AI人工智能与Actor - Critic算法的碰撞
想象一位天赋异禀的年轻厨师(Actor)正在学习烹饪艺术,旁边站着一位经验丰富的美食评论家(Critic)。厨师不断尝试新的菜肴组合,而评论家则根据每道菜的味道、 presentation 和创新性给出反馈。随着时间的推移,厨师逐渐理解了哪些组合能创造出真正令人难忘的美食,而评论家也越来越擅长准确评估和指导。这正是Actor-Critic算法的核心思想——两个智能体的动态协作,共同学习如何在复杂环
AI人工智能与Actor-Critic算法的碰撞:深度强化学习的动态协作艺术

关键词
强化学习, Actor-Critic, 深度强化学习, 策略梯度, 价值函数, 智能决策, 神经网络
摘要
想象一位天赋异禀的年轻厨师(Actor)正在学习烹饪艺术,旁边站着一位经验丰富的美食评论家(Critic)。厨师不断尝试新的菜肴组合,而评论家则根据每道菜的味道、 presentation 和创新性给出反馈。随着时间的推移,厨师逐渐理解了哪些组合能创造出真正令人难忘的美食,而评论家也越来越擅长准确评估和指导。这正是Actor-Critic算法的核心思想——两个智能体的动态协作,共同学习如何在复杂环境中做出最优决策。
本文将带您深入探索Actor-Critic算法这一融合了策略梯度与价值函数优势的强大框架。我们将从强化学习的基础出发,逐步揭开Actor-Critic的神秘面纱,解析其数学原理,展示如何通过深度神经网络实现这一算法,并探讨其在游戏AI、机器人控制、自动驾驶等前沿领域的革命性应用。无论您是AI领域的初学者还是希望深入理解强化学习的专业人士,这篇文章都将为您提供清晰的概念解释、实用的代码示例和深刻的行业洞察。
1. 背景介绍:强化学习的困境与突破
1.1 从试错学习到智能决策
在人工智能的发展历程中,我们一直致力于教会机器如何像人类一样学习和决策。强化学习(Reinforcement Learning, RL)作为机器学习的一个重要分支,专注于如何使智能体(Agent)通过与环境的交互来学习最优行为策略。
与监督学习不同,强化学习中没有"正确答案"可供直接学习;与无监督学习也不同,它有明确的奖励信号来指导学习过程。强化学习更像是一种"从经验中学习"的范式——智能体通过尝试不同的行动,观察环境的反馈(奖励),逐渐调整自己的行为策略,以最大化长期累积奖励。
这种学习方式与人类和动物的自然学习过程极为相似。想想看,当我们学习骑自行车时,没有人会给我们提供数百万张正确姿势的图片(监督学习),我们也不是在无目的地尝试(无监督学习)。相反,我们通过尝试不同的平衡方式,感受身体的倾斜(反馈),不断调整姿势,最终掌握了这项技能。
1.2 强化学习的两大支柱:策略与价值
在强化学习的发展过程中,逐渐形成了两种主要的方法体系:
基于策略(Policy-based)的方法:直接学习一个策略函数π(a∣s)\pi(a|s)π(a∣s),该函数表示在给定状态sss下选择动作aaa的概率分布。策略梯度(Policy Gradient)是这类方法的代表,它通过直接优化策略参数来最大化期望累积奖励。
基于价值(Value-based)的方法:学习一个价值函数V(s)V(s)V(s)或Q(s,a)Q(s,a)Q(s,a),分别表示在状态sss下的期望累积奖励,或在状态sss下执行动作aaa后的期望累积奖励。Q-learning和SARSA是这类方法的典型代表,它们通过估计最优价值函数来间接地确定最优策略。
1.3 两种方法的局限性
尽管基于策略和基于价值的方法都取得了显著成功,但它们各自存在明显的局限性:
基于策略的方法:
- 通常具有较好的收敛性,但学习过程方差较大,导致学习不稳定
- 每次更新需要大量采样,样本效率较低
- 难以评估当前策略的好坏,缺乏中间反馈
基于价值的方法:
- 学习过程方差较小,但容易陷入局部最优
- 在连续动作空间中应用困难,通常需要离散化处理
- 无法直接表示随机策略,而随机策略在许多场景中更为鲁棒
1.4 Actor-Critic:融合优势的创新框架
Actor-Critic算法的诞生正是为了克服上述两种方法的局限性,它巧妙地将策略梯度和价值函数结合起来,形成了一个协同工作的双智能体系统:
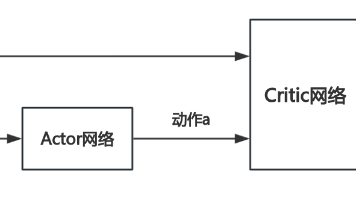
- Actor(执行者):负责学习和执行策略,决定在特定状态下应该采取什么动作
- Critic(评论家):负责评估Actor的动作好坏,通过价值函数提供反馈信号
这种架构的优势在于:
- Critic提供的价值估计可以减少策略梯度的方差,提高学习稳定性
- Actor可以直接在连续动作空间中学习,无需离散化
- 两者可以并行学习,相互促进,提高整体学习效率
1.5 本文目标读者与阅读收获
本文适合以下读者:
- 对人工智能和机器学习有基本了解,希望深入学习强化学习的开发者
- 正在研究或应用强化学习算法的科研人员和工程师
- 希望了解Actor-Critic算法原理及其实际应用的技术决策者
- 对AI决策系统背后的数学原理感兴趣的技术爱好者
阅读本文后,您将能够:
- 清晰理解Actor-Critic算法的核心原理和数学基础
- 掌握不同类型Actor-Critic变体的特点和适用场景
- 能够使用Python和深度学习框架实现基本的Actor-Critic算法
- 了解Actor-Critic在各个领域的创新应用和未来发展趋势
2. 核心概念解析:Actor与Critic的协作舞蹈
2.1 强化学习的基本框架
在深入Actor-Critic算法之前,让我们先回顾强化学习的基本框架。一个典型的强化学习系统由以下几个核心组件构成:
- 智能体(Agent):学习和执行动作的主体
- 环境(Environment):智能体所处的外部世界
- 状态(State):环境的当前情况,通常表示为sss
- 动作(Action):智能体可以执行的操作,通常表示为aaa
- 奖励(Reward):环境对智能体动作的即时反馈,通常表示为rrr
- 策略(Policy):智能体从状态到动作的映射,通常表示为π(a∣s)\pi(a|s)π(a∣s)
- 价值函数(Value Function):对未来奖励的预测,通常表示为V(s)V(s)V(s)或Q(s,a)Q(s,a)Q(s,a)
