大模型+小模型,原地起飞
大模型能力强但耗资源,小模型省资源但能力有限...有什么办法能将它们结合起来,发挥1+1>2的效果?今天就给大家分享几个常用的结合策略!为方便理解和学习,我还附上了每种策略相关的参考论文,共有17篇,包含开源代码,如果你对大模型结合小模型感兴趣,那强烈推荐阅读!
大模型能力强但耗资源,小模型省资源但能力有限...有什么办法能将它们结合起来,发挥1+1>2的效果?今天就给大家分享几个常用的结合策略!
为方便理解和学习,我还附上了每种策略相关的参考论文,共有17篇,包含开源代码,如果你对大模型结合小模型感兴趣,那强烈推荐阅读!
扫描下方二维码,免费获取学习资料包

模型压缩
模型压缩是实现大模型与小模型衔接的基础策略,核心是通过知识蒸馏/轻量化设计/剪枝与量化将复杂大模型转化为计算效率更高、资源需求更低的小模型,同时保留核心能力。
论文:Large Language Models Are Reasoning Teachers【模型蒸馏】
内容
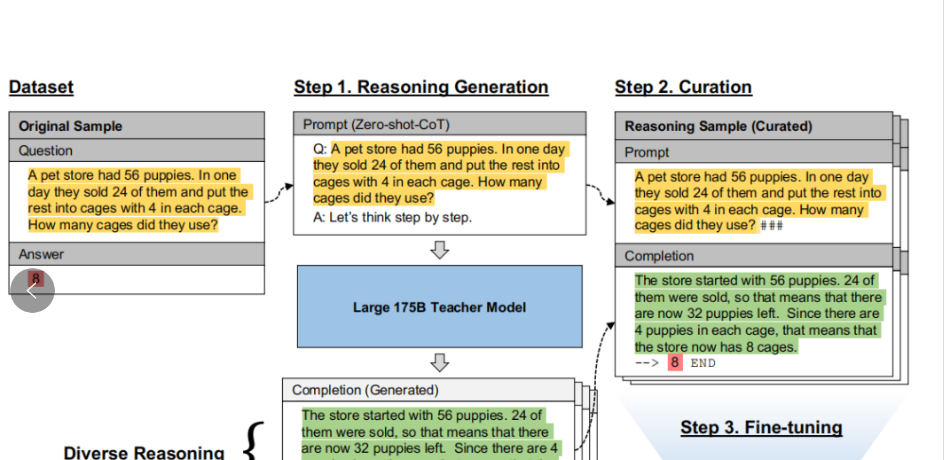
该论文提出了一种名为Fine-tune-CoT的方法,旨在利用大型语言模型(LLMs)作为“推理教师”,通过生成推理样本来训练小型语言模型,从而在小型模型中实现复杂的推理能力,大大降低了对模型规模的要求,使得推理能力可以在参数量小得多的模型中实现。
联合推理
复杂任务小模型搞不定?那就让大模型来当 “教师”!先让大模型生成一堆带详细解题步骤的样本(问题 + 正确答案 + 思路),然后用这些样本去 “特训” 小模型,慢慢小模型就学会怎么推理复杂问题了。
