当 Agent 接入 DeepSeek-V3.1会发生什么?
本文解读 DeepSeek-V3.1,核心聚焦其混合推理架构及编程、搜索智能体的性能突破(如 SWE-bench、Browsecomp 等测试得分显著提升)。还分享其接入 AiPy 的两案例:生成俄罗斯方块(无需核心代码)、分析医院就诊数据,展现大模型 + Agent 的落地价值,探讨 Agent 时代初期实践。
往期作品中,我对 DeepSeek-V3.1的技术升级做了一个初步介绍《低开高走的典例:DeepSeek V3.1于8月19日晚更新:128K 上下文击败 Claude 4 Opus》
这次我们换个视角接着分析,8月21日,DeepSeek 公众号发布了 DeepSeek-V3.1 的更新,标题里 “迈向 Agent 时代的第一步” 让我很感兴趣 —— 毕竟之前用过大模型做开发,总觉得 “智能” 和 “落地” 之间还差一层衔接。
我试着把 V3.1 接入 AiPy 的 Agent 框架,跑了两个实际案例,算是摸透了这版模型在 Agent 场景下的真实价值,今天就从技术解读到案例体验,跟大家好好聊聊。

一、先看懂 DeepSeek-V3.1:Agent 时代需要的 “硬能力”
其实大模型做 Agent,核心就两个痛点:要么处理复杂问题时 “绕远路”(输出冗余、效率低),要么简单任务反应慢,V3.1 这次的核心突破,正好冲着这两个问题来的 ——混合推理架构。
简单说,这个架构让一个模型能同时跑两种模式:
一种是 “非思考模式”(DeepSeek-Chat),处理日常问答、基础工具调用这种简单活,比如查天气、生成基础代码,快且直接;
另一种是 “思考模式”(DeepSeek-Reasoner),专门啃硬骨头 —— 像多步数学推理、128K 超长文本解析(比如完整读透《三体》这种百万字内容,还能找出里面的语义矛盾)。
最直观的是评测数据:在 AIME 2025、GPQA 这些复杂任务里,V3.1 的准确率和前代 R1-0528 差不多,但输出的 token 量少了 20%-50%,相当于 “说话更精炼,还不丢重点”。
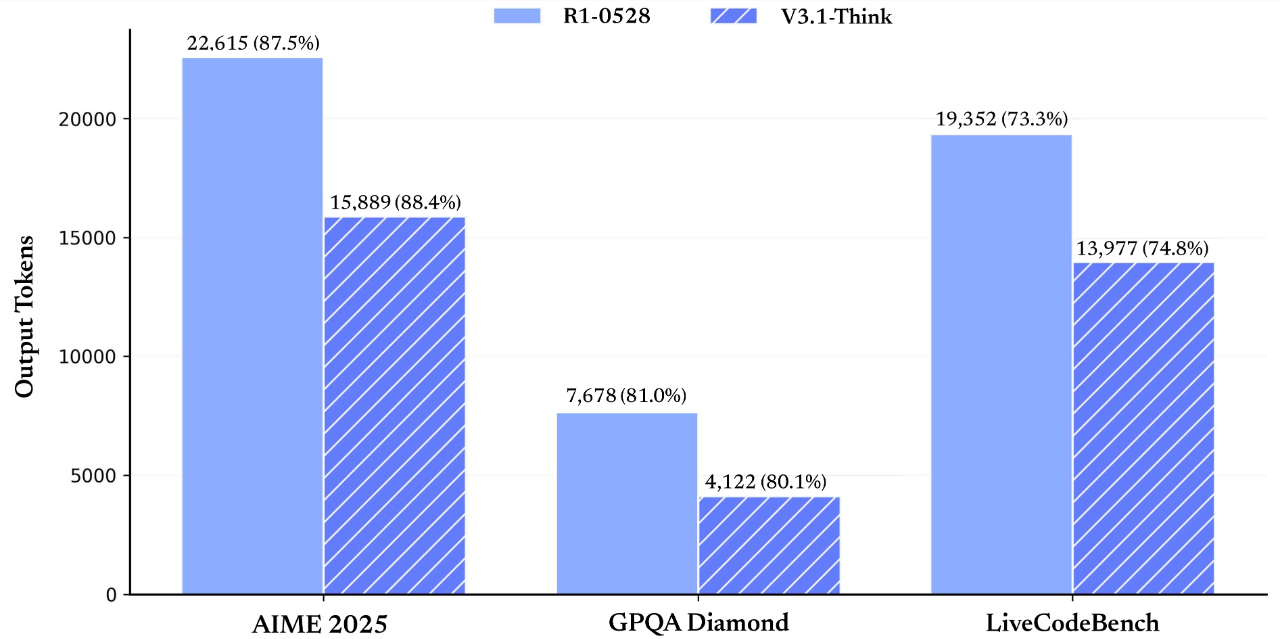
对 Agent 来说,光会 “想” 还不够,得会 “动手”——V3.1 的工具调用能力也升级了。通过 Function Calling 接口,它能自己调用外部 API(比如查实时天气的 OpenWeather)、写 Python 函数做数据清洗,甚至驱动 Swarm 这种多智能体框架搭分布式任务。这一点在编程和搜索两个核心场景里体现得最明显:
