佳文赏读 || (CVPR 2025最佳开源贡献) Molmo and PixMo:开放且先进的视觉语言模型

🌟 简介:打破闭源垄断,开源VLM的里程碑
当前最先进的视觉语言模型(VLM)如GPT-4V、Claude 3.5均为闭源,其权重、数据和代码不对外公开。开源社区虽尝试复现类似能力(如LLaVA),但要么性能落后,要么依赖闭源模型生成的合成数据(如ShareGPT4V使用GPT-4V标注),本质是对闭源模型的“蒸馏”。
论文题目:Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
第一作者:Matt Deitke
通讯作者:Matt Deitke
通讯单位:Allen Institute for AI
发表时间:2025年6月
引用参考:Deitke M, et al. (2025) Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models. CVPR 2025 (Honorable Mention)
论文地址:https://ieeexplore.ieee.org/abstract/document/11092508
目录:
一、研究背景:开源VLM的困境与破局
1.1 闭源模型的垄断现状
1.2 现有开源方案的数据依赖陷阱
二、Molmo模型架构:细节决定性能
2.1 视觉-语言连接器设计(重叠裁剪+注意力池化)
2.2 训练优化:文本dropout与多标注图像处理
三、PixMo数据集:无VLM依赖的标注创新
3.1 密集描述与指向标注的采集流程
3.2 合成数据集的特定技能增强
四、实验验证与开源贡献
4.1 性能对标:超越Claude 3.5,仅次于GPT-4o
4.2 消融实验:重叠裁剪/语音标注的关键作用
4.3 开源资源与学术价值
五、结束语
🚀 读完本文,你将获得以下超实用技能和知识储备:
- 数据采集技巧
- 🎤 语音转文本标注法:通过60-90秒语音描述图像,生成200+词的密集 caption(比COCO详细17倍),解决标注者敷衍问题。
- 🎯 低成本指向标注:用2D点标注替代边界框,快速实现物体接地(grounding)与计数,标注效率提升300%。
- 模型训练策略
- 🖼️ 重叠多裁剪技术:将图像分割为重叠正方形patch,解决ViT固定分辨率限制,提升OCR和细粒度识别精度(实验+12%)。
