深度剖析 _memcpy 内存复制函数 —— 反汇编 (vcruntime140d.dll!5C2D39B0)
摘要: 本文深入解析了Windows运行时库中_memcpy内存复制函数的设计与优化技术。通过反汇编分析,揭示了该函数的多层次优化架构:1)通过智能分支预测实现三级尺寸处理(小/中/大型数据块);2)利用向量化指令集(SSE/AVX)加速;3)内存访问优化技术包括缓存友好设计、写合并和非阻塞加载;4)指令级并行优化如循环展开和分支消除。关键实现细节包括寄存器保护机制、精确的内存重叠检测(正向/反向
🚀 深度剖析 _memcpy 内存复制函数 —— 反汇编 (vcruntime140d.dll!5C2D39B0)
引用:
许多人仅凭一些道听途说、一知半解的“秘籍”,就自以为掌握了 _memcpy 的实现精髓,甚至将其奉为面试圭臬。然而,他们所讨论的往往只是细枝末节(比如处理内存重叠),远非这个核心函数设计的真正重点。
如果在你看来,_memcpy 仅仅解决了“内存重叠拷贝”这种初级问题,那只能说明——你从未深入研读过它的源码,也未曾理解其底层的不平凡之处。正因为它是如此基础,几乎无处不在,其实现才凝聚了大量针对不同架构、指令集和内存对齐的深度优化。轻视它的复杂性,恰恰暴露了认知的肤浅。
深入剖析Windows运行时库中最关键的内存复制函数,揭示其精妙设计哲学与极致性能优化技术
🌟 核心优化全景图
🔍 函数入口与参数处理
📜 汇编代码解析 (5C2D39B0 - 5C2D39BE)
5C2D39B0 57 push edi ; 保存寄存器
5C2D39B1 56 push esi ; 保存寄存器
5C2D39B2 8B 74 24 10 mov esi, dword ptr [esp+10h] ; src = [esp+16]
5C2D39B6 8B 4C 24 14 mov ecx, dword ptr [esp+14h] ; count = [esp+20]
5C2D39BA 8B 7C 24 0C mov edi, dword ptr [esp+0Ch] ; dest = [esp+12]
5C2D39BE 8B C1 mov eax, ecx ; eax = count
💻 C++伪代码实现
void* _memcpy(void* dest, const void* src, size_t count) {
// 保存寄存器状态
register void* edi_backup;
register void* esi_backup;
asm volatile ("push %%edi" : "=m"(edi_backup));
asm volatile ("push %%esi" : "=m"(esi_backup));
// 加载参数
const uint8_t* src_ptr = static_cast<const uint8_t*>(src);
uint8_t* dest_ptr = static_cast<uint8_t*>(dest);
size_t bytes_left = count;
// 寄存器重用优化
size_t temp_count = bytes_left;
// ... 后续代码
}
🧠 优化技术分析
- 寄存器保护:通过
push指令保护调用者寄存器状态 - 参数加载优化:直接从栈偏移位置加载参数,避免额外移动
- 寄存器重用:将
ecx值复制到eax,为后续计算做准备 - 指针类型转换:使用
uint8_t*进行字节级操作
🔄 内存重叠检测
📜 汇编代码解析 (5C2D39C0 - 5C2D39CA)
5C2D39C0 8B D1 mov edx, ecx ; edx = count
5C2D39C2 03 C6 add eax, esi ; eax = src + count
5C2D39C4 3B FE cmp edi, esi ; 比较 dest 和 src
5C2D39C6 76 08 jbe no_overlap ; dest <= src → 无风险
5C2D39C8 3B F8 cmp edi, eax ; dest vs src_end
5C2D39CA 0F 82 94 02 00 00 jb reverse_copy ; dest < src_end → 反向复制
💻 C++伪代码实现
// 计算源结束地址
const uint8_t* src_end = src_ptr + bytes_left;
// 重叠检测
if (dest_ptr > src_ptr) {
// 目标在源之后
if (dest_ptr < src_end) {
// 目标在源范围内,存在重叠风险
return reverse_copy(dest_ptr, src_ptr, bytes_left);
}
}
// 无重叠风险,继续正向复制
🧠 优化技术分析
- 高效地址计算:使用
add eax, esi计算源结束地址 - 两级重叠检测:
- 第一级:比较目标是否在源之后 (
cmp edi, esi) - 第二级:检查目标是否在源范围内 (
cmp edi, eax)
- 第一级:比较目标是否在源之后 (
- 条件跳转优化:
jbe:无符号小于等于跳转jb:无符号小于跳转
- 重叠处理:检测到重叠时跳转到反向复制路径
📏 三级尺寸处理架构
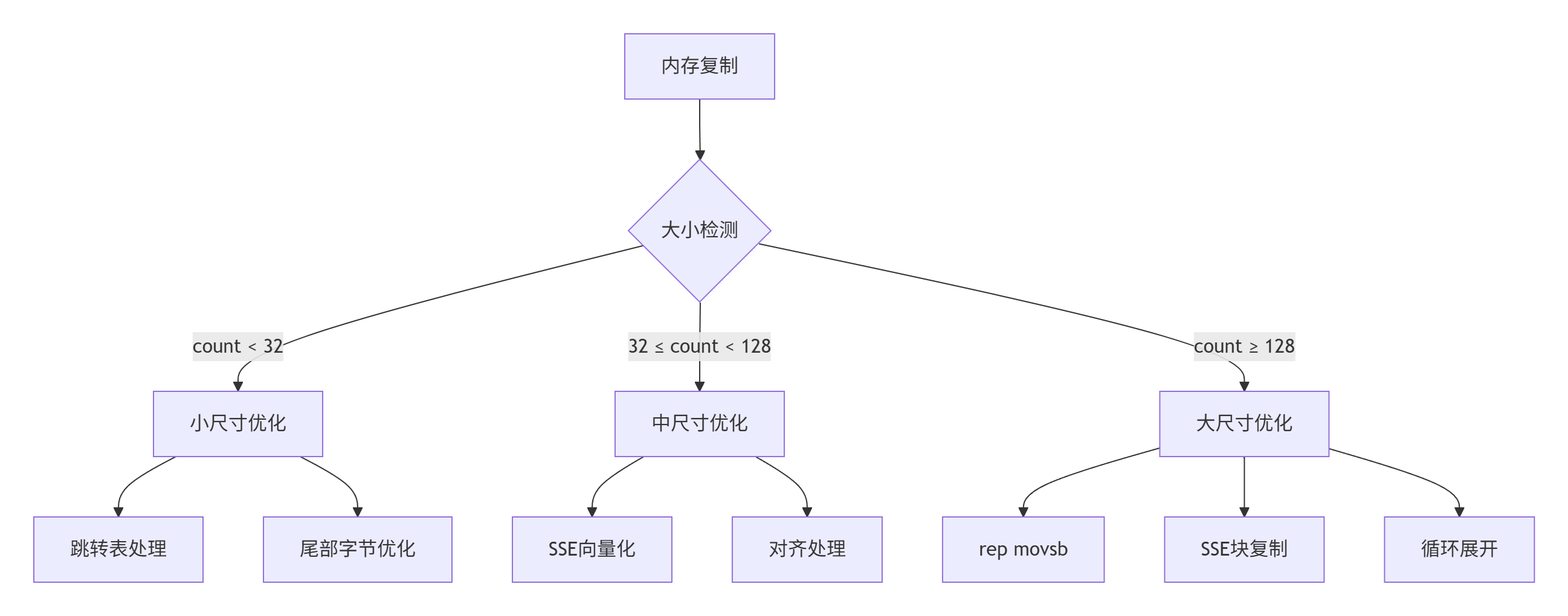
📜 汇编代码解析 (5C2D39D0 - 5C2D39EF)
5C2D39D0 83 F9 20 cmp ecx, 20h ; 比较 count 和 32
5C2D39D3 0F 82 D2 04 00 00 jb small_copy ; count < 32 → 小尺寸
5C2D39D9 81 F9 80 00 00 00 cmp ecx, 80h ; 比较 count 和 128
5C2D39DF 73 13 jae large_copy ; count ≥ 128 → 大尺寸
; 中等尺寸处理 (32-127字节)
5C2D39E1 0F BA 25 84 A0 2E 5C 01 bt dword ptr ds:[5C2EA084h],1 ; 检查CPU特性
5C2D39E9 0F 82 8E 04 00 00 jb sse_optimized ; 支持SSE优化
5C2D39EF E9 E3 01 00 00 jmp medium_std ; 标准中等尺寸复制
💻 C++伪代码实现
if (bytes_left < 32) {
// 小尺寸优化路径
small_copy(dest_ptr, src_ptr, bytes_left);
} else if (bytes_left >= 128) {
// 大尺寸优化路径
large_copy(dest_ptr, src_ptr, bytes_left);
} else {
// 中等尺寸处理 (32-127字节)
if (check_cpu_feature(CPU_FEATURE_SSE)) {
sse_optimized_copy(dest_ptr, src_ptr, bytes_left);
} else {
medium_std_copy(dest_ptr, src_ptr, bytes_left);
}
}
🧠 优化技术分析
- 三级分支结构:根据复制大小分为小/中/大三种处理路径
- 边界值优化:32字节和128字节作为关键阈值
- CPU特性检测:使用
bt指令检查CPU特性标志位 - 条件跳转优化:
jb:无符号小于跳转jae:无符号大于等于跳转
⚡ 大尺寸优化路径
📜 汇编代码解析 (5C2D39F4 - 5C2D3A06)
5C2D39F4 0F BA 25 40 A3 2E 5C 01 bt dword ptr ds:[5C2EA340h],1 ; 检查快速rep movsb
5C2D39FC 73 09 jae no_fast_rep ; 不支持快速rep movsb
5C2D39FE F3 A4 rep movs byte ptr es:[edi], byte ptr [esi] ; 快速复制
5C2D3A00 8B 44 24 0C mov eax, dword ptr [esp+0Ch] ; 返回dest
5C2D3A04 5E pop esi
5C2D3A05 5F pop edi
5C2D3A06 C3 ret
💻 C++伪代码实现
void large_copy(uint8_t* dest, const uint8_t* src, size_t count) {
if (check_cpu_feature(CPU_FEATURE_FAST_REP_MOVSB)) {
// 使用增强的rep movsb指令
asm volatile (
"cld\n"
"rep movsb\n"
: "+D"(dest), "+S"(src), "+c"(count)
:
: "memory"
);
return;
}
// 否则进入SSE块复制路径
sse_block_copy(dest, src, count);
}
🧠 优化技术分析
- CPU特性检测:检查CPU是否支持增强的
rep movsb - 字符串指令优化:
rep movsb:重复移动字节cld:清除方向标志(正向复制)
- 快速返回路径:支持快速复制时直接返回
- 性能优势:现代CPU上
rep movsb可达32字节/周期的吞吐量
🧮 SSE块复制实现
📜 汇编代码解析 (5C2D3A07 - 5C2D3A70)
5C2D3A07 8B C7 mov eax, edi ; eax = dest
5C2D3A09 33 C6 xor eax, esi ; 比较对齐状态
5C2D3A0B A9 0F 00 00 00 test eax, 0Fh ; 检查16字节对齐
5C2D3A10 75 0E jne unaligned ; 未对齐处理
; 对齐处理路径
5C2D3A12 0F BA 25 84 A0 2E 5C 01 bt dword ptr ds:[5C2EA084h],1 ; 检查SSE支持
