【强化学习】确定性策略梯度算法DPG与DDPG
本文介绍了确定性策略梯度方法(DPG/DDPG)及其实现。DPG通过确定性策略直接输出连续动作值,与随机策略不同。DDPG在DPG基础上结合深度网络,采用软更新机制更新目标网络。文章详细说明了网络结构(Actor-Critic)、更新公式、off-policy特性以及行为策略的探索方法,并提供了完整的DDPG代码实现和在OpenAI Gym环境中的测试示例。该方法通过添加噪声进行探索,适用于连续动
一、确定性策略梯度方法(Deterministic Policy Gradient (DPG))
1、概述
在策略梯度和Actor-Critic方法中,策略通常都是随机的
通过输出一个概率分布,然后按照概率采样动作。这就导致了在一个状态下只能输出有限个动作。
而在DPG中,策略是确定的
表示s到a的映射,可以通过s直接输出一个动作值。所以不再输出分布,而是直接输出连续动作值。
2、网络设置
Actor 网络(策略网络)
-
输入:状态 s
-
输出:确定动作
Critic 网络(动作价值函数网络)
-
输入:状态 s和动作a
-
输出:动作值
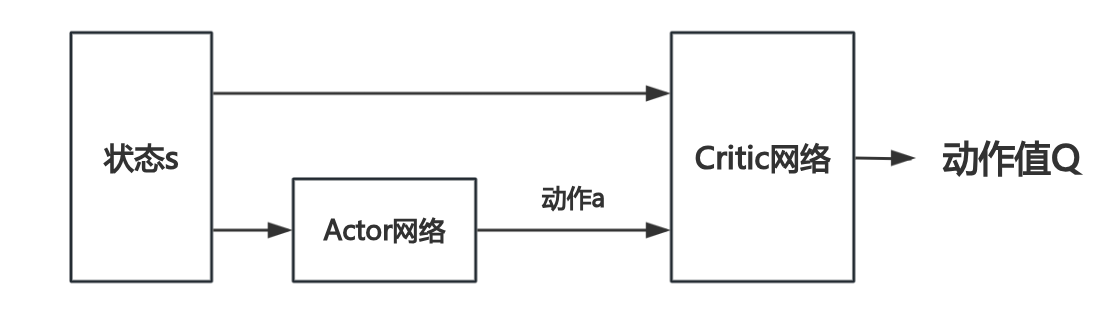
和A2C的区别在于
| 算法 | Actor 网络输出 | Critic 网络输出 | Critic 输入 | ||
|---|---|---|---|---|---|
| A2C | 动作分布 |
状态价值 |
状态 |
||
| DPG / DDPG | 确定动作 |
动作值 |
状态 + 动作 |
3、更新公式
Critic 更新 (动作价值函数网络/Q网络)
类似与DQN的更新过程,也是使用TD方法进行更新:
TD target:
critic网络的损失函数:
Actor 更新 (确定性策略网络)
Actor 目标是最大化 Critic 的 Q 值:
梯度更新公式如下:
其中是状态分布。
4、为什么DPG是off-policy的
可以看到,在随机梯度策略(REINFORCE / A2C / PPO)下,因为策略是随机的,所以梯度的期望受到动作概率分布的影响。
要想让其是off-policy的,就必须引入重要性采样来修正分布差异。
而因为DPG是确定性策略梯度,所以策略梯度公式为:
可以看到,与A2C等on-policy的公式不同的地方在于,DPG的策略梯度公式的期望只依赖于状态分布,与动作的概率
分布无关。
5、行为策略的选择
因为DPG的策略是确定性策略,如果直接用确定性动作,智能体会一直重复同样的动作,从而无法探索新的状态。
常用的方法是在行为策略上选择一些探索性策略来打破局部最优,可以选择通过给添加一个噪声。
相较于“ε-greedy”策略,这种方法更适合连续动作空间。
一、DDPG(Deep Deterministic Policy Gradient)
1、概述
在工程上更多的选择使用 DDPG(Deep Deterministic Policy Gradient),其将 DPG的理论基础扩展到深度网络环境。
其Critic网络的更新过程与DQN有点类似,其中有一点不同的是DQN在更新目标网络的时候采用的是硬更新(直接复制主网络的参数),而DDPG采取的是软更新。
软更新实际上就是一个加权平均的过程。
其中:
-
:主网络的参数
-
:目标网络的参数
-
:软更新系数,如果τ=1则为硬更新。
2、代码
DDPG类
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
from collections import deque
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, max_action):
super(Actor, self).__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU()
)
self.out = nn.Linear(128, action_dim)
self.max_action = max_action
def forward(self, state):
a = self.out(self.fc(state))
return torch.tanh(a) * self.max_action
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim + action_dim, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 1)
)
def forward(self, state, action):
x = torch.cat([state, action], dim=1)
return self.fc(x)
class ReplayBuffer:
def __init__(self, capacity=100000):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
batch = random.sample(self.buffer, batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
return np.array(states), np.array(actions), np.array(rewards), np.array(next_states), np.array(dones)
def __len__(self):
return len(self.buffer)
class DDPG:
def __init__(self, state_dim, action_dim, max_action, gamma=0.99, lr=1e-3, tau=0.005, buffer_size=100000):
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.gamma = gamma
self.tau = tau
self.max_action = max_action
# Actor & Critic 网络
self.actor = Actor(state_dim, action_dim, max_action).to(self.device)
self.actor_target = Actor(state_dim, action_dim, max_action).to(self.device)
