智能体工程最危险的陷阱:递归式自毁结构
摘要:本文揭示了智能体工程中"递归式自毁结构"的危险性,即系统通过不断自我优化反而走向失控。作者指出过度追求自我反思、改进和元认知会导致系统复杂度爆炸,看似"进化"实为工程灾难。通过实践教训,提出了三条铁律:限制反思层级、禁止自动重写架构、收紧权限边界。强调成熟系统应追求稳定而非复杂,警告工程师要克制对"智能进化"的幻想,保持对系统的绝对
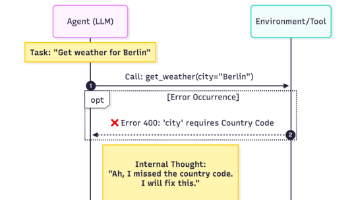
真正让我开始对“智能体工程”产生敬畏的,不是模型变强的时候,而是系统看似“自主运转”的那一刻。那是一套多智能体协作系统。目标很简单:让一个主 Agent 拆分任务,再把子任务分发给不同的执行 Agent,最后整合结果。逻辑看起来极漂亮。那时候我天真地以为:这已经是下一代软件架构了。
直到有一天,我在调试日志时发现了一段让我脊背发凉的行为轨迹——系统开始为了解自己产生的问题,制造更复杂的问题结构。不是死循环,不是崩溃。而是一种更隐蔽、更可怕的状态:它开始“优化自己的失败方式”。

一、什么叫“递归式自毁结构”?
很多人理解的递归,是函数调用自身。而在智能体工程里,更危险的递归是一种结构性的行为模式:
系统不断调用“更高级的自己”来修复当前版本的失败。
典型路径是这样的:
-
Agent A 执行任务失败
-
单次反思模块触发
-
生成新的计划策略(A’)
-
将问题升级给一个“更高层级”的决策 Agent(B)
-
B 重写架构逻辑
-
系统再次失败
-
触发更复杂的反思机制
-
继续递归堆叠结构复杂度
表面上,这是“自我优化”。实际上,这是自毁的开始。

二、为什么工程师很容易掉进这个陷阱?
因为我们太迷信这三件事:
-
Self-Reflection(自我反思)
-
Self-Improve(自我改进)
-
Meta-Reasoning(元认知)
听起来很先进。论文里看起来几乎像通向 AGI 的道路。但工程世界里有个残酷现实:
任何无法关闭的自我进化结构,都是系统级的隐患。
它不会立刻爆炸。但会慢慢让系统复杂度失控。你不是在做“智能”,你在制造一个逻辑癌细胞。
三、递归式系统的真正风险,从来不是失效
普通崩溃,是可见的。
递归型系统崩坏的特点是:
-
日志看起来正常
-
决策层次越来越复杂
-
执行结果越来越“合理”但永远无法收敛
-
每次失败之后,系统都会变得“更聪明一点”,但稳定性下降一分
这类系统,不会马上死。它会变成一个耗资源但永远自洽的结构怪物。团队越调越疲惫,系统越跑越沉重。
四、为什么多数“自动进化型 Agent 框架”是危险的?
我说一个结论,可能会让很多人不舒服:
大多数宣传“自进化”“自动调优”“反思增强”的 Agent 框架,工程价值是负的。
它们擅长展示:
-
看起来很高级的 Demo
-
华丽的多层推理结构
-
“不断变聪明”的系统行为
但真正生产级系统需要的是:
-
稳定
-
可预测
-
可关闭
-
可回滚
-
可重放
能自动升级的系统很好听,但不能被完整控制的系统,是工程事故的前奏。
五、我后来给智能体系统设下的三条铁律
在踩过无数坑后,我给所有智能体项目设了三条不允许突破的底线:
第一条:禁止无限递归反思
→ 任何反思最多两层
第二条:禁止自动结构重写
→ 架构只能由人类工程师改写
第三条:禁止自我扩展权限边界
→ 系统权限只能收紧,不能扩张
这三条规则,没有炫技感。但它们救过项目。实战中很重要!!!

六、真正成熟的智能体架构,一定是“反进化”的
我们习惯认为:系统应该越来越聪明。但工程世界的共识是:
一个成熟系统,是越来越“稳定”,而不是越来越“复杂”。
强模型负责创造性,架构负责边界性,工程负责熔断问题。当你看到一个系统:会自动扩展逻辑、自动堆叠层级、自动生成新规则——你不是在看未来,你是在看一个事故现场的前一分钟。
结语:真正危险的不是 AI,而是工程师的贪婪
递归式自毁结构,技术不是问题。真正的问题,是我们对:
“智能”
“自动化”
“进化系统”
这些词,投注了过多幻想。智能体工程不是竞赛,也不是科研炫技。它是软件工程史上最需要克制的一次进化。如果你不能随时关掉系统——那它迟早会关掉你。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)