MySQL篇
MySQL 核心技术包括:InnoDB 引擎支持事务与行锁,以 B + 树构建索引(聚簇索引存数据、二级索引需回表,覆盖索引减 IO)。通过 EXPLAIN 和慢日志定位慢查询,优化索引(遵最左前缀、防失效)与 SQL(如分页、覆盖索引)提升性能。事务靠 ACID 保障,MVCC 借版本链和 ReadView 解决并发。主从同步基于 Binlog 实现读写分离,分库分表(垂直按业务 / 字段、水平
一、小知识
1.关于数据库引擎
在mysql中提供了很多的存储引擎,比较常见有InnoDB、MyISAM、Memory
-
InnoDB存储引擎是mysql5.5之后是默认的引擎,它支持事务、外键、表级锁和行级锁
-
MyISAM是早期的引擎,它不支持事务、只有表级锁、也没有外键,用的不多
-
Memory主要把数据存储在内存,支持表级锁,没有外键和事务,用的也不多
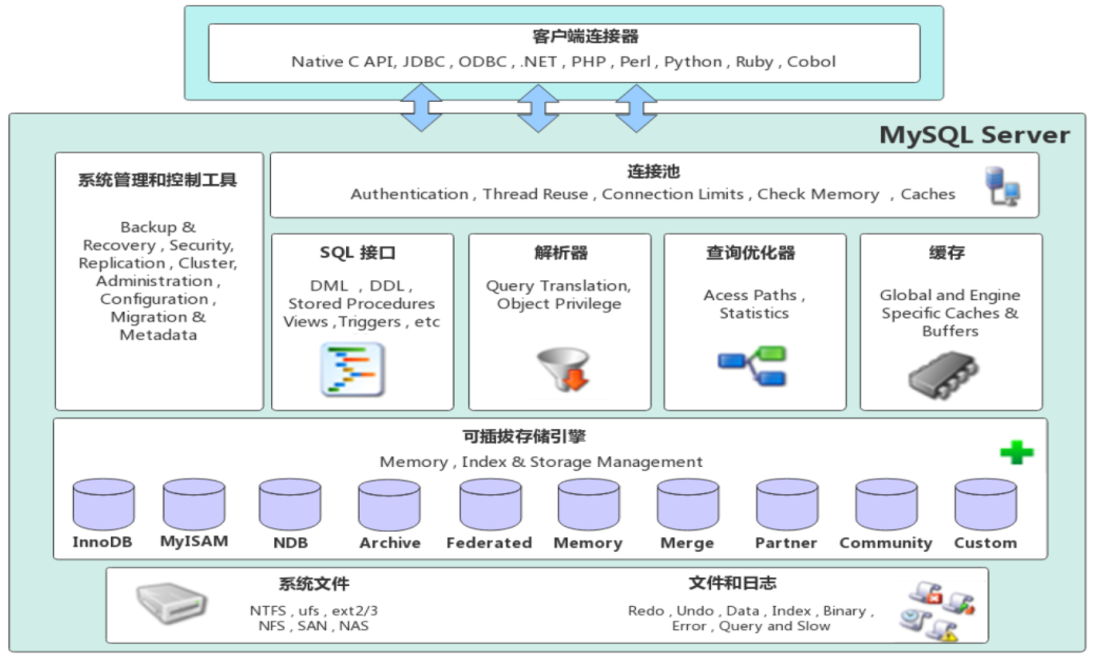
MySql的体系结构:连接层、服务层、引擎层、存储层
InnoDB:
-
它是一种兼顾高可靠性和高性能的通用存储引擎,在 MySQL 5.5 之后,它是默认的 MySQL 存储引擎。
-
特点:
-
DML操作遵循ACID模型,支持事务
-
行级锁 ,提高并发访问性能
-
支持外键,FOREIGN KEY约束,可以保证数据的完整性和正确性
-
-
文件:
-
xxx.ibd:xxx代表的是表名,innoDB引擎的每张表都会对应这样一个表空间文件,存储该表的表结构(frm、sdi)、数据和索引。
-
xxx.frm 存储表结构(MySQL8.0时,合并在表名.ibd中)
-
2.索引的基本语法
创建索引:
create [ unique ] index 索引名 on 表名 (字段名,... ) ;
-- 案例:为tb_emp表的name字段建立一个索引
create index idx_emp_name on tb_emp(name);查看索引
show index from 表名;
-- 案例:查询 tb_emp 表的索引信息
show index from tb_emp;删除索引
drop index 索引名 on 表名;
-- 案例:删除 tb_emp 表中name字段的索引
drop index idx_emp_name on tb_emp;注意事项:
-
主键字段,在建表时,会自动创建主键索引
-
添加唯一约束时,数据库实际上会添加唯一索引
二、SQL慢查询
1.定位慢查询的思路
通常情况下慢查询出现的原因:聚合查询、多表查询、表数据量过大查询、深度分页查询。导致的接口响应时间慢。
表象:表象:页面加载过慢、接口压测响应时间过长(超过1s)
方案一:使用开源的工具(调试工具:Arthas ;运维工具:Prometheus 、Skywalking)
方案二:使用MySql自带的慢日志
方式1:配置文件(需要重启)
# 开启MySQL慢日志查询开关(1=开启,0=关闭)
slow_query_log = 1
# 输出日志路径(指定慢查询日志的存储位置)
slow_query_log_file = /var/log/mysql/mysql-slow.log
# 设置慢日志的时间阈值为2秒
# SQL语句执行时间超过此值将被记录为慢查询
long_query_time = 2
# 记录未使用索引的查询(有助于发现潜在索引优化点)
log_queries_not_using_indexes = 1
# 仅记录扫描行数超过此阈值的查询(减少日志量)
min_examined_row_limit = 100
# 记录慢管理语句(如ALTER TABLE、ANALYZE TABLE等)
log_slow_admin_statements = 1
# 记录从库的慢查询(主从复制环境适用)
log_slow_slave_statements = 1
# 日志输出格式(FILE=文件,TABLE=数据库表,COMMA=同时输出到文件和表)
log_output = FILE
方式2:动态方式(无需重启)
-- 开启慢查询日志
SET GLOBAL slow_query_log = 'ON';
-- 设置慢查询阈值(秒)
SET GLOBAL long_query_time = 0.5;
-- 记录未使用索引的查询
SET GLOBAL log_queries_not_using_indexes = 'ON';效果如下:

2.sql语句执行很慢该如何分析?
可以采用MySql自带的分析工具EXPLAIN(获取Sql的执行计划)
-
通过key和key_len检查是否命中了索引(索引本身存在是否有失效的情况)。
-
通过type字段查看sql是否有进一步的优化空间,是否存在全索引扫描或全盘扫描。
-
通过extra建议判断,是否出现了回表的情况,如果出现了,可以尝试添加索引或修改返回字段来修复。
语法:EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件;(前面的关键字可以是 explain /desc)

3.SQL慢查询的优化
-
定位瓶颈:日志分析 +
EXPLAIN -
索引优化:补全缺失索引,修正低效索引
-
SQL重构:精简查询逻辑,避免全表扫描
-
配置调优:调整内存、连接池参数
-
架构升级:读写分离、分库分表(数据量极大时)
三、索引
在数据之外,数据库系统还维护着满足特定查找算法的数据结构(B + 树(我们平常所说的索引,如果没有特别指明,都是指默认的 B+Tree 结构组织的索引。)),这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。
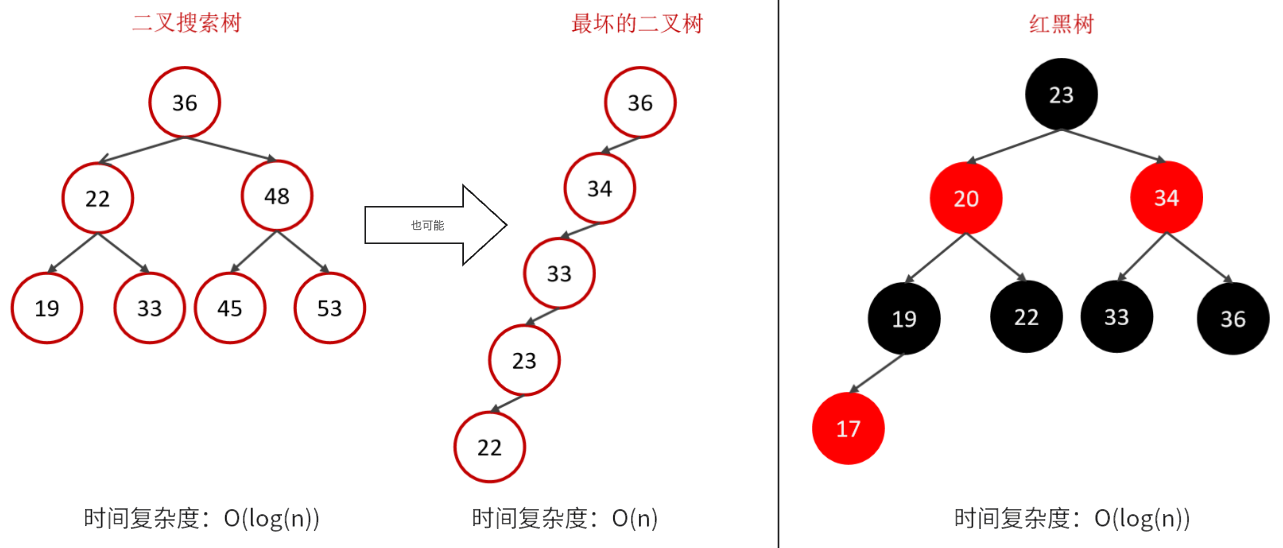
当采用二叉搜索树或者是红黑树来作为索引的结构有什么问题?
