AI视觉系统的致命弱点:一张贴纸就能骗过自动驾驶!深度解读物理对抗样本开山之作
🔥当AI遇上现实世界的"视觉欺骗"!本文精读Google Brain经典论文,全面解析物理对抗样本的生成原理与攻击机制。对抗样本研究已从数字图像延伸到物理世界。通过在真实物体上添加特定的扰动图案,可以影响深度学习模型的识别结果。本文介绍物理对抗样本的基本原理、常见生成方法,以及在交通标志识别、人脸识别等场景中的实际表现。同时探讨现有的防御机制和未来研究方向,帮助开发者更好地理解和应对AI系统在真
注:本文为个人阅读论文精读,学术译文及其注解,或有瑕疵
以下提供原文链接:https://arxiv.org/abs/1607.02533
文章目录
ADVERSARIAL EXAMPLES IN THE PHYSICAL WORLD【个人阅读注解】
摘要(Abstract)
大多数现有的机器学习分类器(Machine Learning Classifiers) 对对抗样本(Adversarial Examples) 高度脆弱。对抗样本是对输入数据进行极其轻微的修改而成,其目的在于诱使机器学习分类器(Machine Learning Classifier) 产生误分类。在许多情形下,这些改动细微到人类观察者(Human Observer) 几乎察觉不到,但分类器仍会犯错。对抗样本带来安全隐患(Security Concerns) ,因为即使攻击者无法访问底层模型,也可能利用它们对机器学习系统发动攻击。迄今为止,既有研究普遍假设一种威胁模型:攻击者可以将数据直接馈入机器学习分类器(Machine Learning Classifier) 。然而,对于在物理世界(Physical World) 中运行的系统(例如以相机(Camera) 和其他传感器(Sensors) 信号为输入的系统),上述假设并不总是成立。本文表明,即便在此类物理场景中,机器学习系统仍然易受对抗样本攻击。我们通过将手机相机(Cell-Phone Camera) 拍摄得到的对抗图像输入ImageNet上训练的Inception分类器并测量系统的分类精度(Classification Accuracy) 来验证这一点。我们发现,即便通过相机感知,对抗样本中仍有相当比例会被错误分类。
- 研究背景:现有的研究通常假设攻击者能够直接向机器学习模型输入数据,从而产生对抗样本并进行误分类。然而,在现实中,很多机器学习系统是通过物理设备(如相机、传感器)感知世界的,现有研究未充分考虑这一点。
- 对抗样本定义:对抗样本是对输入数据进行微小的修改,使得模型产生误分类,这些修改对人类观察者几乎不可察觉。
- 实验方法:本文通过使用手机相机拍摄对抗样本,并将其输入Inception v3图像分类模型来测试在物理世界中的效果。实验结果显示,这些对抗样本在被相机拍摄后,仍然能够导致模型产生误分类。
- 主要发现:即使对抗样本通过相机转化为现实世界的图像,它们仍能欺骗深度学习模型。这表明物理世界中的机器学习系统可能面临对抗样本攻击的风险。
- 研究意义:这一发现揭示了物理对抗样本(physical adversarial examples)对机器学习系统的潜在安全威胁,并为未来在物理世界中进行对抗攻击的研究提供了重要依据。
- 未来方向:研究者可以进一步探索如何通过显式建模物理变换来提高对抗样本攻击的成功率,并且研究如何在黑盒条件下进行有效的对抗攻击。
1 引言(Introduction)
近期在机器学习(Machine Learning) 与深度神经网络(Deep Neural Networks) 方面的进展,使研究者得以解决图像、视频、文本分类等多种重要的实际问题(Krizhevsky et al., 2012; Hinton et al., 2012; Bahdanau et al., 2015)。然而,机器学习模型常常易受输入的对抗性操纵(Adversarial Manipulation) 而发生误分类(Dalvi et al., 2004)。尤其是,神经网络(Neural Networks) 及其他多类机器学习模型,在测试时仅需对输入做很小幅度的改动,便会表现出高度脆弱(Biggio et al., 2013; Szegedy et al., 2014; Goodfellow et al., 2014; Papernot et al., 2016b)。
问题可概括如下:设存在一个机器学习系统(Machine Learning System) M M M 与一个输入样本 C C C(记为干净样本(Clean Example) )。设 C C C 被系统正确分类,即 M ( C ) = y true M(C)=y_{\text{true}} M(C)=ytrue。则可以构造一个对抗样本(Adversarial Example) A A A,它在感知上与 C C C 难以区分,却会被错误分类,即 M ( A ) ≠ y true M(A)\neq y_{\text{true}} M(A)=ytrue。相较于加入随机噪声的样本(即便噪声幅度大得多),对抗扰动导致的样本被误分类的频率要高得多(Szegedy et al., 2014)。
对抗样本对实际的机器学习应用(Practical ML Applications) 构成潜在安全威胁。尤其是(Szegedy et al., 2014)显示,为模型 M 1 M_1 M1 设计的对抗样本,往往也会误导另一个模型 M 2 M_2 M2。这种可迁移性(Transferability) 意味着,无需访问目标模型,也可以生成对抗样本并发动误分类攻击。(Papernot et al., 2016a; Papernot et al., 2016b)在更真实的场景中演示了此类攻击。
然而,既有针对神经网络的对抗样本研究,普遍采用一种威胁模型:攻击者可以将输入直接提供给模型。在此之前,并不清楚当在物理世界(Physical World) 中构造对抗样本,并通过相机(Camera) 观测时,这些样本是否仍会被误分类。
上述威胁模型可覆盖某些完全在计算机内部展开的攻击场景(如规避垃圾邮件过滤器(Spam Filters) 或恶意软件检测器(Malware Detectors) ,Biggio et al., 2013; Nelson et al. )。但许多实际的机器学习系统运行在物理世界中,如借助相机与传感器感知世界的机器人(Robots) 、视频监控系统(Video Surveillance Systems) 、以及面向图像或声音分类的移动应用(Mobile Apps) 。在这些场景中,攻击者无法依赖对输入数据进行逐像素(Per-Pixel) 的细粒度修改。由此产生了一个问题:当系统通过各种传感器(而非数字表示)获取数据时,是否仍能构造对抗样本并发动攻击?
