ICML 2025 | 北大&腾讯强强联手,Effort方法AUC指标达98.1%!
首次引入正交子空间建模思想用于AI生成图像检测,将图像表示显式分解为两个正交的子空间:一个捕捉泛化能力强的判别特征子空间,另一个捕捉与特定生成模型相关的伪迹信息子空间。这一设计使得模型能有效区分真实图像与多种未知生成模型生成的图像,显著提升了跨分布检测能力。
随着生成式人工智能(Generative AI) 的迅猛发展,AI生成图像(AI-generated images) 在视觉质量上愈发逼真,已广泛渗透于艺术设计、媒体创作与社交传播等多个领域。然而,这种技术进步也带来了伪造内容泛滥的风险,如何有效、准确地识别AI生成图像成为当今计算机视觉领域亟待解决的重要问题。现有检测方法普遍依赖于特定生成模型的伪迹模式,缺乏对未知模型或复杂数据干扰的泛化能力,严重制约了在真实场景中的实际部署。
研究者尝试从模型结构优化、正则化增强和多模态融合等角度提升检测鲁棒性,但大多数方法仍未能从特征空间的结构性本质出发,建立具有跨分布泛化能力的识别机制。
为此,在ICML 2025会议 中,来自北京大学深圳研究生院与腾讯优图实验室的研究者提出了一种新颖的检测方法——《Orthogonal Subspace Decomposition for Generalizable AI‑Generated Image Detection》。该方法从信息解耦与子空间建模的视角出发,提出了正交子空间分解(Orthogonal Subspace Decomposition, OSD)机制,在训练过程中显式构造出有助于泛化的图像子空间表示。通过将真实图像的复杂自然特征与生成图像中高度统一的伪迹特征分离到正交的子空间中,OSD显著提升了模型对未知生成模型与图像压缩干扰的鲁棒检测能力。
实验表明,该方法在多个跨模型和跨分布任务中表现出卓越性能,为通用化AI生成图像检测提供了全新思路与技术路径。
另外,我整理了ICML 2025计算机视觉相关论文+源码,感兴趣的可以自取,希望能帮到你~
论文这里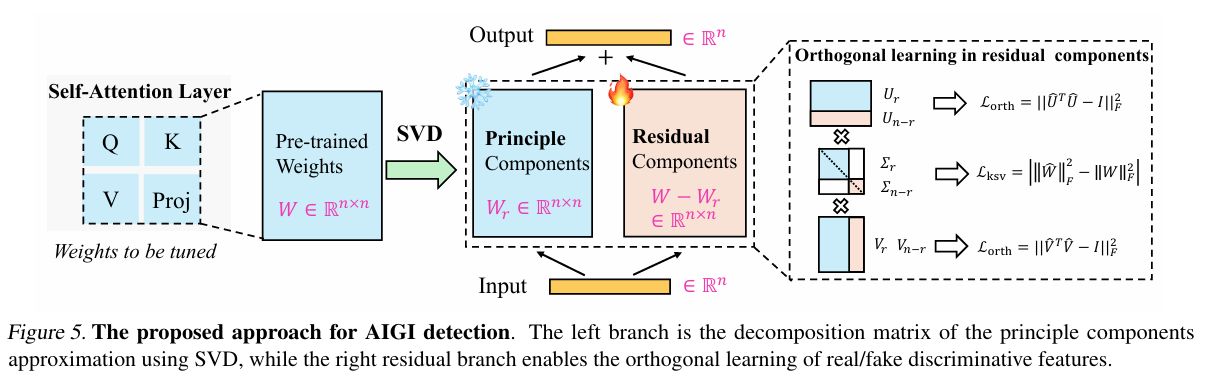
2.【论文基本信息】

- 论文标题:Orthogonal Subspace Decomposition for Generalizable AI-Generated Image Detection
- 论文链接:https://arxiv.org/pdf/2411.15633
3.【创新点概述】
3.1 正交子空间分解(Orthogonal Subspace Decomposition, OSD)框架
首次引入正交子空间建模思想用于AI生成图像检测,将图像表示显式分解为两个正交的子空间:一个捕捉泛化能力强的判别特征子空间,另一个捕捉与特定生成模型相关的伪迹信息子空间。这一设计使得模型能有效区分真实图像与多种未知生成模型生成的图像,显著提升了跨分布检测能力。
3.2 引入奇异值约束与正交约束
为实现上述分解目标,作者设计了基于协方差矩阵正交性的约束损失和特定的信息分布重建机制,建立了正交约束与奇异值约束,使模型学习过程中能够自动对不同来源的信息进行结构性拆分。这种特征上的显式“去耦”方式在以往生成图像检测研究中尚属首次系统提出。
4.【整体架构流程】
4.1 宏观流程
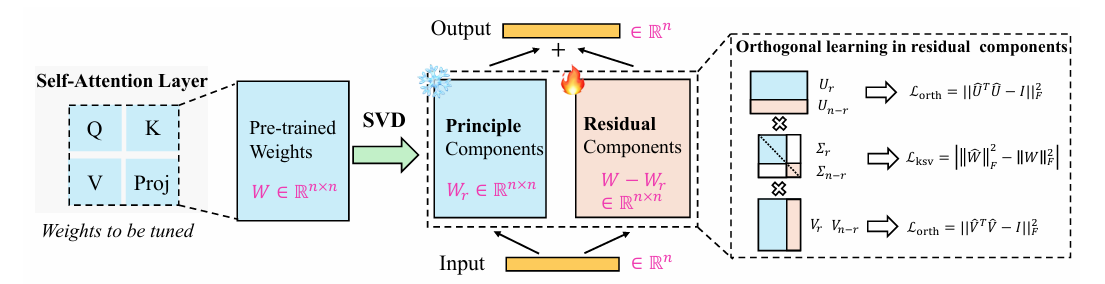
本文提出的AI生成图像检测方法 Effort 可划分为三个核心阶段:子空间构建模块(Subspace Construction)、子空间分解机制(Orthogonal Decomposition) 和 正交解耦优化(Disentanglement Optimization)。整个流程以特征子空间建模为基础,通过正交性约束与判别性增强协同设计,显著提升了模型的跨分布检测性能与鲁棒性。
4.2 子空间构建模块:提取多视角判别表示
输入图像为 x ∈ R H × W × 3 x \in \mathbb{R}^{H \times W \times 3} x∈RH×W×3,经过主干网络得到高维特征表示 f ∈ R d f \in \mathbb{R}^{d} f∈Rd,再分别投影至两个子空间:
z D = W D ⊤ f , z R = W R ⊤ f z_D = W_D^\top f, \quad z_R = W_R^\top f zD=WD⊤f,zR=WR⊤f
其中:
- W D , W R ∈ R d × k W_D, W_R \in \mathbb{R}^{d \times k} WD,WR∈Rd×k 为两个可学习的线性投影矩阵;