答案:最大的问题就是在
数据量大的情况下,树的层级比较深,会影响检索速度。因为不管是二叉搜索数还是红黑数,一个节点下面只能有两个子节点。此时在数据量大的情况下,就会造成数的高度比较高,树的高度一旦高了,检索速度就会降低。
说明:如果数据结构是红黑树,那么查询1000万条数据,根据计算树的高度大概是23左右,这样确实比之前的方式快了很多,但是如果高并发访问,那么一个用户有可能需要23次磁盘IO,那么100万用户,那么会造成效率极其低下。所以为了减少红黑树的高度,那么就得增加树的宽度,就是不再像红黑树一样每个节点只能保存一个数据,可以引入另外一种数据结构,一个节点可以保存多个数据,这样宽度就会增加从而降低树的高度。这种数据结构例如BTree就满足。
什么是索引?
-
索引(index)是帮助MySQL高效获取数据的数据结构(有序)
-
他可以提高数据检索的效率,降低数据库的IO成本(不需要全表扫描)
-
通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗
索引的底层数据结构?
MySQL的InnoDB引擎采用的B+树的数据结构来存储索引
-
它的阶数更多,路径更短
-
磁盘读写代价B+树更低,非叶子节点只存储指针,叶子阶段存储数据
-
B+树便于扫库和区间查询,因为叶子节点之间是一个双向链表
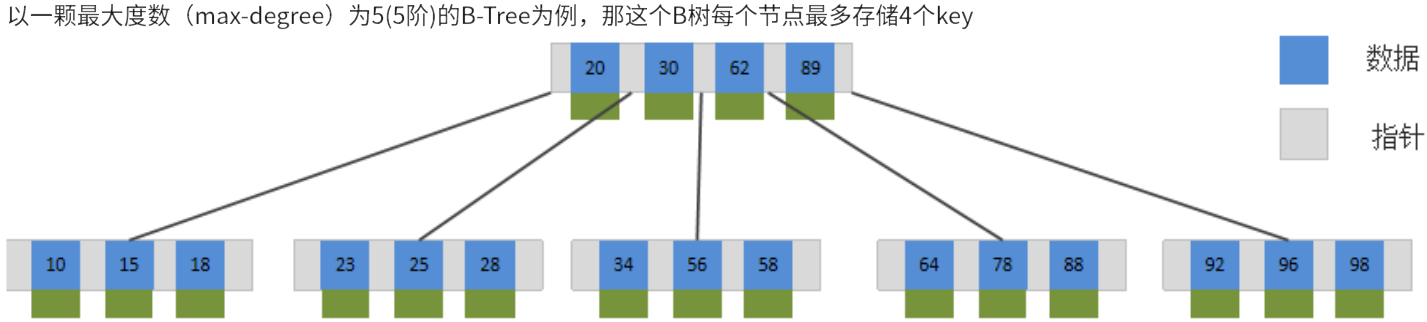
1.关于B树和B+树
B-Tree
-
B树是一种多叉路衡查找树,相对于二叉树,B树每个节点可以有多个分支,即多叉。
-
B-Tree的三个特性:
-
平衡:所有的叶子节点一定在同一层
-
有序:节点内有序,任一元素的左子树都小于他,右子树都大于他
-
多路:对于m阶B—Tree的结点。最多(m个分支,m-1个元素)最少(根节点:2个分支,1个元素;其他节点:m/2个分支,m/2-1个元素(上取整))
-
-
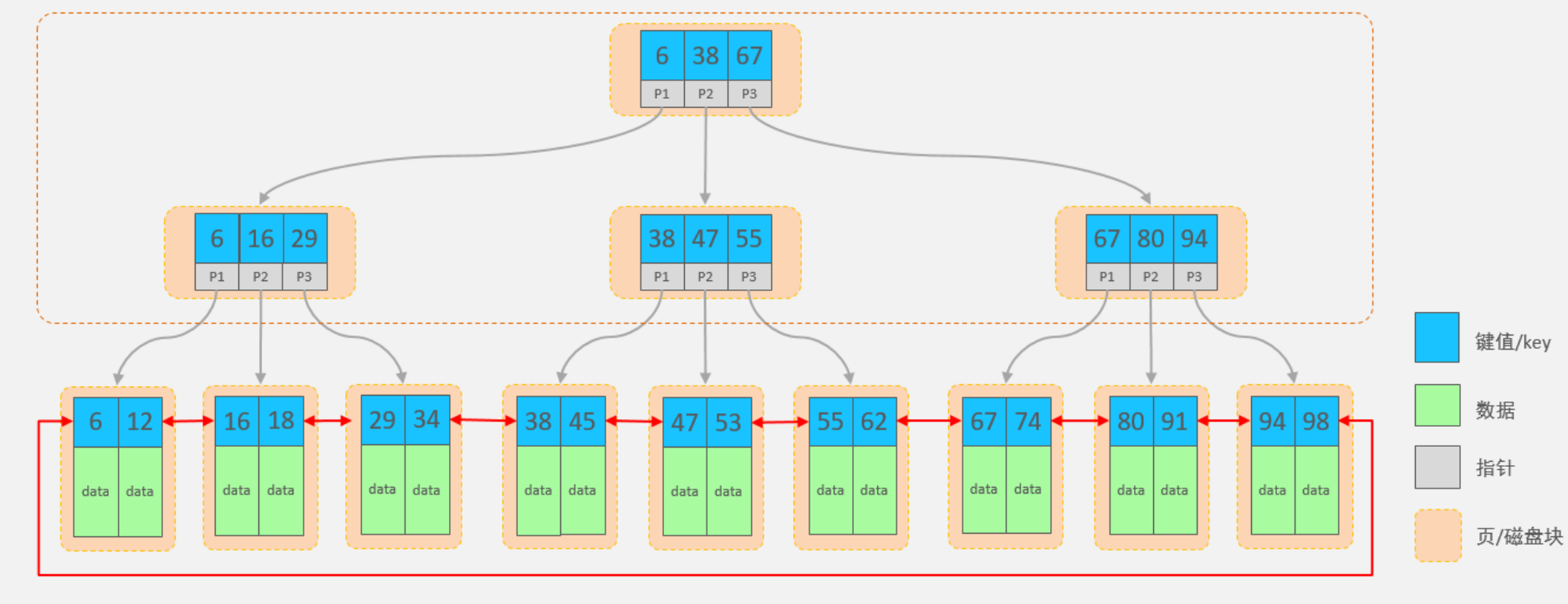
B+Tree
-
它是在B—Tree基础上的进行优化,使其更适合外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构。
-
B树与B+树对比:
-
磁盘读写代价B+树更低;(
非叶子节点只存储指针不存储数据,数据记录都存储在叶子节点中) -
