义”但跟踪显示已赋值),则过滤该样本。
模型训练


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)