论文:CascadeBERT: Acceleratingnference of Pre-trained Language Models viaCalibrated Complete Models Cascade【模型串联】
内容
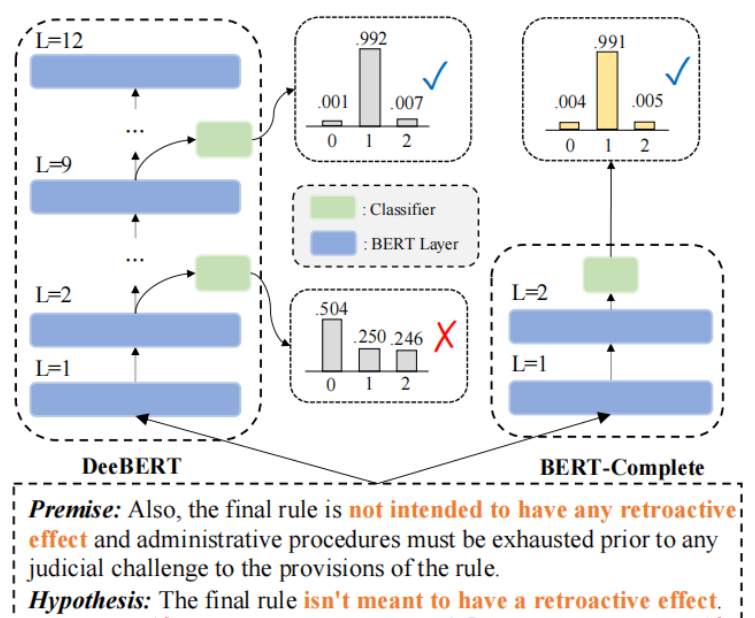
该论文提出了一种名为 CascadeBERT 的新框架,旨在通过动态选择合适大小的完整预训练语言模型(PLMs)来加速推理过程。该框架通过级联方式使用一系列不同层数的PLMs,并引入了一种基于实例难度的正则化目标,以提高模型在高加速比下的性能。
权值共享
大模型的底层能力很难打,可以让小模型直接共享大模型低层的权值,不用重新训练,只在小模型的高层针对具体任务训新权值,省时间又保效果。
论文:Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks viaAttention Transfer
内容
该论文提出了一种名为Attention Transfer(注意力转移) 的方法,用于通过模仿强大的教师网络的注意力图来显著提升卷积神经网络(CNN)的性能。论文定义了两种类型的注意力图:基于激活的注意力图和基于梯度的注意力图,并展示了如何通过这些注意力图将知识从教师网络转移到学生网络。

迁移学习
先在大规模通用数据集上训练大模型,让它具备扎实的基础认知与泛化能力,然后将该大模型作为预训练基础,在特定场景的小型数据集上对小模型进行微调,让小模型快速适配具体任务需求。
论文:A Simple Framework for Contrastive Learning of Visual Representations
内容