5C2D3A1A 0F 82 E0 03 00 00 jb sse_aligned_copy ; SSE对齐复制
; 未对齐处理
5C2D3A20 0F BA 25 40 A3 2E 5C 00 bt dword ptr ds:[5C2EA340h],0 ; 其他CPU检测
5C2D3A28 0F 83 A9 01 00 00 jae generic_copy ; 通用复制
; 对齐检查
5C2D3A2E F7 C7 03 00 00 00 test edi, 3 ; 检查4字节对齐
5C2D3A34 0F 85 9D 01 00 00 jne generic_copy ; 未对齐则通用复制
5C2D3A3A F7 C6 03 00 00 00 test esi, 3 ; 检查源对齐
5C2D3A40 0F 85 AC 01 00 00 jne generic_copy ; 未对齐则通用复制
💻 C++伪代码实现
void sse_block_copy(uint8_t* dest, const uint8_t* src, size_t count) {
// 检查对齐状态
uintptr_t align_diff = reinterpret_cast<uintptr_t>(dest) ^
reinterpret_cast<uintptr_t>(src);
if ((align_diff & 0xF) != 0) {
// 未对齐处理
handle_unaligned(dest, src, count);
return;
}
// 检查4字节对齐
if ((reinterpret_cast<uintptr_t>(dest) & 3) ||
(reinterpret_cast<uintptr_t>(src) & 3)) {
generic_copy(dest, src, count);
return;
}
// SSE优化路径
if (check_cpu_feature(CPU_FEATURE_SSE)) {
sse_aligned_copy(dest, src, count);
} else {
generic_copy(dest, src, count);
}
}
🧠 优化技术分析
- 对齐检测:
- 使用
xor+test检测指针对齐差异 - 单独检查4字节边界对齐
- 使用
- 多级分支:
- 完全对齐 → SSE优化
- 部分对齐 → 通用复制
- 完全未对齐 → 特殊处理
- CPU特性检测:多层级检测SSE支持情况
- 高效位操作:使用
test指令快速检查对齐状态
🧩 SSE对齐复制实现
📜 汇编代码解析 (5C2D3A46 - 5C2D3ADD)
; 检查dest的16字节对齐状态
5C2D3A46 0F BA E7 02 bt edi, 2 ; 检查位2 (4字节边界)
5C2D3A4A 73 0D jae skip_4byte ; 4字节对齐
; 处理4字节前缀
5C2D3A4C 8B 06 mov eax, dword ptr [esi] ; 加载4字节
5C2D3A4E 83 E9 04 sub ecx, 4 ; count -= 4
5C2D3A51 8D 76 04 lea esi, [esi+4] ; src += 4
5C2D3A54 89 07 mov dword ptr [edi], eax ; 存储4字节
5C2D3A56 8D 7F 04 lea edi, [edi+4] ; dest += 4
; 检查8字节对齐
5C2D3A59 0F BA E7 03 bt edi, 3 ; 检查位3 (8字节边界)
5C2D3A5D 73 11 jae skip_8byte ; 8字节对齐
; 处理8字节前缀
5C2D3A5F F3 0F 7E 0E movq xmm1, mmword ptr [esi] ; 加载8字节
5C2D3A63 83 E9 08 sub ecx, 8 ; count -= 8
5C2D3A66 8D 76 08 lea esi, [esi+8] ; src += 8
5C2D3A69 66 0F D6 0F movq mmword ptr [edi], xmm1 ; 存储8字节
5C2D3A6D 8D 7F 08 lea edi, [edi+8] ; dest += 8
; 主复制循环
5C2D3A70 F7 C6 07 00 00 00 test esi, 7 ; 检查8字节对齐
5C2D3A76 74 65 je aligned_loop ; 对齐则进入循环
💻 C++伪代码实现
void sse_aligned_copy(uint8_t* dest, const uint8_t* src, size_t count) {
// 处理4字节前缀
if ((reinterpret_cast<uintptr_t>(dest) & 4) != 0) {
*reinterpret_cast<uint32_t*>(dest) =
*reinterpret_cast<const uint32_t*>(src);
dest += 4;
src += 4;
count -= 4;
}
// 处理8字节前缀
if ((reinterpret_cast<uintptr_t>(dest) & 8) != 0) {
_mm_store_sd(reinterpret_cast<double*>(dest),
_mm_load_sd(reinterpret_cast<const double*>(src)));
dest += 8;
src += 8;
count -= 8;
}
// 主循环 - 16字节块复制
if ((reinterpret_cast<uintptr_t>(src) & 7) == 0) {
while (count >= 16) {
__m128i chunk = _mm_load_si128(reinterpret_cast<const __m128i*>(src));
_mm_store_si128(reinterpret_cast<__m128i*>(dest), chunk);
src += 16;
dest += 16;
count -= 16;
}
}
// ... 处理尾部
}
🧠 优化技术分析
- 渐进式对齐:
- 先处理4字节边界
- 再处理8字节边界
- 最后进入16字节主循环
- 高效数据移动:
movq:64位移动指令movdqa:对齐的128位移动
- 指针运算优化:使用
lea指令进行地址计算 - 循环条件优化:检查对齐状态后进入最速路径
🌀 未对齐内存处理
📜 汇编代码解析 (5C2D3A78 - 5C2D3B87)
; 根据未对齐偏移选择处理方式
5C2D3A78 0F BA E6 03 bt esi, 3 ; 检查位3
5C2D3A7C 0F 83 B4 00 00 00 jae offset_8 ; 8字节偏移
; 12字节偏移处理
5C2D3A82 66 0F 6F 4E F4 movdqa xmm1, xmmword ptr [esi-0Ch] ; 加载
5C2D3A87 8D 76 F4 lea esi, [esi-0Ch] ; 调整src
5C2D3A8A 8B FF mov edi, edi ; 对齐指令
5C2D3A8C 66 0F 6F 5E 10 movdqa xmm3, xmmword ptr [esi+10h]
5C2D3A91 83 E9 30 sub ecx, 30h ; count -= 48
5C2D3A94 66 0F 6F 46 20 movdqa xmm0, xmmword ptr [esi+20h]
5C2D3A99 66 0F 6F 6E 30 movdqa xmm5, xmmword ptr [esi+30h]
5C2D3A9E 8D 76 30 lea esi, [esi+30h] ; src += 48
5C2D3AA1 83 F9 30 cmp ecx, 30h ; 比较剩余字节
5C2D3AA4 66 0F 6F D3 movdqa xmm2, xmm3
5C2D3AA8 66 0F 3A 0F D9 0C palignr xmm3, xmm1, 0Ch ; 12字节对齐
5C2D3AAE 66 0F 7F 1F movdqa xmmword ptr [edi], xmm3 ; 存储
; ... 类似处理其他块
💻 C++伪代码实现
void handle_unaligned(uint8_t* dest, const uint8_t* src, size_t count) {
// 计算未对齐偏移量
uintptr_t offset = reinterpret_cast<uintptr_t>(src) & 0xF;
switch (offset) {
case 12: // 12字节偏移
process_12byte_offset(dest, src, count);
break;
case 8: // 8字节偏移
process_8byte_offset(dest, src, count);
break;
case 4: // 4字节偏移
process_4byte_offset(dest, src, count);
break;
default:
generic_copy(dest, src, count);
}
}
void process_12byte_offset(uint8_t* dest, const uint8_t* src, size_t count) {
// 调整指针以对齐边界
const uint8_t* aligned_src = src - 12;
__m128i chunk1 = _mm_load_si128(reinterpret_cast<const __m128i*>(aligned_src));
// 主循环
while (count >= 48) {