智能体与环境的交互过程可以描述为一个循环:智能体观察环境状态sts_tst,根据策略选择动作ata_tat,执行动作后环境转移到新状态st+1s_{t+1}st+1,并给予智能体奖励rt+1r_{t+1}rt+1。这一过程可以用以下Mermaid流程图表示:
graph TD
A[开始] --> B[观察状态 s_t]
B --> C[根据策略 π 选择动作 a_t]
C --> D[执行动作 a_t]
D --> E[环境反馈: 奖励 r_{t+1} 和新状态 s_{t+1}]
E --> F[智能体学习更新]
F --> B
2.2 Actor与Critic:舞伴关系的精妙比喻
理解Actor-Critic算法最直观的方式是将其比作一对舞蹈伙伴:
想象一场探戈舞表演:
- Actor 是舞蹈者,负责执行具体的舞步(动作),他的目标是跳出优美流畅的舞蹈(最大化累积奖励)
- Critic 是舞蹈教练或评委,不直接跳舞,但会根据舞蹈规则和美学标准(价值函数)对Actor的每一个动作给出评价和反馈
- Actor根据Critic的反馈不断调整自己的舞步,而Critic也通过观察Actor的表现和实际效果来改进自己的评价标准
这种关系的精妙之处在于:
- 分工明确:Actor专注于行动,Critic专注于评估
- 相互学习:两者都从交互经验中学习并不断进步
- 共同目标:最终都是为了实现最优的整体表现(最大化累积奖励)
2.3 Actor的角色与职责
在Actor-Critic框架中,Actor的主要职责是学习和表示策略πθ(a∣s)\pi_\theta(a|s)πθ(a∣s),其中θ\thetaθ是策略的参数。具体来说,Actor需要:
- 根据当前状态选择动作:在给定状态sss下,根据策略πθ(a∣s)\pi_\theta(a|s)πθ(a∣s)输出动作的概率分布,并从中采样动作aaa
- 接收Critic的反馈:获取Critic对其动作的评价信号
- 更新策略参数:使用策略梯度方法调整参数θ\thetaθ,以提高获得高奖励的概率
Actor可以表示确定性策略或随机性策略:
- 确定性策略:a=πθ(s)a = \pi_\theta(s)a=πθ(s),在给定状态下输出一个确定的动作
- 随机性策略:a∼πθ(a∣s)a \sim \pi_\theta(a|s)a∼πθ(a∣s),在给定状态下输出一个动作的概率分布
在Actor-Critic算法中,通常使用随机性策略,因为它能提供更多样化的探索,并且便于使用策略梯度方法进行优化。
2.4 Critic的角色与职责
Critic的主要职责是评估Actor的动作好坏,它通过学习价值函数来实现这一目标。Critic需要:
- 观察状态和动作:了解Actor在什么状态下采取了什么动作
- 评估动作价值:计算当前状态的价值或特定动作的价值
- 提供反馈信号:将价值评估结果转化为Actor可以使用的学习信号
Critic可以学习不同类型的价值函数:
- 状态价值函数 Vϕ(s)V_\phi(s)Vϕ(s):表示从状态sss开始,遵循当前策略能够获得的期望累积奖励
- 动作价值函数 Qϕ(s,a)Q_\phi(s,a)Qϕ(s,a):表示在状态sss下执行动作aaa后,遵循当前策略能够获得的期望累积奖励
- 优势函数 Aϕ(s,a)A_\phi(s,a)Aϕ(s,a):表示在状态sss下执行动作aaa相对于平均水平的优势,即A(s,a)=Q(s,a)−V(s)A(s,a) = Q(s,a) - V(s)A(s,a)=Q(s,a)−V(s)
优势函数在Actor-Critic算法中尤为重要,因为它能够提供更有效的反馈信号,告诉Actor某个动作比平均水平好多少或差多少。
2.5 Actor与Critic的协作流程
Actor和Critic的协作可以概括为以下步骤:
- 观察与行动:Actor观察当前环境状态sss,根据策略πθ(a∣s)\pi_\theta(a|s)πθ(a∣s)选择并执行动作aaa
- 环境反馈:环境转移到新状态s′s's′,并给予奖励rrr
- 价值评估:Critic根据状态sss、动作aaa、奖励rrr和新状态s′s's′评估Actor的表现,计算价值或优势
- 策略更新:Actor使用Critic提供的反馈信号(通常是优势估计)通过策略梯度更新策略参数θ\thetaθ
- 价值更新:Critic根据实际奖励和新状态的价值估计更新自己的价值函数参数ϕ\phiϕ
- 循环迭代:重复上述过程,直到策略收敛或达到预设的学习次数
这个协作流程可以用以下Mermaid序列图表示:
sequenceDiagram
participant Environment
participant Actor
participant Critic
Environment->>Actor: 当前状态 s
Actor->>Actor: 根据 π_θ(a|s) 选择动作 a
Actor->>Environment: 执行动作 a
Environment->>Critic: 状态 s, 奖励 r, 新状态 s'
Environment->>Actor: 状态 s, 奖励 r, 新状态 s'
Actor->>Critic: 请求评估
Critic->>Critic: 计算价值/优势 A(s,a)
Critic->>Actor: 反馈 A(s,a)
Actor->>Actor: 使用 ∇θ logπ_θ(a|s)·A(s,a) 更新 θ
Critic->>Critic: 使用 TD 误差更新 φ
loop 直到收敛
Environment->>Actor: 当前状态 s'
... (重复上述流程)
end
2.6 Actor-Critic与其他RL方法的关系
为了更好地理解Actor-Critic的定位,我们可以将其与其他强化学习方法进行比较:
| 方法类型 | 代表算法 | 核心思想 | 优势 | 劣势 |
|---|---|---|---|---|
| 基于价值 | Q-Learning, SARSA | 学习价值函数,间接确定策略 | 学习稳定,方差小 | 连续动作空间困难,无法表示随机策略 |
| 基于策略 | REINFORCE | 直接学习策略函数 | 适用于连续动作空间,可表示随机策略 | 学习不稳定,方差大,样本效率低 |
| Actor-Critic | A2C, A3C, DDPG | 同时学习策略和价值函数 | 兼顾两者优势,方差小,样本效率高 | 实现复杂,需要协调两个网络的学习 |
