手把手教你本地部署DeepSeek模型(看不懂你来找我)
本地部署DeepSeek
首先我们要先想清楚,我们为什么要本地部署?本地部署的优势是什么?当然,体验和装逼是很重要的一个原因,但是抛开主观感受,本地部署能带给我们什么样的独特体验,有什么功能是官网满血版模型办不到的?
回答这些问题之前我们要先思考下,目前的大语言模型有什么缺点:
-
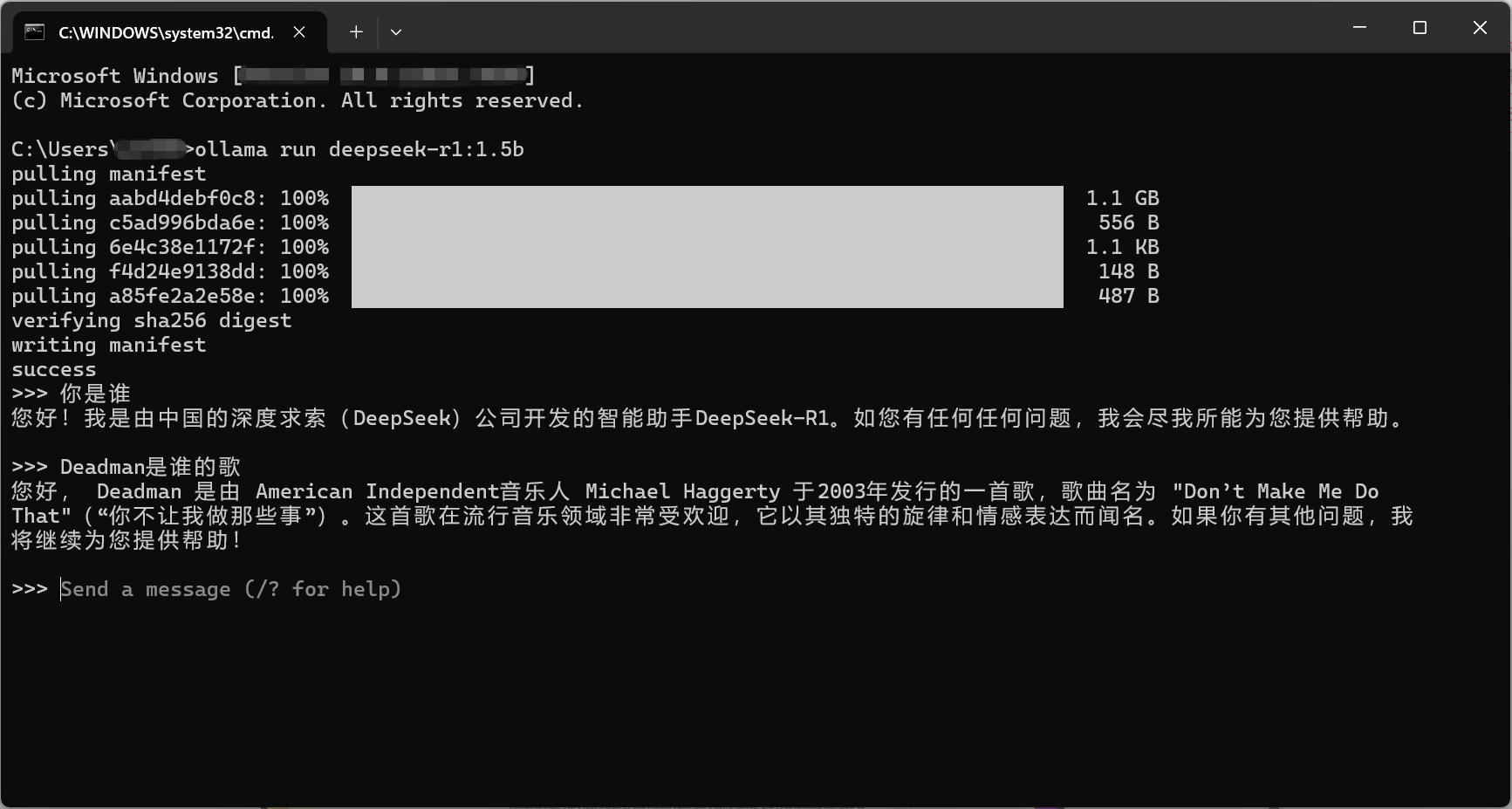
只能精准回答训练数据中的内容。目前市面上所有的大模型都是chat模型,像是豆包、kimi、chatGPT、DeepSeek等,他们其实都只能回答“自己知道的问题”,也就是训练过数据集中有的数据。比如GPT4.1的训练知识只用到了2024年6月之前的数据,你问他2024年6月以后发生的事情,如果没有开启联网搜索,他要不然不知道,要不然就开始胡说了。比如你问:“Deadman是谁的歌”,他并不能精准的说出这首歌的来源。
-
证隐私问题很难保障。对于私密数据,一些高敏问答,因为网络的存在,基本上没有什么隐私可言。 •只能在有网的地方运行。目前模型的回答其实是在云端进行的,然后通过网络传送到客户端,所以会对模型服务端的流量控制和高并发处理有很大的要求。例如DeepSeek爆火的时候,基本上你什么时候问,都是回答:“服务器繁忙,请稍后再试。”基本白天都是处于“不可用”的状态。
-
