DataFlow:提升 AI 大模型竞争力的开源利器
当数据准备成为竞争主战场,开源开放的技术生态正成为破局关键。即通过透明可验的工程实践,推动形成学界及工业界的数据治理协作生态。以数据为中心的 AI 系统 DataFlow 正是这一理念的实践者:通过开源模块化架构,将大型科技公司“黑盒化”的数据工程能力,转化为可复用、可扩展的公共基础设施。
AI 模型的竞争在这两年已经愈演愈烈,很多人认为其核心竞争力在于算法架构。其实不然,当前开源生态已使主流架构趋于透明——Llama、GPT、Gemma等模型结构均可公开复现,算法层面的护城河正在迅速消解。真正的竞争壁垒实则存在于更底层的维度——数据。数据是 AI 大模型知识的唯一源泉,而数据质量则决定了模型的“情商”与“智商”。
近年来,大模型的发展在很大程度上依赖于大规模、高质量的训练数据。然而,目前主流的训练数据及其处理流程多未公开,公开数据资源的规模和质量仍有限,给社区在构建和优化大模型训练数据的过程中带来不小挑战。
另外,虽然现在已有了大量的开源数据集,学术界在大模型数据准备方面仍面临诸多难题。大模型训练数据的清洗与构建仍主要依赖各个研究团队 “闭门造车”,缺乏系统化、高效的工具支持。现有的数据处理工具如 Hadoop() 和 Spark 等,支持的操作算子大多偏向传统方法,尚未有效集成基于最新大语言模型(LLMs)的智能算子,对于构建先进大模型的训练数据支持有限。 这样的困境该如何解决?
开源 DataFlow:面向大模型的数据工程引擎
当数据准备成为竞争主战场,开源开放的技术生态正成为破局关键。即通过透明可验的工程实践,推动形成学界及工业界的数据治理协作生态。以数据为中心的 AI 系统 DataFlow 正是这一理念的实践者:通过开源模块化架构,将大型科技公司“黑盒化”的数据工程能力,转化为可复用、可扩展的公共基础设施。
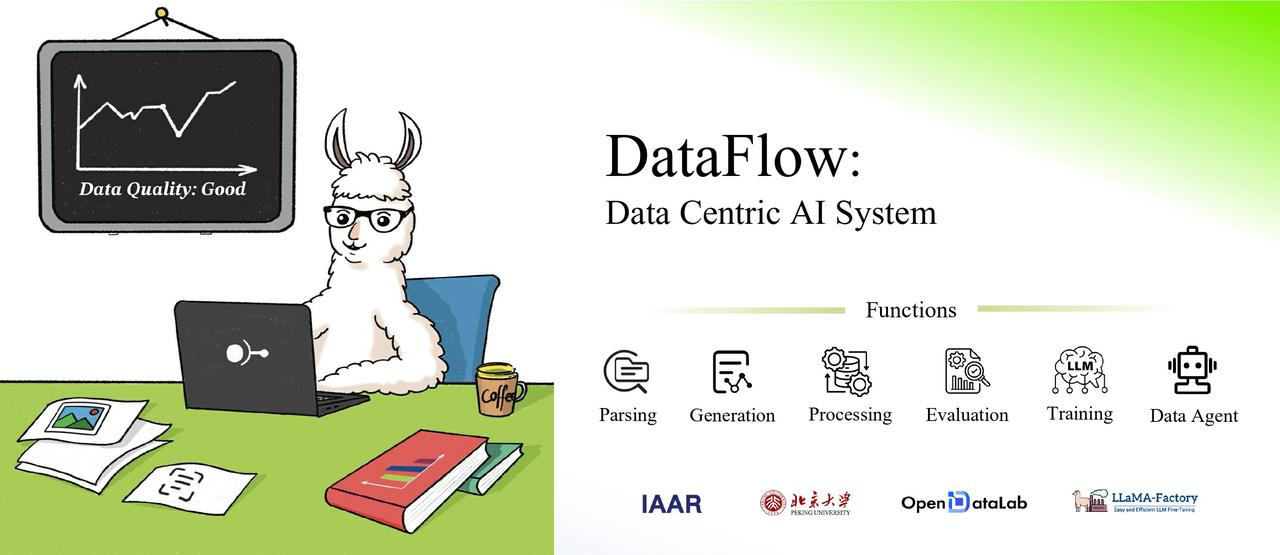