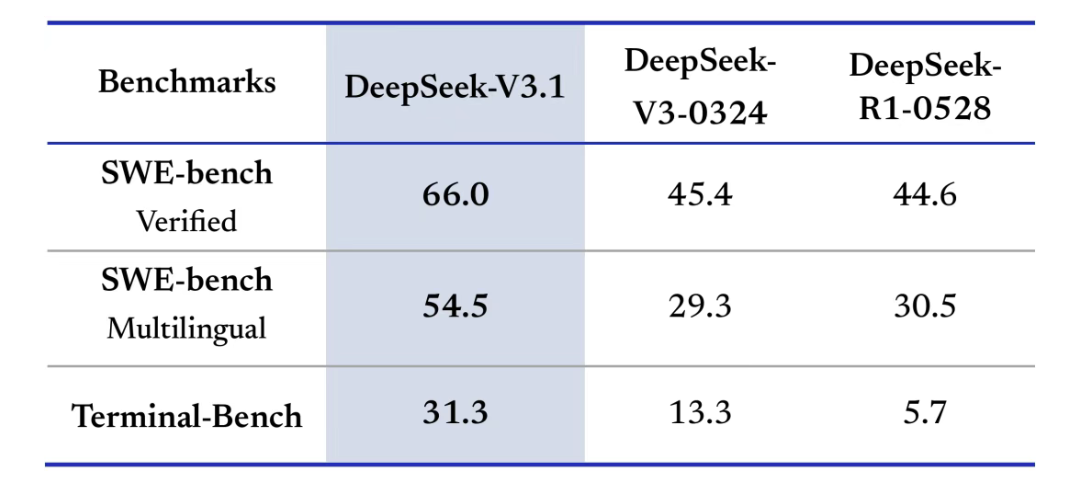
在编程智能体上,以前大模型生成代码常 “卡壳”,比如多语言混合项目调试、终端运维任务。但 V3.1 在 SWE-bench(代码修复测试)里,Verified 得分从 R1-0528 的 45.4 涨到 66.0,多语言项目修复能力更是从 29.3 翻倍到 54.5;Terminal-Bench(终端任务)得分从 13.3 冲到 31.3,意味着它能自己排查 K8s 集群故障、写 Terraform 代码部署多云环境,不用再靠人手动补代码。
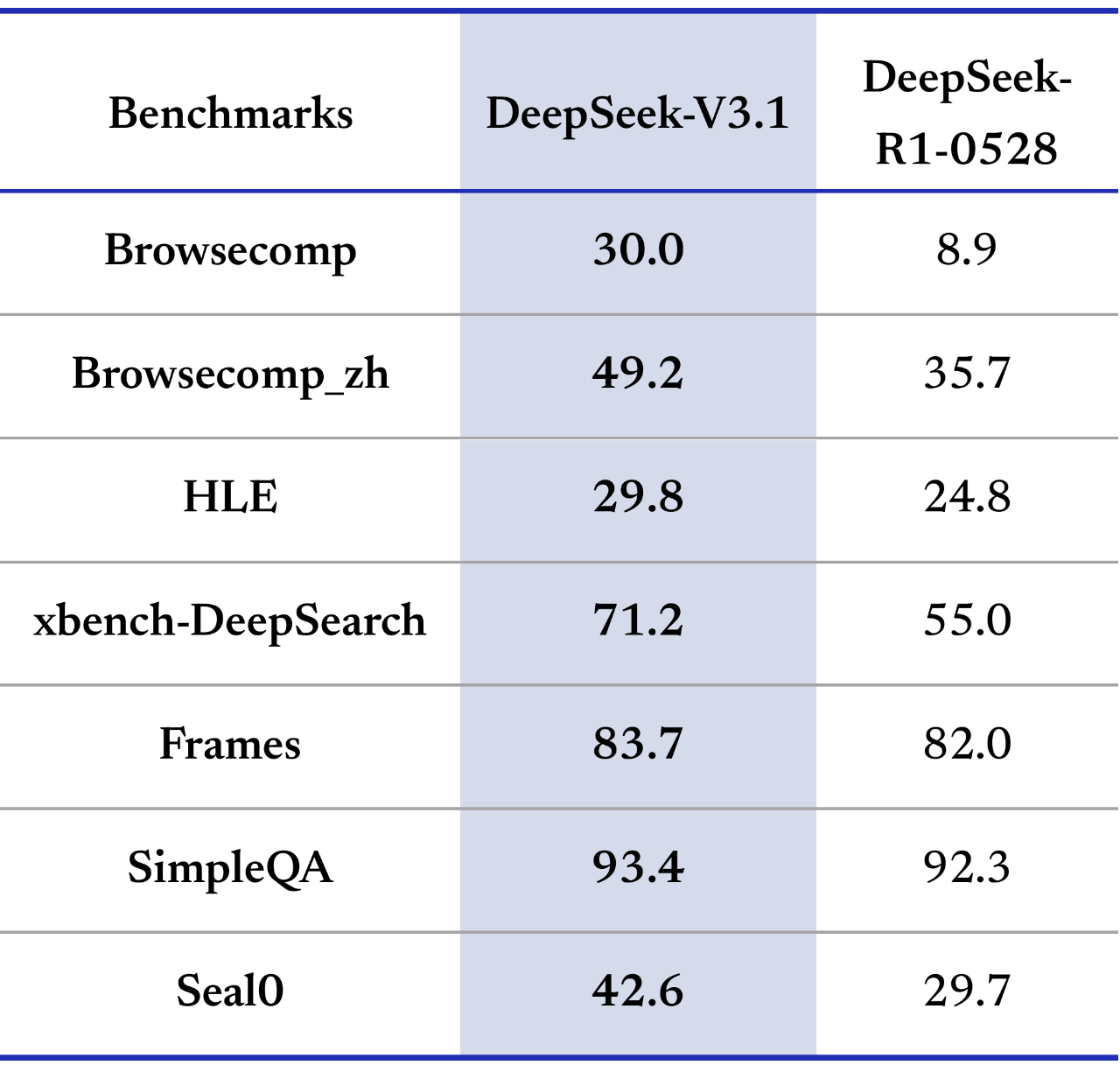
搜索智能体则跳出了 “查资料” 的局限,能做 “知识挖掘”。比如 Browsecomp_zh(中文多步推理)得分从 35.7 升到 49.2,能逐句比对《数据安全法》修正案和行业标准的冲突;xbench-DeepSearch(深度搜索)得分 71.2,比 R1-0528 的 55 高了不少,像查 AI 制药靶点时,能穿透 4 层文献引用关系,找到跨领域的研究方法 —— 这已经不是 “找信息”,而是 “挖价值” 了。
接下来,通过实操给大家展示一下,我把DeepSeek-V3.1接入到AiPy后,会发生什么?