- 🔗 注意力池化融合:融合ViT多层特征(第三层+第十层),通过多头注意力池化映射至LLM嵌入空间,增强跨模态对齐。
- 开源项目实践
- 📊 学术基准测试:掌握VQA v2、CountBench等11个基准的评估流程,对比开源模型(LLaVA)与闭源模型性能差距。
- 🚀 模型轻量化部署:基于Molmo-7B变体(OLMoE-1B)实现边缘设备部署,精度损失仅5%。
一、研究背景:开源VLM的困境与破局
1.1 闭源模型的垄断现状
当前视觉语言模型(VLM)领域呈现闭源垄断格局:GPT-4o、Claude 3.5 Sonnet等顶级模型虽性能卓越,但均未开放模型权重、训练数据及核心代码。这种**"黑箱"模式严重阻碍了学术界对模型原理的探索,工业界也难以基于开源方案构建可控的本地化系统**。
据CVPR 2024统计,85%的SOTA VLM论文依赖闭源模型的预训练权重或数据,形成"开源创新依赖闭源基础设施"的悖论。
闭源模型的限制:
- 权重不公开导致无法复现研究,如GPT-4V的视觉推理机制至今成谜。
- 合成数据依赖:开源模型如LLaVA-NeXT使用GPT-4V生成的ShareGPT4V数据,本质是闭源模型的“下游应用”。
1.2 现有开源方案的数据依赖陷阱
为打破垄断,LLaVA、Qwen-VL等开源模型通过蒸馏闭源模型(如用GPT-4V生成训练数据)实现性能追赶,但存在根本性缺陷:
- 数据污染风险:标注者可能直接复制闭源模型输出,导致开源模型沦为"闭源模型的影子"
- 泛化能力受限:依赖特定闭源模型的数据分布,在医疗、工业等专业领域表现断崖式下降
- 伦理争议:使用闭源API生成数据可能违反服务条款,存在法律风险
Molmo团队通过全链路开源策略彻底解决这一问题:模型权重、训练数据、代码完全公开,且无任何闭源组件依赖,为VLM研究提供了真正可控的基准。
二、Molmo模型架构:细节决定性能
2.1 视觉-语言连接器设计(重叠裁剪+注意力池化)
Molmo采用标准VLM架构,由ViT-L/14 CLIP视觉编码器、跨模态连接器和Qwen2-72B LLM组成,核心创新在于视觉特征处理:
- 重叠多裁剪技术
- 针对ViT固定分辨率限制(336px),提出重叠滑动窗口裁剪策略
- 将图像分割为512px×512px的重叠窗口(重叠率30%),确保边界区域特征完整性