查询效率B+树更加稳定;(B+Tree所有的数据都存储在了叶子节点上)
-
B+树便于扫库和区间查询(叶子节点之间通过双向指针进行连接,进行范围查询更加方便)
-
-
2.关于聚簇索引和非聚簇索引
前置概念:聚集索引也叫所聚簇索引,二级索引也叫所非聚集索引。
聚集索引:
-
含义:数据与索引放到一块,B+树的叶子节点保存了整行数据。
-
特点:有且只有一个
-
聚集索引的选取规则:
-
若存在主键,则主键索引就是聚集索引
-
若不存在主键,将使用第一个唯一索引作为聚集索引
-
若表没有主键,或没有合适的唯一索引,则InnDB就会自动生成一个rowid作为隐藏的聚集索引
-
二级索引:
-
含义:数据与索引分开存储,B+树的叶子节点保存对应的主键。
-
特点:可以有多个
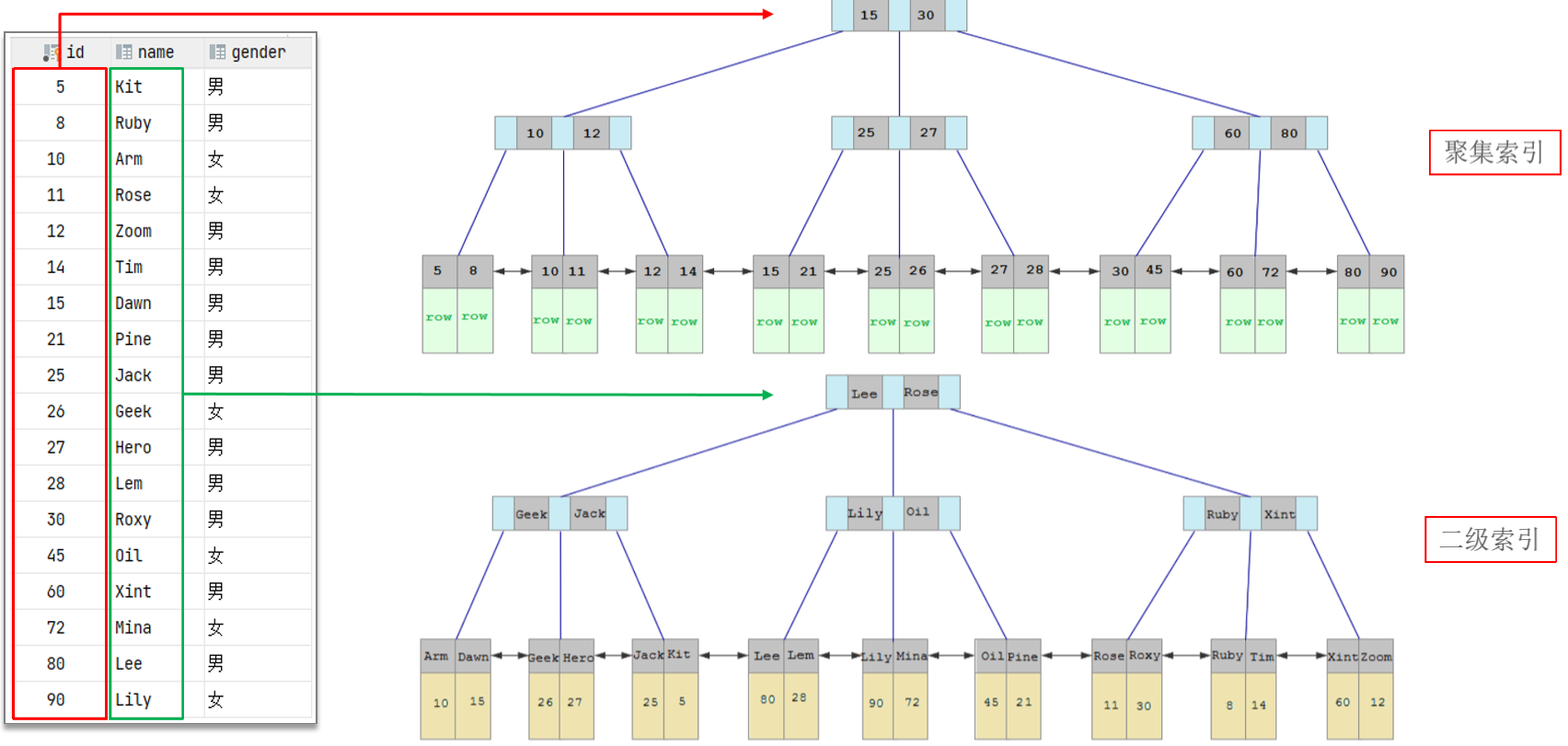
回表查询:
-
含义:通过二级索引找到对应的主键值,到聚集索引中查找整行数据,这个过程就是回表
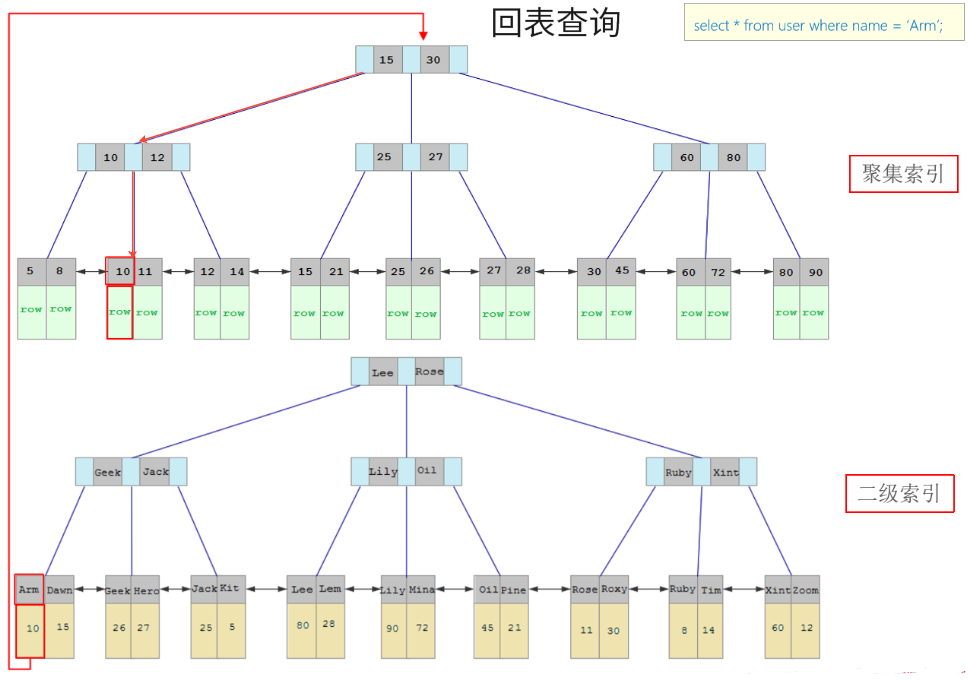
3.关于覆盖索引
覆盖索引:是指select查询语句使用了索引,并且需要返回的列,在该索引中已经全部能够找到 。
-
使用id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。
-
如果返回的列中没有创建索引,有可能会触发回表查询,尽量避免使用select *,尽量在返回的列中都包含添加索引的字段

MySql超大分页怎样处理?(优化)
问题引入:在数据量比较大时,如果进行limit分页查询,在查询时,越往后,分页查询效率越低。
核心思想: 避免全表扫描和减少无效数据遍历

4.索引的创建原则(复合索引)
-
针对于数据量较大,且查询比较频繁的表建立索引。单表超过10万数据(增加用户体验)(重要)
-
针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。(重要)
-
尽量选择区分度高的列作为索引,尽量建立唯一索引,(字段)区分度越高,使用索引的效率越高。
-
如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引(截取前面的一部分内容作为索引)。
-
尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。(重要)