让我们一起验证一下此次更新是否达到了官方口中的升级与突破。
二、案例一:用 Agent 搭俄罗斯方块
知道 V3.1 的编程能力后,第一个想法就是试个实际开发场景 —— 做个俄罗斯方块游戏。
以前自己写这种小游戏,光碰撞检测就得查 1 小时 API 文档:方块下落碰地面、平移撞墙、旋转卡堆叠,哪一步没调好都得 debug 半天。
这次我只给 AiPy+V3.1 提了个需求:“做个俄罗斯方块,要碰撞检测、用键盘方向键来控制,能显示分数和等级”,剩下的全交给 Agent。
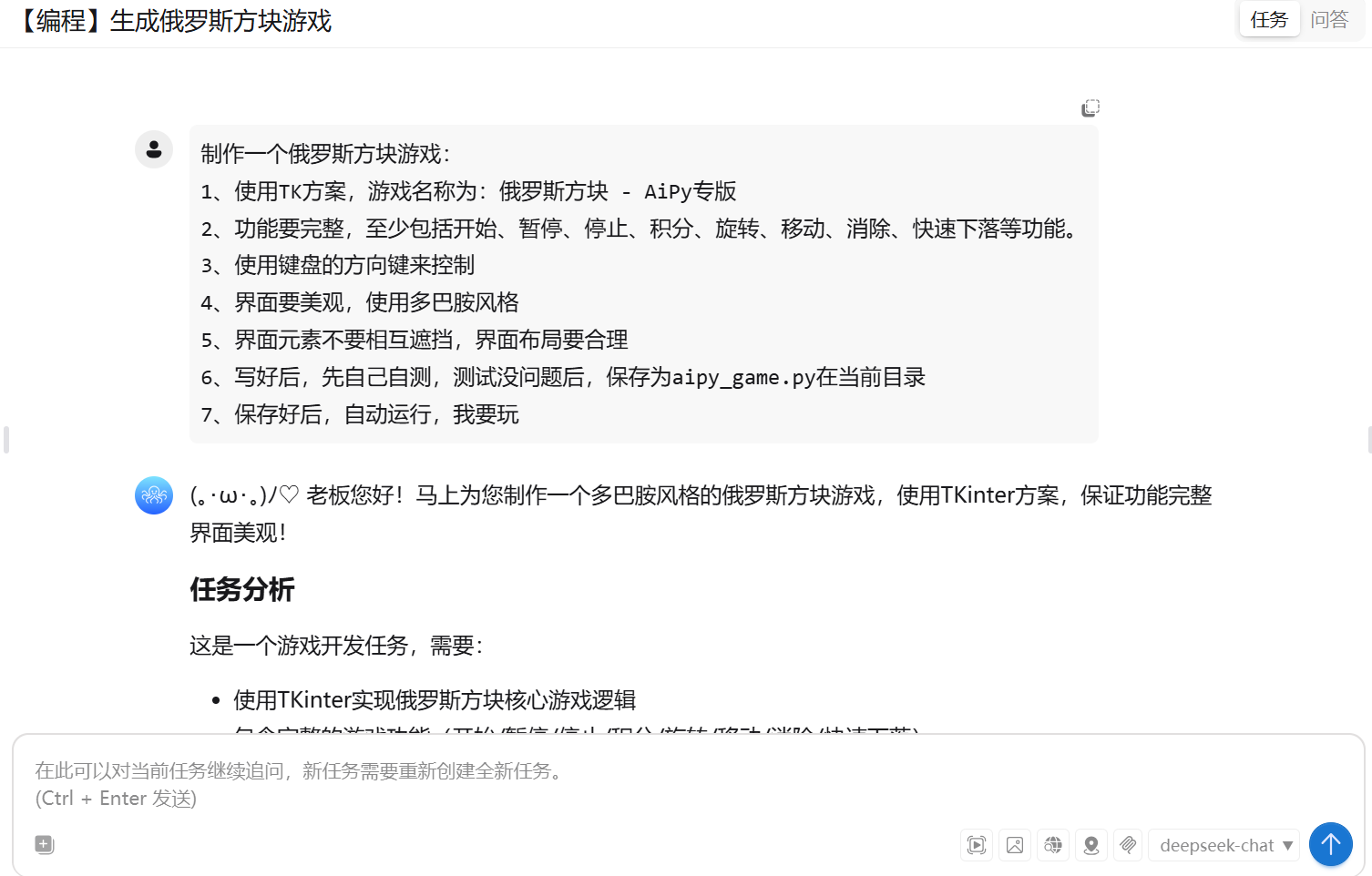
实际体验比预想的顺:V3.1 先把需求拆成了游戏循环、图形渲染、物理判定三个模块,然后自动调用 Pygame 库生成代码。最惊喜的是细节处理 —— 比如方块旋转时,它没让我手动调偏移量,而是自己加了 “自动微调” 逻辑,避免旋转时卡到已堆叠的方块;按方向键平移时,响应延迟几乎没有,不像以前用普通脚本写的 “按了半秒才动”。