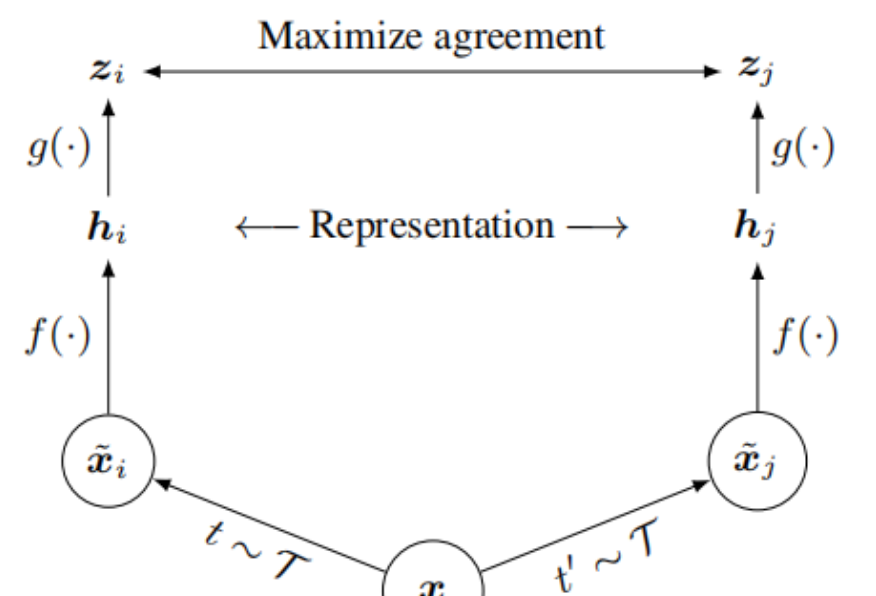
该论文提出了一个名为SimCLR的简单框架,用于对比学习视觉表示,SimCLR通过最大化不同增强视图之间的相似性来学习表示,无需复杂的架构或记忆库,通过系统性研究发现,数据增强的组合、非线性变换的引入以及更大的批量大小和更多的训练步骤对学习有效的表示至关重要。
扫描下方二维码,免费获取学习资料包

将小模型作为插件
插件化策略将小模型定位为大模型的功能延伸或辅助模块,实现任务的精细化分工。大模型负责核心复杂任务,小模型就承担专项辅助功能。
论文:Small Models are Valuable Plug-ins for Large Language Models
内容
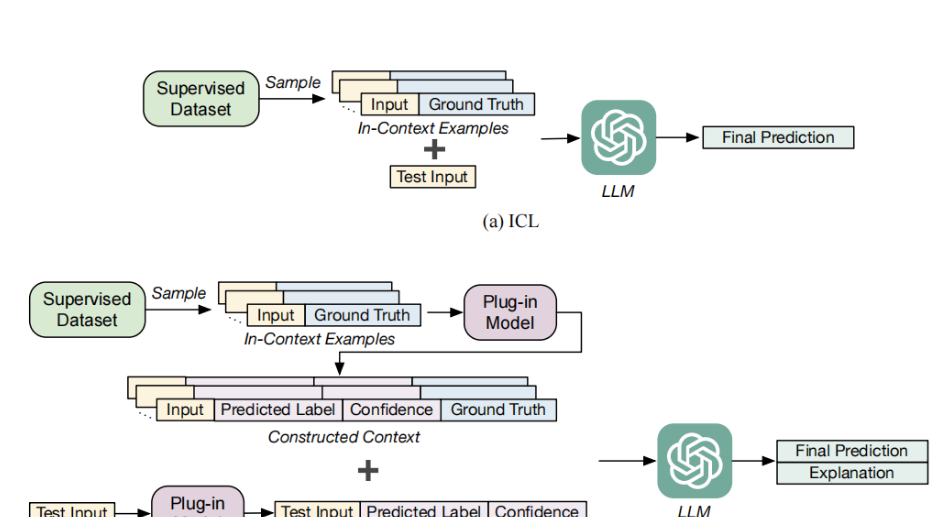
该论文提出了一种结合大型语言模型(LLM)和本地微调的小型模型的方法SuperICL,用于提升监督任务的性能,通过将小型模型作为插件,利用其对特定任务的了解来增强大型语言模型的性能,同时解决了传统上下文学习(ICL)的不稳定性和性能瓶颈问题。
提示语压缩
通过一个小模型对提示语进行压缩。
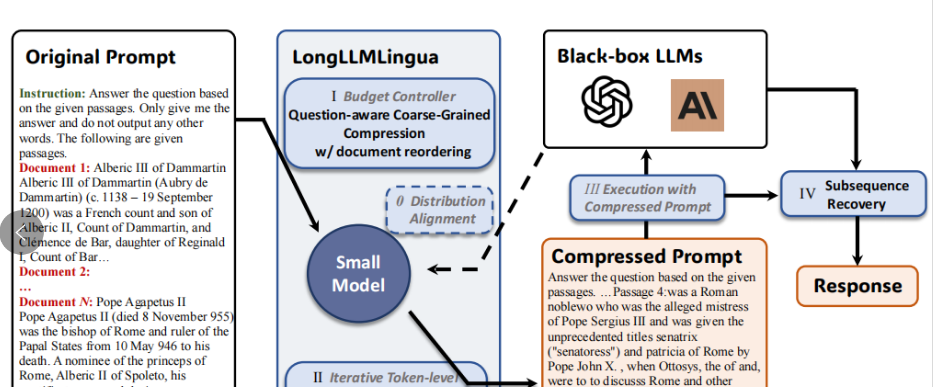
论文:LongLLMLingua:ACCELERATING ANDLLMS IN LONG CONTEXT SCENARIOS VIA PROMPTCOMPRESSION
内容
ga该论文提出了一个名为LongLLMLingua的框架,旨在通过提示压缩来加速并提升大型语言模型(LLMs)在长文本场景下的性能,LLMs在多个长文本基准测试中表现出色,不仅显著降低了计算成本和延迟,还提高了模型性能。
