INT4量化新突破!昇腾MindStudio 量化工具助力DeepSeek R1显存减负75%,精度仅损失<1%
msModelSlim量化工具,为用户提供了多种量化、离群值抑制算法的API接口。同时,msModelSlim也提供一键量化、自动选层的能力,用户无需深入量化细节或反复调试参数,仅需调用简洁接口即可快速完成最优量化配置搜索,降低操作门槛,显著提升开发效率。无论是希望快速部署轻量化模型的工程师,还是追求极致性能的研究者,msModelSlim都能提供专业、高效的量化工具,助力AI应用高效落地,欢迎大
目录
02 精度保障:Fused Iter-smooth逆向平滑创新算法
实操指南:使用msModelSlim进行DeepSeek R1 W4A8量化
模型量化挑战
随着Transformer 架构的模型参数规模迅速扩大,其对显存和算力的需求也日益增加,因此,如何有效减少模型的权重大小、提升计算效率变得尤为重要。为解决这一痛点问题,大模型量化技术提出降低参数数值精度的方案,例如,从浮点数转为整数,来节省资源。其中,INT4量化凭借将参数从16bit压缩至4bit的突破性设计,实现模型4倍瘦身。
昇腾MindStudio 全流程工具链中的量化工具msModelSlim,提供多种先进量化算法接口,支持INT8\INT4量化,显著提升大模型推理效率,降低服务部署成本。msModelSlim现已适配DeepSeek R1模型的W4A8(Weight 4-bit, Activation 8-bit)量化,在精度损失小于1%的前提下,实现权重占用减小75%,支持千亿级模型单卡低显存量化,单机高效部署。
MindStudio量化工具 W4A8混合量化技术解读
01 模型压缩:W4A8混合量化策略
MLA作为DeepSeek R1模型中一种特殊的注意力机制设计,参数占比较小,但对量化误差更为敏感。与之相反的是,MoE中的路由专家部分参数占比大,对于量化误差不太敏感,所以为平衡精度损失与量化效率,msModelSlim采用了W4A8和W8A8混合量化的策略。
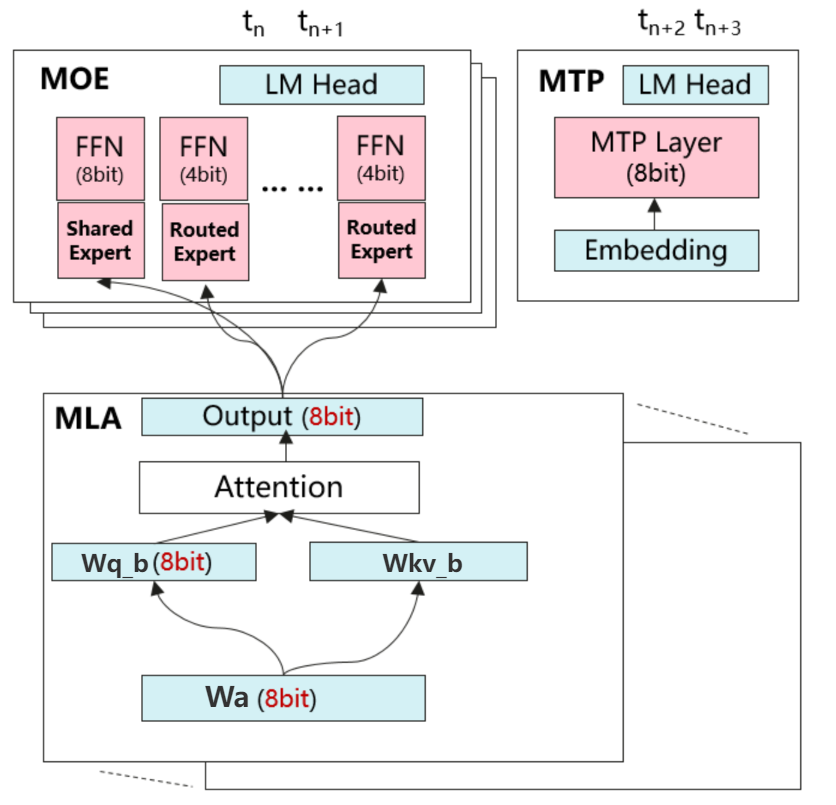
图1 DeepSeek R1 W4A8混合量化策略示意图