中途还遇到个小问题:方块旋转功能缺失。没等我提优化需求,Agent 就自己定位到 “游戏旋转功能有误”,自己主动重新检查旋转逻辑并修复问题。从输入需求到能上手玩,总共也就6-7分钟,要是纯手工开发,光搭框架就得1小时,更别说调这些细节了。

这是我最后的游戏过程,大家可以看一下,整体体验还是很不错的。
俄罗斯方块视频
三、案例二:拆医院就诊数据 “硬骨头”,AI 比人工更懂 “落地”
如果说游戏开发是 “小试牛刀”,那医院就诊记录分析就是真的 “啃硬骨头”。医院数据向来乱:830 条就诊记录里,混着患者信息、科室分布、费用构成,以前用普通脚本跑,要么输出的表格没逻辑,要么图表中文乱码,根本没法直接用。这次用 V3.1+Agent,相当于给数据加了个 “智能拆解器”。
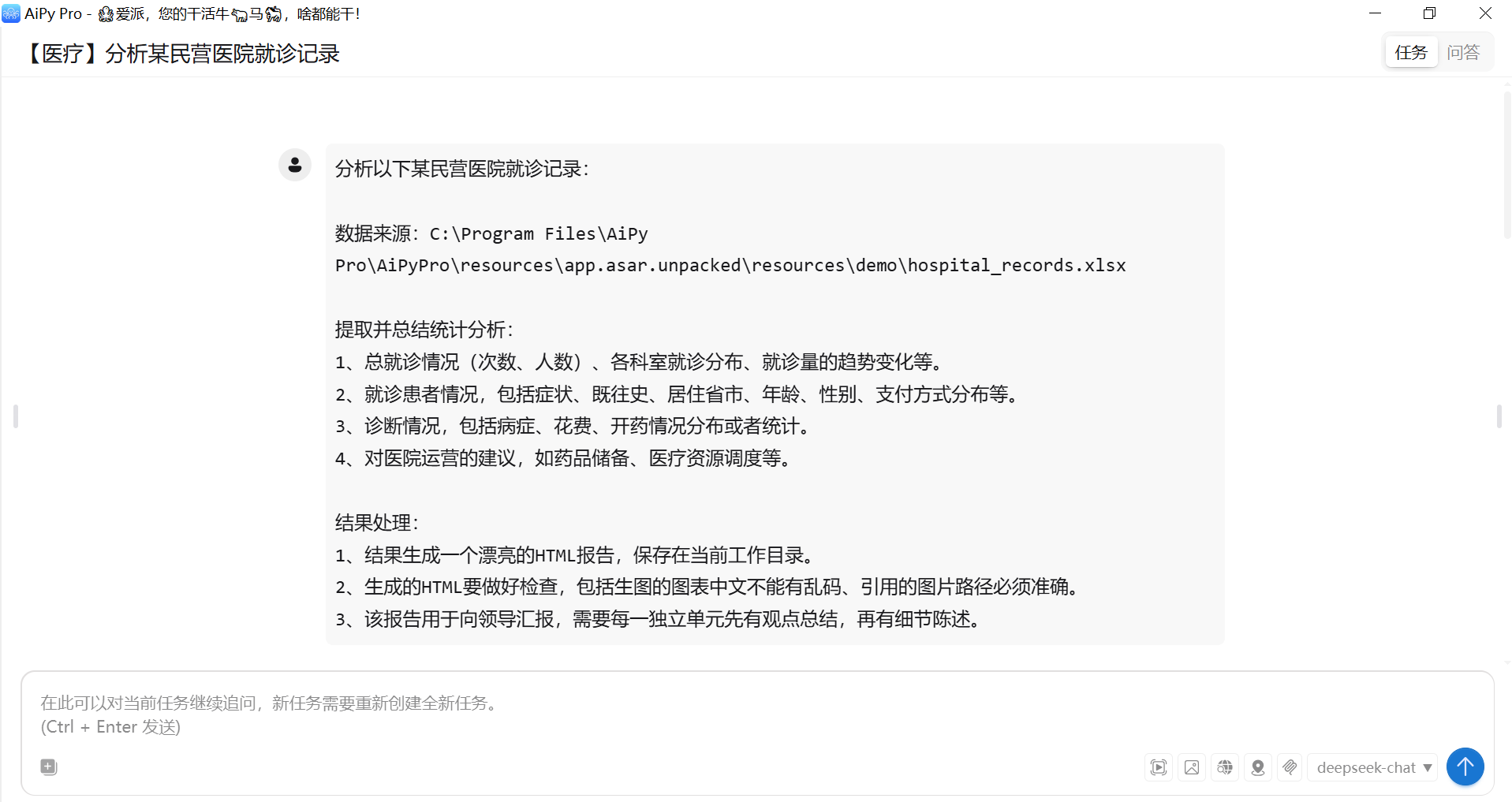
先看它怎么处理数据:没有一上来就堆报表,而是先把信息拆成 “总就诊情况”“患者特征”“诊断细节” 三块,每块都配了清晰的表格和图表。比如总就诊情况里,心内科占了 87.47% 的就诊量(726 次),高血压是主要诊断结果 —— 这一下就抓住了医院的核心业务。
