架构实践:用YOLOv11、PaddleOCR与ArcFace构建高并发AI视频违规检测分析系统
在当今的智能化浪潮中,实时视频分析的需求日益增长。本文将详细阐述一个我独立设计并实现的高性能AI视频分析系统的架构。该系统能够从实时RTMP流中,通过多线程并行处理的方式,同时运行YOLOv11(目标检测)、PaddleOCR(文字识别)和ArcFace(人脸识别)三个独立的AI模型,并将检测结果通过WebSocket实时推送,同时利用异步队列将日志信息批量持久化到数据库,有效解决了多模型推理的性
摘要: 在当今的智能化浪潮中,实时视频分析的需求日益增长。本文将详细阐述一个我独立设计并实现的高性能AI视频分析系统的架构。该系统能够从实时RTMP流中,通过多线程并行处理的方式,同时运行YOLOv11(目标检测)、PaddleOCR(文字识别)和ArcFace(人脸识别)三个独立的AI模型,并将检测结果通过WebSocket实时推送,同时利用异步队列将日志信息批量持久化到数据库,有效解决了多模型推理的性能瓶颈和高并发写入的I/O阻塞问题。
一、 项目背景与挑战
项目的核心目标是打造一个能够7x24小时稳定运行的“AI视觉哨兵”,它需要具备同时识别多种违规场景的能力:
-
特定行为识别: 如检测画面中是否有违禁画面或内容。
-
敏感文字识别: 捕捉屏幕或文档上出现的违禁词汇。
-
特定人物识别: 判断是否有名单中的关键人物出现在画面中。
要将这三个独立的、计算密集型的AI任务整合到一个实时的视频流处理流程中,我们面临两个核心的技术挑战:
-
性能瓶颈: 三个AI模型如果串行处理,帧率将无法接受。如果为每个模型都单独解码视频流,又会造成巨大的资源浪费。如何让它们在不互相干扰的情况下,高效地并行工作?
-
I/O阻塞: 大量的违规事件会产生密集的日志记录需求。如果每次检测到结果都直接写入数据库,高频的I/O操作会严重阻塞核心的AI推理线程,导致系统响应延迟、帧丢失。
二、项目亮点:兼顾实时性与高精度的设计哲学
在深入架构细节之前,我想先阐明本项目的核心设计理念:在保证高识别精度的前提下,将端到端的延迟压缩到极致。这意味着从事件发生到用户收到警报,整个过程必须在毫秒间完成。
1. 极致的实时性
实时性是本系统的生命线。我们通过以下几点来保障:
-
全链路异步化:从AI推理到结果推送,再到日志记录,所有可能产生阻塞的环节都被设计为异步执行。核心的AI检测线程永远不会因为等待网络或磁盘I/O而暂停工作。
-
并行推理管线:多线程架构使得三个AI模型能真正地并行运行,系统的处理帧率不再是三个模型耗时的简单叠加,而是取决于最慢的那个模型,极大地提升了吞吐量。
-
智能“弃帧”策略:我们主动选择了一种“弃帧保畅”的策略。当某个AI模型的处理速度跟不上视频流的输入速度时,其专属的缓冲队列会填满。此时,调度器会果断丢弃新的帧,而不是让延迟无限累积。这确保了用户收到的警报永远是关于“当下”正在发生的事,而不是几秒钟前的陈旧信息。
2. 不动摇的准确性
追求速度的同时,我们并未对准确性做出任何妥协:
-
选用SOTA模型:项目直接采用了YOLOv11、PaddleOCR和InsightFace等在各自领域被广泛验证的、具备顶尖水平(State-of-the-art)的开源模型,这是保证识别准确率的基石。
-
多模态交叉验证:系统从行为、文字、身份三个完全不同的维度对视频内容进行同步审查,构成了一张交叉验证的“天网”。相比于单一模型,这种多模态检测极大地降低了单一场景下的漏报风险。
-
精准的优化手段:我们所做的性能优化(如禁用OCR角度分类)都是经过审慎评估的,旨在“剪掉”在特定场景下非必要的计算分支,而非降低核心算法的精度。这体现了对业务场景的深刻理解和对技术的精细把控。
-
高可靠的警报信息:系统推送的每一条警报都包含了时间戳、违规原因、置信度分数和包含标注框的截图URL。这种富文本的证据链,使得警报信息不再是一个模糊的信号,而是一份高可靠性、可追溯的事件报告。
三、架构设计:解耦与并发