Actor-Critic可以看作是基于策略方法和基于价值方法的有机融合,它继承了前者直接优化策略的能力和后者提供稳定学习信号的优势,从而在性能上往往优于单一方法。
3. 技术原理与实现:从数学公式到代码
3.1 策略梯度:Actor学习的数学基础
策略梯度方法是Actor学习的理论基础。它的核心思想是通过调整策略参数θ\thetaθ来最大化期望累积奖励J(θ)J(\theta)J(θ):
J(θ)=Eτ∼πθ[R(τ)]J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} [R(\tau)]J(θ)=Eτ∼πθ[R(τ)]
其中τ=(s0,a0,r1,s1,a1,...,rT,sT)\tau = (s_0, a_0, r_1, s_1, a_1, ..., r_T, s_T)τ=(s0,a0,r1,s1,a1,...,rT,sT)是一条完整的轨迹,R(τ)=∑t=0T−1γtrt+1R(\tau) = \sum_{t=0}^{T-1} \gamma^t r_{t+1}R(τ)=∑t=0T−1γtrt+1是这条轨迹的累积奖励,γ\gammaγ是折扣因子。
策略梯度定理告诉我们,J(θ)J(\theta)J(θ)的梯度可以表示为:
∇θJ(θ)=Eτ∼πθ[∑t=0T−1∇θlogπθ(at∣st)⋅Gt]\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot G_t \right]∇θJ(θ)=Eτ∼πθ[t=0∑T−1∇θlogπθ(at∣st)⋅Gt]
其中Gt=∑k=tT−1γk−trk+1G_t = \sum_{k=t}^{T-1} \gamma^{k-t} r_{k+1}Gt=∑k=tT−1γk−trk+1是从时间步ttt开始的累积奖励,也称为回报(Return)。
这一公式的直观解释是:如果一个动作ata_tat之后跟随正的回报GtG_tGt,我们就增加这个动作被选中的概率;反之,如果跟随负的回报,我们就减少这个动作被选中的概率。∇θlogπθ(at∣st)\nabla_\theta \log \pi_\theta(a_t|s_t)∇θlogπθ(at∣st)表示策略对参数的敏感度,而GtG_tGt则是调整的方向和幅度。
3.2 价值函数与TD学习:Critic的工具箱
Critic的核心任务是估计价值函数,常用的方法包括蒙特卡洛(Monte Carlo, MC)方法和时序差分(Temporal Difference, TD)学习。
蒙特卡洛方法:通过完整轨迹的实际回报来估计价值:
V(st)←V(st)+α(Gt−V(st))V(s_t) \leftarrow V(s_t) + \alpha (G_t - V(s_t))V(st)←V(st)+α(Gt−V(st))
其中α\alphaα是学习率,GtG_tGt是实际观察到的回报。
时序差分学习:不需要等待完整轨迹结束,而是使用 bootstrap 方法,通过估计的未来价值来更新当前价值:
V(st)←V(st)+α(rt+1+γV(st+1)−V(st))V(s_t) \leftarrow V(s_t) + \alpha (r_{t+1} + \gamma V(s_{t+1}) - V(s_t))V(st)←V(st)+α(rt+1+γV(st+1)−V(st))
这里rt+1+γV(st+1)r_{t+1} + \gamma V(s_{t+1})rt+1+γV(st+1)称为TD目标,而(rt+1+γV(st+1)−V(st))(r_{t+1} + \gamma V(s_{t+1}) - V(s_t))(rt+1+γV(st+1)−V(st))称为TD误差。
TD学习相比MC方法有两个主要优势:
- 可以在线学习,无需等待轨迹结束
- 通常具有更低的方差,学习更稳定
因此,在Actor-Critic算法中,Critic通常采用TD学习来估计价值函数。
3.3 优势函数:连接Actor与Critic的桥梁
在基础的策略梯度中,我们使用回报GtG_tGt作为加权因子。然而,GtG_tGt的方差通常很大,导致学习不稳定。Actor-Critic算法的关键创新在于使用Critic估计的价值函数来减少这种方差。
最常用的方法是使用优势函数(Advantage Function) Aπ(s,a)A^\pi(s,a)Aπ(s,a),它定义为:
Aπ(s,a)=Qπ(s,a)−Vπ(s)A^\pi(s,a) = Q^\pi(s,a) - V^\pi(s)Aπ(s,a)=Qπ(s,a)−Vπ(s)
直观地说,优势函数表示在状态sss下选择动作aaa相比于平均水平的优势。如果Aπ(s,a)>0A^\pi(s,a) > 0Aπ(s,a)>0,说明这个动作比平均水平好;如果Aπ(s,a)<0A^\pi(s,a) < 0Aπ(s,a)<0,则说明比平均水平差。
使用优势函数,策略梯度可以重写为:
∇θJ(θ)≈E[∇θlogπθ(at∣st)⋅A(st,at)]\nabla_\theta J(\theta) \approx \mathbb{E} \left[ \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot A(s_t,a_t) \right]∇θJ(θ)≈E[∇θlogπθ(at∣st)⋅A(st,at)]
优势函数的估计方法有多种,其中最常用的是TD误差:
δt=rt+1+γV(st+1)−V(st)\delta_t = r_{t+1} + \gamma V(s_{t+1}) - V(s_t)δt=rt+1+γV(st+1)−V(st)
当使用TD误差作为优势估计时,我们得到了最简单的Actor-Critic算法形式。
3.4 Actor-Critic的数学框架
综合以上内容,Actor-Critic算法的完整数学框架可以表示为:
- 策略(Actor):πθ(a∣s)\pi_\theta(a|s)πθ(a∣s),参数为θ\thetaθ
- 价值函数(Critic):Vϕ(s)V_\phi(s)Vϕ(s),参数为ϕ\phiϕ
- 优势估计:A^t=δt=rt+1+γVϕ(st+1)−Vϕ(st)\hat{A}_t = \delta_t = r_{t+1} + \gamma V_\phi(s_{t+1}) - V_\phi(s_t)A^t=δt=rt+1+γVϕ(st+1)−Vϕ(st)