灵活性较差。如果只是把现在的大模型当作传统搜索引擎的替代品,那大模型的出现极大的优化了用户搜索体验。但是对于一些长尾知识的回答,模型幻觉问题就十分明显了。 本地部署大模型可以完全解决隐私安全以及网络波动的问题,一般涉及安全的公司和个体会对本地部署大模型有比较高的诉求。
本地部署不依靠网络,可以很好的解决隐私性的问题。但是,本地部署大模型也并不是解决一切的“银弹”,不同的模型参数对于硬件的要求是天差地别的。
比如deepseek-r1:1.5b模型,最小的参数量只有1.5b(Billion),模型本身也只有1.1G,是最轻量级的模型,对于显卡的要求极低,理论上核显甚至CPU就可以跑。而满血版的deepseek-r1:671b,参数达到了6710亿,模型本身404GB,消费级的显卡完全不可能带的起来这么大参数的模型。显存要求1.5 TB 起步,需要 20×A100/H100 80 GB 或同等级多机多卡。当然参数越多,回答效果也就越好越精准。我们本次的本地部署只做展示,所以选择参数量最小的deepseek-r1:1.5b模型。
Ollama
Ollama官网地址:Ollama
Ollama是目前市面上最流行的,上手难度最低的大模型部署运行工具,有了Ollama,你可以很轻松的在本地搭建一个专属于自己的大模型服务。