为了实现上述目标,我设计了一套基于“生产者-消费者”模型的多线程并发架构。核心思想是“分而治之”和“异步化”,将视频流处理、AI推理、结果分发和数据持久化等环节彻底解耦。
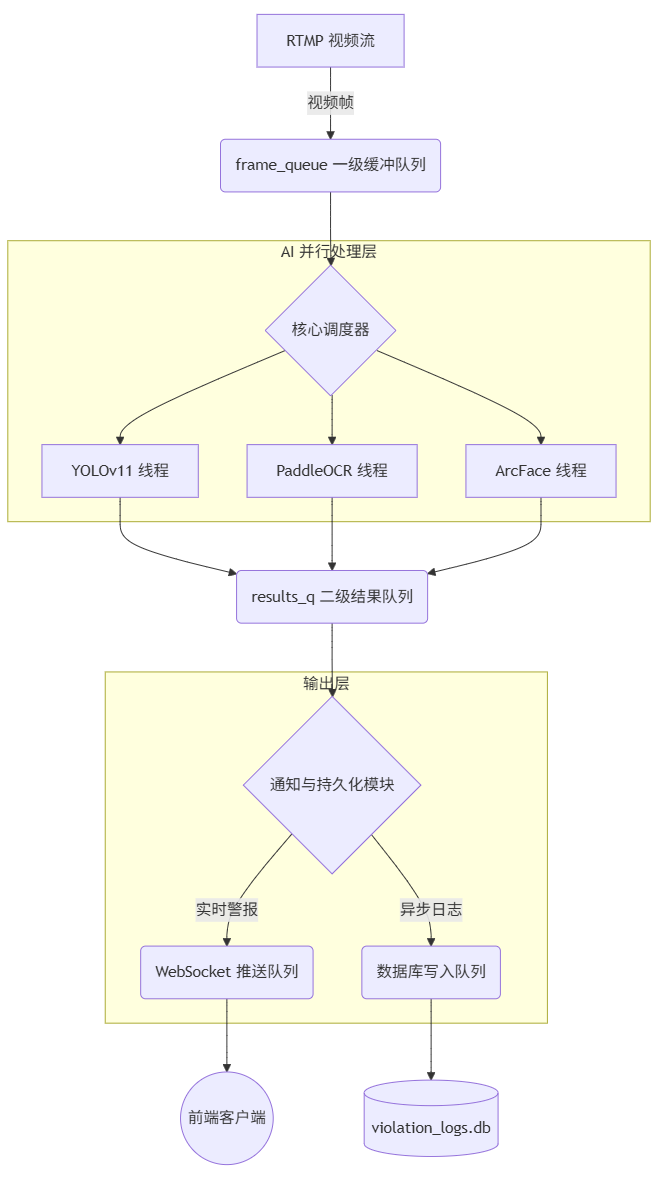
下面是系统的整体数据流架构图:
1. 视频流捕获 (生产者) 与RTMP协议的选择
系统的数据源头是一个独立的视频捕获线程 (stream_handler)。它的职责是连接到指定的视频流,持续解码,并将图像帧快速放入一个全局的一级缓冲队列 frame_queue 中。
在这里,我们特意选择了RTMP (Real-Time Messaging Protocol) 作为输入协议。RTMP是一个基于TCP的、为实时音视频传输设计的协议,它最大的优势就是极低的延迟(通常在1-3秒)。
选择RTMP的意义在于:
-
奠定“实时”的基础:一个真正的实时分析系统,其前提是数据源必须是实时的。如果视频流本身就有几十秒的延迟(如HLS协议),那么后端再快的处理速度也失去了意义。RTMP保证了我们分析的画面与真实世界发生的情况仅有微小的延迟。
-
适配流式处理:RTMP提供的是一种连续、不间断的数据流,这与我们
while True: cap.read()的流式处理模型完美契合。OpenCV等库对RTMP有良好的原生支持,使得我们可以轻松地像处理本地摄像头一样处理远程实时视频流,极大地简化了数据接入层的复杂度。
2. 核心调度与AI并行处理 (一级消费者 & 二级生产者)
这是整个架构的核心。一个核心调度线程 (detect_and_notify) 作为一级消费者,不断地从 frame_queue 中取出帧。但它自己不进行任何耗时的AI计算,而是立即将同一帧分发给三个独立的AI工作线程:
-
YOLOv11线程: 拥有自己的输入队列
yolo_q,负责目标检测。 -
PaddleOCR线程: 拥有自己的输入队列
ocr_q,负责文字识别。 -
ArcFace线程: 拥有自己的输入队列
face_q,负责 人脸识别。
这种设计带来了几个好处:
-
并行计算: 三个模型在独立的线程中运行,可以充分利用多核CPU或GPU的计算资源。
-
“弃帧保畅”: 调度器向各AI线程的队列分发帧时,采用的是非阻塞的
put_nowait()。如果某个AI线程的队列已满(意味着它处理不过来了),调度器会直接丢弃这一帧,而不是等待。这确保了即使某个模型出现短暂的性能抖动,整个系统仍然能以接近实时的状态运行,不会发生延迟的“雪崩”。
当任何一个AI线程完成计算并检测到违规时,它会将结构化的结果(包含违规类型、截图、置信度等)放入一个公共的二级结果队列 results_q 中。
3. 结果分发与实时推送 (二级消费者)
一个独立的通知器线程 (notifier_worker) 作为二级消费者,专门负责处理 results_q 中的结果。它的工作流程是:
-
从
results_q中取出一个结果。 -
将作为证据的已标注截图保存到服务器的静态文件目录。
-
构建一个包含所有信息的JSON消息。
-
将此消息同时放入两个不同的队列:
-
WebSocket推送队列: 一个
asyncio队列,由FastAPI的WebSocket端点消费,用于将警报立即发送给前端监控页面。 -
数据库写入队列: 一个标准的
queue.Queue,用于将日志信息发送给持久化模块。
-
4. 异步批量持久化 (最终消费者)
这是解决I/O瓶颈的关键。我实现了一个独立的数据库写入线程 (DatabaseWriter),它完全不知道前面发生了什么,只负责消费数据库写入队列中的消息。
为了最大化性能,它并非来一条就写一条,而是采用了“批量+超时”的策略:
-
批量: 线程会持续从队列中取消息,直到积攒了200条,然后通过
executemany()一次性写入数据库。 -
超时: 如果队列中的消息不够200条,线程不会一直傻等。在等到第一条消息后,如果超过5秒还没有新的消息进来,它也会将当前积攒的所有消息(无论多少)立即写入数据库。
这种设计,将成百上千次零散的数据库写入操作,合并为了少数几次高效的批量操作,使得数据库写入的开销被平摊到几乎可以忽略不计的程度,从而完全不会影响到主检测流程的性能。
