当心学术不端!AI辅助写作的5条红线
经技术检测,这些论文均由大型语言模型(LLM)生成,且作者未按期刊规定在 “方法” 或 “声明” 部分披露 AI 工具的使用。现有AI工具在文献检索中存在"幻觉引用"缺陷,可能自动合成看似真实但实际不存在的论文信息,包括虚构的标题、作者、期刊卷期甚至DOI编码。AI生成内容的法律地位仍存在争议,其可能涉及训练数据的版权问题。由于AI模型的训练数据包含海量已有文献,其生成文本可能无意中复现特定段落的
2024年Springer Nature共发表了超过 482,000 篇文章,同时撤回了 2,923 篇文章。此次撤稿行动源于《神经外科评论》编辑部发现大量投稿存在异常特征:文本风格高度模板化、逻辑结构生硬、引用文献与主题关联性弱。经技术检测,这些论文均由大型语言模型(LLM)生成,且作者未按期刊规定在 “方法” 或 “声明” 部分披露 AI 工具的使用。
当科研效率提升与学术诚信防线产生碰撞,我们亟需明确AI写作工具的禁用场景与合规操作规范。
红线一:责任转嫁——禁止将AI列为作者或替代研究者决策
核心风险
-
将AI系统列为论文作者或依赖其生成研究结论,本质上是将学术责任转嫁给无法律主体资格的算法工具。
-
这种行为不仅违反科研诚信基本原则,更可能导致研究成果的可信度遭到永久性质疑。
合规操作
-
在致谢部分明确说明AI工具的使用范围(如语言润色、格式调整)
-
核心创新点、方法论设计与结论推导必须由研究者独立完成
-
建立AI使用日志制度,完整记录人机交互过程
红线二:文献伪造——杜绝AI生成虚假参考文献
潜在危机
现有AI工具在文献检索中存在"幻觉引用"缺陷,可能自动合成看似真实但实际不存在的论文信息,包括虚构的标题、作者、期刊卷期甚至DOI编码。此类行为等同于学术造假。
防御机制
实施文献三重验证:
1.通过权威数据库交叉核对文献元数据
2.逐篇确认引用内容与原文的实质性关联
3.追溯文献在学术脉络中的逻辑位置
优先选用经学术机构认证的智能检索工具
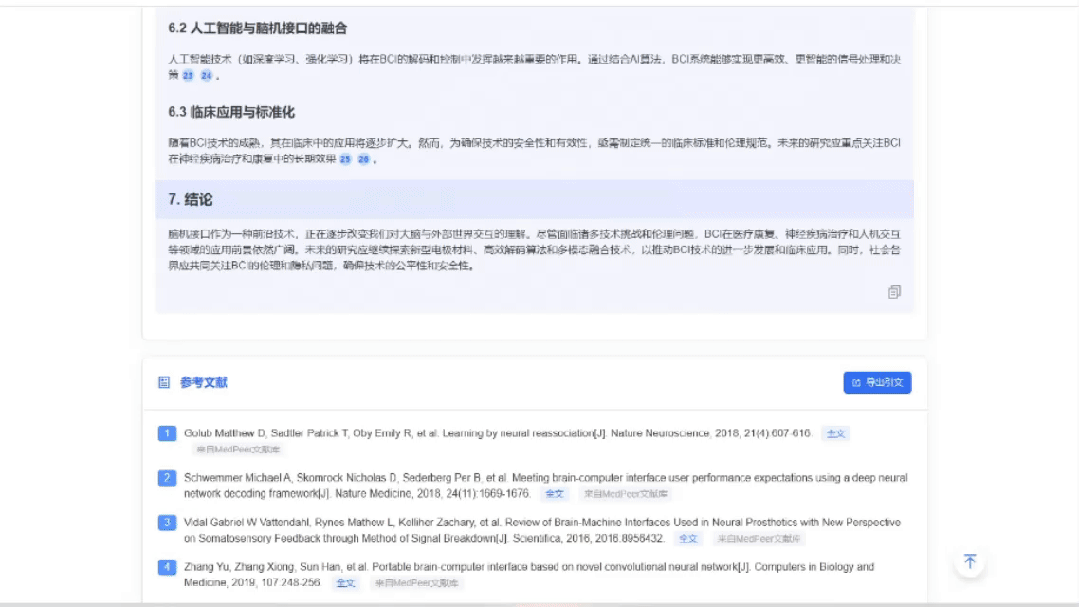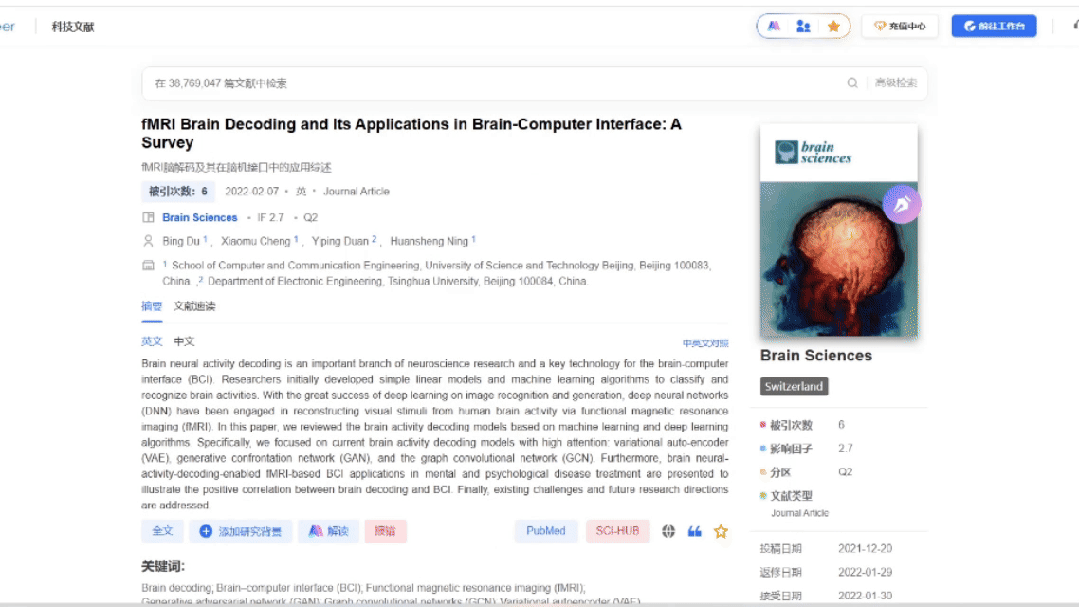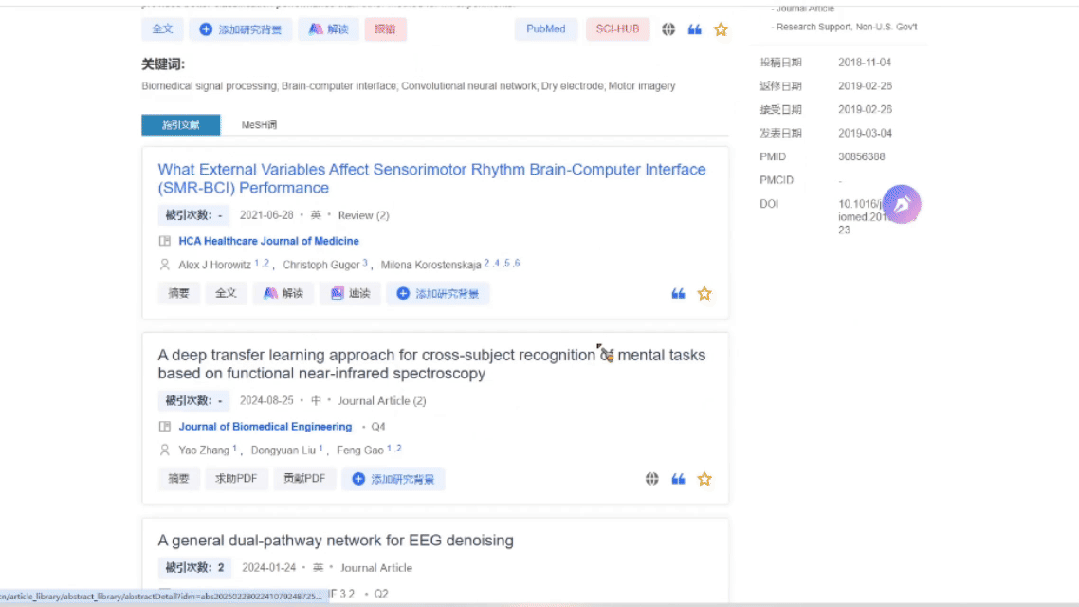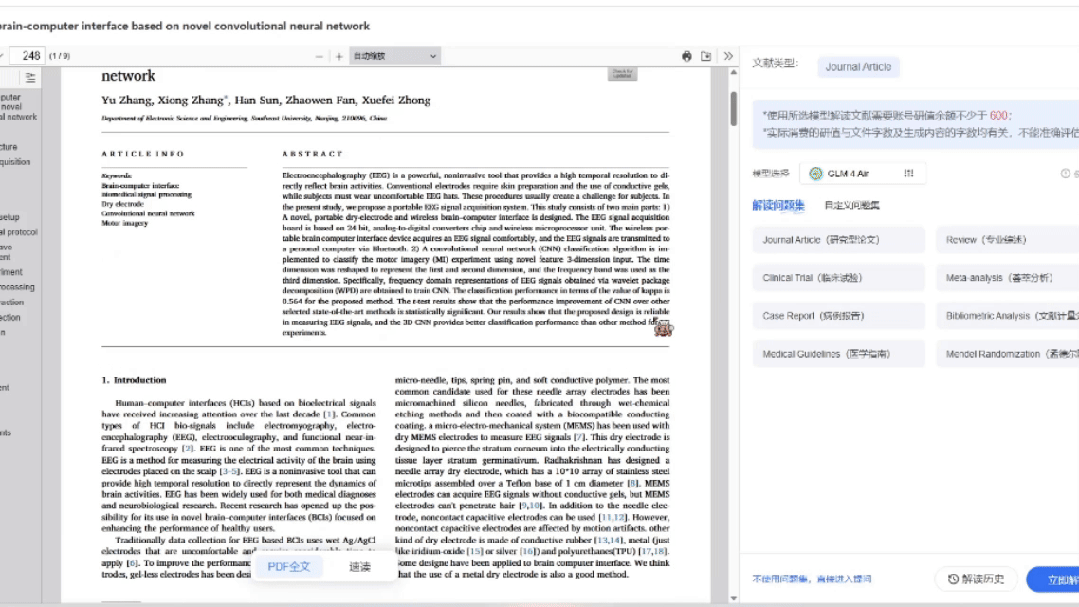