-
要控制索引的数量,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。(重要)
-
如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
5.索引的失效问题
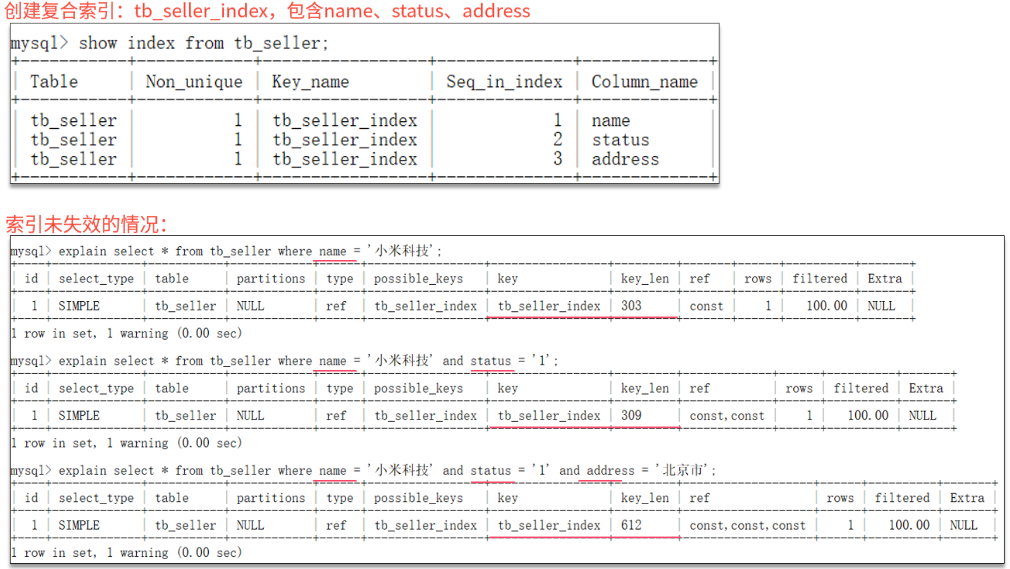
未失效的情况:
失效的情况:
-
违反最左前缀法则。如果索引了多列,要遵守最左前缀法则,含义是指的是查询从索引的最左前列开始,并且不跳过索引中的列。

-
范围查询右边的列,不能使用索引

-
不要在索引列上进行运算操作,否则索引将失效
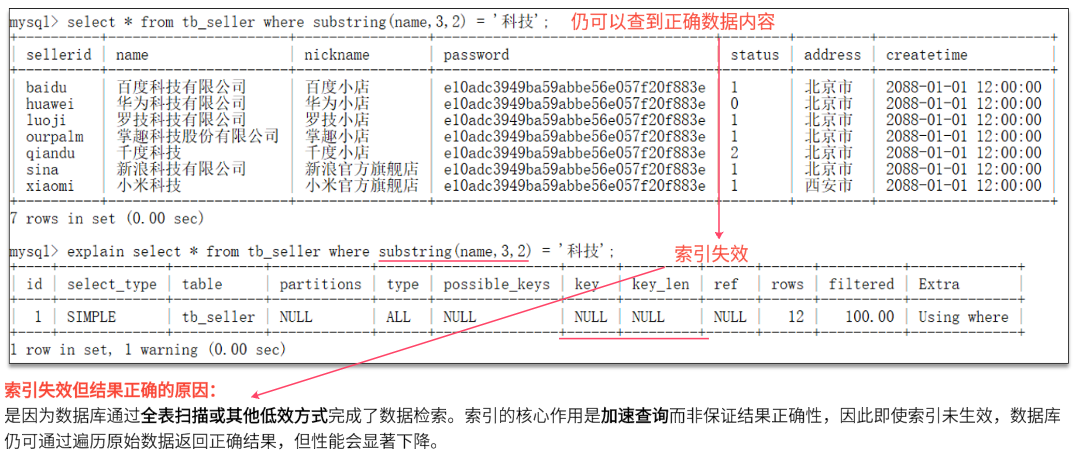
-
字符串不加单引号,会造成索引失效。

-
模糊查询可能会导致索引失效
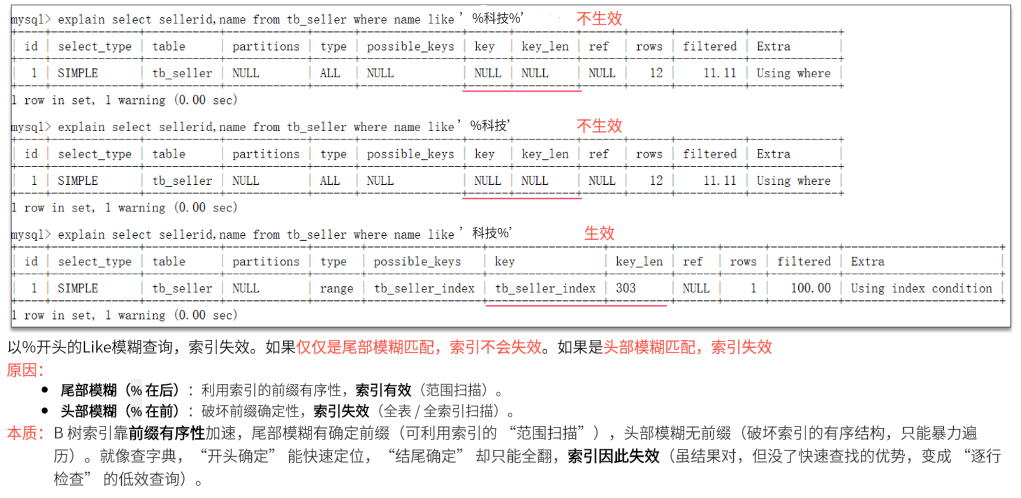
6.关于SQL的优化
-
表设计的优化(参考阿里开发手册)
根据存储内容的长短选择不同的类型,这样不仅可以节省存储的成本还可以提升查询的效率。-
比如设置合适的字符串类型(
char和varchar)其中char定长效率高,varchar可变长度,效率稍低。 -
比如设置合适的数值(
tinyint、int、bigint)。
-
-
索引的优化(
参考索引的创建原则和索引的失效) -
SQL语句的优化
-
SELECT语句务必指明字段名称(
避免直接使用select * ,因为可能会造成回表查询) -
SQL语句要避免造成索引失效的写法。(
五种索引失效情况) -
尽量用union all(他会返回拼接的查询语句的合集)代替union(他会在前者的基础上进行一次去重),因为union会多一次过滤,效率比较低。
-
避免在where子句中对字段进行表达式操作(
比如之前的substring例子,导致了索引的失效) -
Join优化能用inner join 就不用left join或right join,如必须使用 一定要以小表为驱动。内连接会对两个表进行优化,优先把小表放到外边,把大表放到里边。left join 或 right join,不会重新调整顺序,因为你在编写Sql时已经确定了它们的顺序。

-
-
主从同步、读写分离
-