- Actor更新:θ←θ+αθ∇θlogπθ(at∣st)A^t\theta \leftarrow \theta + \alpha_\theta \nabla_\theta \log \pi_\theta(a_t|s_t) \hat{A}_tθ←θ+αθ∇θlogπθ(at∣st)A^t
- Critic更新:ϕ←ϕ+αϕδt∇ϕVϕ(st)\phi \leftarrow \phi + \alpha_\phi \delta_t \nabla_\phi V_\phi(s_t)ϕ←ϕ+αϕδt∇ϕVϕ(st)
其中αθ\alpha_\thetaαθ和αϕ\alpha_\phiαϕ分别是Actor和Critic的学习率。
3.5 深度Actor-Critic:神经网络的力量
随着深度学习的发展,我们现在可以使用神经网络来表示复杂的策略和价值函数,这就是深度Actor-Critic算法。
策略网络(Actor Network):通常是一个输出动作分布参数的神经网络。对于连续动作空间,常用高斯分布,网络输出均值和标准差;对于离散动作空间,常用softmax输出动作概率。
价值网络(Critic Network):通常是一个输出状态价值估计的神经网络,输入是状态,输出是一个标量值。
深度Actor-Critic的优势在于:
- 能够处理高维状态空间(如图像输入)
- 能够表示复杂的非线性策略和价值函数
- 可以通过端到端学习直接从原始输入中提取特征
3.6 实现一个基本的Actor-Critic算法
现在,让我们通过代码实现一个基本的Actor-Critic算法。我们将使用OpenAI Gym的CartPole环境作为示例,这是一个经典的控制问题,目标是通过左右移动小车来保持杆的平衡。
首先,我们需要导入必要的库:
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Categorical
import gym
接下来,定义Actor和Critic网络。在这个简单示例中,我们可以使用共享的特征提取层,然后分支出策略头和价值头:
class ActorCritic(nn.Module):
def __init__(self, state_dim, action_dim, hidden_dim=64):
super(ActorCritic, self).__init__()
# 共享特征层
self.shared = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.Tanh()
)
# Actor头:输出动作概率
self.actor = nn.Sequential(
nn.Linear(hidden_dim, action_dim),
nn.Softmax(dim=-1)
)
# Critic头:输出状态价值
self.critic = nn.Linear(hidden_dim, 1)
def forward(self, state):
x = self.shared(state)
policy = self.actor(x)
value = self.critic(x)
return policy, value
现在,实现Actor-Critic的学习过程:
def train_actor_critic(env, model, optimizer, episodes=1000, gamma=0.99):
scores = [] # 记录每回合的得分
for episode in range(episodes):
state = env.reset()
state = torch.FloatTensor(state)
score = 0
log_probs = [] # 存储对数概率
values = [] # 存储状态价值
rewards = [] # 存储奖励
while True:
# Actor选择动作
policy, value = model(state)
dist = Categorical(policy)
action = dist.sample()
log_prob = dist.log_prob(action)
# 执行动作
next_state, reward, done, _ = env.step(action.item())
next_state = torch.FloatTensor(next_state)
# 存储数据
log_probs.append(log_prob)
values.append(value)
rewards.append(reward)
score += reward
state = next_state
if done:
break
# 计算回报和优势
R = 0
returns = []
for r in reversed(rewards):
R = r + gamma * R
returns.insert(0, R)
returns = torch.FloatTensor(returns)
# 标准化回报(可选,但有助于稳定训练)
returns = (returns - returns.mean()) / (returns.std() + 1e-7)
# 计算损失
actor_loss = 0
critic_loss = 0
for log_prob, value, R in zip(log_probs, values, returns):
advantage = R - value.item()
actor_loss -= log_prob * advantage # 策略梯度上升
critic_loss += F.mse_loss(value, torch.tensor([R])) # 价值函数均方误差
# 综合损失
total_loss = actor_loss + 0.5 * critic_loss
# 反向传播和优化
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
# 记录和打印结果
scores.append(score)
if episode % 100 == 0:
print(f"Episode {episode}, Average Score: {np.mean(scores[-100:])}")