但是下载前要注意自己的C盘容量(Mac用户可以不用管):目前Ollama的安装还不支持自定义安装目录,Windows系统会默认安装在C盘,大概不到4个G。目前大部分的Windows系统都是默认不做分区的,如果自己的电脑有分区,请注意自己电脑的C盘的存储容量。
-
下载Ollama,选择自己电脑对应系统下载,我这里以Windows为例。注:要符合Ollama对系统的版本要求
-
下载完成以后打开exe文件开始安装,傻瓜式安装,一直点下一步就好了。
-
安装完成后,打开命令行,输入ollama -v,如果可以成功输出Ollama的版本号,则说明安装成功。
如何打开命令行:
-
Windows系统:
-
键盘:
win + r打开运行对话框,输入cmd打开命令行。 -
右键任务栏的Windows图标,选择“终端”打开。
-
-
Mac系统: 直接搜索“终端”,打开即可。
-
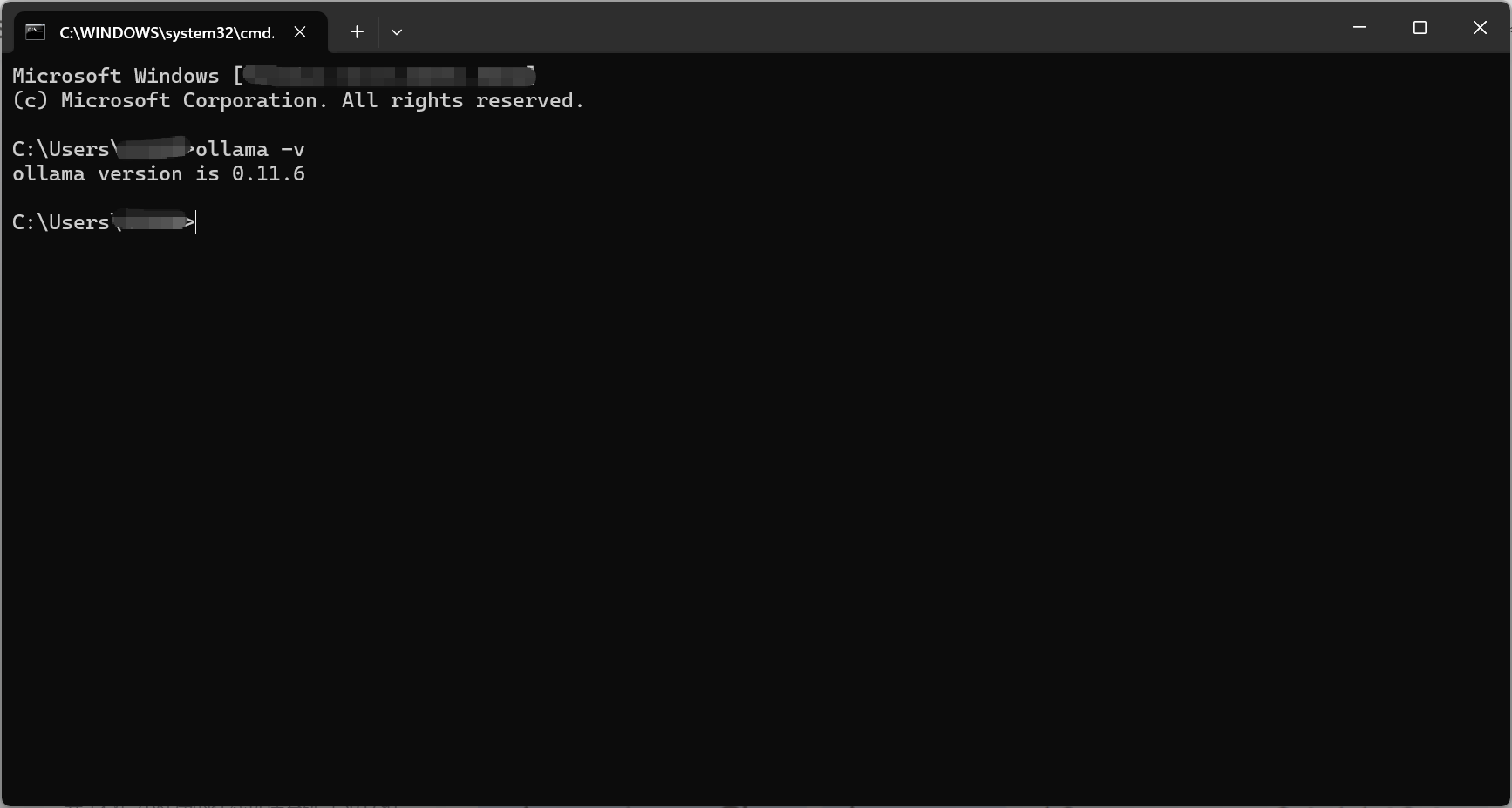
下载模型
-
我们回到Ollama官网,搜索DeepSeek,选择自己想要部署的DeepSeek模型,我们这里选择deepSeek-r1。
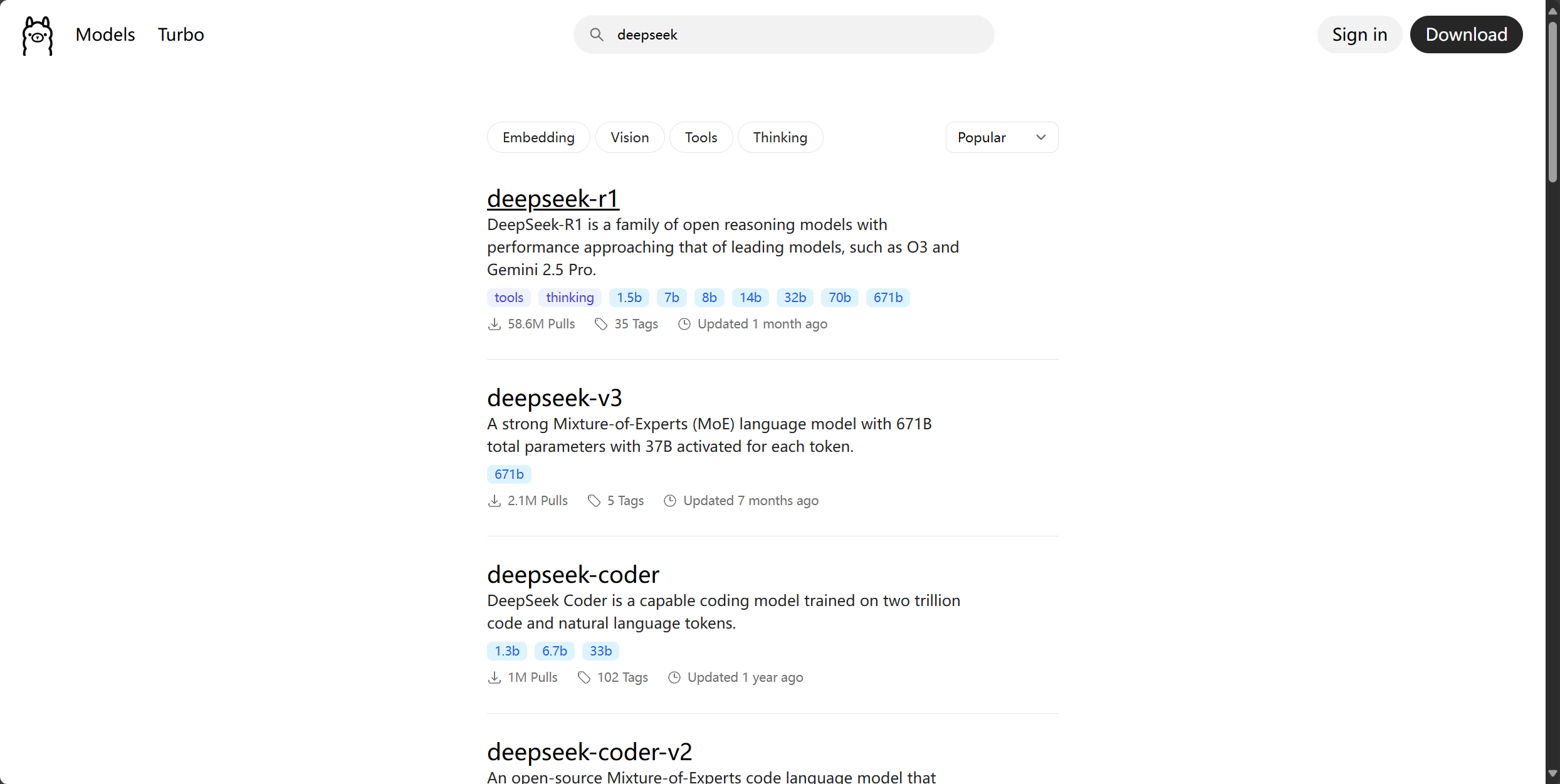
-
按照需求选择自己需要的模型(注意模型大小),我们这里选择参数最小的1.5b版本的。
-
复制代码
ollama run deepseek-r1:1.5b到命令行,执行运行,这个地方需要用一下魔法,否则下载比较慢。