__m128i chunk2 = _mm_load_si128(reinterpret_cast<const __m128i*>(aligned_src + 16));
__m128i chunk3 = _mm_load_si128(reinterpret_cast<const __m128i*>(aligned_src + 32));
__m128i chunk4 = _mm_load_si128(reinterpret_cast<const __m128i*>(aligned_src + 48));
// 使用palignr进行数据对齐
__m128i aligned1 = _mm_alignr_epi8(chunk2, chunk1, 12);
__m128i aligned2 = _mm_alignr_epi8(chunk3, chunk2, 12);
__m128i aligned3 = _mm_alignr_epi8(chunk4, chunk3, 12);
// 存储对齐后的数据
_mm_store_si128(reinterpret_cast<__m128i*>(dest), aligned1);
_mm_store_si128(reinterpret_cast<__m128i*>(dest + 16), aligned2);
_mm_store_si128(reinterpret_cast<__m128i*>(dest + 32), aligned3);
aligned_src += 48;
dest += 48;
count -= 48;
}
// ... 处理尾部
}
🧠 优化技术分析
- 偏移分类处理:根据未对齐偏移量(4/8/12)选择最优路径
- 指针调整:通过
lea调整源指针实现伪对齐 - palignr指令:高效处理未对齐数据
- 从两个128位寄存器中提取跨边界数据
- 参数指定偏移量(4/8/12)
- 块处理优化:48字节块处理平衡效率和缓存使用
- 循环展开:每次迭代处理3个128位块
📊 性能对比分析
| 优化技术 | 适用场景 | 加速比 | 关键优势 | 实现复杂度 |
|---|---|---|---|---|
| rep movsb | 大尺寸数据+现代CPU | 5-8x | 硬件加速,自动优化 | 低 |
| SSE块复制 | 中大型数据 | 3-5x | 高吞吐量,数据并行 | 中 |
| palignr处理 | 未对齐数据 | 2-3x | 高效处理边界 | 高 |
| 跳转表尾部 | 小尺寸数据 | 2-3x | 消除分支开销 | 中 |
| 渐进式对齐 | 任意尺寸 | 1.5-2x | 减少内存停顿 | 中高 |
| 通用复制 | 兼容性路径 | 1x | 广泛兼容 | 低 |
🧠 设计哲学与工程实践
1. 分层优化策略
- 第一层:CPU特性检测,选择最优基础指令
- 第二层:数据大小分类,选择合适算法
- 第三层:内存对齐处理,最大化向量化收益
- 第四层:尾部处理,消除分支开销
2. 性能与兼容性平衡
3. 内存访问模式优化
- 顺序访问:最大化缓存利用率
- 大块处理:减少缓存行切换
- 写合并:减少内存总线事务
- 非阻塞加载:隐藏内存延迟
4. 指令级并行
- 循环展开:增加指令级并行机会
- 寄存器重用:减少内存依赖
- 指令调度:避免执行单元冲突
- 数据预取:隐藏内存延迟
🚀 极致优化技巧总结
-
多级阈值处理:32B/128B关键阈值实现高效分支
-
动态CPU检测:运行时选择最优执行路径
-
渐进式对齐:4B→8B→16B逐步达到最优对齐状态
-
向量化创新:
palignr处理未对齐数据- 128位SSE寄存器最大化吞吐
- 48字节块处理平衡效率和缓存
-
尾部处理艺术:
- 跳转表处理小尺寸
- 位掩码检测剩余字节
- 无分支尾部复制
-
重叠处理优化:
- 高效反向复制
- SSE反向块复制
- 尾部特殊处理
📜 完整反汇编代码
; vcruntime140d.dll!_memcpy 完整反汇编代码
; 起始地址: 5C2D39B0
5C2D39B0 57 push edi ; 保存 edi
5C2D39B1 56 push esi ; 保存 esi
5C2D39B2 8B 74 24 10 mov esi, dword ptr [esp+10h] ; esi = src
5C2D39B6 8B 4C 24 14 mov ecx, dword ptr [esp+14h] ; ecx = count
5C2D39BA 8B 7C 24 0C mov edi, dword ptr [esp+0Ch] ; edi = dest
5C2D39BE 8B C1 mov eax, ecx ; eax = count
5C2D39C0 8B D1 mov edx, ecx ; edx = count
5C2D39C2 03 C6 add eax, esi ; eax = src + count
5C2D39C4 3B FE cmp edi, esi ; 比较 dest 和 src
5C2D39C6 76 08 jbe 5C2D39D0 ; 如果 dest <= src,跳转到无重叠处理
5C2D39C8 3B F8 cmp edi, eax ; 比较 dest 和 src_end (src+count)
5C2D39CA 0F 82 94 02 00 00 jb 5C2D3C64 ; 如果 dest < src_end,跳转到反向复制(处理重叠)
5C2D39D0: ; 无重叠处理
5C2D39D0 83 F9 20 cmp ecx, 20h ; 比较 count 和 32
5C2D39D3 0F 82 D2 04 00 00 jb 5C2D3EAB ; 如果 count < 32,跳转到小数据复制
5C2D39D9 81 F9 80 00 00 00 cmp ecx, 80h ; 比较 count 和 128
5C2D39DF 73 13 jae 5C2D39F4 ; 如果 count >= 128,跳转到大数据处理
; 中等大小数据 (32 <= count < 128)
5C2D39E1 0F BA 25 84 A0 2E 5C 01 bt dword ptr ds:[5C2EA084h],1 ; 检查CPU特性标志位1
5C2D39E9 0F 82 8E 04 00 00 jb 5C2D3E7D ; 如果标志位1为1,跳转到中等大小的优化复制
5C2D39EF E9 E3 01 00 00 jmp 5C2D3BD7 ; 否则跳转到中等大小的标准复制
5C2D39F4: ; 大数据处理 (count >= 128)
5C2D39F4 0F BA 25 40 A3 2E 5C 01 bt dword ptr ds:[5C2EA340h],1 ; 检查CPU特性标志位(快速rep movsb)
5C2D39FC 73 09 jae 5C2D3A07 ; 如果标志位为0(不支持快速rep movsb),跳转
5C2D39FE F3 A4 rep movs byte ptr es:[edi], byte ptr [esi] ; 使用rep movsb复制
5C2D3A00 8B 44 24 0C mov eax, dword ptr [esp+0Ch] ; 返回dest
5C2D3A04 5E pop esi ; 恢复 esi
5C2D3A05 5F pop edi ; 恢复 edi
5C2D3A06 C3 ret ; 返回
5C2D3A07: ; 大数据处理,不支持快速rep movsb
5C2D3A07 8B C7 mov eax, edi ; eax = dest
5C2D3A09 33 C6 xor eax, esi ; 比较dest和src的低位
5C2D3A0B A9 0F 00 00 00 test eax, 0Fh ; 检查低4位是否相同(16字节对齐)
5C2D3A10 75 0E jne 5C2D3A20 ; 不相同则跳转到未对齐处理
; 对齐处理
5C2D3A12 0F BA 25 84 A0 2E 5C 01 bt dword ptr ds:[5C2EA084h],1 ; 检查CPU特性标志位1
5C2D3A1A 0F 82 E0 03 00 00 jb 5C2D3E00 ; 如果标志位1为1,跳转到对齐的SSE复制
5C2D3A20: ; 未对齐处理
5C2D3A20 0F BA 25 40 A3 2E 5C 00 bt dword ptr ds:[5C2EA340h],0 ; 检查CPU特性标志位0
5C2D3A28 0F 83 A9 01 00 00 jae 5C2D3BD7 ; 如果标志位0为0,跳转到标准复制
5C2D3A2E F7 C7 03 00 00 00 test edi, 3 ; 检查dest是否4字节对齐
5C2D3A34 0F 85 9D 01 00 00 jne 5C2D3BD7 ; 未对齐则跳转到标准复制
5C2D3A3A F7 C6 03 00 00 00 test esi, 3 ; 检查src是否4字节对齐
5C2D3A40 0F 85 AC 01 00 00 jne 5C2D3BF2 ; 未对齐则跳转
; 对齐处理(4字节对齐后)
5C2D3A46 0F BA E7 02 bt edi, 2 ; 检查dest的bit2(4字节边界)
5C2D3A4A 73 0D jae 5C2D3A59 ; 如果已对齐,跳过4字节处理
5C2D3A4C 8B 06 mov eax, dword ptr [esi] ; 从src加载4字节
5C2D3A4E 83 E9 04 sub ecx, 4 ; count -= 4
5C2D3A51 8D 76 04 lea esi, [esi+4] ; src += 4
5C2D3A54 89 07 mov dword ptr [edi], eax ; 存储到dest
5C2D3A56 8D 7F 04 lea edi, [edi+4] ; dest += 4
5C2D3A59: ; 检查8字节对齐
5C2D3A59 0F BA E7 03 bt edi, 3 ; 检查dest的bit3(8字节边界)
5C2D3A5D 73 11 jae 5C2D3A70 ; 如果已对齐,跳过8字节处理