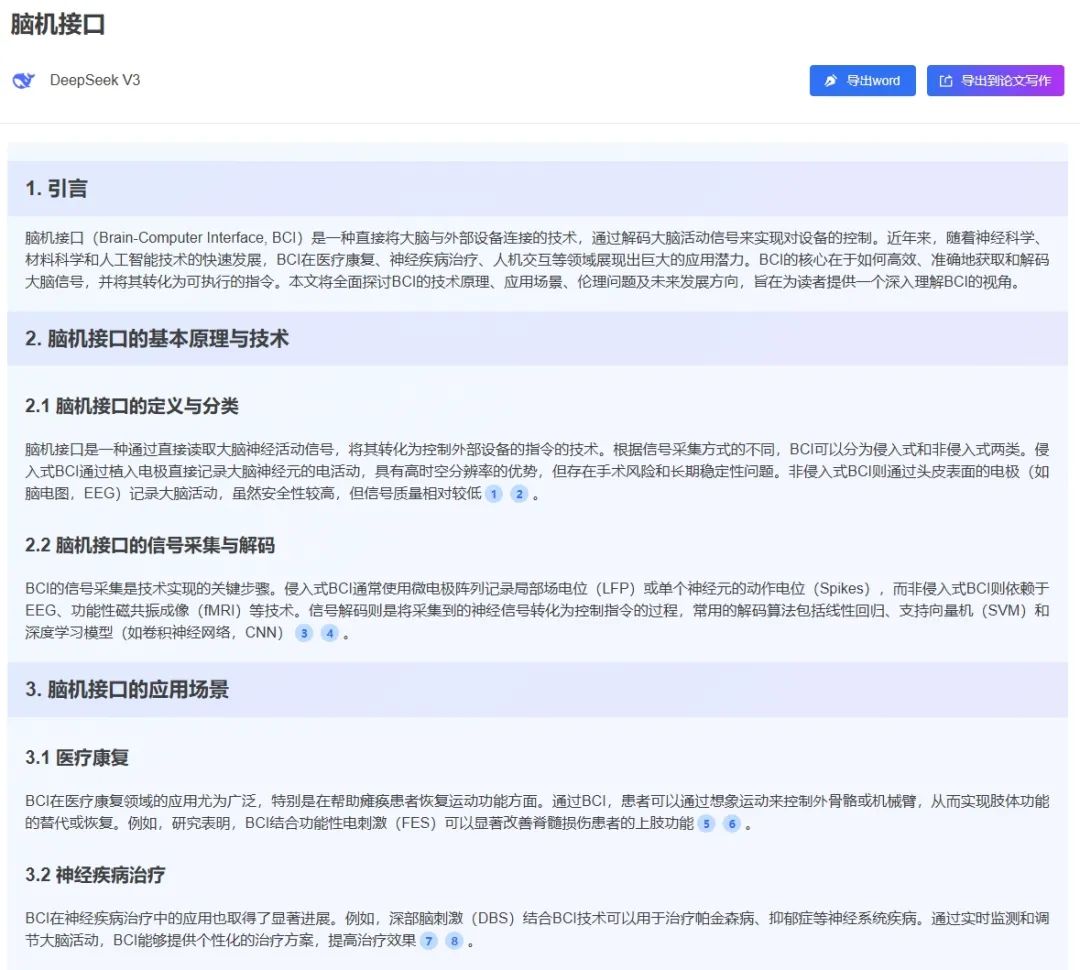
MedPeer的Deep Search检索工具,全新的智能文献检索方式,改变了科研人员的工作流
2.5亿文献库+AI精准定位
输入你的科学问题(比如"脑机接口"),系统会自动识别核心关键词并在2.5亿真实全学科文献库内进行检索;
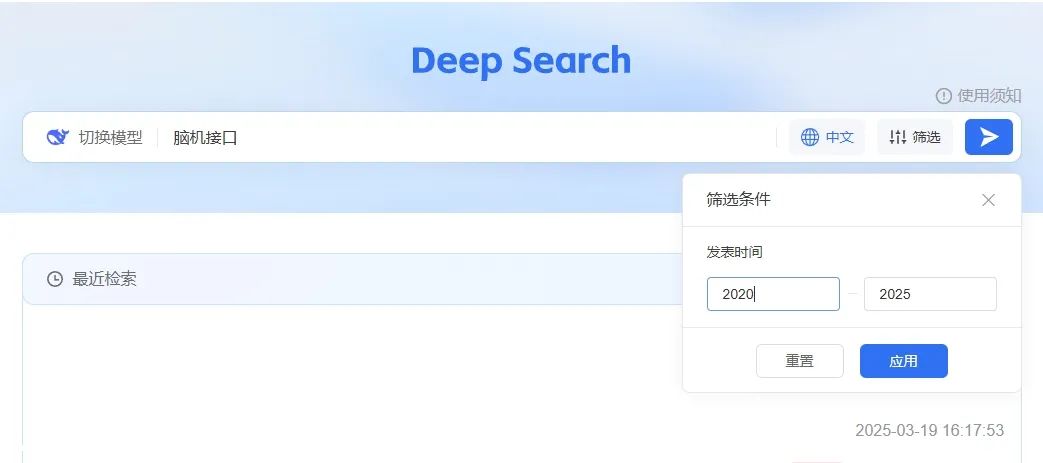
一键生成Mini综述
自动提炼研究现状/关键争议/未来方向,比人工阅读效率提升10倍 实测3分钟完成原本3天的工作量

直接获取全文
集成MedPeer自有文献库,大多数文献都可直接跳转下载全文
红线三:洗稿抄袭——防范AI引发的文本重复风险
客观困境
由于AI模型的训练数据包含海量已有文献,其生成文本可能无意中复现特定段落的核心表达,导致查重系统判定为潜在抄袭。
风险控制
对AI生成内容进行预查重检测(建议阈值≤15%)
执行深度文本重构:
替换非必要专业术语的同义表述
重组句式结构并补充原创性分析
增加领域前沿进展的关联性讨论
红线四:版权越界——确认AI内容的合法使用权限
法律边界
AI生成内容的法律地位仍存在争议,其可能涉及训练数据的版权问题。直接使用未经验证的生成内容,可能触发知识产权纠纷。
合规路径
商业性研究优先选择:
开源授权模型
机构采购的合规平台
在方法论章节声明AI内容的合法性审查流程
敏感数据使用隐私计算技术进行处理
红线五:审核缺失——建立AI内容双重验证体系
关键挑战
AI生成文本可能存在隐蔽的逻辑漏洞、事实错误或与实验数据矛盾,未经严格审查直接采用将导致研究质量系统性缺陷。
质量保障
技术审查:
采用逻辑一致性检测工具
关键数据执行逆向验证
人工审查:
组建跨学科核查小组
制定"主张-证据-推论"核查清单
使用AI写作工具,科研工作者需铭记:
1. 工具无善恶,责任在人类
2. 效率可提升,智识不可代劳
3. 红线即底线,越界即毁灭
唯有守住这五条红线,方能使AI真正成为推动学术进步的「加速器」,而非摧毁科研信誉的「粉碎机」。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)