此前也有工作讨论了针对机器学习系统的物理攻击,但并非通过对输入施加极小扰动以欺骗神经网络(Neural Networks) 。例如,Carlini et al. (2016) 展示一种攻击,可创建被手机(Mobile Phones) 识别为可懂语音指令但对人类而言晦涩难辨的音频输入。基于照片的人脸识别系统也易受重放攻击(Replay Attacks) 影响,即以授权用户的预存图像替代真实人脸来欺骗相机(Smith et al., 2015)。原则上,对抗样本也可应用于这些物理域:对于语音指令(Voice Command) ,一个对抗样本可能是一段对人类听来无害(如歌曲)但包含被算法识别的语音指令的录音;对人脸识别(Face Recognition) ,对抗样本可能是在面部施加极其细微的标记,人类仍可正确识别其身份,但机器学习系统将其识别为他人。与本文最相近的是Sharif et al. (2016) (该文公开晚于我们的工作,但更早投稿)。他们同样将对抗图像打印到纸上,并展示经拍摄后仍能欺骗图像识别系统。两者主要差异为:(1)我们在多数实验中采用廉价的闭式(Closed-Form) 攻击,而Sharif et al. (2016) 使用基于优化算法(Optimization Algorithm) 的更昂贵攻击;(2)我们不特别调整对抗样本以提升其经打印与摄影后存活的概率——我们只是科学地观察到,许多对抗样本在该流程中自然存活。Sharif et al. (2016) 则引入额外设计以促使其攻击在人脸识别(Face Recognition) 场景中尽可能奏效;(3)Sharif et al. (2016) 在可修改的像素数量上受限(仅眼镜框区域),但每个像素允许较大改动;我们则受限于对每个像素的改动幅度,但可以修改全部像素。
为检验对抗样本在物理世界中的存活程度,我们基于一个预训练(Pre-trained) 的ImageNet Inception分类器(Szegedy et al., 2015)开展实验。我们为该模型生成对抗样本,然后通过手机相机(Cell-Phone Camera) 将这些样本馈入分类器,并测量分类精度。该场景模拟了一个通过相机感知并随后进行图像分类(Image Classification) 的简化物理系统。我们发现,为原始模型生成的对抗样本中,有相当比例即便经由相机感知,仍然被错误分类。
令人意外的是,我们的攻击方法无需针对相机的存在做任何改动——最简单的做法(The Simplest Possible Attack) ,即直接使用为 Inception 模型制作的对抗样本,便可成功迁移(Transfer) 到“相机 + Inception”这一组合系统。因而,我们的结果为那些在构造对抗样本时显式建模相机、从而可能获得更高成功率的专门化攻击(Specialized Attacks) 提供了一个下界。
我们工作的一个限制是:假设攻击者完全了解模型结构与参数。这主要是为了在全部实验中统一使用单一的Inception v3 模型,而不必设计并训练不同的高性能模型。由于对抗样本的迁移性质(Transfer Property) ,我们的结果可平凡地扩展到攻击者无法获取模型描述的情形(Szegedy et al., 2014; Goodfellow et al., 2014; Papernot et al., 2016b)。虽未详尽研究物理对抗样本(Physical Adversarial Examples) 的迁移性,我们实现了一个简单的手机应用(Phone Application) 来演示在物理世界中的潜在黑盒攻击(Black-Box Attack) ,参见图1。
为更好理解相机导致的非平凡图像变换如何影响对抗样本的迁移性,我们进一步进行了若干实验,考察对抗样本在多种特定的合成图像变换(Synthetic Image Transformations) 下的表现。
本文结构如下:第2节回顾生成对抗样本的不同方法;第3节给出“物理世界(Physical World) ”实验设置与结果;第4节描述我们在各种人工图像变换(Artificial Image Transformations) 上的实验,以及这些变换对对抗样本的影响。
- 研究动机与背景:深度模型在数字域对微小扰动高度脆弱;既有工作多假设攻击者能直接向模型馈入像素级输入,但现实中大量系统通过相机/传感器获取数据,是否仍可被对抗样本欺骗尚未明晰。
- 核心问题:当输入需先经历物理成像(打印→拍照→裁剪等)这一非平凡变换后,针对数字图像生成的对抗样本能否“存活”并继续诱发误分类?
- 威胁模型差异:对比“数字直连”的白盒设置与“物理世界”设置;强调对抗样本的可迁移性(Transferability) 使得无需访问目标模型细节也可能发动黑盒攻击。
- 相关工作位置:区别于重放攻击、隐蔽语音指令等物理域安全研究;与同时期将扰动印制到可穿戴区域(如眼镜框)的工作形成互补,本文更关注低成本、闭式或迭代生成的通用图像扰动在物理链路中的存活性。
- 实验思路:选用 ImageNet 上的 Inception v3,先在数字域生成多种对抗图(快速法与迭代法等),再将其打印并用手机相机拍摄,最后送入同一分类器评估 top-1/top-5 精度与“破坏率”。
- 关键观察(预告) :无需专门建模相机,仅用为 Inception 构造的常规对抗图,经过“相机+Inception”的组合仍能触发显著误分类;简单攻击即可迁移到物理链路。
- 假设与适用性:实验以白盒为主以统一模型与复现实验;因迁移性存在,结论可自然延伸到黑盒场景,同时给出手机端应用演示以体现物理黑盒攻击的可行性。
- 进一步分析:为剖析相机链路中的影响因素,作者还在数字域施加合成变换(亮度/对比度、模糊、噪声、JPEG等)以量化不同扰动生成法的鲁棒性差异。
- 论文结构:方法综述(第2节)→物理打印-拍照实验与结果(第3节)→合成图像变换下的系统性评估(第4节)。
- 安全启示:物理对抗样本对实际部署的视觉系统构成现实威胁,提示需要面向传感器与成像链路的防御机制。

图1:黑盒攻击(Black Box Attack)在手机图像分类应用上的演示,使用物理对抗样本(Physical Adversarial Examples)。我们从数据集中选取一张干净图像(a),并用不同扰动幅度 ε 生成了对抗图像。随后打印干净与对抗图像,并使用 TensorFlow Camera Demo 应用对其进行分类。通过相机感知时,干净图像(b)被正确识别为“washer”,而对抗图像(c)、(d)被误分类。完整演示视频见 https://youtu.be/zQ_uMenoBCk 。
2 生成对抗图像的方法(Methods of Generating Adversarial Images)
本节描述我们在实验中使用的不同对抗样本(Adversarial Examples) 生成方法。需注意,这些方法均不保证生成的图像必然被误分类;尽管如此,我们仍将所有按此生成的图像称为“对抗图像”。
在全文中我们采用如下记号:
- X X X —— 一幅图像(Image) ,通常是一个三维张量(宽 × \times × 高 × \times × 通道)。本文假设像素取值为区间 [ 0 , 255 ] [0,255] [0,255] 上的整数。
- y true y_{\text{true}} ytrue —— 图像 X X X 的真实类别(True Class) 。
- J ( X , y ) J(X,y) J(X,y) —— 给定图像 X X X 与类别 y y y 的神经网络(Neural Network) 的交叉熵损失(Cross-Entropy Loss) 。我们有意省略损失中的网络权重(及其他参数) θ \theta θ,因为在本文情境中它们被视为固定(对应训练完成的模型)。对于带Softmax 输出层(Softmax Output Layer) 且使用交叉熵(Cross-Entropy) 的网络,作用于整型类别标签的交叉熵等于真实类别的负对数概率: J ( X , y ) = − log p ( y ∣ X ) J(X,y)=-\log p(y\mid X) J(X,y)=−logp(y∣X),这一关系将在下文使用。