如图1所示,在MLA模块中,针对线性层激活分布平稳的特性,采用W8A8静态量化方案。权重实施per-channel对称量化(W8),激活采用per-tensor非对称量化(A8),后者能更好地适应非对称分布或存在离群值的激活数据。
MOE模块则采用per-token动态量化策略应对专家激活分布不稳定的挑战。共享专家(Shared Expert)采用W8A8动态量化配置,权重保持per-channel对称量化(W8),激活实施per-token对称量化(A8)。路由专家(Routed Expert)采用W4A8动态量化配置,这样看,误差来源主要是权重,因此权重做Qserve两级量化对权重第一级INT8 per-channel量化,第二级INT4 per-group量化,可以通过较小的量化粒度来保持一个较好的量化精度,激活保持per-token对称量化(A8)
MTP模块则采用per-token动态量化策略,权重保持per-channel对称量化(W8),激活实施per-token对称量化(A8)。
注:per-tensor量化又称为per-layer量化,指对整个linear的weight tensor使用一个scale值进行量化,per-channel量化指对一个channel使用一个scale进行量化,per-group量化指对权重进行分组量化,每组group_size个元素(group size一般为64或128)。
02 精度保障:Fused Iter-smooth逆向平滑创新算法
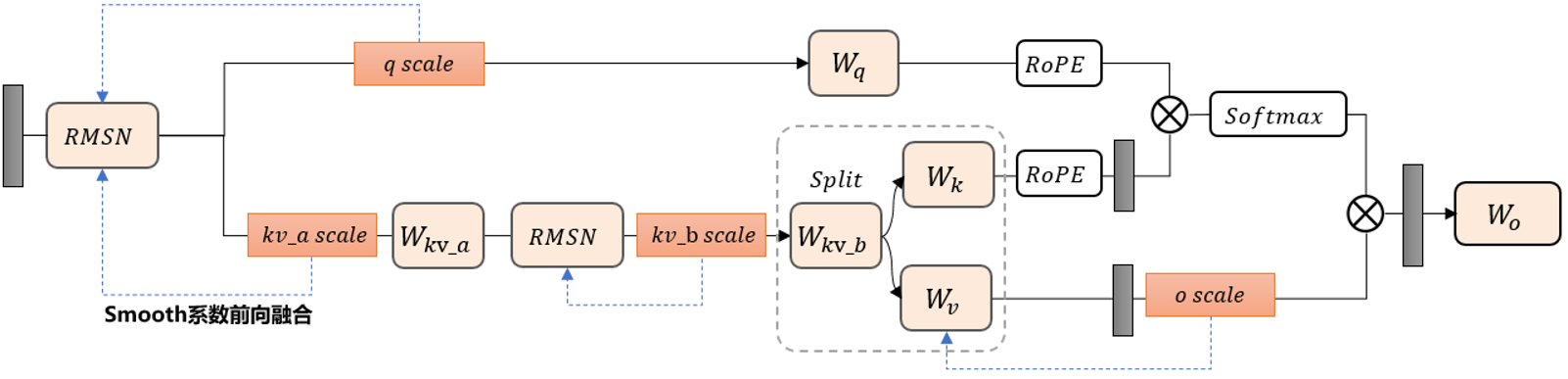
图2 Fused Iter-smooth逆向平滑算法
msModelSlim对于离群值抑制创新性地使用Fused Iter-smooth逆向平滑算法。如图2所示,传统的SmoothQuant算法只平滑norm层和线性层离群值,但Fused Iter-smooth采用自后向前的传播机制,从量化敏感的输出投影层(o_proj)出发,逐层向前迭代优化。具体实现分为三个阶段:首先在o_proj层统计初始平滑系数(smooth scale),将该系数融合至前一层的kvb运算;随后对kvb层的输入激活进行离群值抑制,计算得到新的缩放因子;最后将该因子进一步向前融合至RMSN层。