# 如果连续100回合平均得分超过195,认为问题已解决
if np.mean(scores[-100:]) > 195:
print(f"Solved! Average Score: {np.mean(scores[-100:])}")
break
return scores
最后,创建环境、模型和优化器,并开始训练:
# 创建环境
env = gym.make('CartPole-v1')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
# 创建模型和优化器
model = ActorCritic(state_dim, action_dim)
optimizer = optim.Adam(model.parameters(), lr=3e-4)
# 训练模型
scores = train_actor_critic(env, model, optimizer, episodes=2000)
# 关闭环境
env.close()
3.7 算法变体:从A2C到PPO
基本的Actor-Critic算法虽然简单,但在实际应用中往往需要改进以获得更好的性能。以下是一些流行的Actor-Critic变体:
A2C (Advantage Actor-Critic):
A2C是基本Actor-Critic的一个简单改进,它明确使用优势函数来更新策略,并通常使用多个并行环境来收集经验,提高样本效率。
A3C (Asynchronous Advantage Actor-Critic):
A3C是DeepMind提出的一种异步版本的A2C算法,它使用多个并行的智能体实例独立地与环境交互,异步地更新全局参数。这种方法可以有效减少样本间的相关性,提高学习稳定性。
DDPG (Deep Deterministic Policy Gradient):
DDPG适用于连续动作空间,它结合了DQN和Actor-Critic的思想,使用确定性策略,并通过经验回放和目标网络来提高稳定性。
PPO (Proximal Policy Optimization):
PPO是OpenAI提出的一种高效的策略优化方法,它通过限制策略更新的幅度来提高稳定性和样本效率。PPO有两种主要变体:PPO-Penalty和PPO-Clip,其中后者更为常用。
PPO的核心思想是使用"剪辑"的目标函数来确保新策略不会与旧策略相差太大:
LCLIP(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]L^{CLIP}(\theta) = \mathbb{E}_t \left[ \min(r_t(\theta) \hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_t) \right]LCLIP(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
其中rt(θ)=πθ(at∣st)πθold(at∣st)r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}rt(θ)=πθold(at∣st)πθ(at∣st)是新策略与旧策略的概率比值,ϵ\epsilonϵ是一个超参数(通常设为0.2)。
PPO通常比A3C更容易实现,且性能相当或更好,因此在实际应用中更为流行。
3.8 训练稳定性与超参数调优
Actor-Critic算法的训练稳定性是一个重要挑战。以下是一些提高训练稳定性的关键技巧:
- 优势标准化:将优势函数标准化为零均值和单位方差,有助于稳定策略更新
- 梯度裁剪:限制梯度的最大范数,防止梯度爆炸
- 学习率调度:随着训练进行逐渐降低学习率
- 熵正则化:在策略损失中加入熵项,鼓励探索
- 目标网络:使用延迟更新的目标网络来计算目标值,减少训练波动
- 经验回放:存储和重用过去的经验,减少样本间的相关性(如DDPG)
关键超参数及其典型取值范围:
- 学习率:Actor通常在1e−4∼3e−41e-4 \sim 3e-41e−4∼3e−4,Critic通常稍大
- 折扣因子γ\gammaγ:通常在0.9∼0.990.9 \sim 0.990.9∼0.99之间
- 隐藏层大小:对于简单问题,64256个神经元;对于复杂问题,5121024个神经元
- 批次大小:根据计算资源,通常在32~2048之间
- 熵系数:通常在0.01∼0.10.01 \sim 0.10.01∼0.1之间,用于平衡探索与利用
4. 实际应用:从游戏到现实世界
4.1 游戏AI:超越人类的游戏玩家
游戏一直是强化学习的重要试验场,而Actor-Critic及其变体在这一领域取得了令人瞩目的成就:
Atari游戏:
DeepMind的DQN算法首次展示了AI可以通过像素输入掌握多种Atari游戏。随后的A3C算法进一步提高了性能和训练速度,能够在多种游戏上达到甚至超越人类水平。
围棋:
虽然AlphaGo主要基于蒙特卡洛树搜索(MCTS),但其策略网络和价值网络的训练过程采用了类似Actor-Critic的思想。AlphaGo Zero更是通过自我对弈(一种特殊的强化学习)从零开始掌握了围棋,并以100:0的战绩击败了之前的AlphaGo版本。
Dota 2与StarCraft II:
OpenAI的OpenAI Five使用PPO算法(一种先进的Actor-Critic变体)在5v5的Dota 2比赛中击败了世界冠军队伍。DeepMind的AlphaStar则在StarCraft II中达到了职业玩家水平。这些成就展示了Actor-Critic算法在处理复杂、长期规划、部分可观测的环境中的强大能力。
代码示例:使用PPO玩Atari游戏
虽然完整实现超出了本文范围,但以下是使用Stable Baselines3库(一个流行的强化学习库)实现PPO玩Atari游戏的示例代码:
import gym
from stable_baselines3 import PPO
from stable_baselines3.common.env_util import make_atari_env
from stable_baselines3.common.vec_env import VecFrameStack