- C l i p X , ε { ⋅ } \mathrm{Clip}_{X,\varepsilon}\{\cdot\} ClipX,ε{⋅} —— 对图像逐像素裁剪(逐元素裁剪(Per-Pixel Clipping) )的函数,使结果落在源图像 X X X 的** L ∞ L_\infty L∞** ε \varepsilon ε 邻域(**** L ∞ L_\infty L∞ ε \varepsilon ε -Neighborhood) 内。其精确形式为:
C l i p X , ε { X ′ } ( x , y , z ) = min { 255 , X ( x , y , z ) + ε , max { 0 , X ( x , y , z ) − ε , X ′ ( x , y , z ) } } \mathrm{Clip}_{X,\varepsilon}\{X'\}(x,y,z)=\min\!\big\{255,\;X(x,y,z)+\varepsilon,\;\max\!\big\{0,\;X(x,y,z)-\varepsilon,\;X'(x,y,z)\big\}\big\} ClipX,ε{X′}(x,y,z)=min{255,X(x,y,z)+ε,max{0,X(x,y,z)−ε,X′(x,y,z)}}
其中 X ( x , y , z ) X(x,y,z) X(x,y,z) 表示图像 X X X 在坐标 ( x , y ) (x,y) (x,y) 上通道 z z z 的取值。
关于 C l i p X , ε { ⋅ } \mathrm{Clip}_{X,\varepsilon}\{\cdot\} ClipX,ε{⋅}的理解,实际是为了使结果落在 [ X ( x , y , z ) − ε , X ( x , y , z ) + ε ] [\;X(x,y,z)-\varepsilon, \;X(x,y,z)+\varepsilon] [X(x,y,z)−ε,X(x,y,z)+ε]同时像素值满足在区间 [ 0 , 255 ] [0, 255] [0,255]的要求,公式先用 max { 0 , X ( x , y , z ) − ε , X ′ ( x , y , z ) } \;\max\!\big\{0,\;X(x,y,z)-\varepsilon,\;X'(x,y,z)\big\} max{0,X(x,y,z)−ε,X′(x,y,z)}保证不低于 0 且不低于 X ( x , y , z ) − ε \;X(x,y,z)-\varepsilon X(x,y,z)−ε,再用 min { 255 , X ( x , y , z ) + ε , max { 0 , X ( x , y , z ) − ε , X ′ ( x , y , z ) } } \min\!\big\{255,\;X(x,y,z)+\varepsilon,\;\max\!\big\{0,\;X(x,y,z)-\varepsilon,\;X'(x,y,z)\big\}\big\} min{255,X(x,y,z)+ε,max{0,X(x,y,z)−ε,X′(x,y,z)}}保证不高于 255 且不高于 X ( x , y , z ) − ε \;X(x,y,z)-\varepsilon X(x,y,z)−ε
2.1 快速方法(Fast Method)
一种极为简洁的生成对抗图像方法由(Goodfellow et al., 2014)提出,其动机是对损失函数线性化(Linearization) 并在 L ∞ L_\infty L∞ 约束下最大化损失。该问题可通过一次反向传播(Back-Propagation) 的代价求得闭式解:
X adv = X + ε s i g n ( ∇ X J ( X , y true ) ) X_{\text{adv}}=X+\varepsilon\;\mathrm{sign}\!\big(\nabla_X J(X,y_{\text{true}})\big) Xadv=X+εsign(∇XJ(X,ytrue))
其中 ε \varepsilon ε 为超参数。本文称此法为“快速(Fast) ”,因为其不需要迭代计算,速度远快于其他方法。
快速方法即之前学过的内容:ICLR 2015 对抗样本解释利用Adversial Examples ReadingNotes-CSDN博客
2.2 基本迭代方法(Basic Iterative Method)
我们提出对“快速方法(Fast Method) ”的直接扩展:以较小步长多次应用它,并在每步后对中间结果进行裁剪,使其留在源图像的 ε \varepsilon ε 邻域内:
X adv ( 0 ) = X , X adv ( N + 1 ) = C l i p X , ε { X adv ( N ) + α s i g n ( ∇ X J ( X adv ( N ) , y true ) ) } X^{(0)}_{\text{adv}}=X,\qquad X^{(N+1)}_{\text{adv}}=\mathrm{Clip}_{X,\varepsilon}\!\left\{X^{(N)}_{\text{adv}}+\alpha\;\mathrm{sign}\!\big(\nabla_X J(X^{(N)}_{\text{adv}},y_{\text{true}})\big)\right\} Xadv(0)=X,Xadv(N+1)=ClipX,ε{Xadv(N)+αsign(∇XJ(Xadv(N),ytrue))}
实验中取 α = 1 \alpha=1 α=1(即每步每像素仅改变 1 个灰度级)。迭代步数设为 min ( ε + 4 , 1.25 ε ) \min(\varepsilon+4,\;1.25\varepsilon) min(ε+4,1.25ε),该选择系经验性:足以让对抗样本到达ε最大范数球的边界,同时将计算成本保持在可控范围。下文称该法为“基本迭代(Basic Iterative) ”。
"****== ϵ \epsilon ϵ==最大范数球 "的含义:
- 在 L ∞ L_\infty L∞范数下,以原始图像 X X X为中心、半径为 ϵ \epsilon ϵ的"球"实际上是一个超立方体
- 这个"球"的边界是指所有满足 ∥ X a d v − X ∥ ∞ = ϵ \|X_{adv} - X\|_\infty = \epsilon ∥Xadv−X∥∞=ϵ的点
- 换句话说,就是至少有一个像素的修改幅度达到最大允许值 ϵ \epsilon ϵ的所有对抗样本
"****到达边缘 "的理解:
- 由于每次迭代步长为1,要让某个像素从0修改到 ϵ \epsilon ϵ,大约需要 ϵ \epsilon ϵ次迭代
- min ( ϵ + 4 , 1.25 ϵ ) \min(\epsilon + 4, 1.25\epsilon) min(ϵ+4,1.25ϵ)这个公式确保了算法有足够的迭代次数让对抗扰动"饱和"
- "饱和"意味着算法有机会将扰动推到约束边界,即让某些像素的修改幅度达到 ± ϵ \pm\epsilon ±ϵ的上下限
实际意义:
如果迭代次数太少,算法可能停留在约束区域内部,没有充分利用允许的扰动预算;如果迭代次数太多,则计算成本过高且收益递减。这个启发式选择平衡了攻击效果和计算效率。
2.3 最不可能类别的迭代方法(Iterative Least-Likely Class Method)
前述方法仅试图提升真实类别(Correct Class) 的损失,而未指定应被选择的错误类别(Incorrect Class) 。这在类别数较少且类别差异明显的数据集(如MNIST、CIFAR-10)上已足够。但在ImageNet 上,类别数量庞大且差异层级多样,此类方法可能产生“不够有趣”的误分类(例如将一种雪橇犬(Sled Dog) 误认为另一种雪橇犬)。为制造更“有趣”的错误,我们引入“最不可能类别(Least-Likely Class, LL) ”的迭代方法:令目标类别为网络对图像 X X X 预测中后验概率(Posterior Probability) 最小的类别
y L L = arg min y p ( y ∣ X ) . y_{\mathrm{LL}}=\arg\min_y\,p(y\mid X)\,. yLL=argyminp(y∣X).