当数据库的使用场景读的操作比较多的时,为避免写的操作所造成的性能影响可以采用读写分离的架构。
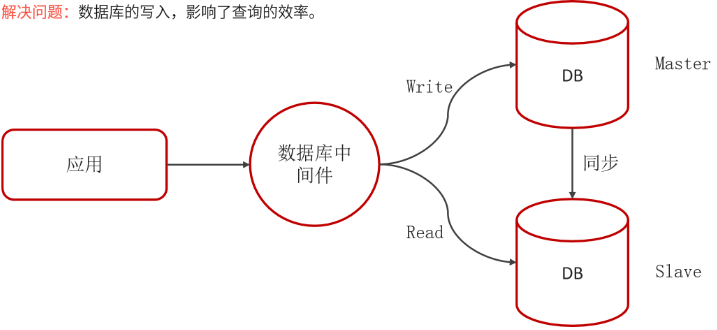
-
-
分库分表(后面会写)
四、事物
1.事物的特性(ACID)
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
-
原子性(
Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。 -
一致性(
Consistency):事务完成时,必须使所有的数据都保持一致状态。 -
隔离性(
Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。 -
持久性(
Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
2.并发事务
并发事务问题:脏读、不可重复读、幻读
-
脏读:一个事务读到另外一个事务还没有提交的数据。
-
不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。
-
幻读:事务并发控制中的隔离性问题,特指在同一事务内,多次执行相同范围查询(Range Query)** 时,因其他事务插入或删除符合该查询条件的行,导致 结果集行数发生不可预期的变化(如新增"幽灵行"或消失行)。
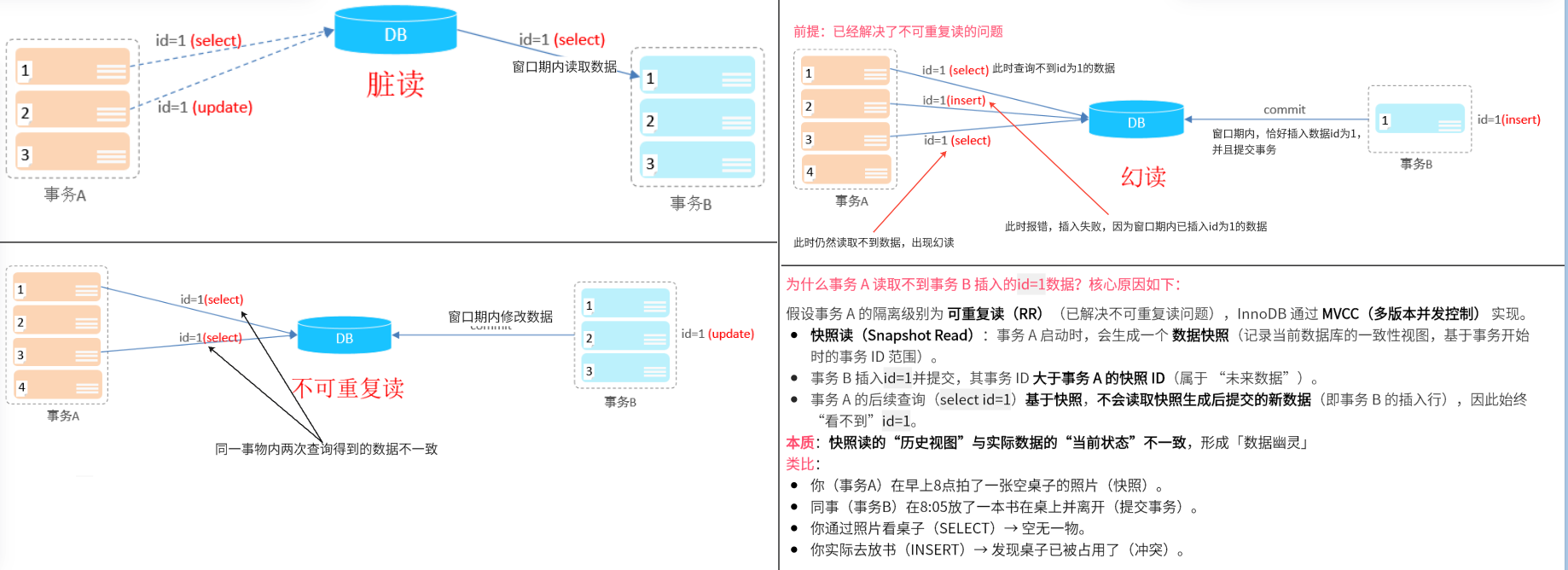
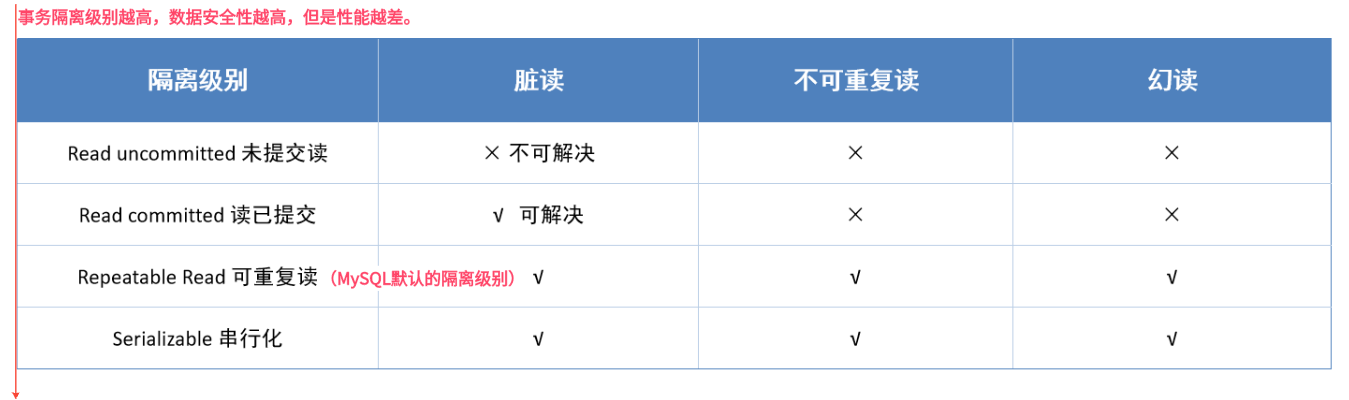
解决并发事物的方法:对事物进行隔离
3.undo log和redo log的区别
两个基本概念
-
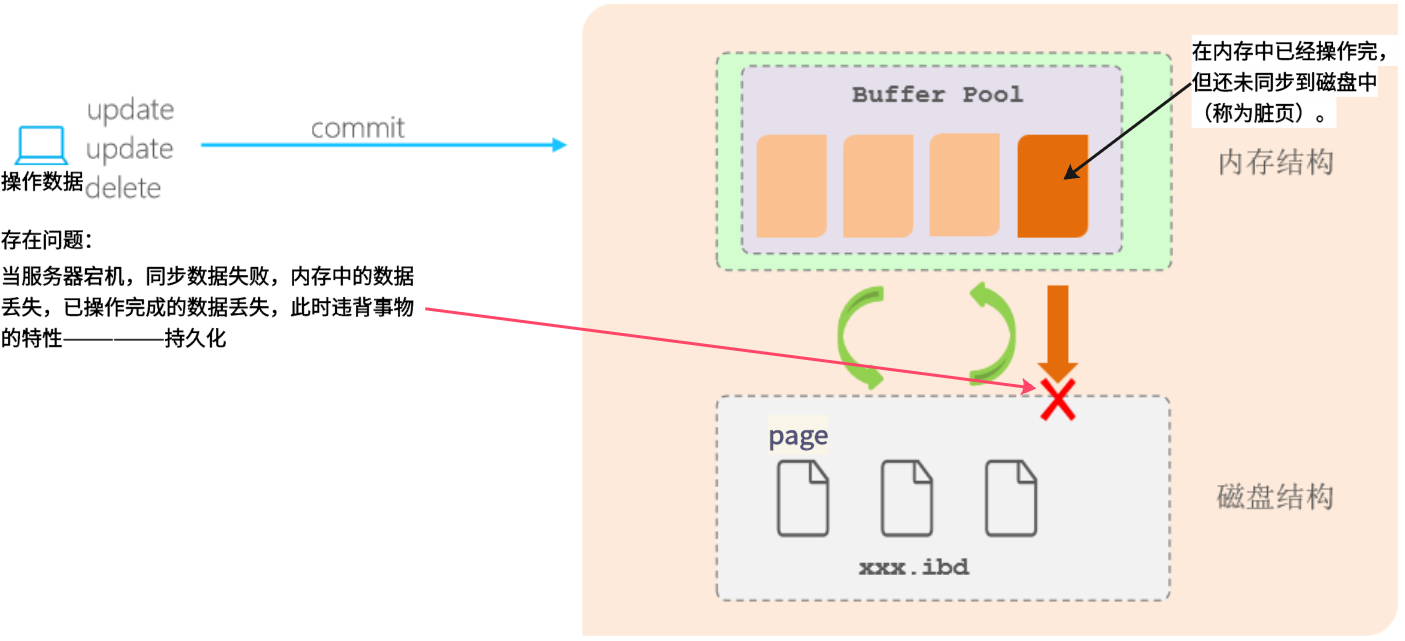
缓冲池(buffer pool):主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。
-
数据页(page):是InnoDB 存储引擎磁盘管理的最小单元,每个页的大小默认为 16KB。页中存储的是行数据。
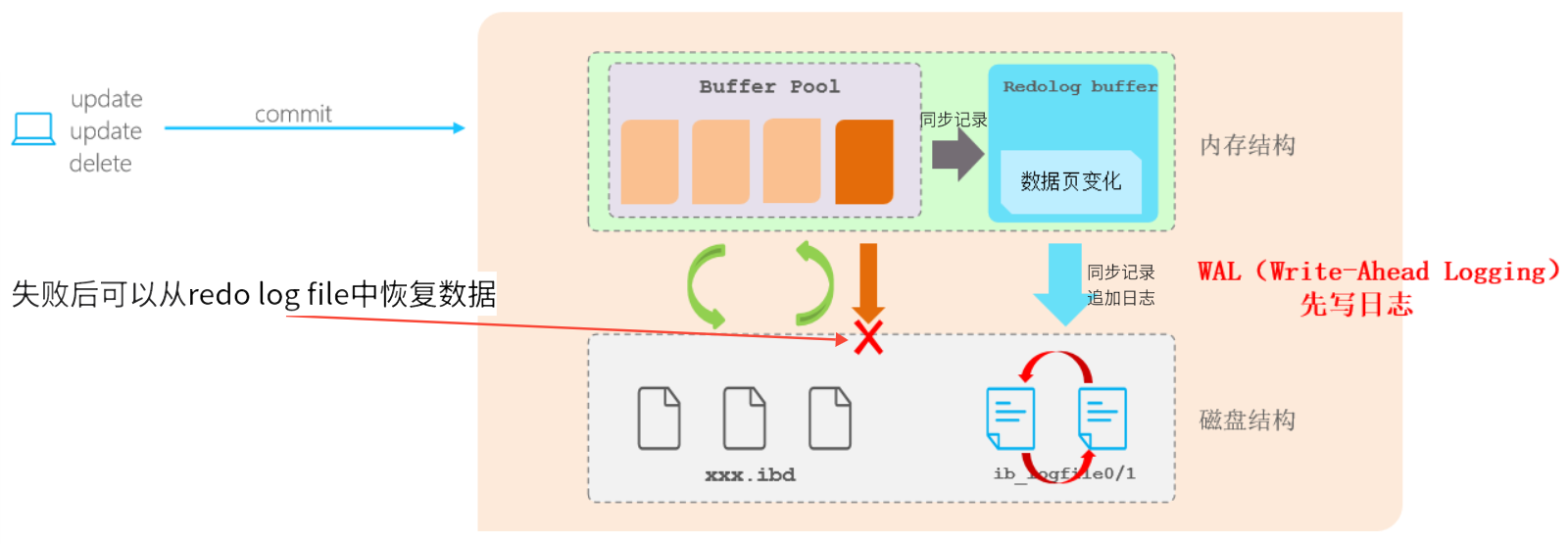
redo log(物理日志)——————实现了事物的持久性
-
作用:重做日志,记录的是事务提交时数据页的物理修改。保证了事务的持久性。
