GPT-5发布:技术“挤牙膏“,OpenAI的“AGI梦“还有多远?
OpenAI发布GPT-5引发争议:技术进步有限,更像迭代而非突破。采用MoE架构,在编程等专业领域表现突出,但创作能力反而退步。多模态功能存在明显缺陷,商业策略引发伦理争议。行业面临性能趋同困局,开源模型快速发展。专家指出,GPT-5虽能处理复杂任务,但本质仍是概率模型,离真正AGI尚有距离。建议用户根据需求选择版本,开发者可重点试用"代码手术刀"等特色功能。当前AI发展需要
引言:从"死星"到"图表乌龙"的落差
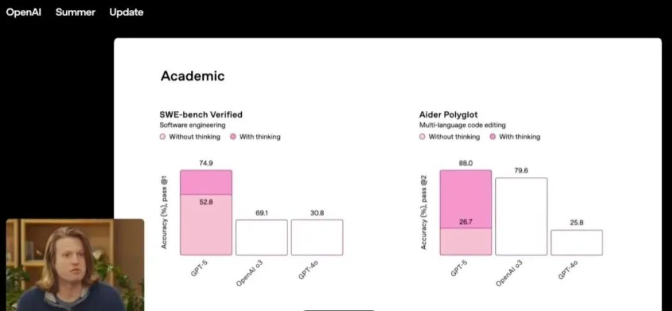
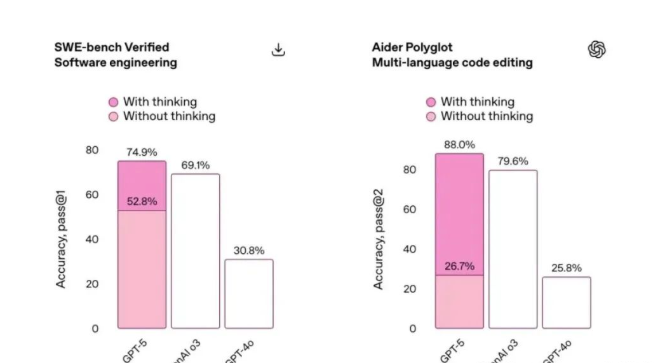
当Sam Altman在推特上放出《星球大战》死星图暗示GPT-5时,嚯当时科技圈沸腾了,人们期待看到能碾压"旧AI范式"终极武器的到来。然而发布会现场,OpenAI工程师用一张错位的柱状图(将52.8%误标为69.1%),这多么尴尬,这场乌龙"委婉"揭示了真相:这次升级更像是iPhone 15到iPhone 16的迭代,而非iPhone到Vision Pro的颠覆。
错误的数据
实际上的
技术解析:进步与争议
1. 架构:"三位一体"的MoE模式
GPT-5本质上是由三个子系统组成的混合专家模型(MoE):
推理引擎(1250亿参数):专攻数学证明和代码生成
创意模块(860亿参数):负责文学创作和对话
校验网络:类似AlphaGo的"裁判"角色
其中“路由机制”的优化是最大亮点。当用户提问"用Python实现快速排序"时,系统会像机场塔台调度般,将任务精准分配给"推理引擎"(90%权重)+ "创意模块"(10%权重用于注释书写)。对比测试显示,其SWE-bench编程基准达到74.9%,比GPT-4提升23个百分点。
2. 性能的优缺点
优势领域:复杂项目开发,智能代理任务,调试大型码库,算法设计等
在LeetCode周赛中可以击败85%的人类程序员
能自动修复PyTorch代码中的CUDA内存泄漏bug
顽固短板:写作内容创建等
当GPT-5要求模仿鲁迅风格写"当代孔乙己"时,却产出这样的段落:
"他排出九文大钱,用区块链钱包扫码支付时,手指在冷冽的NFT界面上微微发抖..."