对于训练良好的分类器,最不可能类别通常与真实类别差异极大,从而该攻击会产生更“离谱”的错误(例如把狗误认为飞机)。为使对抗图像被分类为 y L L y_{\mathrm{LL}} yLL,我们最大化 log p ( y L L ∣ X ) \log p(y_{\mathrm{LL}}\mid X) logp(yLL∣X),即沿
s i g n { ∇ X log p ( y L L ∣ X ) } \mathrm{sign}\{\nabla_X\log p(y_{\mathrm{LL}}\mid X)\} sign{∇Xlogp(yLL∣X)} 的方向迭代更新。对于采用交叉熵损失(Cross-Entropy Loss) 的网络,有
s i g n { ∇ X log p ( y L L ∣ X ) } = s i g n { − ∇ X J ( X , y L L ) } \mathrm{sign}\{\nabla_X\log p(y_{\mathrm{LL}}\mid X)\}=\mathrm{sign}\{-\nabla_X J(X,y_{\mathrm{LL}})\} sign{∇Xlogp(yLL∣X)}=sign{−∇XJ(X,yLL)}。因此迭代过程为:
X adv ( 0 ) = X , X adv ( N + 1 ) = C l i p X , ε { X adv ( N ) − α s i g n ( ∇ X J ( X adv ( N ) , y L L ) ) } X^{(0)}_{\text{adv}}=X,\qquad X^{(N+1)}_{\text{adv}}=\mathrm{Clip}_{X,\varepsilon}\!\left\{X^{(N)}_{\text{adv}}-\alpha\;\mathrm{sign}\!\big(\nabla_X J(X^{(N)}_{\text{adv}},y_{\mathrm{LL}})\big)\right\} Xadv(0)=X,Xadv(N+1)=ClipX,ε{Xadv(N)−αsign(∇XJ(Xadv(N),yLL))}
本方法与基本迭代(Basic Iterative) 在 α \alpha α 与迭代步数上取值一致。下文简称为“最不可能类别(Least-Likely, l.l. class) ”。
2.4 生成方法比较(Comparison of Methods of Generating Adversarial Examples)
如上所述,对抗图像并不保证必然被误分类——有时攻击者成功,有时模型成功。我们通过实验比较不同对抗生成方法(Adversarial Methods) ,以了解在生成图像上的实际分类精度以及各方法所利用的扰动类型。
实验在 ImageNet 验证集全部 50,000 张图像上进行,分类器为预训练(Pre-trained) 的 Inception v3(Szegedy et al., 2015; Russakovsky et al., 2014)。对每张验证图像,我们使用不同方法与不同 ε \varepsilon ε 生成对抗样本;对每一“方法– ε \varepsilon ε”组合,我们在全部 50,000 张图像上计算分类精度(Classification Accuracy) ;另外也在所有干净图像(Clean Images) 上计算精度作为基线。
图2 总结了不同方法在不同 ε \varepsilon ε 下的 top-1 / top-5 精度,并与“干净图像”作对比。更多生成样例见附录图4与图5。
如图2所示,快速方法(Fast) 即便在最小 ε \varepsilon ε 下,也将 top-1 精度降低约一半、top-5 降低约 40%。随着 ε \varepsilon ε 增大,快速方法生成样本的精度在 ε = 32 \varepsilon=32 ε=32 前大致持平,之后随 ε \varepsilon ε 增大缓慢降至接近 0。这可由其向每张图像添加与 ε \varepsilon ε 线性尺度相关的“噪声”来解释: ε \varepsilon ε 较大时本质上破坏了图像内容,使人类也难以辨认(见图5)。
相反,迭代方法(Iterative Methods) 利用更精细的扰动,即使在较大 ε \varepsilon ε 下也不会破坏图像,但可在更高比例上迷惑分类器。在 ε < 48 \varepsilon<48 ε<48 时,基本迭代(Basic Iterative) 可产生更强的对抗样本,但当 ε \varepsilon ε 进一步增大时其性能难以继续提升。最不可能类别(l.l. class) 方法即使在较小 ε \varepsilon ε 下,也能破坏大多数图像的正确分类。
下文的所有实验我们将 ε \varepsilon ε 限制为 ≤ 16 \le 16 ≤16,因为此类扰动仅表现为小幅噪声(Small Noise) (若能察觉的话),同时上述对抗方法在该邻域内即可生成大量被误分类的样本。
第2节介绍了三种生成对抗样本的方法,主要内容总结如下:
符号定义与基础概念
- X X X:输入图像(3维张量,像素值范围[0,255])
- y t r u e y_{true} ytrue:图像的真实类别标签
- J ( X , y ) J(X,y) J(X,y):交叉熵损失函数,等于 − log p ( y ∣ X ) -\log p(y|X) −logp(y∣X)
- Clip X , ϵ { X ′ } \text{Clip}_{X,\epsilon}\{X'\} ClipX,ϵ{X′}:像素级裁剪函数,确保结果在原图像 X X X的 L ∞ L_\infty L∞邻域内
快速方法(Fast Method)
- 原理:通过线性化损失函数,求解 L ∞ L_\infty L∞约束下最大化损失的扰动
- 公式: X a d v = X + ϵ ⋅ sign ( ∇ X J ( X , y t r u e ) ) X_{adv} = X + \epsilon \cdot \text{sign}(\nabla_X J(X, y_{true})) Xadv=X+ϵ⋅sign(∇XJ(X,ytrue))
- 特点:只需一次反向传播,计算速度最快,不需要迭代过程
- 优势:计算效率高,适合大规模实验
基本迭代方法(Basic Iterative Method)
- 原理:快速方法的扩展,多次小步长应用并在每步后裁剪像素值
- 公式: X a d v N + 1 = Clip X , ϵ { X a d v N + α ⋅ sign ( ∇ X J ( X a d v N , y t r u e ) ) } X_{adv}^{N+1} = \text{Clip}_{X,\epsilon}\{X_{adv}^N + \alpha \cdot \text{sign}(\nabla_X J(X_{adv}^N, y_{true}))\} XadvN+1=ClipX,ϵ{XadvN+α⋅sign(∇XJ(XadvN,ytrue))}
- 参数设置:步长 α = 1 \alpha = 1 α=1,迭代次数 min ( ϵ + 4 , 1.25 ϵ ) \min(\epsilon + 4, 1.25\epsilon) min(ϵ+4,1.25ϵ)