-
该日志文件由两部分组成:重做日志缓冲(
redo log buffer)以及重做日志文件(redo log file),前者是在内存中,后者在磁盘中。 -
当事务提交之后会把所有修改信息都存到该日志文件中, 用于在刷新脏页到磁盘,发生错误时, 进行数据恢复使用。
-
undo log(逻辑日志)——————实现了事物的一致性和原子性
-
回滚日志存储旧版本的数据,和redo log记录物理日志不同,它是逻辑日志,用于记录数据被修改前的信息 。保证了事务的一致性和原子性。
-
作用包含两个 :
提供回滚和MVCC(多版本并发控制)。-
在insert、update、delete的时候产生的便于数据回滚的日志。
-
当insert的时候,产生的undo log日志只在回滚时需要,在事务提交后,可被立即删除。
-
而update、delete的时候,产生的undo log日志不仅在回滚时需要,mvcc版本访问也需要,不会立即被删除。
-
-
可以理解为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然。当update一条记录时,它记录一条对应相反的update记录。
-
当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。
-
4.MVCC
redo log和under log分别实现了事物的持久性、原子性和一致性。
事物的隔离性是如何实现的?事物的隔离性是由锁(排他锁(如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁))和mvcc(多版本并发控制)共同实现的
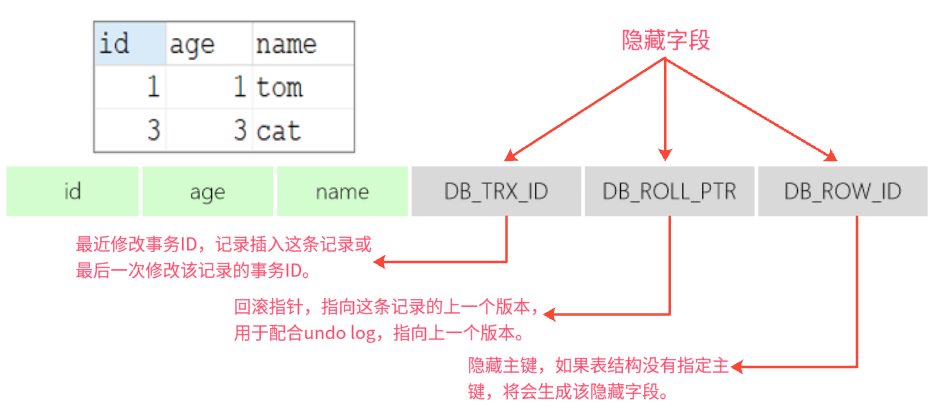
全称 Multi-Version Concurrency Control,多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突。MVCC的具体实现,主要依赖于数据库记录中的隐藏字段、undo log日志、readView。
隐藏字段:
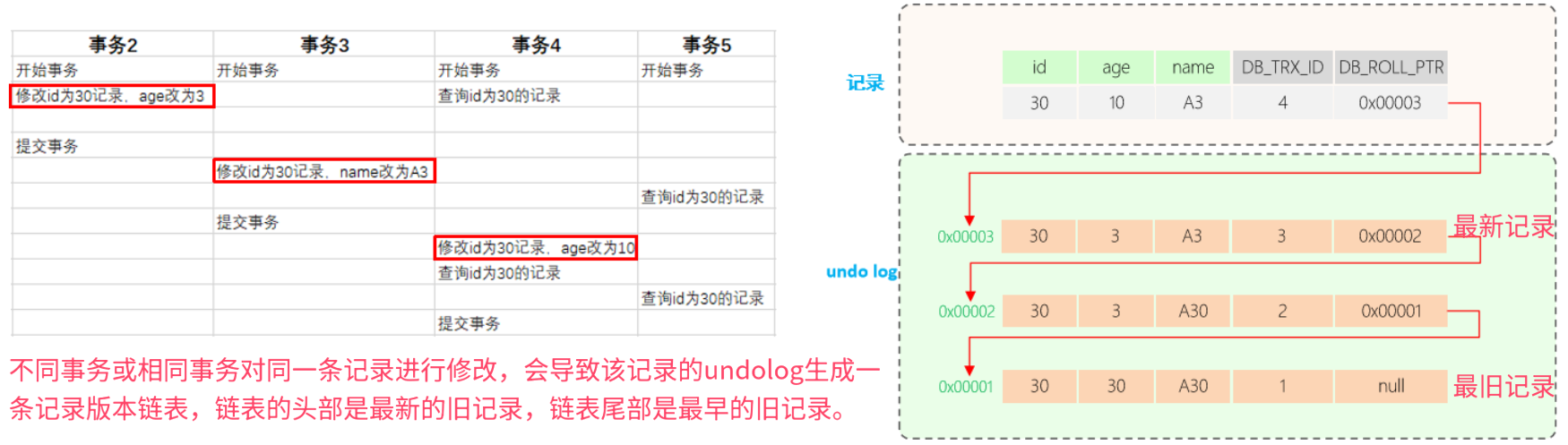
undo log版本链:
多个事务并行操作某一行记录,记录不同事务修改数据的版本,通过roll_pointer指针形成一个链表