这种逆向传播架构具有双重优势:一方面,通过从量化敏感层反向传播的方式,确保关键层的异常值得到优先抑制;另一方面,结合自适应搜索机制动态优化各层平滑系数,使整体量化误差得到系统性降低。实验表明,该算法在不引入额外计算开销的前提下,能有效提升模型在低精度量化下的数值稳定性。
实操指南:使用msModelSlim进行DeepSeek R1 W4A8量化

图3 msModelSlim进行DeepSeek R1 W4A8量化
01 下载安装
参考文档: https://gitee.com/ascend/msit/tree/master/msmodelslim
按照文档中的“环境和依赖”安装环境和依赖。注意根据“注意事项”完成环境自检,然后按照“msModelSlim安装方式”下载安装msModelSlim。
02 快捷量化DeepSeek R1
当前为便于用户使用,msModelSlim提供了针对DeepSeek R1模型的W4A8量化脚本:https://gitee.com/ascend/msit/blob/master/msmodelslim/example/DeepSeek/quant_deepseek_w4a8.py
用户需要准备好浮点权重,就可以使用该量化脚本实现DeepSeek R1模型的W4A8量化,操作步骤如下:
1) 首先按照下列文档中的“DeepSeek-V3/R1/运行前必检”,对需要手动配置的内容进行修改。
参考文档:https://gitee.com/ascend/msit/blob/master/msmodelslim/example/DeepSeek/README.md
2) 如果需要使用NPU多卡量化,请先配置下列环境变量:
# 示例指定0,1,2,3,4,5,6,7卡用于量化export ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7#关闭NPU虚拟内存export PYTORCH_NPU_ALLOC_CONF=expandable_segments:False
3) 最后将命令行中的{浮点权重路径}和{量化权重路径}替换为用户实际路径,运行量化脚本生成DeepSeek-R1模型 W4A8混合量化权重:
# 下面命令默认使用 10 条校准集
python3 quant_deepseek_w4a8.py --model_path {浮点权重路径} --save_path {W4A8量化权重路径}
# 如果想要获取更高的精度,可以使用 50 条校准集,如果显存够用可以尝试 16 batch_size 加载校准集
python3 quant_deepseek_w4a8.py --model_path {浮点权重路径} --save_path {W4A8量化权重路径} --anti_dataset ./anti_prompt_50.json --calib_dataset ./calib_prompt_50.json --batch_size 16
03 输出件展示
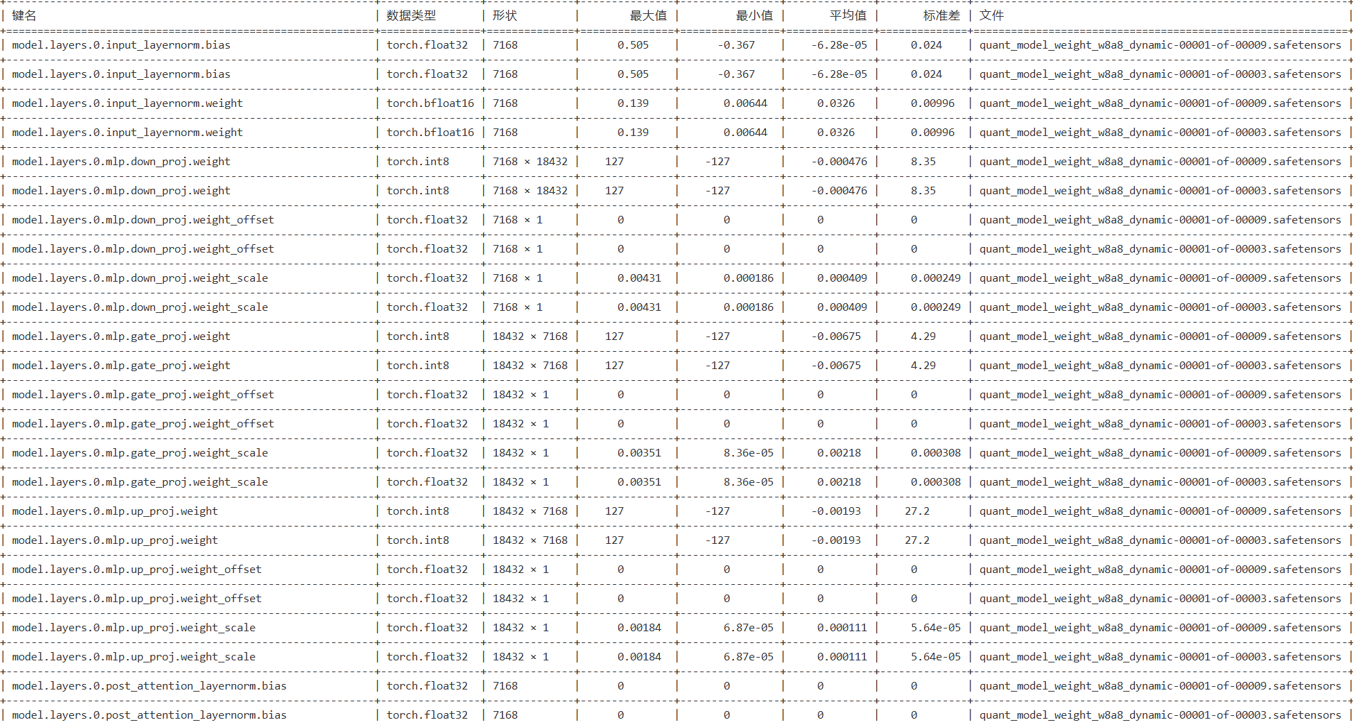
1)量化权重文件.safetensors,部分示例如下:
2)描述文件.json,描述文件对每个权重增加描述字段,说明该权重的量化方式,部分示例如下:
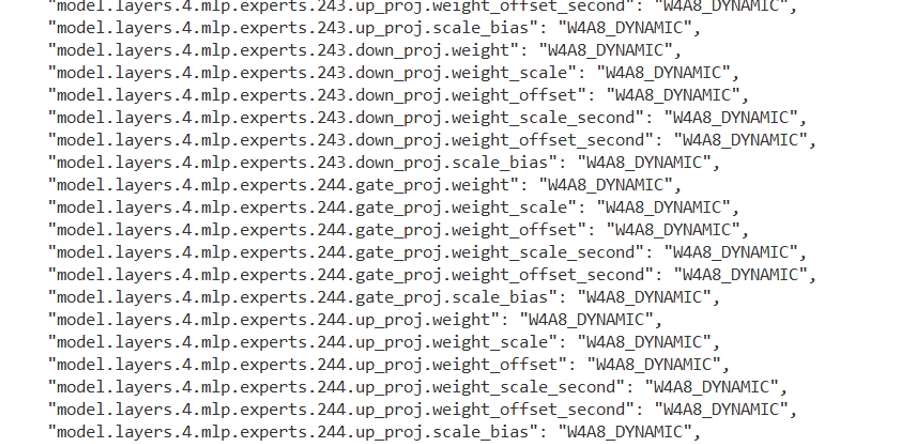
使用msModelSlim提供的量化脚本对DeepSeek R1 671B模型进行W4A8混合量化,原始模型BF16权重数据占内存1.3T,量化后模型权重数据仅占内存340GB。同时,对量化后的模型进行了精度验证,测试结果显示在BoolQ、CEval和GSM8K等多个基准数据集上,量化模型相较于原始模型的平均精度损失控制在1%以内,实现了精度和量化效率的良好平衡。
结语
msModelSlim量化工具,为用户提供了多种量化、离群值抑制算法的API接口。同时,msModelSlim也提供一键量化、自动选层的能力,用户无需深入量化细节或反复调试参数,仅需调用简洁接口即可快速完成最优量化配置搜索,降低操作门槛,显著提升开发效率。无论是希望快速部署轻量化模型的工程师,还是追求极致性能的研究者,msModelSlim都能提供专业、高效的量化工具,助力AI应用高效落地,欢迎大家安装体验msModelSlim带来的便捷与高效!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)