- 目标:增大正确类别的损失,使模型对正确答案信心降低
迭代最不可能类方法(Iterative Least-Likely Class Method)
- 原理:针对特定目标类别进行攻击,选择最不可能的类别作为目标
- 目标选择: y L L = arg min y { p ( y ∣ X ) } y_{LL} = \arg\min_y \{p(y|X)\} yLL=argminy{p(y∣X)}(预测概率最小的类别)
- 公式: X a d v N + 1 = Clip X , ϵ { X a d v N − α ⋅ sign ( ∇ X J ( X a d v N , y L L ) ) } X_{adv}^{N+1} = \text{Clip}_{X,\epsilon}\{X_{adv}^N - \alpha \cdot \text{sign}(\nabla_X J(X_{adv}^N, y_{LL}))\} XadvN+1=ClipX,ϵ{XadvN−α⋅sign(∇XJ(XadvN,yLL))}
- 特点:使用负梯度方向,增大目标类别的预测概率,产生更有趣的错误分类
方法性能比较实验结果
- 实验设置:在ImageNet数据集50,000个验证样本上测试,使用预训练的Inception v3分类器
- 快速方法表现:在小 ϵ \epsilon ϵ值下显著降低分类准确性,但 ϵ \epsilon ϵ过大时会破坏图像内容
- 迭代方法优势:利用更精细的扰动,在较高 ϵ \epsilon ϵ下仍能保持图像质量并有效欺骗分类器
- 最不可能类方法效果:即使在相对较小的 ϵ \epsilon ϵ下也能破坏大部分图像的正确分类
- 参数选择原则:限制 ϵ ≤ 16 \epsilon \leq 16 ϵ≤16,确保扰动被感知为小噪声且能产生大量错误分类样本
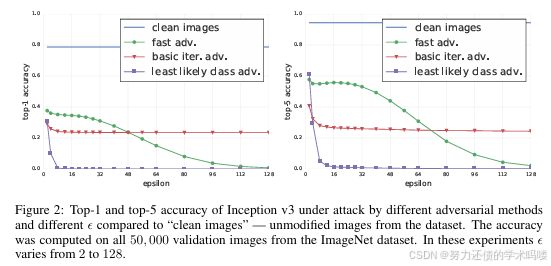
图2:在不同对抗方法与不同 ε \varepsilon ε 下 Inception v3 的 top-1 / top-5 精度,与“干净图像”对比。精度在 ImageNet 验证集全部 50,000 张图像上计算。 ε \varepsilon ε 自 2 变化至 128。
3 对抗样本的照片(Photos of Adversarial Examples)
3.1 对抗图像的破坏率(Destruction Rate of Adversarial Images)
为研究任意变换对对抗图像的影响,我们引入破坏率(Destruction Rate) :即经过某种图像变换(Image Transformation) 后,不再被误分类的对抗图像所占比例。形式化定义如下:
d = ∑ k = 1 n C ( X k , y true k ) C ( X adv k , y true k ) C ( T ( X adv k ) , y true k ) ∑ k = 1 n C ( X k , y true k ) C ( X adv k , y true k ) d=\frac{\sum_{k=1}^{n}\;C\!\big(X^{k},y^{k}_{\text{true}}\big)\;C\!\big(X^{k}_{\text{adv}},y^{k}_{\text{true}}\big)\;C\!\big(T(X^{k}_{\text{adv}}),y^{k}_{\text{true}}\big)}{\sum_{k=1}^{n}\;C\!\big(X^{k},y^{k}_{\text{true}}\big)\;C\!\big(X^{k}_{\text{adv}},y^{k}_{\text{true}}\big)} d=∑k=1nC(Xk,ytruek)C(Xadvk,ytruek)∑k=1nC(Xk,ytruek)C(Xadvk,ytruek)C(T(Xadvk),ytruek)
其中 n n n 为用于估计破坏率的图像数量, X k X^k Xk 为数据集中的图像, y true k y^k_{\text{true}} ytruek 为其真实类别, X adv k X^k_{\text{adv}} Xadvk 为对应的对抗图像。 T ( ⋅ ) T(\cdot) T(⋅) 是任意图像变换——本文研究包括打印+拍照(Printing & Photographing) 在内的多种变换。 C ( X , y ) C(X,y) C(X,y) 是指示函数(Indicator Function) ,表示图像是否被正确分类:
C ( X , y ) = { 1 , 若 X 被分类为 y ; 0 , 否则。 C(X,y)= \begin{cases} 1,& \text{若 }X\text{ 被分类为 }y;\\ 0,& \text{否则。} \end{cases} C(X,y)={1,0,若 X 被分类为 y;否则。
其二值取反(Binary Negation) 记作 C ‾ ( X , y ) \overline{C}(X,y) C(X,y),且满足 C ‾ ( X , y ) = 1 − C ( X , y ) \overline{C}(X,y)=1-C(X,y) C(X,y)=1−C(X,y)。
破坏率(Destruction Rate)公式解析
破坏率公式为:
d = ∑ k = 1 n C ( X k , y t r u e k ) ‾ C ( X a d v k , y t r u e k ) C ( T ( X a d v k ) , y t r u e k ) ∑ k = 1 n C ( X k , y t r u e k ) ‾ C ( X a d v k , y t r u e k ) d = \frac{\sum_{k=1}^n \overline{C(X^k, y^k_{true})} C(X^k_{adv}, y^k_{true}) C(T(X^k_{adv}), y^k_{true})}{\sum_{k=1}^n \overline{C(X^k, y^k_{true})} C(X^k_{adv}, y^k_{true})} d=∑k=1nC(Xk,ytruek)C(Xadvk,ytruek)∑k=1nC(Xk,ytruek)C(Xadvk,ytruek)C(T(Xadvk),ytruek)
核心概念理解
- 破坏率定义:经过变换后不再被错误分类的对抗图像的比例
- 指示函数: C ( X , y ) = 1 C(X,y) = 1 C(X,y)=1(图像 X X X被分类为 y y y), C ( X , y ) = 0 C(X,y) = 0 C(X,y)=0(否则)
- 否定函数: C ( X , y ) ‾ = 1 − C ( X , y ) \overline{C(X,y)} = 1 - C(X,y) C(X,y)=1−C(X,y),表示图像 X X X没有被分类为 y y y
公式各部分含义
分子: ∑ k = 1 n C ( X k , y t r u e k ) ‾ C ( X a d v k , y t r u e k ) C ( T ( X a d v k ) , y t r u e k ) \sum_{k=1}^n \overline{C(X^k, y^k_{true})} C(X^k_{adv}, y^k_{true}) C(T(X^k_{adv}), y^k_{true}) ∑k=1nC(Xk,ytruek)C(Xadvk,ytruek)C(T(Xadvk),ytruek)