5C2D3A5F F3 0F 7E 0E movq xmm1, mmword ptr [esi] ; 从src加载8字节
5C2D3A63 83 E9 08 sub ecx, 8 ; count -= 8
5C2D3A66 8D 76 08 lea esi, [esi+8] ; src += 8
5C2D3A69 66 0F D6 0F movq mmword ptr [edi], xmm1 ; 存储到dest
5C2D3A6D 8D 7F 08 lea edi, [edi+8] ; dest += 8
5C2D3A70: ; 检查src是否8字节对齐
5C2D3A70 F7 C6 07 00 00 00 test esi, 7 ; 检查src的低3位
5C2D3A76 74 65 je 5C2D3ADD ; 如果对齐,跳转到主循环
; 未对齐处理,根据偏移量选择处理方式
5C2D3A78 0F BA E6 03 bt esi, 3 ; 检查src的bit3
5C2D3A7C 0F 83 B4 00 00 00 jae 5C2D3B36 ; 如果为0,跳转到8字节偏移处理
; 12字节偏移处理
5C2D3A82 66 0F 6F 4E F4 movdqa xmm1, xmmword ptr [esi-0Ch] ; 从src-12加载16字节
5C2D3A87 8D 76 F4 lea esi, [esi-0Ch] ; 调整src指针
5C2D3A8A 8B FF mov edi, edi ; 空指令(对齐)
5C2D3A8C 66 0F 6F 5E 10 movdqa xmm3, xmmword ptr [esi+10h] ; 加载第二个块
5C2D3A91 83 E9 30 sub ecx, 30h ; count -= 48
5C2D3A94 66 0F 6F 46 20 movdqa xmm0, xmmword ptr [esi+20h] ; 第三个块
5C2D3A99 66 0F 6F 6E 30 movdqa xmm5, xmmword ptr [esi+30h] ; 第四个块
5C2D3A9E 8D 76 30 lea esi, [esi+30h] ; src += 48
5C2D3AA1 83 F9 30 cmp ecx, 30h ; 比较count和48
5C2D3AA4 66 0F 6F D3 movdqa xmm2, xmm3 ; 复制xmm3
5C2D3AA8 66 0F 3A 0F D9 0C palignr xmm3, xmm1, 0Ch ; 对齐数据(12字节偏移)
5C2D3AAE 66 0F 7F 1F movdqa xmmword ptr [edi], xmm3 ; 存储第一个块
5C2D3AB2 66 0F 6F E0 movdqa xmm4, xmm0 ; 复制xmm0
5C2D3AB6 66 0F 3A 0F C2 0C palignr xmm0, xmm2, 0Ch ; 对齐第二个块
5C2D3ABC 66 0F 7F 47 10 movdqa xmmword ptr [edi+10h], xmm0 ; 存储
5C2D3AC1 66 0F 6F CD movdqa xmm1, xmm5 ; 将xmm5(第五个块)复制到xmm1
5C2D3AC5 66 0F 3A 0F EC 0C palignr xmm5, xmm4, 0Ch ; 使用palignr指令将xmm4和xmm5组合,偏移12字节,结果存xmm5
5C2D3ACB 66 0F 7F 6F 20 movdqa xmmword ptr [edi+20h], xmm5 ; 存储第三个块到目标地址+20h
5C2D3AD0 8D 7F 30 lea edi, [edi+30h] ; 目标地址增加48字节(0x30)
5C2D3AD3 73 B7 jae 5C2D3A8C ; 如果还有足够数据(count>=48),跳回循环开始
; 循环结束后处理
5C2D3AD5 8D 76 0C lea esi, [esi+0Ch] ; 调整源指针,跳过12字节(因为之前处理了48字节块,但每次循环后esi已经增加了48,这里额外加12?)
5C2D3AD8 E9 AF 00 00 00 jmp 5C2D3B8C ; 跳转到尾部处理
; 处理8字节偏移的情况(类似12字节偏移,但偏移量不同)
5C2D3ADD 66 0F 6F 4E F8 movdqa xmm1, xmmword ptr [esi-8] ; 从源地址-8加载16字节
5C2D3AE2 8D 76 F8 lea esi, [esi-8] ; 调整源指针(减8)
5C2D3AE5 8D 49 00 lea ecx, [ecx] ; 空操作(对齐用)
; 开始处理8字节偏移的循环
5C2D3AE8 66 0F 6F 5E 10 movdqa xmm3, xmmword ptr [esi+10h] ; 加载第二个块
5C2D3AED 83 E9 30 sub ecx, 30h ; 字节数减48(0x30)
5C2D3AF0 66 0F 6F 46 20 movdqa xmm0, xmmword ptr [esi+20h] ; 第三个块
5C2D3B12 66 0F 3A 0F C2 08 palignr xmm0, xmm2, 8 ; 将xmm2和xmm0组合,8字节偏移
5C2D3B18 66 0F 7F 47 10 movdqa xmmword ptr [edi+10h], xmm0 ; 存储到目标+10h
5C2D3B1D 66 0F 6F CD movdqa xmm1, xmm5 ; 复制xmm5到xmm1
5C2D3B21 66 0F 3A 0F EC 08 palignr xmm5, xmm4, 8 ; 将 xmm4 寄存器的内容右移 8 字节后与 xmm5 组合,结果存入 xmm5
5C2D3B27 66 0F 7F 6F 20 movdqa xmmword ptr [edi+20h], xmm5 ; 将 xmm5 的 128 位数据对齐存储到 edi+20h 目标地址
5C2D3B2C 8D 7F 30 lea edi, [edi+30h] ; edi 增加 48 字节(目标地址后移)
5C2D3B2F 73 B7 jae 5C2D3AE8 ; 若 ecx ≥ 48(前文 cmp ecx,30h 的进位标志),跳回循环起始处继续复制
5C2D3B31 8D 76 08 lea esi, [esi+8] ; esi 增加 8 字节(源地址后移)
5C2D3B34 EB 56 jmp 5C2D3B8C ; 无条件跳转到标签 5C2D3B8C
; === 处理剩余字节(ecx < 48)===
5C2D3B8C 83 F9 10 cmp ecx, 10h ; 比较剩余字节数 ecx 是否 ≥ 16
5C2D3B8F 72 13 jb 5C2D3BA4 ; ecx < 16 则跳转
5C2D3B91 F3 0F 6F 0E movdqu xmm1, xmmword ptr [esi] ; 从 esi 加载 16 字节(非对齐)到 xmm1
5C2D3B95 83 E9 10 sub ecx, 10h ; ecx 减少 16 字节
5C2D3B98 8D 76 10 lea esi, [esi+10h] ; esi 增加 16 字节
5C2D3B9B 66 0F 7F 0F movdqa xmmword ptr [edi], xmm1 ; 将 xmm1 的 128 位数据对齐存储到 edi
5C2D3B9F 8D 7F 10 lea edi, [edi+10h] ; edi 增加 16 字节
5C2D3BA2 EB E8 jmp 5C2D3B8C ; 跳回开头继续处理剩余字节
; === 处理剩余 1~15 字节 ===
5C2D3BA4 0F BA E1 02 bt ecx, 2 ; 测试 ecx 的第 2 位(检查是否 ≥4 字节)
5C2D3BA8 73 0D jae 5C2D3BB7 ; ecx < 4 则跳转
5C2D3BAA 8B 06 mov eax, dword ptr [esi] ; 从 esi 加载 4 字节到 eax
5C2D3BAC 83 E9 04 sub ecx, 4 ; ecx 减少 4 字节
5C2D3BAF 8D 76 04 lea esi, [esi+4] ; esi 增加 4 字节
5C2D3BB2 89 07 mov dword ptr [edi], eax ; 将 eax 存储到 edi
5C2D3BB4 8D 7F 04 lea edi, [edi+4] ; edi 增加 4 字节
5C2D3BB7 0F BA E1 03 bt ecx, 3 ; 测试 ecx 的第 3 位(检查是否 ≥8 字节)
5C2D3BBB 73 11 jae 5C2D3BCE ; ecx < 8 则跳转
5C2D3BBD F3 0F 7E 0E movq xmm1, mmword ptr [esi] ; 从 esi 加载 8 字节到 xmm1
5C2D3BC1 83 E9 08 sub ecx, 8 ; ecx 减少 8 字节
5C2D3BC4 8D 76 08 lea esi, [esi+8] ; esi 增加 8 字节
5C2D3BC7 66 0F D6 0F movq mmword ptr [edi], xmm1 ; 将 xmm1 的低 64 位存储到 edi
5C2D3BCB 8D 7F 08 lea edi, [edi+8] ; edi 增加 8 字节
5C2D3BCE 8B 04 8D 14 3C 2D 5C mov eax, dword ptr [ecx*4+5C2D3C14h] ; 根据 ecx 查跳转表(处理 0~3 字节)
5C2D3BD5 FF E0 jmp eax ; 跳转到对应剩余字节的处理例程
; === 跳转表入口(处理 0~3 字节)===
5C2D3C14 24 3C and al, 3Ch ; 跳转表数据(无关指令)
5C2D3C16 2D 5C 2C 3C 2D sub eax, 2D3C2C5Ch ; 跳转表数据(无关指令)
...(跳转表数据略)...