目前 DataFlow 全面支持文本模态的数据治理,同时也支持从PDF、网页、音频中提取并转译为文本内容。经过治理的数据可供大语言模型(LLM)的预训练(Pre-training)、有监督微调(Supervised Finetuning)、强化学习微调(Reinforcement Finetuning )使用。经过治理的数据可以有效提升大语言模型在通用领域的推理能力和检索能力,与医疗、金融、法律等特定领域的性能。此外,多模态版本的 DataFlow 正在如火如荼开发中,会在不久的将来与大家见面。
DataFlow 数据治理技术框架
当数据治理的复杂性成为模型进化的最大瓶颈,传统‘碎片化工具+人工编排’的模式一定不是最优解法。DataFlow 的技术框架设计遵循 “输入→处理→输出” 的流式架构,覆盖从原始数据治理到场景落地的全链路,核心分为三大层级:
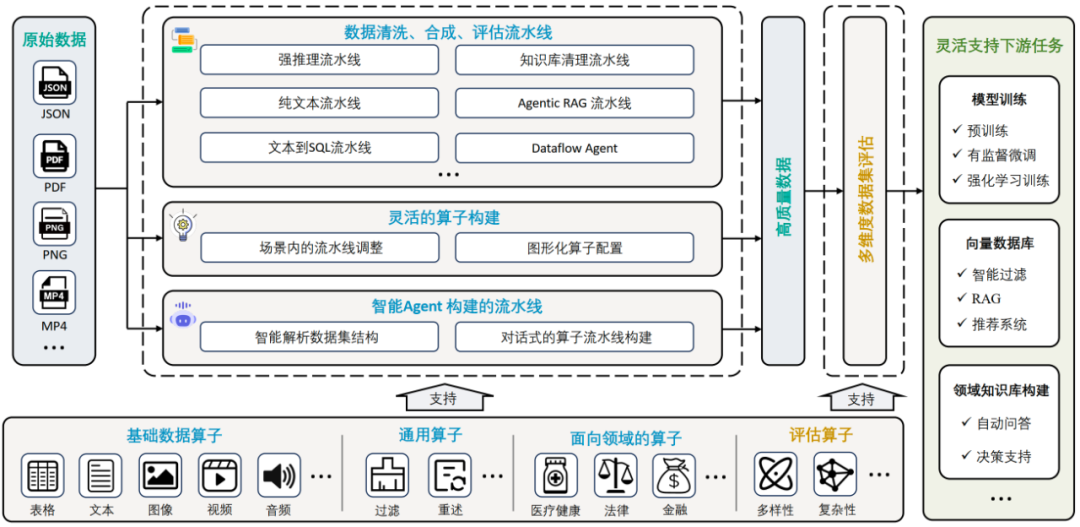
数据输入层:JSON、PDF、图片、视频等多模态数据支持
-
关键设计:
-
统一数据载体:
pandas DataFrame结构化承载多模态数据 -
扩展性:预留多模态处理接口(当前版本聚焦文本,图像/视频支持开发中)
-
核心处理层:算子-流水线-Agent 三级引擎
-
DataFlow 算子体系:
基本数据处理单元,通常基于规则、深度学习模型或大语言模型(LLM)实现处理逻辑。算子类型 功能说明 案例场景 多模态算子 跨模态数据转换 PNG→OCR识别,MP4→语音识别,图片→文本描述 通用算子 普适性数据处理 过滤/去重/多样性控制 领域算子 垂直场景专用逻辑 医疗实体识别、金融合规检测 评估算子 多维度数据质量验证 安全性/复杂性/推理难度评分 -
DataFlow Pipeline:
对多个 DataFlow 算子的有序编排,旨在完成一个完整的数据处理任务。DataFlow 目前提供了 8 条完整流水线以供参考,用户可以自定义修改。- 预制流水线(开箱即用):
-
......