集成学习
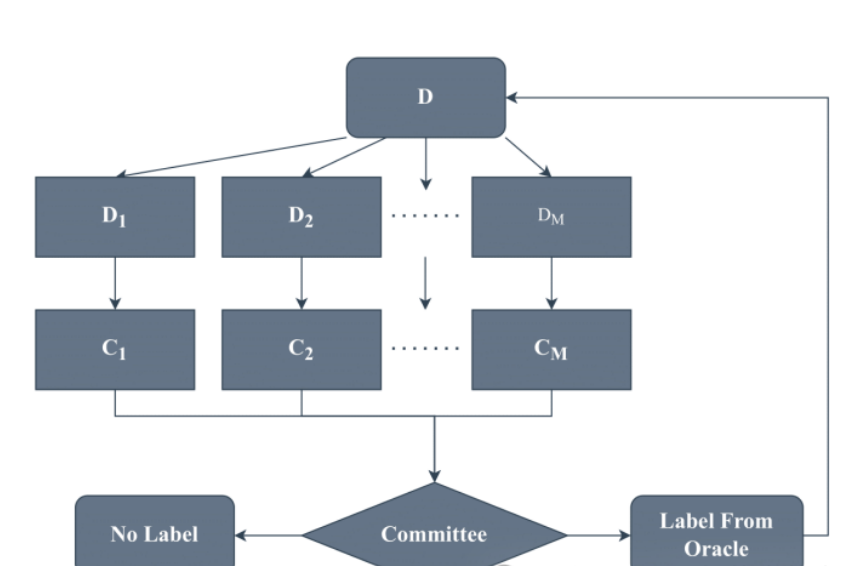
集成学习通过组合多个小模型的优势,弥补单个小模型的能力局限,实现性能提升。具体方法包括模型平均、模型堆叠。
论文:Ensemble deep learning: A review
内容
该论文回顾了当前深度集成学习模型的最新进展,并为研究人员提供了一个广泛的总结,文章将集成模型分为多种类别,包括基于Bagging、Boosting、Stacking、负相关集成、显式/隐式集成、同质/异质集成以及基于决策融合策略的深度集成模型等,并提出了未来研究方向。
其他策略
除上述典型策略外,大模型与小模型的协同还可通过更多场景化方式实现。
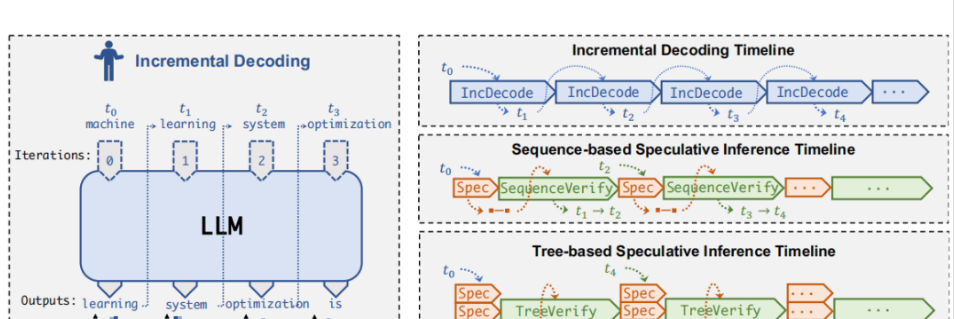
论文:SpecInfer: Accelerating Generative Large Language Model Serving with Speculative Inference and Token Tree Verification【投机式推理】
内容
该论文介绍了一个名为SpecInfer的系统,旨在通过基于树的推测性推理和验证机制加速大型语言模型(LLM)的推理服务,利用小型推测模型(SSM)预测 LLM 的输出,并将这些预测组织成一个令牌树,然后通过一种新颖的并行解码机制对令牌树中的所有候选令牌序列进行并行验证。
扫描下方二维码,免费获取学习资料包


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)