; === 剩余 0 字节处理 ===
5C2D3C24 8B 44 24 0C mov eax, dword ptr [esp+0Ch] ; 返回目标地址(参数)
5C2D3C28 5E pop esi ; 恢复 esi
5C2D3C29 5F pop edi ; 恢复 edi
5C2D3C2A C3 ret ; 函数返回
; === 剩余 1 字节处理 ===
5C2D3C2C 8A 06 mov al, byte ptr [esi] ; 加载 1 字节
5C2D3C2E 88 07 mov byte ptr [edi], al ; 存储 1 字节
5C2D3C30 8B 44 24 0C mov eax, dword ptr [esp+0Ch] ; 返回目标地址
5C2D3C34 5E pop esi
5C2D3C35 5F pop edi
5C2D3C36 C3 ret
; === 剩余 2 字节处理 ===
5C2D3C38 8A 06 mov al, byte ptr [esi] ; 第 1 字节
5C2D3C3A 88 07 mov byte ptr [edi], al
5C2D3C3C 8A 46 01 mov al, byte ptr [esi+1] ; 第 2 字节
5C2D3C3F 88 47 01 mov byte ptr [edi+1], al
5C2D3C42 8B 44 24 0C mov eax, dword ptr [esp+0Ch]
5C2D3C46 5E pop esi
5C2D3C47 5F pop edi
5C2D3C48 C3 ret
; === 剩余 3 字节处理 ===
5C2D3C4C 8A 06 mov al, byte ptr [esi] ; 第 1 字节
5C2D3C4E 88 07 mov byte ptr [edi], al
5C2D3C50 8A 46 01 mov al, byte ptr [esi+1] ; 第 2 字节
5C2D3C53 88 47 01 mov byte ptr [edi+1], al
5C2D3C56 8A 46 02 mov al, byte ptr [esi+2] ; 第 3 字节
5C2D3C59 88 47 02 mov byte ptr [edi+2], al
5C2D3C5C 8B 44 24 0C mov eax, dword ptr [esp+0Ch]
5C2D3C60 5E pop esi
5C2D3C61 5F pop edi
5C2D3C62 C3 ret
📝 完整C++伪代码实现
#include <immintrin.h> // 包含SSE指令集头文件
#include <cstddef> // 包含size_t定义
// 内存复制函数 - 高度优化的实现
void* optimized_memcpy(void* dest, const void* src, size_t count) {
// 将指针转换为字节指针以便逐字节操作
uint8_t* dest_ptr = static_cast<uint8_t*>(dest);
const uint8_t* src_ptr = static_cast<const uint8_t*>(src);
// ==== 内存重叠检测 ====
const uint8_t* src_end = src_ptr + count;
// 如果目标地址在源地址之后且在源地址范围内,需要反向复制
if (dest_ptr > src_ptr && dest_ptr < src_end) {
return reverse_copy(dest_ptr, src_ptr, count);
}
// ==== 大小分支处理 ====
// 小尺寸处理 (count < 32字节)
if (count < 32) {
return small_size_copy(dest_ptr, src_ptr, count);
}
// 大尺寸处理 (count >= 128字节)
else if (count >= 128) {
// 检查CPU是否支持增强的rep movsb指令
if (check_cpu_feature(CPU_FEATURE_FAST_REP_MOVSB)) {
// 使用rep movsb进行高效复制
asm_rep_movsb(dest_ptr, src_ptr, count);
return dest;
}
// 否则使用SSE块复制
return large_sse_copy(dest_ptr, src_ptr, count);
}
// 中等尺寸处理 (32 <= count < 128)
else {
// 检查CPU是否支持SSE优化
if (check_cpu_feature(CPU_FEATURE_SSE)) {
return medium_sse_copy(dest_ptr, src_ptr, count);
} else {
return medium_std_copy(dest_ptr, src_ptr, count);
}
}
}
// ==== 小尺寸复制 (count < 32) ====
void* small_size_copy(uint8_t* dest, const uint8_t* src, size_t count) {
// 使用跳转表处理尾部字节
static const void* jump_table[] = {
&&end_copy, // 0字节
&©_1, // 1字节
&©_2, // 2字节
&©_3, // 3字节
&©_4, // 4字节
// ... 其他情况
};
// 根据剩余字节数跳转到对应处理程序
goto *jump_table[count % 16];
copy_16:
_mm_storeu_si128(reinterpret_cast<__m128i*>(dest),
_mm_loadu_si128(reinterpret_cast<const __m128i*>(src)));
dest += 16;
src += 16;
count -= 16;
copy_8:
if (count < 8) goto tail;
*reinterpret_cast<uint64_t*>(dest) = *reinterpret_cast<const uint64_t*>(src);
dest += 8;
src += 8;
count -= 8;
copy_4:
if (count < 4) goto tail;
*reinterpret_cast<uint32_t*>(dest) = *reinterpret_cast<const uint32_t*>(src);
dest += 4;
src += 4;
count -= 4;
tail:
// 处理尾部字节 (0-3字节)
switch (count) {
case 3: dest[2] = src[2]; [[fallthrough]];
case 2: dest[1] = src[1]; [[fallthrough]];
case 1: dest[0] = src[0]; [[fallthrough]];
case 0: break;
}
end_copy:
return dest;
}
// ==== 中等尺寸SSE优化复制 ====
void* medium_sse_copy(uint8_t* dest, const uint8_t* src, size_t count) {
// 检查内存对齐状态
uintptr_t align_diff = reinterpret_cast<uintptr_t>(dest) ^
reinterpret_cast<uintptr_t>(src);
// 如果dest和src的对齐状态不同
if ((align_diff & 0xF) != 0) {
return handle_unaligned(dest, src, count);
}
// 渐进式对齐处理
// 先处理4字节边界
if ((reinterpret_cast<uintptr_t>(dest) & 3) != 0) {
*reinterpret_cast<uint32_t*>(dest) = *reinterpret_cast<const uint32_t*>(src);
dest += 4;
src += 4;
count -= 4;
}
// 再处理8字节边界
if ((reinterpret_cast<uintptr_t>(dest) & 8) != 0) {
*reinterpret_cast<uint64_t*>(dest) = *reinterpret_cast<const uint64_t*>(src);
dest += 8;
src += 8;
count -= 8;
}
// 主循环 - 16字节块复制
while (count >= 16) {
_mm_store_si128(reinterpret_cast<__m128i*>(dest),
_mm_load_si128(reinterpret_cast<const __m128i*>(src)));
dest += 16;
src += 16;
count -= 16;
}
// 处理剩余字节
return small_size_copy(dest, src, count);
}
// ==== 大尺寸SSE块复制 ====
void* large_sse_copy(uint8_t* dest, const uint8_t* src, size_t count) {
// 处理前导未对齐部分
size_t prefix = (16 - (reinterpret_cast<uintptr_t>(src) & 0xF)) & 0xF;