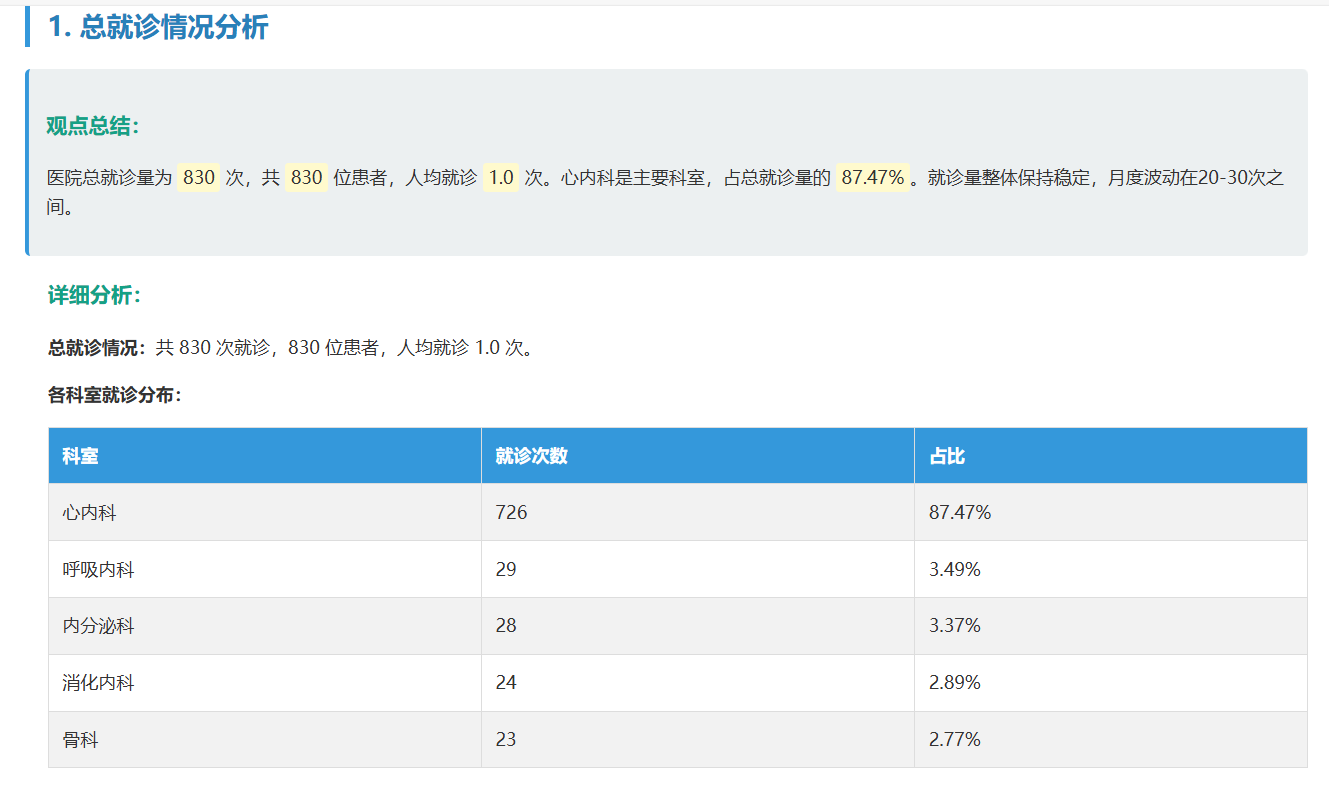
更有用的是 “能落地的结论”。比如支付方式里,商业保险占 34.46%,比医保和自费略高,这暗示患者可能更看重民营医院的报销灵活性,能给医院运营提方向;
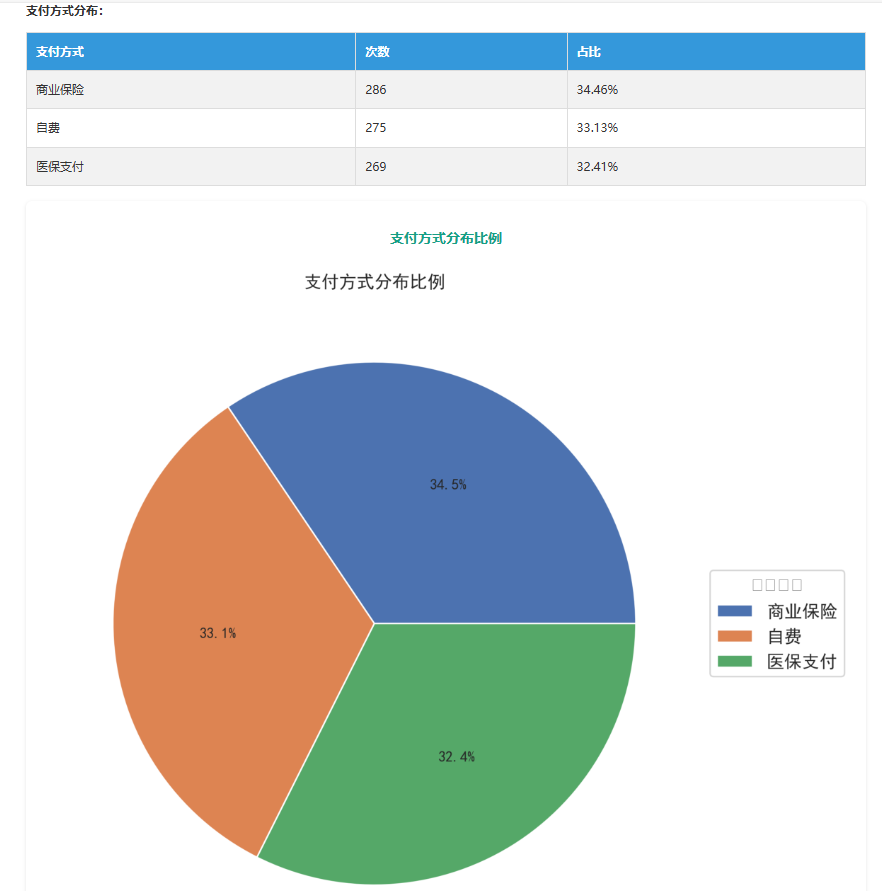
费用构成里,治疗费用占 56.16%(平均 1105.42 元),检查费 28.15%。
Agent 直接建议 “优化治疗方案、统一耗材采购”,甚至点名要重点储备氨氯地平片、贝那普利片这些高频降压药 —— 这不是空泛的 “建议”,而是能直接给医院采购部、运营部用的方案。

当然也有不足,比如症状分布里 “其他” 占了 42%,如果这部分数据能再细化,或许能挖出更多患者需求。但总体来说,以前人工分析这些数据至少要 1 天,现在 Agent两小时就出了完整报告,还附带可落地的建议,效率提升不是一点半点。
这个报告的一个总览:
民营医院就诊记录分析报告
四、Agent 接入 V3.1,到底改变了什么?
聊完技术和案例,其实最直观的感受是:V3.1 没搞花架子,而是解决了 Agent 落地的 “真问题”—— 以前大模型像 “只会背书的学生”,现在更像 “能动手干活的协作者”。
对开发者来说,不用再纠结 “怎么让 AI 懂需求”,扔个想法就能出成品;对行业来说,像医院这种需要深度数据处理的场景,AI 能从 “帮着查资料” 升级到 “给解决方案”。
当然,这只是 “迈向 Agent 时代的第一步”,比如多模态交互、更复杂的跨领域协作还能再优化,但至少现在能看到:当大模型的 “思考能力” 和 Agent 的 “执行能力” 结合,落地的门槛真的变低了。
以后再想做个小 demo、拆份复杂数据,或许不用再 “先学半年代码”,而是直接跟 AI 说 “我要做什么”—— 这种 “想法即落地” 的体验,可能就是 Agent 时代最实在的开始。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)