# 创建Atari环境
env = make_atari_env('BreakoutNoFrameskip-v4', n_envs=4, seed=0)
# 堆叠4帧作为输入
env = VecFrameStack(env, n_stack=4)
# 创建PPO模型
model = PPO(
"CnnPolicy", # 使用卷积神经网络处理图像输入
env,
learning_rate=2.5e-4,
n_steps=128,
batch_size=256,
n_epochs=4,
gamma=0.99,
gae_lambda=0.95,
clip_range=0.1,
ent_coef=0.01,
verbose=1
)
# 训练模型
model.learn(total_timesteps=10_000_000)
# 保存模型
model.save("ppo_breakout")
# 加载模型并测试
model = PPO.load("ppo_breakout")
obs = env.reset()
while True:
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render()
4.2 机器人控制:赋予机器精细运动技能
Actor-Critic算法在机器人控制领域有着广泛应用,特别是在需要精细运动技能的任务中:
机械臂控制:
通过Actor-Critic算法,机械臂可以学习复杂的操作技能,如抓取、组装、插入等。DeepMind的DDPG算法成功地让机械臂学会了从杂乱的物体堆中抓取特定物体。
四足机器人行走:
使用PPO等算法,四足机器人可以学习稳定的行走、奔跑甚至跳跃动作。与传统控制方法相比,强化学习方法更具适应性,能够应对不同地形和负载条件。
灵巧手操作:
配备多个自由度的灵巧手是机器人领域的一大挑战。通过Actor-Critic算法,灵巧手可以学习精细的操作技能,如拧瓶盖、写字、使用工具等。
案例研究:使用DDPG控制机械臂
以下是使用DDPG算法训练机械臂进行目标跟踪的简化示例:
import torch
import torch.nn as nn
import numpy as np
import gym
from gym import spaces
# 定义Actor网络(确定性策略)
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, max_action):
super(Actor, self).__init__()
self.layer1 = nn.Linear(state_dim, 400)
self.layer2 = nn.Linear(400, 300)
self.layer3 = nn.Linear(300, action_dim)
self.max_action = max_action
def forward(self, x):
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = torch.tanh(self.layer3(x)) * self.max_action
return x
# 定义Critic网络
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
# Q1架构
self.layer1 = nn.Linear(state_dim + action_dim, 400)
self.layer2 = nn.Linear(400, 300)
self.layer3 = nn.Linear(300, 1)
# Q2架构(用于稳定训练的双Q网络)
self.layer4 = nn.Linear(state_dim + action_dim, 400)
self.layer5 = nn.Linear(400, 300)
self.layer6 = nn.Linear(300, 1)
def forward(self, x, u):
xu = torch.cat([x, u], 1)
x1 = F.relu(self.layer1(xu))
x1 = F.relu(self.layer2(x1))
x1 = self.layer3(x1)
x2 = F.relu(self.layer4(xu))
x2 = F.relu(self.layer5(x2))
x2 = self.layer6(x2)
return x1, x2
def Q1(self, x, u):
xu = torch.cat([x, u], 1)
x1 = F.relu(self.layer1(xu))
x1 = F.relu(self.layer2(x1))
x1 = self.layer3(x1)
return x1
# DDPG算法实现(简化版)
class DDPG:
def __init__(self, state_dim, action_dim, max_action):
self.actor = Actor(state_dim, action_dim, max_action)
self.actor_target = Actor(state_dim, action_dim, max_action)
self.actor_target.load_state_dict(self.actor.state_dict())
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=1e-4)
self.critic = Critic(state_dim, action_dim)
self.critic_target = Critic(state_dim, action_dim)
self.critic_target.load_state_dict(self.critic.state_dict())
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=1e-3)
self.max_action = max_action
def select_action(self, state):
state = torch.FloatTensor(state.reshape(1, -1))
return self.actor(state).cpu().data.numpy().flatten()