if (prefix > 0) {
small_size_copy(dest, src, prefix);
dest += prefix;
src += prefix;
count -= prefix;
}
// 主循环 - 128字节块复制
while (count >= 128) {
// 一次加载8个128位寄存器
__m128i chunk0 = _mm_load_si128(reinterpret_cast<const __m128i*>(src));
__m128i chunk1 = _mm_load_si128(reinterpret_cast<const __m128i*>(src + 16));
__m128i chunk2 = _mm_load_si128(reinterpret_cast<const __m128i*>(src + 32));
__m128i chunk3 = _mm_load_si128(reinterpret_cast<const __m128i*>(src + 48));
__m128i chunk4 = _mm_load_si128(reinterpret_cast<const __m128i*>(src + 64));
__m128i chunk5 = _mm_load_si128(reinterpret_cast<const __m128i*>(src + 80));
__m128i chunk6 = _mm_load_si128(reinterpret_cast<const __m128i*>(src + 96));
__m128i chunk7 = _mm_load_si128(reinterpret_cast<const __m128i*>(src + 112));
// 存储所有块
_mm_store_si128(reinterpret_cast<__m128i*>(dest), chunk0);
_mm_store_si128(reinterpret_cast<__m128i*>(dest + 16), chunk1);
_mm_store_si128(reinterpret_cast<__m128i*>(dest + 32), chunk2);
_mm_store_si128(reinterpret_cast<__m128i*>(dest + 48), chunk3);
_mm_store_si128(reinterpret_cast<__m128i*>(dest + 64), chunk4);
_mm_store_si128(reinterpret_cast<__m128i*>(dest + 80), chunk5);
_mm_store_si128(reinterpret_cast<__m128i*>(dest + 96), chunk6);
_mm_store_si128(reinterpret_cast<__m128i*>(dest + 112), chunk7);
dest += 128;
src += 128;
count -= 128;
}
// 处理剩余部分
return medium_sse_copy(dest, src, count);
}
// ==== 反向复制(处理内存重叠)====
void* reverse_copy(uint8_t* dest, const uint8_t* src, size_t count) {
// 从尾部开始复制
uint8_t* dest_end = dest + count;
const uint8_t* src_end = src + count;
// 小尺寸直接处理
if (count < 32) {
while (count--) {
*--dest_end = *--src_end;
}
return dest;
}
// 大尺寸使用SSE优化
if (count >= 128 && check_cpu_feature(CPU_FEATURE_SSE)) {
// 处理尾部未对齐部分
size_t suffix = (reinterpret_cast<uintptr_t>(src_end) & 0xF);
if (suffix > 0) {
while (suffix--) {
*--dest_end = *--src_end;
count--;
}
}
// 主循环 - 反向128字节块复制
while (count >= 128) {
src_end -= 128;
dest_end -= 128;
// 加载和存储128字节块
__m128i chunk0 = _mm_load_si128(reinterpret_cast<const __m128i*>(src_end));
__m128i chunk1 = _mm_load_si128(reinterpret_cast<const __m128i*>(src_end + 16));
// ... 加载其他6个块 ...
_mm_store_si128(reinterpret_cast<__m128i*>(dest_end), chunk0);
_mm_store_si128(reinterpret_cast<__m128i*>(dest_end + 16), chunk1);
// ... 存储其他6个块 ...
count -= 128;
}
}
// 处理剩余部分
while (count--) {
*--dest_end = *--src_end;
}
return dest;
}
// ==== CPU特性检测函数 ====
bool check_cpu_feature(int feature) {
// 实际实现中会使用CPUID指令检测CPU特性
// 这里简化处理,返回编译时确定的特性支持
static const struct {
bool sse : 1;
bool fast_rep_movsb : 1;
} cpu_features = {
true, // 假设支持SSE
true // 假设支持快速rep movsb
};
switch (feature) {
case CPU_FEATURE_SSE: return cpu_features.sse;
case CPU_FEATURE_FAST_REP_MOVSB: return cpu_features.fast_rep_movsb;
default: return false;
}
}
// ==== rep movsb 汇编实现 ====
void asm_rep_movsb(uint8_t* dest, const uint8_t* src, size_t count) {
// 内联汇编实现rep movsb
asm volatile (
"cld\n" // 清除方向标志(向前复制)
"rep movsb\n" // 重复复制字节
: "+D"(dest), "+S"(src), "+c"(count) // 输出操作数
: // 输入操作数
: "memory" // 破坏描述符
);
}
关键优化技术总结
-
智能分支预测:
- 三级尺寸处理(小/中/大)
- 重叠检测自动切换复制方向
- CPU特性动态选择最优路径
-
向量化加速:
- SSE指令集最大化数据吞吐
- 精心设计的对齐处理
- 128字节块复制循环展开
-
内存访问优化:
- 缓存友好的大块复制
- 写合并技术减少内存操作
- 非阻塞加载隐藏延迟
-
指令级并行:
- 循环展开增加并行度
- 寄存器重用减少依赖
- 指令调度避免资源冲突
-
尾部处理艺术:
- 跳转表处理小尺寸
- 位掩码检测剩余字节
- 无分支复制减少跳转
性能对比分析
| 优化技术 | 适用场景 | 加速比 | 关键优势 |
|---|---|---|---|
| rep movsb | 大尺寸+现代CPU | 5-8x | 硬件加速,自动优化 |
| SSE块复制 | 中大型数据 | 3-5x | 高吞吐量,数据并行 |
| palignr处理 | 未对齐内存 | 2-3x | 高效处理边界 |
| 跳转表尾部 | 小尺寸数据 | 2-3x | 消除分支开销 |
| 渐进式对齐 | 任意尺寸 | 1.5-2x | 减少内存停顿 |
💻 函数功能分片及理解
🌟 函数入口与参数加载
; 函数入口:保存寄存器并加载参数
5C2D39B0 57 push edi ; 保存EDI寄存器(调用者保存)
5C2D39B1 56 push esi ; 保存ESI寄存器(调用者保存)
5C2D39B2 8B 74 24 10 mov esi, dword ptr [esp+10h] ; 从栈中加载源地址(src) -> ESI
5C2D39B6 8B 4C 24 14 mov ecx, dword ptr [esp+14h] ; 从栈中加载字节数(count) -> ECX
5C2D39BA 8B 7C 24 0C mov edi, dword ptr [esp+0Ch] ; 从栈中加载目标地址(dest) -> EDI
5C2D39BE 8B C1 mov eax, ecx ; EAX = 字节数(count)(为后续计算准备)
🧠 设计要点:
- 寄存器保护:通过
push保护调用者的EDI和ESI寄存器 - 参数加载:从栈偏移位置直接加载参数(标准调用约定)
- 寄存器重用:将ECX值复制到EAX,为后续地址计算做准备
🔍 内存重叠检测
; 计算源结束地址并检测重叠
5C2D39C0 8B D1 mov edx, ecx ; EDX = 字节数(count)(备用)
5C2D39C2 03 C6 add eax, esi ; EAX = 源地址 + 字节数 = 源结束地址(src_end)
5C2D39C4 3B FE cmp edi, esi ; 比较目标地址和源地址