- C ( X k , y t r u e k ) ‾ \overline{C(X^k, y^k_{true})} C(Xk,ytruek):原始图像被错误分类(确保我们考虑的是本来就被错分的情况)
- C ( X a d v k , y t r u e k ) C(X^k_{adv}, y^k_{true}) C(Xadvk,ytruek):对抗图像被错误分类(攻击成功)
- C ( T ( X a d v k ) , y t r u e k ) C(T(X^k_{adv}), y^k_{true}) C(T(Xadvk),ytruek):变换后的对抗图像被正确分类(攻击被破坏)
- 三项乘积为1:表示"原本攻击成功,但变换后攻击失败"的样本
分母: ∑ k = 1 n C ( X k , y t r u e k ) ‾ C ( X a d v k , y t r u e k ) \sum_{k=1}^n \overline{C(X^k, y^k_{true})} C(X^k_{adv}, y^k_{true}) ∑k=1nC(Xk,ytruek)C(Xadvk,ytruek)
- 表示所有"攻击成功的对抗样本"总数
- 即变换前确实被错误分类的对抗样本数量
实际计算逻辑
假设有100个对抗样本:
- 其中80个在变换前攻击成功(被错误分类)
- 变换后,这80个中有30个变为正确分类(攻击被破坏)
- 则破坏率 = 30/80 = 37.5%
物理意义
- 破坏率 = 0:所有对抗样本在变换后仍保持错误分类(变换对攻击无影响)
- 破坏率 = 1:所有对抗样本在变换后都被正确分类(变换完全破坏了攻击)
- 破坏率越高:表示该变换越能有效破坏对抗攻击的效果
这个指标帮助研究者量化不同变换(如打印拍照、模糊、噪声等)对对抗样本鲁棒性的影响程度。
3.2 实验设置(Experimental Setup)
为探索物理对抗样本(Physical Adversarial Examples) 的可能性,我们开展了一系列“对抗图像的照片(Photos of Adversarial Examples) ”实验:将干净与对抗图像打印在纸上,拍照,再从照片中裁剪出各图像。可将其视为一种黑盒变换(Black-Box Transformation) ,我们称之为“照片变换(Photo Transformation) ”。
我们在照片变换前后,分别对干净与对抗图像计算精度,并计算对抗图像的破坏率。
实验流程如下:
- 打印(Printing) (见图3(a) )。为减少人工操作,每页纸上打印多对“干净–对抗”样本;在纸张四角打印 QR 码(QR Codes) 以便自动裁剪。
(a)所有打印页源图被保存为无损 PNG(Lossless PNG) 。
(b)使用 ImageMagick convert 工具以默认设置将一批 PNG 转为多页 PDF(Multi-page PDF) :convert *.png output.pdf
(c)使用 Ricoh MP C5503 办公打印机打印生成的 PDF;每页按默认缩放充满整页;打印分辨率设为 600 dpi。 - 拍照(Photography) :使用 Nexus 5x 手机相机拍摄打印页(见图3(b) )。
- 自动裁剪与透视矫正(Auto Cropping & Perspective Warp) (见图3© ):
(a)检测图片四角 QR 码 的位置与内容(编码当前批次索引)。若任一角检测失败,则丢弃整张照片(不计入精度)。在任一实验中丢弃比例不超过 10%,通常为 3%–6%。
(b)通过透视变换(Perspective Transform) 将 QR 角点映射到预定义坐标。
(c)透视矫正完成后,各样本位置已知,据此裁剪出与源图同尺寸的正方形图像。 - 在变换前与变换后的图像上分别运行分类器,计算精度与对抗图像破坏率。
拍照过程为人工手持完成:不刻意控制光照、相机角度或与纸面的距离——此举是有意为之,用以引入烦扰性变化(Nuisance Variability) ,以破坏那些依赖细微像素级协同的对抗扰动。我们也未刻意选择极端角度或光照;照片均在一般室内光照下、基本正对纸面拍摄。
针对每种“对抗方法– ε \varepsilon ε”组合,我们开展两类实验:
- 平均情形(Average Case) :随机选择 102 102 102 张图像。此实验估计在“世界随机给定图像、攻击者尝试使其被误分类”的情形下,攻击者成功的频率。
- 预筛选情形(Prefiltered Case) :更激进的攻击设定。我们选择 102 102 102 张图像,使得(数字形态下)所有干净图像均被正确分类,而所有对抗图像(在照片变换之前)均被错误分类(top-1 与 top-5 均错),且最大预测概率满足 p ( y pred ∣ X ) ≥ 0.8 p(y_{\text{pred}}\mid X)\ge 0.8 p(ypred∣X)≥0.8。这模拟“攻击者可挑选原始图像”的场景:在我们的威胁模型中,攻击者可访问模型参数与结构,因此总能先离线推断,筛选出在“未拍照”条件下就会成功的攻击,再交由受害者对该物理对象进行拍照,照片变换可能保留或摧毁该攻击。
Top-1分类:模型预测的最高概率类别是否为正确答案
Top-5分类:正确答案是否在模型预测的前5个最高概率类别中

3.3 照片对抗图的实验结果(Experimental Results on Photos of Adversarial Images)
“照片变换”实验结果汇总见表1、表2、表3。
我们发现,相比迭代方法,快速方法(Fast) 生成的对抗图像对照片变换更鲁棒(More Robust) 。这可能是因为迭代方法利用了更细微的扰动,而这些细微扰动更易在照片变换中被破坏。
一个出乎意料的现象是:在某些情形下,预筛选情形(Prefiltered Case) 的破坏率高于平均情形(Average Case) 。尤其对于迭代方法,甚至出现“预筛选的总体成功率低于随机选图”的情况。这暗示:为获得极高置信度,迭代方法常会形成对细微协同依存的扰动,而这些协同在照片变换中不易存活(Fail to Survive) 。
总体而言,结果表明:在经历非平凡变换(即照片变换)后,仍有相当一部分对抗样本保持被误分类。这证明了物理对抗样本(Physical Adversarial Examples) 的可能性。举例来说,攻击者采用快速方法(Fast) 且 ε = 16 \varepsilon=16 ε=16 时,可期望约 2/3 的图像在 top-1 上被误分类、约 1/3 在 top-5 上被误分类。因而,只要生成足够多的对抗图像,攻击者即可造成远超过自然输入所致的误分类数量。
1. 扰动特性的差异
快速方法:
- 使用单步梯度符号方法(FGSM)
- 在每个像素上添加均匀的 ±ε 扰动
- 扰动模式相对粗糙但一致
- 类似于在整个图像上添加结构化噪声
迭代方法:
- 通过多步优化精细调整每个像素
- 产生更细微、更精确的扰动
- 扰动经过精心设计,刚好能欺骗模型
2. 为什么快速方法反而更鲁棒?