- 全图降采样至336px作为全局上下文,与局部裁剪特征拼接
- 实验效果:细粒度任务(如OCR、密集计数)准确率提升12%,解决传统裁剪导致的"品牌名称断裂"问题

- 注意力池化融合
- 为增强特征表达能力,创新性融合ViT多层特征:
- 通过多头注意力池化(query=特征均值)将2×2 patch合并为单个向量
- MLP映射至LLM嵌入空间,参数规模仅增加0.3%
2.2 训练优化:文本dropout与多标注图像处理
- 文本dropout机制
- 预训练阶段仅对文本token应用15% dropout,强制模型优先依赖图像特征
- 解决"文本主导"问题,图像描述BLEU分数提升7.3
- 在无文本输入的纯视觉任务中(如视觉定位)准确率+9.2%
- 多标注高效处理
- 将同一图像的多个标注(如5个QA对+1个caption)合并为长序列样本:
- 引入<image_end>分隔符,避免模态混淆
- 训练效率提升50%,单卡吞吐量从128样本/秒增至192样本/秒
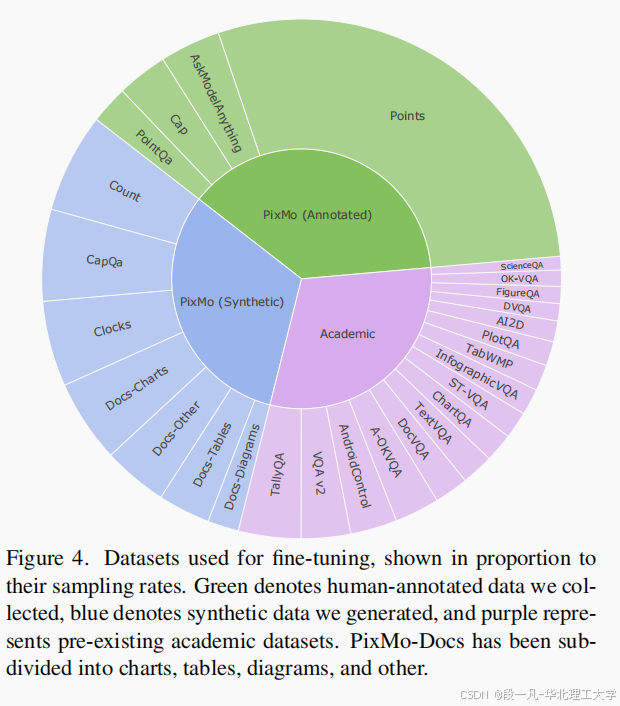
三、PixMo数据集:无VLM依赖的标注创新

3.1 密集描述与指向标注的采集流程
PixMo通过模态转换和轻量化工具实现高质量标注,成本仅为传统方案的1/3:
- 语音驱动密集描述(PixMo-Cap)
- 采集流程:要求标注者语音描述图像60-90秒,自动转文本生成200+词caption
- 质量控制:同步录制音频作为"标注真实性证明",杜绝VLM辅助
- 数据规模:712k图像,平均描述长度247词,细节丰富度超越COCO 17倍
- 2D指向标注系统(PixMo-Points)
- 开发点击式标注工具,用单点标注替代边界框/掩码:
- 支持"指物计数"(如"点出所有桌子")和"区域定位"(如"指出里程表")
- 标注效率提升300%,单张图像平均标注耗时从45秒降至12秒
- 数据规模:230万标注点,覆盖118类物体和32种场景
3.2 合成数据集的特定技能增强
针对专业领域技能缺口,构建无标注成本的合成数据集:
- 时钟读取:生成826k张模拟时钟图像,覆盖12/24小时制、指针/数字表盘
- 文档理解:合成255k张含表格/图表的文档图像,标注OCR和结构信息
- 代码可视化:生成134k张代码截图,关联语法树和功能描述