(对比测试的GPT-4.5版至少知道用"青白脸色"这类典型意象,而GPT-5反而退步到堆砌科技名词)
3. 多模态的模糊
尽管宣传视频展示GPT-5能解读CT影像,但实际测试中却出现如下状况:
把MRI脑部扫描图的左右半球镜像搞混淆
无法区分毕加索《格尔尼卡》与儿童涂鸦的情感之间的表达差异
华人研究员Liang Chen在GitHub指出:"当前视觉模块本质上是给图像打标签的增强版CLIP模型。"
商业策略:价格战背后的焦虑
OpenAI这次价格偏低:
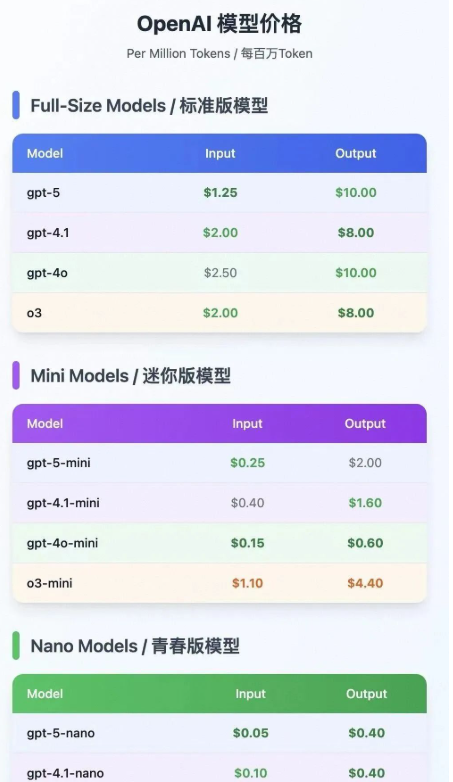
争议操作:
强制开发者6个月内迁移旧模型(换新的意思),从而引发抗议,目前Reddit上已有3000+抗议帖
被发现在API条款中新增"输出内容可用于模型训练"的隐藏条款。AI伦理研究员Timnit Gebru尖锐评价:"这就像卖给你一台相机,却保留随时查看你相册的权利。"
行业影响:LLM的天花板现象
1. 性能趋同困局
在MMLU综合测试中,GPT-5与Claude 4 Opus和Gemini 2.5 Pro比拼数据对比,如图。
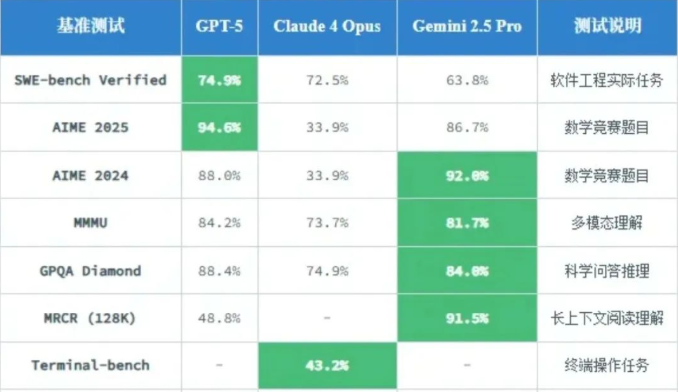
2. 开源势力的猛烈发展
Meta最新开源的Llama 3-400B在Hugging Face排行榜超越GPT-4 Turbo,然而训练成本仅为前者的1/7。看来开源模型正在降低训练成本以达到快速商品化大模型能力。
用户指南:需把钢用在刀刃上
开发者必试功能,看看好不好用:
"代码手术刀"模式:用自然语言指令直接修改GitHub仓库(实测重构Flask项目效率能提升40%)
长上下文彩蛋:在128k窗口输入《三体》全文后,是可以准确回答"云天明的大脑发射日期"等细节问题
给普通用户的小建议:
免费版足够应付日常邮件润色/简单问答
不过20美元/月的Pro版性价比存疑,除非需要高频调用API,这样才划算
结语:AGI不应该只是一个噱头,想要真正踏入AGI时代,更要落实行动才有成果
Yann LeCun的预言正在应验:"用更大规模的LLM追求AGI,就像造更高的巴别塔。"当我们看到:
GPT-5仍会坚信"华盛顿是唐朝皇帝"这类基础常识的事实错误,还有其"思维链"本质上是概率抽卡产生的精致幻觉
那么或许我们该把目光投向更底层的突破:
1.神经符号系统(如DeepMind的AlphaGeometry)
2.世界模型构建(特斯拉的Occupancy Networks)
3. 合成数据革命(Anthropic的宪法AI)
最后引入一位知乎用户的妙喻:"GPT-5像是能背诵《辞海》的学者,但离'理解'世界如同婴儿还在蹒跚学步。"
还想了解更多AI知识么?更多讨论,咨讯尽在“AI共学苑”,欢迎大家加入

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)