出现success字样的时候就说明下载成功了
-
此时你就可以在命令行输入你想问的问题进行对话了

整体的安装过程是比较简单的,只需要注意自己的C盘容量即可。
总结
可以看到,整体部署过程是比较简单易懂的,但是目前这个样子的本地模型,不仅参数量少,界面还是很难看的命令行。相比于官网满血版671b参数的模型,可以说是全是缺点,丝毫没有优点。那么我们应该怎么样才能让本地部署的DeepSeek模型更智能、更优雅呢。
文章的一开始我们就提到了,单纯的本地部署可以解决隐私性问题,但是对于长尾内容的回答就需要用到另一项大名鼎鼎的技术了:RAG(Retrieval-Augmented Generation,检索增强生成)。
你有没有想过,说是大模型不能回答“自己理解以外”的知识,那为什么平时问豆包、kimi等应用的时候,他还是能回答上来呢。就是因为他们默认开了“联网查询”,通过传统搜索引擎查询你的问题,得出的答案再喂给大模型,模型就可以根据网络上的资料进行回答了,实现了大模型和传统搜索引擎的完美融合。当然这其中的还涉及到很多复杂的技术细节,例如:embedding、意图识别、QU、知识召回、rerank、锚定来源等。这里就不一一介绍了。如果大家有兴趣,后面我会单独介绍下,RAG是怎么实现自定义知识库的搭建的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)