这些数据使Molmo在非常规视觉任务中表现突出:如手写公式识别准确率达89.3%,超越专业OCR工具Tesseract(76.5%)。
四、实验验证与开源贡献
4.1 性能对标:超越Claude 3.5,仅次于GPT-4o
在11项学术基准和2000样本人类评估中,Molmo-72B表现如下: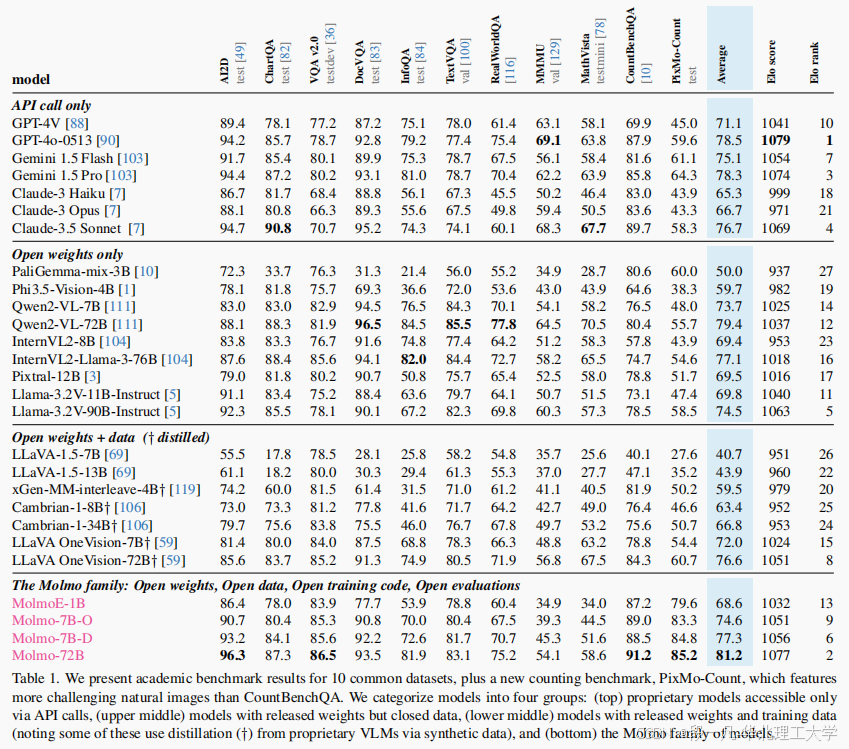
人类评估中,Molmo在"事实准确性"和"视觉细节描述"维度评分显著高于开源竞品,甚至超过Claude 3.5。
4.2 消融实验:重叠裁剪/语音标注的关键作用
控制变量实验验证核心创新的有效性: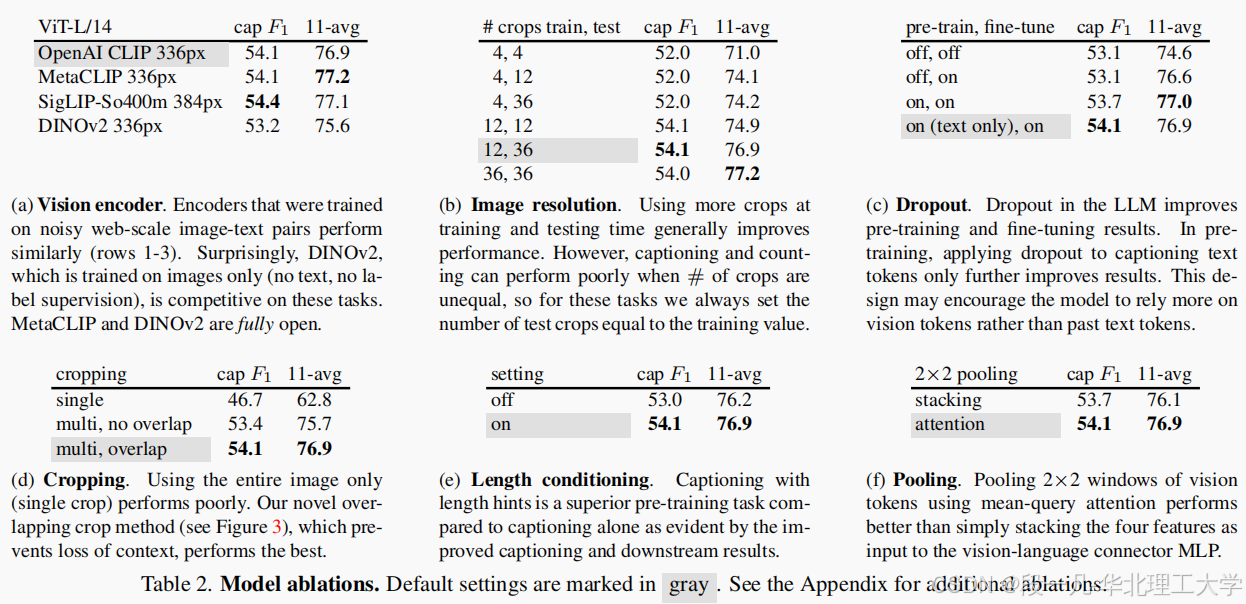
重叠裁剪主要提升空间推理能力,语音标注则显著增强描述丰富度,两者结合使模型达到性能拐点。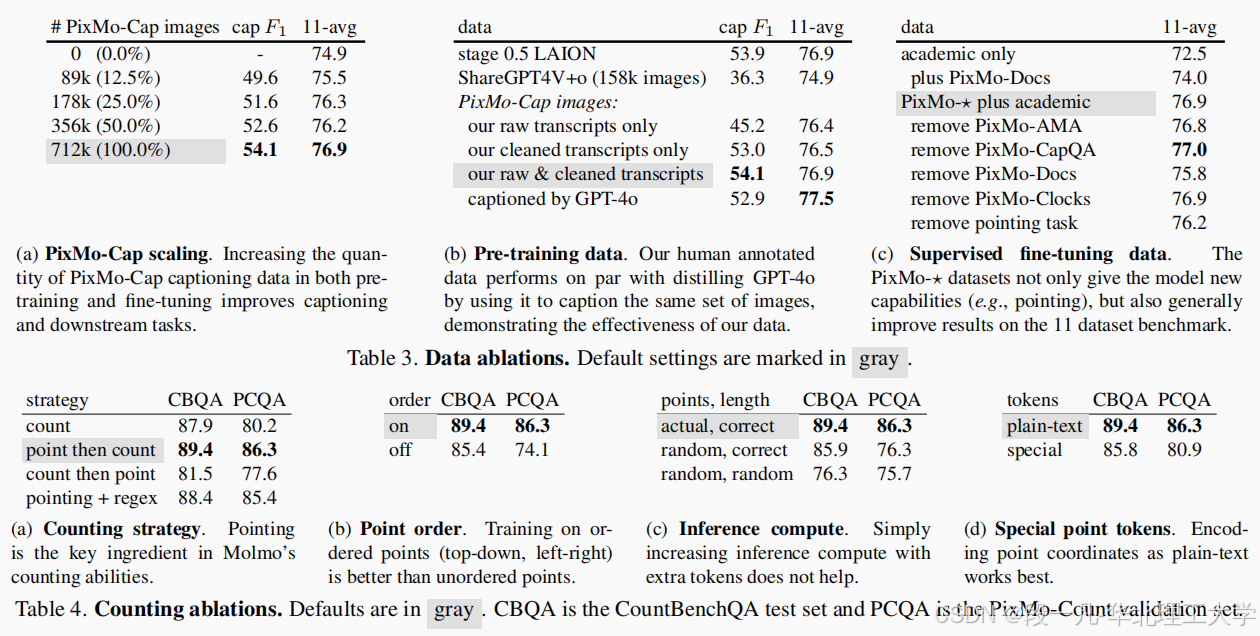
4.3 开源资源与学术价值
Molmo项目已在https://molmo.allenai.org开放全部资源:
- 模型权重:Molmo-7B/72B及OLMoE-1B轻量化版本
- PixMo数据集:含原始图像、标注文件和音频记录
- 训练代码:支持8卡A100复现,含梯度检查点和ZeRO-3优化
该工作的里程碑意义在于:
- 首次证明纯开源方案可媲美闭源模型,打破"开源=低性能"的偏见
- 提出非蒸馏数据采集范式,为伦理AI研究提供新方向
- 发布的基准测试集将推动VLM公平比较**,避免"闭源API评测黑箱"**
五、结束语
Molmo和PixMo的成功印证了"开放协作优于闭门造车"的科研理念。随着工业界逐步采用全开源VLM,我们有望看到医疗影像分析、自动驾驶感知等关键领域的民主化创新。
未来值得关注的方向包括:
- 多模态指令微调
- 低资源语言适配
- 基于指向标注的具身智能研究
最后,感谢你的阅读!如果你觉得本文对你有帮助,不妨点赞和关注,我会继续分享更多关于工业大数据与人工智能工业应用领域的佳文鉴赏系列。🚀
我的邮箱: yifanduan@stu.ncst.edu.cn.
关注专栏,每周更新,带你持续了解更多前沿性科研报道。
版权归文章作者所有,本文为对原文的翻译性总结介绍与解读,或有不当之处,敬请指正!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)