到底什么是RAG技术以及有哪些chunk切片策略?一文带你了解核心流程。
RAG(检索增强生成)是一种结合信息检索与大模型生成能力的技术,通过实时检索外部知识库增强回答的准确性和时效性。其核心流程包括数据预处理、检索相关内容和生成回答,能有效解决传统大模型的知识时效性、幻觉问题和专业领域深度不足等局限。知识切片策略包括改进固定长度、语义、LLM语义、层次和滑动窗口等多种方法,各有优缺点,适用于不同场景。
在大模型快速发展的今天,人们对 AI 的要求不再只是“能说会道”,而是希望它“既聪明又可靠”。然而,传统大模型存在明显局限:参数中固化的知识具有时效性,无法实时更新;面对超出训练语料范围的问题时,容易出现“幻觉”;同时,模型训练和更新成本高昂。因此,本文将对应运而生的RAG技术进行原理和流程介绍,并提供数据处理阶段的切片策略方法。
目录
什么是RAG?
-
RAG 全称 Retrieval-Augmented Generation 检索增强生成。顾名思义,是将信息检索(Retrieval) 与自然语言生成(Generation) 有机结合。简单来说,RAG 的过程像一个学生做题:先去资料库中找到相关内容,再用自己的语言组织答案。
-
它的核心思想非常直白:大模型不用死记硬背所有知识,而是在需要时“查资料”,再结合自身的语言生成能力给出答案。
-
通过实时检索相关文档或信息,并将其作为上下文输入到生成模型中,从而提高生成结果的时效性和准确性。
RAG的优势?
-
解决知识时效性问题:大模型的训练数据通常是静态的,无 法涵盖最新信息,而RAG可以检索外部知识库实时更新信息。
-
减少模型幻觉:通过引入外部知识,RAG能够减少模型生成 虚假或不准确内容的可能性。
-
提升专业领域回答质量:RAG能够结合垂直领域的专业知识 库,生成更具专业深度的回答。
RAG的核心原理与流程
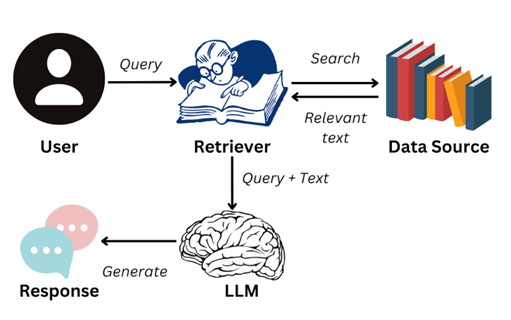
Step1 数据预处理
-
知识库构建:收集并整理文档、网页、数据库等多源数据,构建外部知识库。
-
文档分块:将文档切分为适当大小的片段(chunks),以便后续检索。分块策略需要在语义完整性与 检索效率之间取得平衡。
-
向量化处理:使用嵌入模型将文本块转换为向量,并存储在向量数据库中。
Step2 检索阶段
-
查询处理:将用户输入的问题转换为向量,并在向量数据库中进行相似度检索,找到最相关的文本片段。
-
重排序:对检索结果进行相关性排序,选择最相关的片段作为 生成阶段的输入。
Step3 生成阶段
-
上下文组装:将检索到的文本片段与用户问题结合,形成增强的上下文输入。
-
生成回答:大语言模型在“理解问题 + 利用外部知识”的基础上,生成更准确和可靠的回复。
虽然以上步骤流程看起来比较简单,但是在RAG应用从构建到落地实施的过程中,还是会涉及到很多问题与挑战,将会在后续的博客中详细的阐述相关内容以及针对这些问题的应对措施。
RAG的知识切片策略有哪些?(Chunk)
方法1:改进的固定长度切片
在固定 Token 数/字数切片的基础上,优先在句子边界切分,并引入重叠机制,保证上下文连续性。(最初的固定token方法粗暴简单,适用于精度要求没那么高的场景。)
方法2:语义切片
基于自然语言处理(NLP),按照句子/段落/语义边界进行切片,不做重叠。
方法3:LLM 语义切片
借助大语言模型(LLM)的语义理解能力,自动选择最佳分割点,在保证语义完整的同时,精确控制切片长度。
方法4:层次切片
结合文档的层级结构(标题、章节、小节、段落)进行切分,保持原有逻辑组织。
方法5:滑动窗口切片
设定固定大小窗口,在文本上滑动,产生重叠切片(例如每 500 Token,重叠 100 Token)
优缺点以及使用场景对比
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 改进的固定长度切片 | 实现简单,处理速度快;长度统一,方便批量处理和索引;重叠机制减少语义割裂 | 仍可能导致部分语义中断,尤其在长句子或跨段落时。 | 技术文档、大规模批量处理 |
| 语义切片 | 保持语义完整性,避免“句子被截断”;检索结果更精准 | 切片长度不均,可能造成过短或过长。 | 自然语言文本 |
| LLM 语义切片 | 能够智能选择切分点;同时兼顾语义完整性和长度控制 | 依赖算力(GPU/大模型调用),成本高;切分速度相对较慢 | 医疗、法律、科研等高精度场景,高质量要求 |
| 层次切片 | 保留文档逻辑关系;支持层次化检索和定位 | 依赖文档格式,切片大小不均衡 | 手册、教材、报告等结构化文档 |
| 滑动窗口切片 | 上下文连续性,减少信息丢失;提高召回率,处理速度也快 | 产生大量冗余内容,存储和计算成本高 | 长文档处理、问答系统 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 43
43 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)