readView:
ReadView(读视图)是快照读SQL执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务(未提交的)id。解决了事物查询选择版本的问题。
-
当前读:
-
读取的是记录的最新版本`,读取时还要保证其他的并发事务不能修改当前的记录,会对读取的记录进行加锁。
-
对于我们日常的操作,如:select... lock in share mode(共享锁),select... for update、update、insert、delete(排他锁)都是一种当前读。
-
-
快照读:
-
普通的 select(不加锁)就是快照读,快照读,
读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读。
-
Read Committed(RC,读已提交):每次 select,都生成一个快照读。
-
Repeatable Read(RR,可重复读):开启事务后第一个 select 语句才是快照读的地方。
-
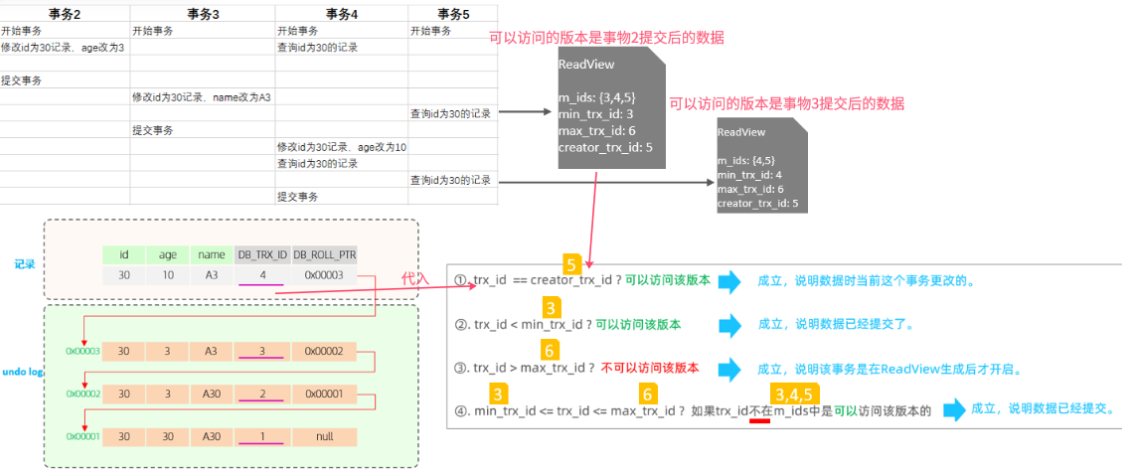
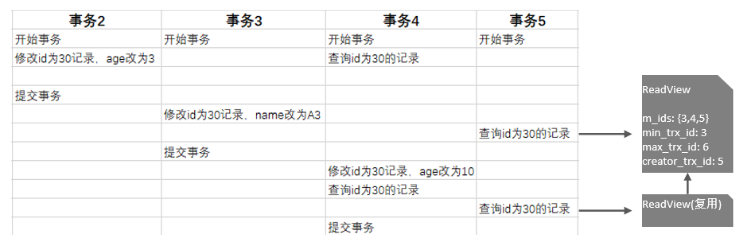
Readview中包含的四个核心字段及版本链数据访问规则:

不同的隔离级别,生成ReadView的时机不同:
-
READ COMMITTED (RC):在事务中每一次执行快照读时生成ReadView。
-
-
REPEATABLE READ(RR):仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView。
五、MySQL的主从同步原理
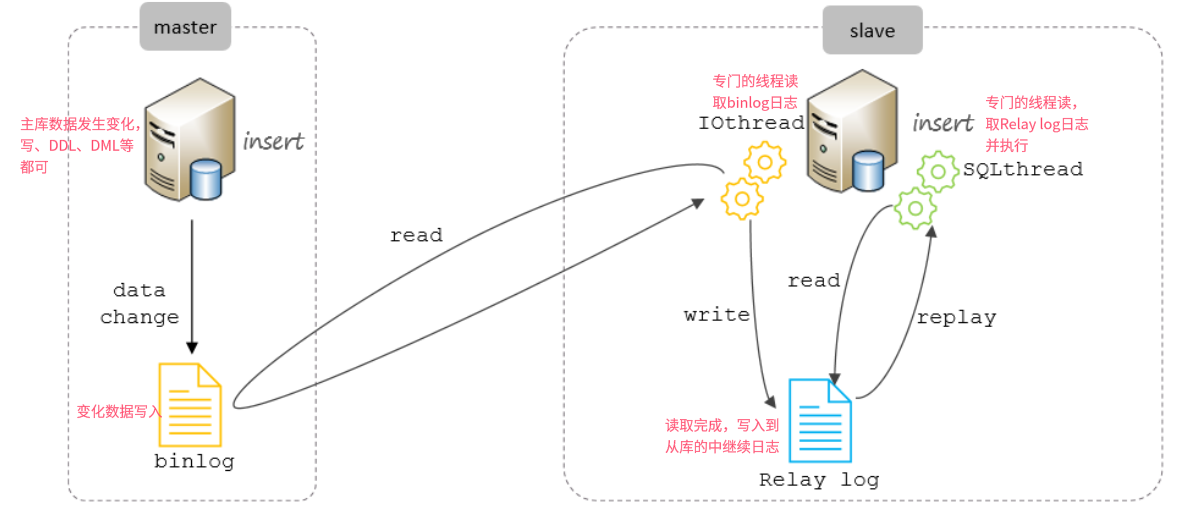
MySQL主从复制的核心就是二进制日志
-
二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句。
步骤:
-
Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
-
从库读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log 。
-
slave重做中继日志中的事件,将改变反映它自己的数据。