这看似反直觉,但实际上很合理:
细微扰动的脆弱性:
- 迭代方法产生的扰动依赖于像素级别的精确配合
- 这种精细的协同作用(co-adaptation)很容易被破坏
- 打印、拍照过程中的任何小变化都可能打破这种平衡
快速方法扰动的鲁棒性:
- 快速方法的扰动更像是全局性的、方向性的偏移
- 不依赖精确的像素值
- 即使经过物理变换产生一些退化,主要的扰动方向仍能保持
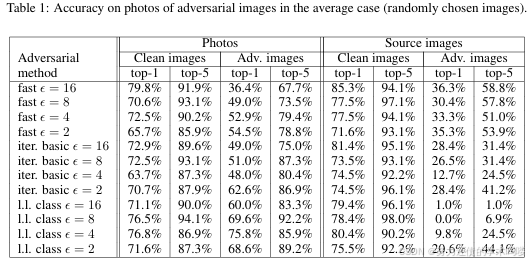
表1:平均情形(Average Case) 下,对抗图像照片的分类精度。对比“源图像(数字形态)”与“照片(物理变换后)”,分别给出对抗图像与干净图像的 top-1 / top-5 精度。
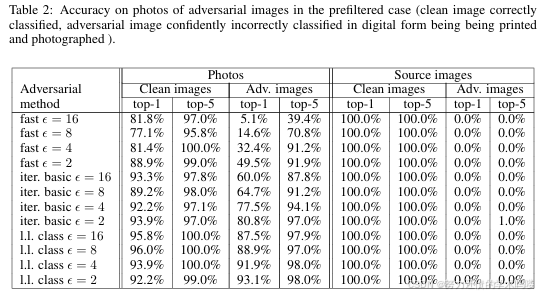
表2:预筛选情形(Prefiltered Case) 下,对抗图像照片的分类精度(前提:在打印与拍照前,干净图像被正确分类、对抗图像以高置信度被错误分类)。
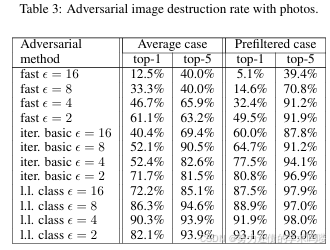
表3:照片变换(Photo Transformation) 下的对抗图像破坏率(Destruction Rate) (top-1 / top-5)。
3.4 物理世界中的黑盒攻击演示(Demonstration of Black-Box Adversarial Attack in the Physical World)
上述实验基于攻击者可完全访问模型(已知结构、权重等)的假设。然而,在很多安全威胁中更现实的是黑盒(Black Box) 场景:攻击者无法访问模型。鉴于对抗样本常可在模型间迁移(Szegedy et al., 2014; Papernot et al., 2016a),它们亦可用于黑盒攻击。我们演示了:为某一模型构造的物理对抗样本(Physical Adversarial Examples) 可以欺骗与之不同的模型。具体地,我们展示了其可欺骗开源的 TensorFlow camera demo(移动端图像分类(Image Classification) 应用)。我们将打印的干净与对抗图像展示给该 App,观察到从真实标签到错误标签的分类变化。演示视频见 https://youtu.be/zQ_uMenoBCk;我们亦在 GeekPwn 2016 现场演示了该效果。
4 人工图像变换(Artificial Image Transformations)
打印–拍照–裁剪这一流程,可视为若干更简单图像变换(Image Transformations) 的组合。为更好理解其中机理,我们测量了对抗图像在人工变换(Artificial Transformations) 下的破坏率。我们考虑以下变换:对比度与亮度变化(Contrast/Brightness Changes) 、高斯模糊(Gaussian Blur) 、高斯噪声(Gaussian Noise) 与 JPEG 编码(JPEG Encoding) 。
在这组实验中,我们从验证集中随机选取 1,000 张图像(单次抽样,后续各实验均使用这同一子集)。对每一“对抗方法–变换”组合,我们先生成对抗样本,再施加变换,随后按式(6)计算破坏率(Destruction Rate) 。
在 ε = 16 \varepsilon=16 ε=16 下,不同变换与方法的详细结果见附录的图6。可得到如下总体观察:
- 由快速方法(Fast) 生成的对抗样本对变换最鲁棒;由最不可能类别(l.l. class) 生成的样本最不鲁棒。这与“照片变换”的结论一致。
- top-5 破坏率通常高于 top-1。原因在于:要“摧毁”一个 top-5 级的对抗样本,仅需使真实标签进入 top-5;而要“摧毁” top-1 级的对抗样本,则必须将真实标签推回至 top-1,这是更强的要求。
- 亮度/对比度变化(Brightness/Contrast Changes) 对对抗样本影响较小:对快速与基本迭代方法的破坏率 < 5 % <5\% <5%,对最不可能类别方法也 < 20 % <20\% <20%。
- 模糊(Blur) 、噪声(Noise) 与 JPEG 编码的破坏率更高:对迭代方法(Iterative Methods) 可达 80 % 80\% 80%– 90 % 90\% 90%。然而,没有任何一种变换可将破坏率提升到 100%,这与“照片变换”实验一致。
实验目的
为了更好地理解物理变换(打印+拍照)对对抗样本的影响机制,作者通过一系列人工图像变换实验来分解和分析这个复杂过程。测试的变换类型
- 亮度变化(Brightness change)
- 对比度变化(Contrast change)
- 高斯模糊(Gaussian blur)
- 高斯噪声(Gaussian noise)
- JPEG编码(JPEG encoding)
主要发现
1. 方法鲁棒性排序
- Fast方法生成的对抗样本最鲁棒
- Basic iterative方法次之
- Iterative least-likely class方法最脆弱
这与照片变换实验的结果一致2. Top-1 vs Top-5破坏率
- Top-5破坏率通常高于Top-1破坏率
- 原因:破坏Top-5只需将正确类别推入前5名,而破坏Top-1需要将正确类别推到第1名,要求更严格
3. 不同变换的影响程度
影响较小的变换:
- 亮度和对比度变化对对抗样本影响很小
- Fast和basic iterative方法的破坏率 < 5%
- Least-likely class方法的破坏率 < 20%
影响较大的变换:
- 模糊、噪声和JPEG编码有更高的破坏率
- 对迭代方法的破坏率可达80-90%
- 但没有任何变换能100%破坏所有对抗样本
关键洞察
这些实验揭示了一个重要现象:简单粗暴的扰动(Fast方法)比精细优化的扰动(迭代方法)更能承受各种图像变换。这解释了为什么在物理世界中,看似"不够优化"的攻击方法反而更实用。
与物理实验的呼应
人工变换实验的结果与第三节的物理世界实验高度一致,验证了对抗样本在物理世界中仍然有效的原因——即使经过多种降质变换,仍有相当比例的对抗扰动能够保持其攻击效果。
5 结论(Conclusion)