-
知识库清洗流水线:从 PDF,网页,音频中提取信息,构造 RAG 知识片段或问答对。
-
Text2SQL:自然语言到 SQL 的精准映射(见下图流程)
-
Agentic RAG 优化:构建检索增强生成的高质量知识库
-
强推理合成:生成数学/代码类思维链数据
-
-
自定义流水线:
-
图形化拖拽:连接算子构建 DAG(无需代码)
-
YAML 配置:支持版本化管理与复用
-
- 预制流水线(开箱即用):
-
DataFlow Agent:
基于多智能体协同的自动化任务处理系统,覆盖 “任务拆解 → 工具注册 → 调度执行 → 结果验证 → 报告生成” 完整流程,致力于复杂任务的智能化管理与执行。现在使用大模型 Agent 可实现多种智能数据治理功能:-
根据用户描述自动编排算子构成新 Pipeline
-
根据用户描述自动编写新算子
-
Agent 自动解决数据分析任务。
-
输出层:高质量数据与应用场景
-
多维度评估报告:可视化展示清洗/合成数据的质量提升
-
下游场景支持(部分举例)
-
模型训练:提供预训练/SFT/RLHF 全阶段优质数据
-
向量数据库:输出适配 RAG 的<问题,证据片段,答案>三元组
-
领域知识库:医疗/金融专用知识问答及决策支持
-
......
-
DataFlow 快速入门指南
基于代码使用
代码仓库
-
目前 DataFlow 已经部署在 PyPi,可以通过 pip install open-dataFlow 轻松一键安装。