六、分库分表
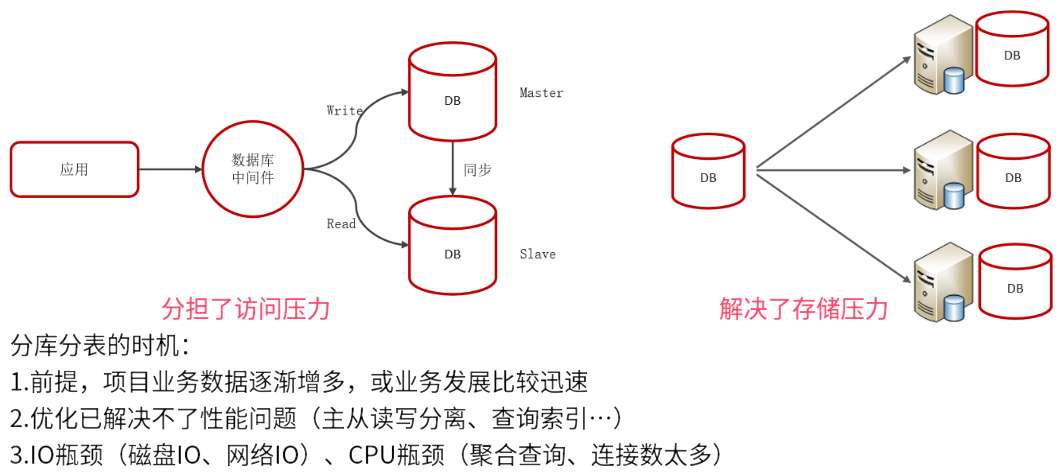
垂直拆分:垂直分库、垂直分表;水平拆分:水平分库、水平分表;
垂直拆分:
-
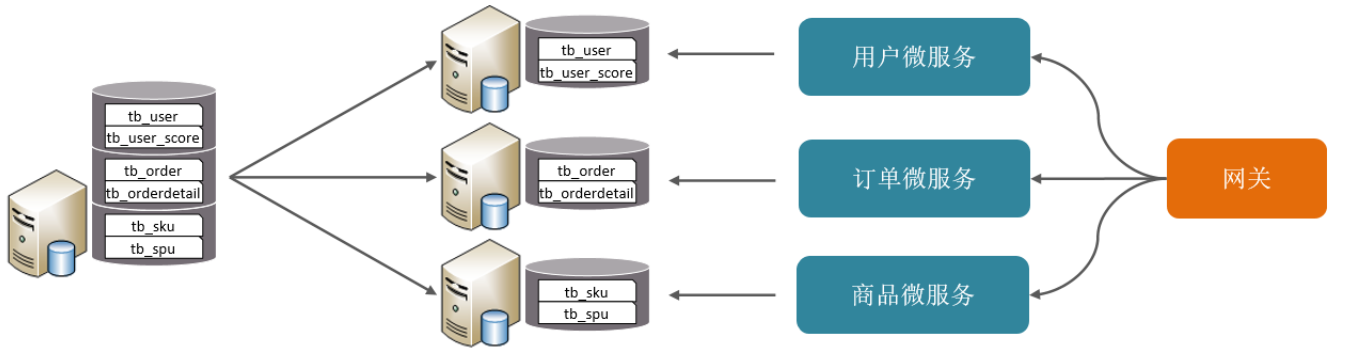
垂直分库:以表为依据,根据业务将不同表拆分到不同库中。
-
特点:
-
按业务对数据分级管理、维护、监控、扩展
-
在高并发下,提高磁盘IO和数据量连接数
-
-
-
-
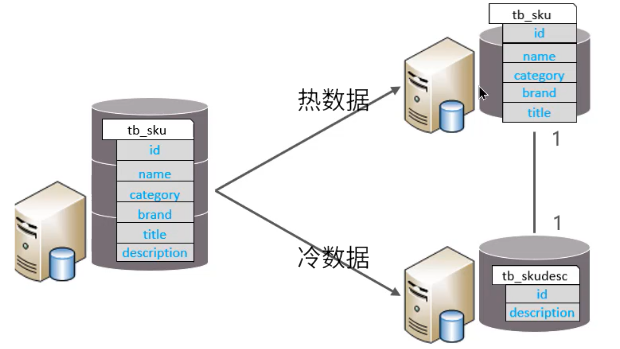
垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中。
-
特点:
-
冷热数据分离
-
减少IO过渡争抢,两表互不影响
-
-
拆分规则:
-
把不常用的字段单独放在一张表
-
把text,blob等大字段拆分出来放在附表中
-
-
-
水平拆分:
-
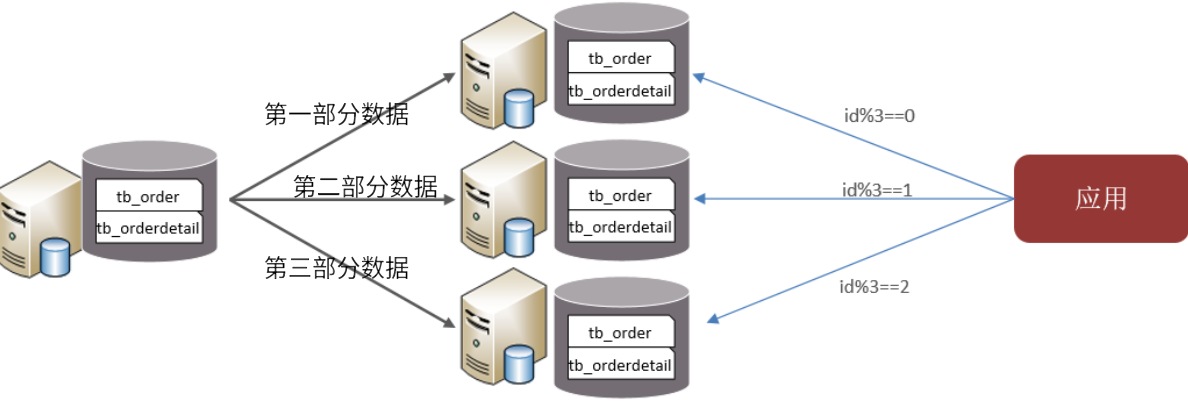
水平分库:将一个库的数据拆分到多个库中。
-
特点:
-
解决了单库大数量,高并发的性能瓶颈问题
-
提高了系统的稳定性和可用性
-
-
路由规则:
-
根据id节点取模
-
按id也就是范围路由,节点1(1-100万 ),节点2(100万-200万)
-
……
-
-
-
-
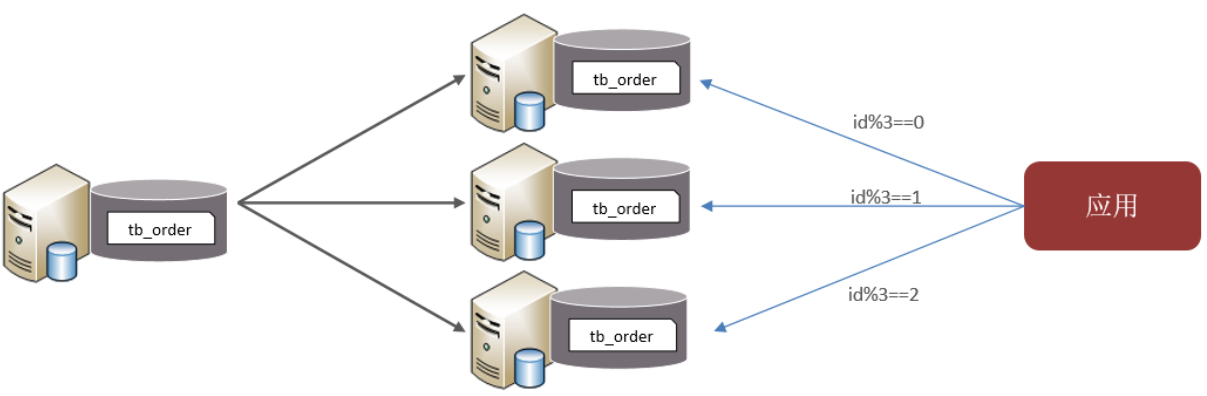
水平分表:将一个表的数据拆分到多个表中(
可以在同一个库内)。-
特点:
-
优化单一表数据量过大而产生的性能问题
-
免IO争抢并减少锁表的几率
-
-
路由规则参考水平分库的
-
分库分表的策略及问题
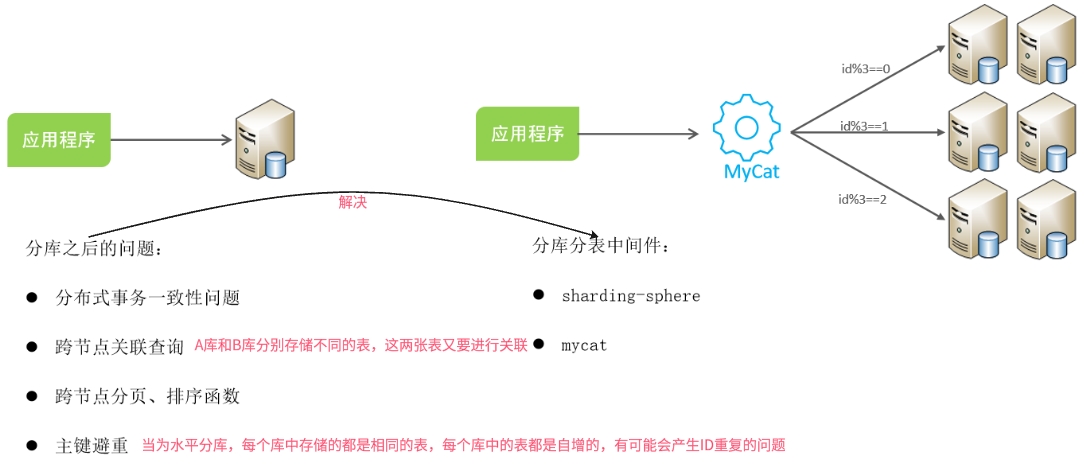
总结:
-
水平分库,将一个库的数据拆分到多个库中,解决海量数据存储和高并发的问题
-
水平分表,解决单表存储和性能的问题
-
垂直分库(适用于微服务),根据业务进行拆分,高并发下提高磁盘IO和网络连接数
-
垂直分表,冷热数据分离,多表互不影响

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 36
36 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)