# 训练代码省略,完整实现需要经验回放缓冲区等...
# 假设我们有一个机械臂环境
# env = gym.make("RoboticArm-v0")
# state_dim = env.observation_space.shape[0]
# action_dim = env.action_space.shape[0]
# max_action = float(env.action_space.high[0])
# agent = DDPG(state_dim, action_dim, max_action)
# # 训练循环省略...
4.3 自动驾驶:通往未来交通的关键技术
自动驾驶是Actor-Critic算法的另一个重要应用领域,它需要在复杂、动态的环境中做出安全、高效的决策:
纵向控制:控制车辆的加速和减速,保持安全距离
横向控制:控制方向盘,保持车道或进行车道变换
决策制定:如变道、超车、转弯、路口通行等高级决策
优势与挑战:
- 优势:能够处理复杂的交通场景,适应不同的路况和天气条件
- 挑战:安全性要求极高,需要处理罕见但关键的边缘情况,解释性和可信赖性问题
案例:特斯拉的Autopilot与强化学习
虽然特斯拉的Autopilot系统细节未完全公开,但有报道称他们正在积极探索强化学习方法。2020年,特斯拉AI负责人Andrej Karpathy在公开演讲中提到,他们使用类似强化学习的方法来优化自动驾驶决策系统。
4.4 金融交易:智能决策的量化革命
金融交易是Actor-Critic算法的一个富有前景的应用领域,因为它本质上是一个序贯决策问题,需要在不确定环境中最大化长期回报:
算法交易:学习最优交易策略,决定何时买入、卖出或持有金融资产
投资组合优化:动态调整资产配置,平衡风险和回报
风险控制:学习识别和规避潜在的市场风险
案例研究:使用PPO进行加密货币交易
以下是一个使用PPO算法开发加密货币交易策略的概念框架:
# 伪代码:使用PPO进行加密货币交易
class CryptoTradingEnv(gym.Env):
def __init__(self, price_data):
super().__init__()
self.price_data = price_data
self.current_step = 0
self.balance = 10000 # 初始资金
self.assets_held = 0 # 持有的资产数量
# 动作空间:0=卖出,1=持有,2=买入
self.action_space = spaces.Discrete(3)
# 观察空间:包括价格、技术指标、持仓情况等
self.observation_space = spaces.Box(
low=-np.inf, high=np.inf, shape=(10,), dtype=np.float32
)
def step(self, action):
# 获取当前价格
current_price = self.price_data[self.current_step]
# 根据动作执行交易
if action == 0 and self.assets_held > 0:
# 卖出所有资产
self.balance += self.assets_held * current_price
self.assets_held = 0
elif action == 2 and self.balance > 0:
# 买入尽可能多的资产
self.assets_held += self.balance / current_price
self.balance = 0
# 计算资产净值
portfolio_value = self.balance + self.assets_held * current_price
# 计算奖励(资产净值变化)
reward = portfolio_value - self.prev_portfolio_value
self.prev_portfolio_value = portfolio_value
# 移动到下一步
self.current_step += 1
done = self.current_step >= len(self.price_data) - 1
# 构建观察状态(包括价格、技术指标等)
obs = self._build_observation()