-
DataFlow 借鉴了 PyTorch 的风格的算子组织与调用方式,算子声明通过__init__函数实现,算子运行通过 run 函数实现。接口简明清晰,易于上手。
-
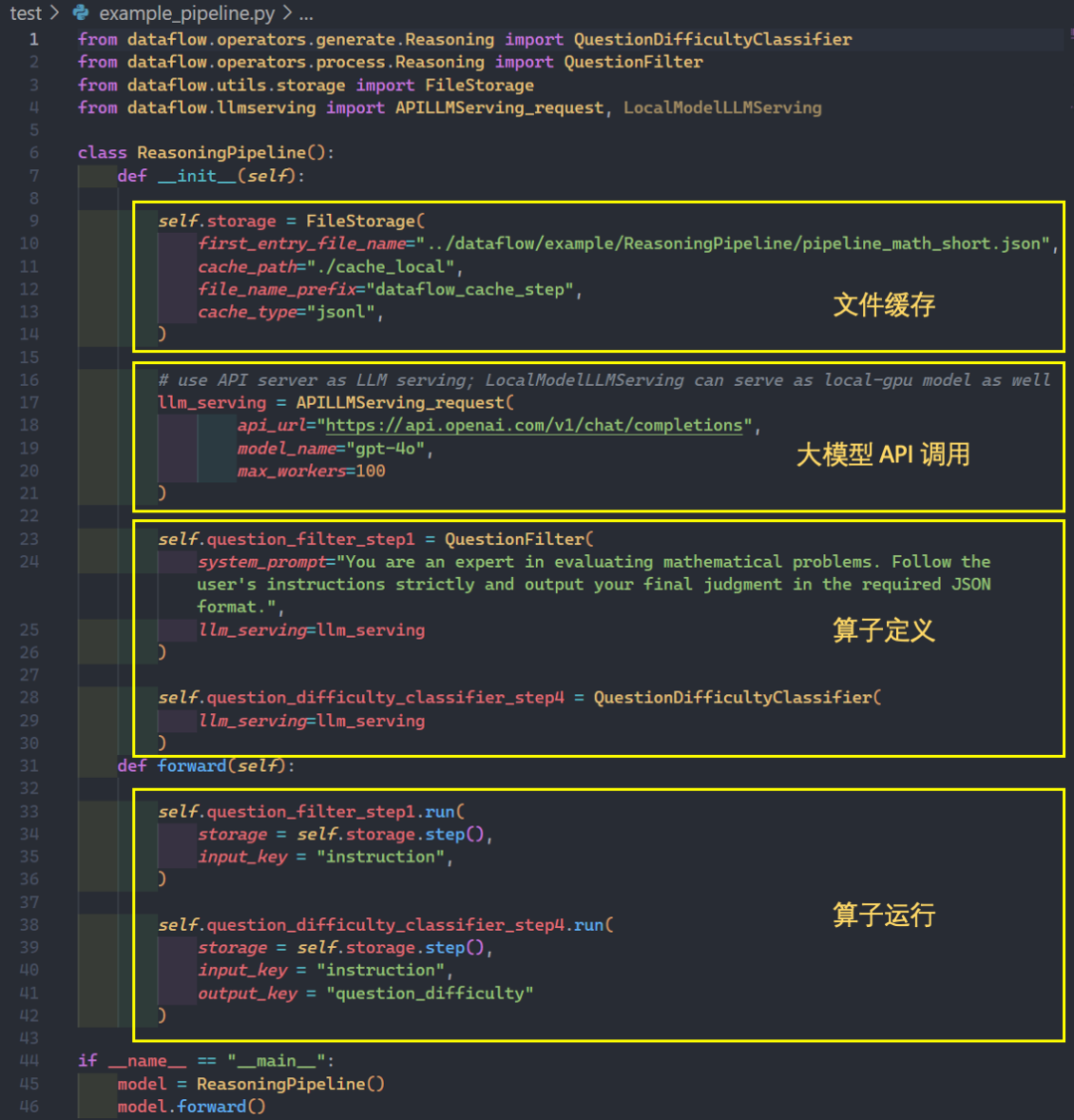
使用文档
我们还提供了详细的教程文档,也欢迎开源社区提出有趣的见解,一起丰富完善文档内容,让 DataFlow 更加新手友好,利于上手。
基于前端使用
-
无代码拖拽式 Pipeline 搭建:满足需要针对业务场景个性化定制/微调 pipeline 的需求。
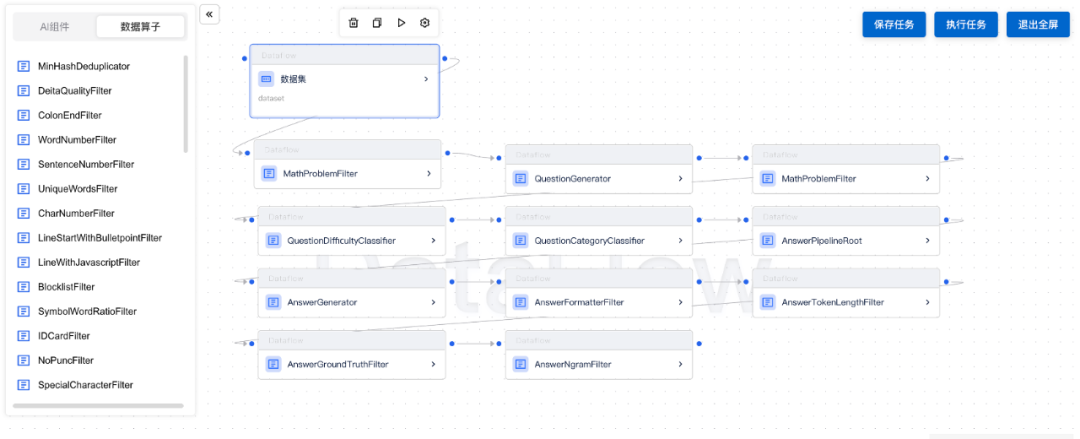
-
一键调用数据准备 Pipeline:提供已跑通的行业/特定场景的最佳实践模版。
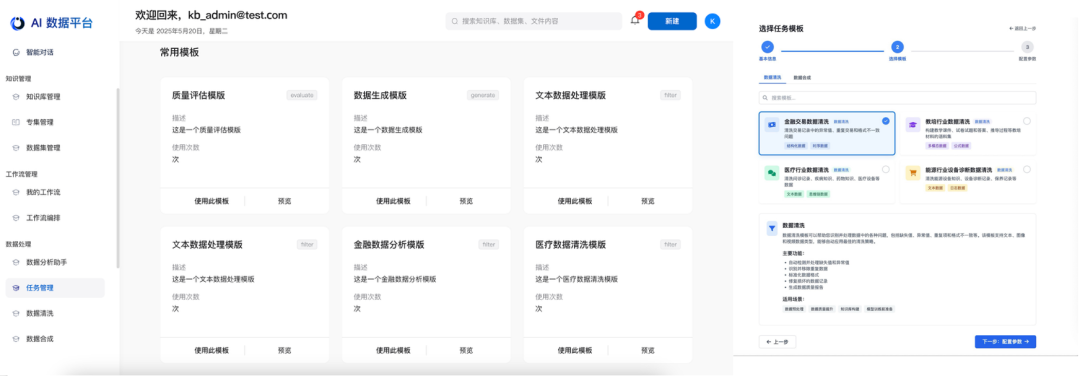
-
Agent 自动化 Pipeline 设计:通过多轮对话理解并分析客户需求,给出合理的数据过滤、数据合成、pipeline 调整等建议,确认后可一键配置。
结语:数据工程的新范式
DataFlow 的价值不在于替代工程师,而是将数据治理的‘认知负荷’转移给 AI 系统。当大模型竞争进入下半场,可复现的数据流水线正成为新时代的 LLMOps 基础设施。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)