本文探究了针对运行于物理世界(Physical World) 的机器学习系统构造对抗样本(Adversarial Examples) 的可能性。我们使用手机相机(Cell-Phone Camera) 拍摄得到的图像作为 Inception v3 图像分类(Image Classification) 网络的输入。我们展示了:在此设置下,使用原始网络构造的对抗图像中,有相当比例即使通过相机馈入分类器,仍会被误分类。这一发现证明了物理对抗样本(Physical Adversarial Examples) 的可能性。未来工作包括:在纸面打印图像之外的其他物理对象上展示攻击;针对不同类型的机器学习系统(如强化学习智能体(Reinforcement Learning Agents) )开展攻击;在不可访问模型参数与结构的黑盒(Black Box) 条件下进行攻击(预计利用迁移性(Transferability) );以及在构造阶段显式建模物理变换(Physical Transformation) 以获得更高成功率。我们亦期望未来研究能提出有效的防御方法(Defenses) 来抵御此类攻击。
参考文献(References)
[1] Devlin et al., 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805.
[2] Brown et al., 2020. Language Models are Few-Shot Learners. arXiv:2005.14165.
[3] Dosovitskiy et al., 2020. Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(9):1734–1747.
[4] Liu et al., 2021b. Vision Transformers: Do They Really Work? arXiv:2105.13457.
[5] Krizhevsky et al., 2012. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems (NeurIPS).
[6] Hinton et al., 2012. Deep Neural Networks for Acoustic Modeling in Speech Recognition. IEEE Signal Processing Magazine, 29(6):82–97.
[7] Bahdanau et al., 2015. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the International Conference on Learning Representations (ICLR).
[8] Biggio et al., 2013. Evasion Attacks Against Machine Learning at Test Time. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security (CCS).
[9] Szegedy et al., 2014. Intriguing Properties of Neural Networks. In Proceedings of the 30th International Conference on Machine Learning (ICML).
[10] Goodfellow et al., 2014. Explaining and Harnessing Adversarial Examples. In Proceedings of the 3rd International Conference on Learning Representations (ICLR).
[11] Papernot et al., 2016b. The Limitations of Deep Learning in Adversarial Settings. In Proceedings of the 3rd Workshop on Security and Privacy in Machine Learning (SPML).
[12] Carlini et al., 2016. Hidden Voice Commands. In Proceedings of the 25th USENIX Security Symposium.
[13] Smith et al., 2015. Robust Physical-World Attacks on Deep Learning Models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[14] Sharif et al., 2016. Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security.
[15] Szegedy et al., 2015. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[16] Russakovsky et al., 2014. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision, 115(3):211–252.
[17] Papernot et al., 2016a. Transferability in Machine Learning: From Phenomena to Black-Box Attacks Using Adversarial Samples. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy.
[18] George et al., 2016. Fooling Deep Neural Networks. Evolving AI.
附录(Appendix)
附录包含以下图表:
- 图4展示了不同对抗方法生成的对抗样本示例。
- 图5展示了不同ε值下的对抗样本示例。
- 图6包含了各种图像变换下的对抗样本破坏率图表。

图4:不同对抗方法的比较,ε = 32。与快速方法相比,迭代方法生成的扰动更加精细。同时,迭代方法并不总是选择ε邻域边界上的点作为对抗样本。

图5:使用"快速"方法在不同扰动大小ε下生成的对抗扰动图像比较。上图是"洗衣机",下图是"仓鼠"。在这两种情况下,干净图像都被正确分类,而对抗图像在所有考虑的ε值下都被错误分类。
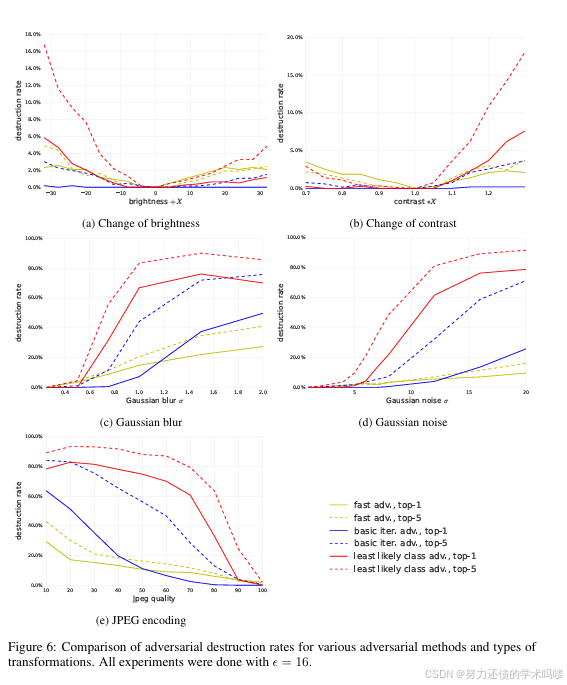
图6:不同对抗方法和变换类型的对抗破坏率比较。所有实验均使用ε = 16。
以上为学术翻译和精度注解,希望对您有所帮助

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)