return obs, reward, done, {}
# 其他必要方法省略...
# 使用PPO训练交易策略
# env = CryptoTradingEnv(historical_price_data)
# model = PPO("MlpPolicy", env, verbose=1)
# model.learn(total_timesteps=100000)
# # 评估策略
# obs = env.reset()
# for _ in range(len(env.price_data)):
# action, _states = model.predict(obs)
# obs, rewards, done, info = env.step(action)
# if done:
# break
# print(f"最终资产净值: {env.balance + env.assets_held * env.price_data[-1]}")
4.5 能源管理:智能电网与可持续未来
Actor-Critic算法在能源管理领域的应用正变得越来越重要,有助于实现更高效、更可持续的能源使用:
智能电网优化:动态调整电力生产和分配,平衡供需
建筑能源管理:优化 heating、通风和空调系统(HVAC),降低能耗
可再生能源整合:预测和管理太阳能、风能等间歇性可再生能源
案例:使用深度强化学习优化数据中心能源消耗
数据中心是能源消耗大户,使用Actor-Critic算法可以优化服务器集群的能源使用:
- 状态:服务器负载、温度、能源价格、任务队列等
- 动作:服务器开关、频率调整、任务调度等
- 奖励:能源成本节约、性能提升、可靠性维护的综合指标
4.6 医疗健康:个性化治疗与医疗决策
医疗健康是Actor-Critic算法最具社会价值的应用领域之一:
个性化治疗方案:根据患者的具体情况动态调整治疗方案
重症监护:优化ICU患者的生命支持系统参数
康复治疗:为中风或受伤患者设计个性化康复计划
案例:强化学习在 sepsis治疗中的应用
Sepsis(败血症)是一种危及生命的感染并发症,需要及时调整抗生素和液体治疗方案。DeepMind与伦敦大学学院合作开发的强化学习系统能够推荐最佳治疗方案,在模拟环境中表现优于人类医生。
5. 未来展望:Actor-Critic算法的发展趋势
5.1 算法改进方向
Actor-Critic算法仍在快速发展中,以下是几个有前景的研究方向:
样本效率提升:
当前的深度强化学习算法通常需要大量样本才能达到良好性能,这在许多实际应用中是不现实的。未来的研究将致力于开发更样本高效的Actor-Critic变体,可能的方向包括:
- 更好的探索策略
- 迁移学习和元学习技术
- 利用先验知识和结构化模型
稳定性与收敛性保证:
尽管在实践中取得了成功,但许多深度强化学习算法缺乏理论收敛性保证。未来的研究将致力于:
- 开发具有更强理论基础的Actor-Critic变体
- 更好的探索-利用平衡策略
- 自适应学习率和超参数调整方法
多智能体Actor-Critic:
在多智能体环境中,每个智能体的策略都在不断变化,使得环境本质上是非平稳的。多智能体Actor-Critic面临的挑战包括:
- 如何建模其他智能体的行为
- 如何实现合作与竞争的平衡
- 如何处理信用分配问题
5.2 与其他AI技术的融合
Actor-Critic算法将与其他AI技术深度融合,创造更强大的智能系统:
强化学习与监督学习的结合:
- 使用监督学习初始化Actor和Critic网络,加速学习过程
- 结合模仿学习,从专家示范中学习基本策略
- 使用半监督学习处理稀疏奖励问题
强化学习与自然语言处理的融合:
- 使用语言描述指导强化学习过程
- 将自然语言作为状态或动作空间的一部分
- 开发能够理解和生成自然语言解释的Actor-Critic系统
强化学习与计算机视觉的融合:
- 从原始图像直接学习复杂动作策略
- 结合视觉注意力机制,关注环境中的关键部分
- 开发能够处理部分可观测性的视觉强化学习系统
5.3 挑战与伦理考量
随着Actor-Critic等强化学习算法的广泛应用,一系列挑战和伦理问题亟待解决:
安全性与鲁棒性:
- 如何确保强化学习系统在面对意外情况时的安全性
- 如何防御对抗性攻击
- 如何避免强化学习系统利用环境漏洞或"欺骗"奖励函数
公平性与偏见:
- 强化学习系统可能从环境中学习到偏见
- 如何确保算法对不同群体的公平性
- 如何平衡不同利益相关者的需求
透明度与可解释性:
- "黑箱"决策过程难以获得人类信任
- 需要开发可解释的Actor-Critic变体
- 如何向人类用户解释AI系统的决策依据
责任与问责:
- 当强化学习系统造成伤害时,责任归属问题
- 如何设计具有适当"道德"约束的强化学习系统
- 强化学习系统的自主决策权应如何限制
5.4 行业影响与社会变革
Actor-Critic算法的发展和应用将对各个行业和整个社会产生深远影响:
劳动力转型:
- 自动化将改变许多工作的性质,部分工作可能被取代
- 新的就业机会将在AI开发、维护和监督领域出现
- 需要社会政策支持劳动力转型和再培训
医疗保健革命:
- 个性化治疗将提高医疗效果并降低成本
- 医疗资源分配将更加高效
- 远程和预防性医疗将得到加强
能源与环境:
- 智能能源管理将显著减少浪费和碳排放
- 可再生能源整合将加速能源转型
- 智能交通系统将减少拥堵和污染
教育变革:
- 个性化学习系统将根据学生需求调整教学内容和节奏
- 教育资源将更加普及和可及
- 终身学习将变得更加高效和便捷
6. 总结要点
-
Actor-Critic算法是一种融合了策略梯度和价值函数优势的强化学习框架,通过两个协作组件(Actor和Critic)实现高效学习。
-
Actor负责学习和执行策略,根据环境状态选择动作;Critic负责评估Actor的动作,通过价值函数提供反馈信号。
-
数学基础:Actor-Critic基于策略梯度定理,使用Critic估计的价值函数或优势函数来减少策略梯度的方差,提高学习稳定性。
-
深度Actor-Critic使用神经网络表示策略和价值函数,能够处理高维状态空间和复杂的非线性关系,是实现复杂智能行为的关键。
-
算法变体:A2C、A3C、DDPG和PPO等变体通过改进探索策略、并行计算、经验回放等技术,显著提升了基本Actor-Critic的性能和稳定性。
-
应用领域:Actor-Critic算法已在游戏AI、机器人控制、自动驾驶、金融交易、能源管理和医疗健康等多个领域取得了突破性进展。
-
挑战与未来方向:样本效率、稳定性、多智能体协作以及与其他AI技术

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献97条内容
已为社区贡献97条内容

所有评论(0)