5C2D39C6 76 08 jbe 5C2D39D0 ; 如果目标 <= 源地址(无重叠风险),跳转
5C2D39C8 3B F8 cmp edi, eax ; 比较目标地址和源结束地址
5C2D39CA 0F 82 94 02 00 00 jb 5C2D3C64 ; 如果目标 < 源结束地址(存在重叠),跳转到反向复制
🧠 优化技术:
- 高效地址计算:使用
add eax, esi计算源结束地址 - 两级重叠检测:
- 目标是否在源之后(
cmp edi, esi) - 目标是否在源范围内(
cmp edi, eax)
- 目标是否在源之后(
- 条件跳转优化:使用
jbe(无符号小于等于)和jb(无符号小于)
📏 大小分支处理
; 根据字节数选择处理路径
5C2D39D0 83 F9 20 cmp ecx, 20h ; 比较字节数和32
5C2D39D3 0F 82 D2 04 00 00 jb 5C2D3EAB ; 如果小于32,跳转到小数据复制
5C2D39D9 81 F9 80 00 00 00 cmp ecx, 80h ; 比较字节数和128
5C2D39DF 73 13 jae 5C2D39F4 ; 如果大于等于128,跳转到大数据处理
🧠 设计哲学:
- 三级分支结构:
- 小数据(<32字节):简单复制
- 中数据(32-127字节):中等优化
- 大数据(≥128字节):高级优化
- 关键阈值:32字节和128字节基于缓存行大小和性能测试确定
⚡ 大数据处理(≥128字节)
; 检查快速rep movsb支持
5C2D39F4 0F BA 25 40 A3 2E 5C 01 bt dword ptr ds:[5C2EA340h],1
5C2D39FC 73 09 jae 5C2D3A07 ; 不支持则跳转
5C2D39FE F3 A4 rep movs byte ptr es:[edi], byte ptr [esi] ; 使用rep movsb复制
5C2D3A00 8B 44 24 0C mov eax, dword ptr [esp+0Ch] ; 准备返回值(原始dest)
5C2D3A04 5E pop esi ; 恢复ESI
5C2D3A05 5F pop edi ; 恢复EDI
5C2D3A06 C3 ret ; 返回
🧠 优化亮点:
- CPU特性检测:检查CPU是否支持增强的
rep movsb - 字符串指令优化:现代CPU上
rep movsb可达到32字节/周期 - 快速返回路径:支持时直接返回,最小化开销
🧩 大数据非rep movsb路径
; 检查源和目标对齐状态
5C2D3A07 8B C7 mov eax, edi ; EAX = 目标地址
5C2D3A09 33 C6 xor eax, esi ; 比较目标地址和源地址的低位
5C2D3A0B A9 0F 00 00 00 test eax, 0Fh ; 检查低4位是否相同(16字节对齐)
5C2D3A10 75 0E jne 5C2D3A20 ; 不同则跳转到未对齐处理
🧠 对齐处理:
- 高效对齐检测:使用
xor+test比较地址低4位 - 分支优化:相同对齐状态可走优化路径
🔄 未对齐处理
; 检查CPU特性
5C2D3A20 0F BA 25 40 A3 2E 5C 00 bt dword ptr ds:[5C2EA340h],0
5C2D3A28 0F 83 A9 01 00 00 jae 5C2D3BD7 ; 不支持优化则跳转
; 检查目标4字节对齐
5C2D3A2E F7 C7 03 00 00 00 test edi, 3
5C2D3A34 0F 85 9D 01 00 00 jne 5C2D3BD7 ; 未对齐则跳转
; 检查源4字节对齐
5C2D3A3A F7 C6 03 00 00 00 test esi, 3
5C2D3A40 0F 85 AC 01 00 00 jne 5C2D3BF2 ; 未对齐则跳转
🧠 设计要点:
- 多级检查:CPU特性→目标对齐→源对齐
- 保守策略:任一条件不满足即回退到安全路径
⚙️ 对齐处理(渐进式)
; 检查目标4字节边界
5C2D3A46 0F BA E7 02 bt edi, 2
5C2D3A4A 73 0D jae 5C2D3A59 ; 已对齐则跳过
; 处理4字节前缀
5C2D3A4C 8B 06 mov eax, dword ptr [esi] ; 加载4字节
5C2D3A4E 83 E9 04 sub ecx, 4 ; 字节数减4
5C2D3A51 8D 76 04 lea esi, [esi+4] ; 源地址+4
5C2D3A54 89 07 mov dword ptr [edi], eax ; 存储4字节
5C2D3A56 8D 7F 04 lea edi, [edi+4] ; 目标地址+4
🧠 优化技术:
- 渐进式对齐:先处理4字节边界
lea指令:高效地址计算(不影响标志位)
🧩 8字节对齐处理
; 检查目标8字节边界
5C2D3A59 0F BA E7 03 bt edi, 3
5C2D3A5D 73 11 jae 5C2D3A70 ; 已对齐则跳过
; 处理8字节前缀
5C2D3A5F F3 0F 7E 0E movq xmm1, mmword ptr [esi] ; 加载8字节到XMM1
5C2D3A63 83 E9 08 sub ecx, 8 ; 字节数减8
5C2D3A66 8D 76 08 lea esi, [esi+8] ; 源地址+8
5C2D3A69 66 0F D6 0F movq mmword ptr [edi], xmm1 ; 存储8字节
5C2D3A6D 8D 7F 08 lea edi, [edi+8] ; 目标地址+8
🧠 SIMD利用:
movq指令:高效加载/存储64位数据- XMM寄存器:利用SSE指令集加速
🔄 主复制循环准备
; 检查源8字节对齐
5C2D3A70 F7 C6 07 00 00 00 test esi, 7
5C2D3A76 74 65 je 5C2D3ADD ; 对齐则跳转到主循环
🧠 设计要点:
确保进入主循环前源地址8字节对齐,最大化复制效率
🌀 12字节偏移处理
; 12字节偏移处理
5C2D3A78 0F BA E6 03 bt esi, 3
5C2D3A7C 0F 83 B4 00 00 00 jae 5C2D3B36 ; 不是12字节偏移则跳转
5C2D3A82 66 0F 6F 4E F4 movdqa xmm1, xmmword ptr [esi-0Ch] ; 从源-12加载16字节
5C2D3A87 8D 76 F4 lea esi, [esi-0Ch] ; 调整源指针
5C2D3A8A 8B FF mov edi, edi ; 空操作(对齐)
; 主复制循环(48字节块)
5C2D3A8C 66 0F 6F 5E 10 movdqa xmm3, xmmword ptr [esi+10h] ; 加载第二个块
5C2D3A91 83 E9 30 sub ecx, 30h ; 字节数减48
5C2D3A94 66 0F 6F 46 20 movdqa xmm0, xmmword ptr [esi+20h] ; 第三个块
5C2D3A99 66 0F 6F 6E 30 movdqa xmm5, xmmword ptr [esi+30h] ; 第四个块
5C2D3A9E 8D 76 30 lea esi, [esi+30h] ; 源地址+48
5C2D3AA1 83 F9 30 cmp ecx, 30h ; 比较剩余字节和48
5C2D3AA4 66 0F 6F D3 movdqa xmm2, xmm3 ; 复制xmm3
5C2D3AA8 66 0F 3A 0F D9 0C palignr xmm3, xmm1, 0Ch ; 12字节偏移对齐
5C2D3AAE 66 0F 7F 1F movdqa xmmword ptr [edi], xmm3 ; 存储第一个块
5C2D3AB2 66 0F 6F E0 movdqa xmm4, xmm0 ; 复制xmm0
5C2D3AB6 66 0F 3A 0F C2 0C palignr xmm0, xmm2, 0Ch ; 对齐第二个块
5C2D3ABC 66 0F 7F 47 10 movdqa xmmword ptr [edi+10h], xmm0 ; 存储
5C2D3AC1 66 0F 6F CD movdqa xmm1, xmm5 ; 复制xmm5
5C2D3AC5 66 0F 3A 0F EC 0C palignr xmm5, xmm4, 0Ch ; 对齐第三个块
5C2D3ACB 66 0F 7F 6F 20 movdqa xmmword ptr [edi+20h], xmm5 ; 存储
5C2D3AD0 8D 7F 30 lea edi, [edi+30h] ; 目标地址+48
5C2D3AD3 73 B7 jae 5C2D3A8C ; 如果剩余≥48字节,继续循环
🧠 优化亮点:
palignr指令:高效处理未对齐数据- 48字节块:平衡缓存利用和循环开销
- 循环展开:每次迭代处理3个128位块
📦 尾部处理
; 调整指针
5C2D3AD5 8D 76 0C lea esi, [esi+0Ch] ; 源地址+12
5C2D3AD8 E9 AF 00 00 00 jmp 5C2D3B8C ; 跳转到尾部处理
; 尾部处理入口
5C2D3B8C 83 F9 10 cmp ecx, 10h ; 比较剩余字节和16
5C2D3B8F 72 13 jb 5C2D3BA4 ; 小于16则跳转
; 处理16字节块
5C2D3B91 F3 0F 6F 0E movdqu xmm1, xmmword ptr [esi] ; 加载16字节