三、 核心技术选型与实时性优化
选择合适的AI模型并对其进行深度优化,是保障系统实时性的关键。本项目中,PaddleOCR和InsightFace承担了核心的识别任务,我围绕它们进行了一系列针对性的性能优化。
1. PaddleOCR:轻量高效的中文识别引擎
基本概念:PaddleOCR是百度飞桨开源的一款超轻量级OCR(光学字符识别)工具库。它的工作模式通常分为两步:首先,一个文本检测模型(如DBNet)在图像中定位出所有文字行的边界框;然后,一个文本识别模型(如CRNN)对每个边界框内的文字进行识别。这种两阶段的设计兼顾了灵活性和准确性。
针对性优化实践:
-
模型选型:项目中采用了PaddleOCR的默认模型,特别是其轻量化的中文识别模型。这套模型在保证了极高的中文识别精度的同时,对计算资源的消耗相对较小,是部署在服务器环境下进行实时流处理的理想选择。
-
关键参数调优:在初始化OCR引擎时,我明确设置了
use_angle_cls=False。这是一个至关重要的性能优化点。角度分类模型用于判断文本的旋转角度(0°, 90°, 180°, 270°),但在我们的监控场景中,画面中的文字大多是水平的。通过禁用这个功能,我们直接跳过了一个独立的模型推理步骤,在几乎不影响准确率的前提下,极大地提升了单帧OCR的处理速度。 -
置信度过滤:在后处理阶段,我增加了一道置信度过滤门槛。只有当OCR识别结果的置信度高于预设阈值(例如0.7)时,我们才将其纳入后续的违禁词比对流程。这有效避免了将模糊、不可靠的识别结果引入业务逻辑,减少了不必要的计算和误报。
2. InsightFace (ArcFace):高精度的工业级人脸识别库
基本概念:InsightFace是当前人脸识别领域最顶尖的开源算法库之一,其核心是它提出的ArcFace损失函数。人脸识别并非简单的“图片比对”,而是将人脸图像通过一个深度卷积网络,转换成一个高维(通常是512维)的数学向量,我们称之为“特征嵌入(Embedding)”。这个向量就是人脸的“数学表示”。比较两张人脸是否为同一个人,就转变成了计算他们对应Embedding向量之间的余弦相似度。
针对性优化实践:
-
模型与硬件:项目中选用了
buffalo_l模型集,它在速度和精度之间取得了出色的平衡。同时,通过配置ctx_id=0,我们充分利用了服务器的GPU资源进行加速,这是保证实时性的基础。 -
核心优化:已知人脸特征预加载:这是本系统在人脸识别环节最重要的性能优化。如果每次都在视频帧中识别人脸后,再去和磁盘中的“已知人脸”图片进行实时比对,那将涉及大量重复的文件读取和AI计算,性能会非常低下。我的做法是:
-
在
FaceRecognizer类初始化时,程序会一次性遍历所有known_faces目录下的照片。 -
对每一张“标准照”进行人脸检测和特征提取,得到它们的Embedding向量。
-
将这些计算好的Embedding向量全部加载到内存中,存成一个字典(
{“张三”: embedding_of_张三, ...})。 -
在后续的实时视频处理中,我们只需要计算当前帧中出现人脸的Embedding,然后与内存中成百上千个已经计算好的“标准Embedding”进行高速的向量相似度计算即可。这把一个“图像到图像”的慢速比对,变成了一个“向量到向量”的纯数学运算,速度提升了几个数量级,是实现实时识别的关键所在。
-
四、 总结与展望
通过采用多线程、多队列的并发架构,我们成功地将三个独立的重型AI模型整合进一个统一的实时视频分析流程中。通过将计算任务、通知任务和I/O任务彻底解耦,系统不仅实现了高效的并行处理,还通过异步批量写入机制解决了高频日志带来的性能问题,保证了端到端的低延迟和高吞吐量。
未来的工作可以将系统中的硬编码路径和参数提取到独立的配置文件中,并为视频流的捕获增加更鲁棒的断线重连和错误恢复机制,使其成为一个更加产品化的解决方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)