self.actor_target.load_state_dict(self.actor.state_dict())
self.critic = Critic(state_dim, action_dim).to(self.device)
self.critic_target = Critic(state_dim, action_dim).to(self.device)
self.critic_target.load_state_dict(self.critic.state_dict())
# 优化器
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=lr)
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=lr)
# Replay Buffer
self.replay_buffer = ReplayBuffer(capacity=buffer_size)
# (选择动作 + 探索噪声)
def choose_action(self, state, noise_scale=0.1):
state = torch.FloatTensor(state).unsqueeze(0).to(self.device)
action = self.actor(state).cpu().data.numpy().flatten()
action += noise_scale * np.random.randn(len(action))
return np.clip(action, -self.max_action, self.max_action)
def store_transition(self, state, action, reward, next_state, done):
self.replay_buffer.push(state, action, reward, next_state, done)
# 软更新 target 网络
def soft_update(self, net, net_target):
for param, target_param in zip(net.parameters(), net_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
# 更新 Actor 和 Critic
def update(self, batch_size=64):
if len(self.replay_buffer) < batch_size:
return
states, actions, rewards, next_states, dones = self.replay_buffer.sample(batch_size)
states = torch.FloatTensor(states).to(self.device)
actions = torch.FloatTensor(actions).to(self.device)
rewards = torch.FloatTensor(rewards).unsqueeze(1).to(self.device)
next_states = torch.FloatTensor(next_states).to(self.device)
dones = torch.FloatTensor(dones).unsqueeze(1).to(self.device)
# Critic 更新
with torch.no_grad():
next_actions = self.actor_target(next_states)
target_Q = self.critic_target(next_states, next_actions)
y = rewards + self.gamma * (1 - dones) * target_Q
current_Q = self.critic(states, actions)
critic_loss = nn.MSELoss()(current_Q, y)
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
#Actor 更新
actor_loss = -self.critic(states, self.actor(states)).mean()
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
#更新 Target 网络
self.soft_update(self.actor, self.actor_target)
self.soft_update(self.critic, self.critic_target)
Openai Gym测试
import gymnasium as gym
env = gym.make("Pendulum-v1")
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = env.action_space.high[0]
agent = DDPG(state_dim, action_dim, max_action)
num_episodes = 1000
batch_size = 64
for episode in range(num_episodes):
state = env.reset()[0]
done = False
total_reward = 0
while not done:
action = agent.choose_action(state)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
agent.store_transition(state, action, reward, next_state, done)
agent.update(batch_size)
state = next_state
total_reward += reward
if (episode + 1) % 100 == 0:
print(f"Episode {episode+1}/{num_episodes}, Total Reward: {total_reward:.2f}")
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)