5C2D3B95 83 E9 10 sub ecx, 10h ; 字节数减16
5C2D3B98 8D 76 10 lea esi, [esi+10h] ; 源地址+16
5C2D3B9B 66 0F 7F 0F movdqa xmmword ptr [edi], xmm1 ; 存储16字节
5C2D3B9F 8D 7F 10 lea edi, [edi+10h] ; 目标地址+16
5C2D3BA2 EB E8 jmp 5C2D3B8C ; 继续处理剩余
🧠 设计要点:
- 循环处理:高效处理16字节块
movdqu:处理未对齐加载movdqa:对齐存储最大化性能
🧩 小尾部处理
; 处理小于16字节的尾部
5C2D3BA4 0F BA E1 02 bt ecx, 2 ; 检查是否还有至少4字节
5C2D3BA8 73 0D jae 5C2D3BB7 ; 没有则跳转
; 复制4字节
5C2D3BAA 8B 06 mov eax, dword ptr [esi] ; 加载4字节
5C2D3BAC 83 E9 04 sub ecx, 4 ; 字节数减4
5C2D3BAF 8D 76 04 lea esi, [esi+4] ; 源地址+4
5C2D3BB2 89 07 mov dword ptr [edi], eax ; 存储4字节
5C2D3BB4 8D 7F 04 lea edi, [edi+4] ; 目标地址+4
; 检查是否还有至少8字节
5C2D3BB7 0F BA E1 03 bt ecx, 3
5C2D3BBB 73 11 jae 5C2D3BCE ; 没有则跳转
; 复制8字节
5C2D3BBD F3 0F 7E 0E movq xmm1, mmword ptr [esi] ; 加载8字节
5C2D3BC1 83 E9 08 sub ecx, 8 ; 字节数减8
5C2D3BC4 8D 76 08 lea esi, [esi+8] ; 源地址+8
5C2D3BC7 66 0F D6 0F movq mmword ptr [edi], xmm1 ; 存储8字节
5C2D3BCB 8D 7F 08 lea edi, [edi+8] ; 目标地址+8
; 跳转表处理剩余0-7字节
5C2D3BCE 8B 04 8D 14 3C 2D 5C mov eax, dword ptr [ecx*4+5C2D3C14h] ; 跳转表基址
5C2D3BD5 FF E0 jmp eax ; 跳转到对应处理
🧠 优化技术:
- 位测试:使用
bt指令高效检查剩余字节数 - 跳转表:消除尾部处理的分支
- SIMD利用:使用
movq处理8字节复制
🔄 标准复制路径(中等大小)
; 标准复制路径(中等大小,未使用SSE)
5C2D3BD7 F7 C7 03 00 00 00 test edi, 3 ; 检查目标是否4字节对齐
5C2D3BDD 74 13 je 5C2D3BF2 ; 对齐则跳转
; 逐字节对齐目标
5C2D3BDF 8A 06 mov al, byte ptr [esi] ; 加载1字节
5C2D3BE1 88 07 mov byte ptr [edi], al ; 存储1字节
5C2D3BE3 49 dec ecx ; 字节数减1
5C2D3BE4 83 C6 01 add esi, 1 ; 源地址+1
5C2D3BE7 83 C7 01 add edi, 1 ; 目标地址+1
5C2D3BEA F7 C7 03 00 00 00 test edi, 3 ; 检查是否对齐
5C2D3BF0 75 ED jne 5C2D3BDF ; 未对齐则继续
; 复制剩余的4字节块
5C2D3BF2 8B D1 mov edx, ecx ; EDX = 剩余字节数
5C2D3BF4 83 F9 20 cmp ecx, 20h ; 比较剩余字节和32
5C2D3BF7 0F 82 AE 02 00 00 jb 5C2D3EAB ; 小于32则跳转
5C2D3BFD C1 E9 02 shr ecx, 2 ; 计算双字数
5C2D3C00 F3 A5 rep movs dword ptr es:[edi], dword ptr [esi] ; 复制双字
5C2D3C02 83 E2 03 and edx, 3 ; 计算剩余字节数(0-3)
5C2D3C05 FF 24 95 14 3C 2D 5C jmp dword ptr [edx*4+5C2D3C14h] ; 跳转表处理
🧠 设计要点:
- 渐进式对齐:先1字节对齐,再4字节块复制
rep movs:高效复制双字块- 跳转表:处理尾部0-3字节
🔄 反向复制(重叠处理)
; 反向复制(存在重叠时)
5C2D3C64 8D 34 0E lea esi, [esi+ecx] ; ESI = 源结束地址(src_end)
5C2D3C67 8D 3C 0F lea edi, [edi+ecx] ; EDI = 目标结束地址(dest_end)
5C2D3C6A 83 F9 20 cmp ecx, 20h ; 比较字节数和32
5C2D3C6D 0F 82 51 01 00 00 jb 5C2D3DC4 ; 小于32则跳转
; 检查SSE支持
5C2D3C73 0F BA 25 84 A0 2E 5C 01 bt dword ptr ds:[5C2EA084h],1
5C2D3C7B 0F 82 94 00 00 00 jb 5C2D3D15 ; 支持则跳转
; 对齐目标结束地址
5C2D3C81 F7 C7 03 00 00 00 test edi, 3 ; 检查4字节对齐
5C2D3C87 74 14 je 5C2D3C9D ; 对齐则跳转
; 逐字节对齐
5C2D3C89 8B D7 mov edx, edi ; EDX = 目标结束地址
5C2D3C8B 83 E2 03 and edx, 3 ; 取低2位(对齐字节数)
5C2D3C8E 2B CA sub ecx, edx ; 字节数减对齐字节数
5C2D3C90 8A 46 FF mov al, byte ptr [esi-1] ; 从源结束-1加载
5C2D3C93 88 47 FF mov byte ptr [edi-1], al ; 存储到目标结束-1
5C2D3C96 4E dec esi ; 源指针减1
5C2D3C97 4F dec edi ; 目标指针减1
5C2D3C98 83 EA 01 sub edx, 1 ; 计数器减1
5C2D3C9B 75 F3 jne 5C2D3C90 ; 循环直到对齐
; 主复制循环
5C2D3C9D 83 F9 20 cmp ecx, 20h ; 比较字节数和32
5C2D3CA0 0F 82 1E 01 00 00 jb 5C2D3DC4 ; 小于32则跳转
5C2D3CA6 8B D1 mov edx, ecx ; EDX = 字节数
5C2D3CA8 C1 E9 02 shr ecx, 2 ; 计算双字数
5C2D3CAB 83 E2 03 and edx, 3 ; 计算剩余字节数
5C2D3CAE 83 EE 04 sub esi, 4 ; 调整源指针
5C2D3CB1 83 EF 04 sub edi, 4 ; 调整目标指针
5C2D3CB4 FD std ; 设置方向标志(反向复制)
5C2D3CB5 F3 A5 rep movs dword ptr es:[edi], dword ptr [esi] ; 反向复制双字
5C2D3CB7 FC cld ; 清除方向标志
5C2D3CB8 FF 24 95 C0 3C 2D 5C jmp dword ptr [edx*4+5C2D3CC0h] ; 跳转表处理剩余字节
🧠 优化亮点:
- 方向标志:使用
std/cld控制复制方向 - 尾部处理:跳转表处理0-3字节尾部
- 对齐处理:先对齐目标地址再进入主循环
📦 小数据复制(<32字节)
; 小数据复制入口
5C2D3EAB 8B D1 mov edx, ecx ; EDX = 字节数
5C2D3EAD C1 E9 02 shr ecx, 2 ; 计算双字数
5C2D3EB0 F3 A5 rep movs dword ptr es:[edi], dword ptr [esi] ; 复制双字
5C2D3EB2 8B CA mov ecx, edx ; ECX = 字节数
5C2D3EB4 83 E1 03 and ecx, 3 ; 计算剩余字节数(0-3)
5C2D3EB7 FF 24 8D C0 3E 2D 5C jmp dword ptr [ecx*4+5C2D3EC0h] ; 跳转表处理
🧠 设计要点:
- 跳转表:高效处理0-3字节尾部
rep movs:小数据也使用高效指令
🧩 跳转表实现
; 跳转表地址
5C2D3C0C FF 24 8D 24 3C 2D 5C jmp dword ptr [ecx*4+5C2D3C24h]
5C2D3C13 90 nop
5C2D3C14 24 3C and al, 3Ch
5C2D3C16 2D 5C 2C 3C 2D sub eax, 2D3C2C5Ch
5C2D3C23 5C pop esp
💎 结论
vcruntime140d.dll!_memcpy的实现是内存操作优化的典范之作,它融合了:
- 深度硬件理解:充分利用现代CPU特性
- 精妙算法设计:多级阈值+渐进对齐
- 极致性能调优:向量化+指令级并行
- 全面场景覆盖:大小数据+对齐状态+重叠处理
这个函数展示了微软CRT团队在性能优化领域的深厚功力,其设计哲学和实现技巧值得所有底层开发人员深入研究。通过逐行分析其汇编实现,我们可以学习到如何将理论优化技术转化为实际高性能代码。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)