AI生成测试用例,真的“卷”到天花板了?
调了两天,终于通了!自动编写测试用例,这个工具👍
测试用例作为质量保障的核心,影响着研发-测试-发布-上线的全过程,如单元测试用例、手工测试用例、接口自动化用例、UI 自动化用例等。但用例撰写的高成本,尤其是自动化用例,导致用例的可持续积累、更新和迭代受到非常大的制约。
然而,当ChatGPT写出第一个有效测试用例,当机器学习开始预判系统脆弱点,软件测试正在经历百年未遇的范式转移。人工智能技术的深度介入,正在从生成逻辑、执行方式到验证维度全方位重构测试用例的设计边界,推动测试工程从经验驱动向智能驱动跃迁。

测试用例的重要性
测试用例是测试工作的基础,是测试工程师执行测试的重要依据。测试用例详细规定了测试的目标、步骤和预期结果等内容,为测试人员提供了清晰的操作指南。
好的测试用例,可以覆盖软件系统的各种功能、性能、兼容性等方面的需求,尽可能地发现软件中的缺陷和问题。可以从不同的角度和场景对软件进行测试,包括正常情况和异常情况,从而提高软件的可靠性和稳定性。
详情往下拉查看
传统测试用例生成方法的局限性
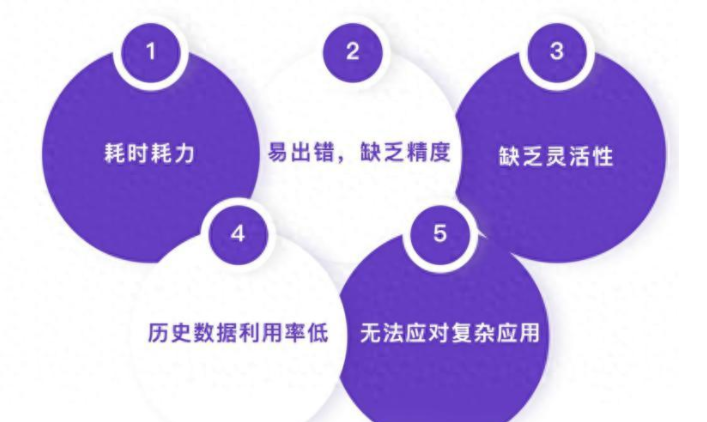
在软件复杂度呈指数级增长的今天,传统测试用例设计面临五大痛点:
耗时耗力
传统测试用例生成方法通常需要人工编写和整理测试用例,这需要耗费大量的人力和时间。
在开发周期紧张的情况下,手工编写测试用例可能会影响测试进度和质量。
易出错, 缺乏精度
人工编写测试用例容易出错,且缺乏准确性。测试工程师可能因为疏忽、理解偏差或经验不足等原因导致测试用例的设计不合理或遗漏重要测试点,从而影响测试效果。
缺乏活性
传统的手动测试用例生成方法通常需要事先定义测试场景和条件,无法灵活应对快速变化的需求。
当需求变更或软件功能发生变化时,需要重新设计和编写测试用例,这会影响测试效率和质量。
历史数据 利用率低
传统的手动测试用例生成方法通常仅基于当前测试数据和测试结果进行设计,无法充分利用历史数据和知识经验。
无法应对复杂应用
人工测试用例生成方法难以全面覆盖各种场景和需求,同时复杂系统和应用还涉及到大量的数据和算法,人工测试用例生成方法难以准确模拟用户。
基于 AI 的测试用例生成方法的可能性
1、边界拓展:从规则覆盖到智能探索
AI 通过算法模型突破了传统测试用例的预设边界。以大语言模型(LLM)为例,其基于自然语言处理和代码理解能力,可自动生成覆盖边界值、异常输入和场景组合的测试用例。
例如,在用户年龄验证场景中,GPT-4 不仅能生成 18/99 等常规边界值,还能构造 - 1、1000 等极端输入,甚至模拟空值、特殊字符等异常场景,覆盖人工设计易遗漏的逻辑漏洞。
2、范式革新:从线性设计到动态演进
AI 驱动的测试用例呈现出 "自我进化" 特征。通过机器学习算法分析历史缺陷数据,系统可自动优化用例优先级排序,将执行资源聚焦于高风险模块。
某金融系统应用聚类算法消除 40% 冗余用例后,测试效率提升 60%,缺陷发现率提高 3 倍。这种动态优化机制打破了静态测试集的固有局限。
3、价值重构:从质量验证到风险预判
AI 正在将测试用例的价值从 "缺陷发现" 向 "风险预防" 延伸。通过分析代码变更模式与测试结果的关联关系,Facebook 的 DeepTest 工具可精准定位缺陷根源,准确率达 92%。这种因果推理能力使测试用例成为代码质量的实时监控器。
未来趋势和展望
随着技术演进,AI 重构测试用例设计将呈现三大趋势:
【使用deepseek 智能体模型自动分析需求,提取测试点,自动编写测试用例,方法已整理成文档,滴滴“测试用例文档‘领哦】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)