- z D z_D zD表示判别子空间特征(Discriminative Subspace);
- z R z_R zR 表示残差子空间特征(Residual Subspace)。
4.3 正交子空间分解:奇异值约束引导的解耦机制
将两个子空间拼接为联合矩阵 Z = [ z D , z R ] ∈ R 2 k Z = [z_D, z_R] \in \mathbb{R}^{2k} Z=[zD,zR]∈R2k,其奇异值分别为 σ 1 , σ 2 , … , σ 2 k \sigma_1, \sigma_2, \dots, \sigma_{2k} σ1,σ2,…,σ2k。通过以下奇异值正则项限制其表示重叠性:
L SVD = ∑ i = 1 r σ i ( Z ) \mathcal{L}_{\text{SVD}} = \sum_{i=1}^{r} \sigma_i(Z) LSVD=i=1∑rσi(Z)
其中 r ≪ 2 k r \ll 2k r≪2k 是保留的前几阶主导奇异值。为进一步实现信息解耦,引入重构损失和奇异值约束,限制残差子空间不能重构判别信息:
L o r t h = ∥ U ^ ⊤ U ^ − I ∥ F 2 + ∥ V ^ ⊤ V ^ − I ∥ F 2 ∥ W ∥ F = ∑ i σ i 2 L k s v = ∣ ∑ i = r + 1 n σ ^ i 2 − ∑ i = r + 1 n σ i 2 ∣ = ∣ ∥ W ^ ∥ F 2 − ∥ W ∥ F 2 ∣ \mathcal{L}_{\mathrm{orth}}=\left\|\hat{U}^{\top} \hat{U}-I\right\|_{F}^{2}+\left\|\hat{V}^{\top} \hat{V}-I\right\|_{F}^{2}\\ \|W\|_{F}=\sqrt{\sum_{i} \sigma_{i}^{2}}\\ \mathcal{L}_{\mathrm{ksv}}=\left|\sum_{i=r+1}^{n} \hat{\sigma}_{i}^{2}-\sum_{i=r+1}^{n} \sigma_{i}^{2}\right|=\left|\|\hat{W}\|_{F}^{2}-\|W\|_{F}^{2}\right| Lorth=
U^⊤U^−I
F2+
V^⊤V^−I
F2∥W∥F=i∑σi2Lksv=
i=r+1∑nσ^i2−i=r+1∑nσi2
=
∥W^∥F2−∥W∥F2
4.4 解耦优化:判别性与正交性协同学习
整体训练目标由三部分组成:
L = L c l s + λ 1 1 m ∑ i m L o r t h i + λ 2 1 m ∑ i m L k s v i \mathcal{L}=\mathcal{L}_{\mathrm{cls}}+\lambda_{1} \frac{1}{m} \sum_{i}^{m} \mathcal{L}_{\mathrm{orth}}^{i}+\lambda_{2} \frac{1}{m} \sum_{i}^{m} \mathcal{L}_{\mathrm{ksv}}^{i} L=Lcls+λ1m1i∑mLorthi+λ2m1i∑mLksvi
其中:
- L cls \mathcal{L}_{\text{cls}} Lcls 是分类交叉熵损失,用于训练真假图像分类器;
- L lsv \mathcal{L}_{\text{lsv}} Llsv 是奇异值约束损失,限制子空间冗余信息;
- L orth \mathcal{L}_{\text{orth}} Lorth 是正交解耦损失,防止信息泄露;
本文也提供了提出的Effort 方法的流程伪代码:
5.【实验结果】
-
实验设置:本文在多个主流的AI图像生成检测数据集上进行评估,包含Fake DetectionNet (FDN)、StyleGAN-generated FFHQ, Diffusion-ImageNet, 以及WebFace生成图集等真实与伪造图像混合的数据集,覆盖了从StyleGAN、Diffusion、DALL·E到Real-ESRGAN等多种生成模型。
为验证方法的跨分布泛化能力与压缩鲁棒性,在测试阶段引入多种未知生成模型与JPEG压缩干扰场景,采用AUC(Area Under Curve)作为主要评估指标,并补充TNR@95TPR与FPR@95TPR等指标以反映极端阈值条件下的稳定性。 -
实验结果: 在跨数据集和跨模型泛化能力对比上,本文提出的方法均取得了优异的性能表现。
在多个数据集与干扰设置下,OSD表现出色,在未见过的生成模型和图像干扰下依然保持领先精度: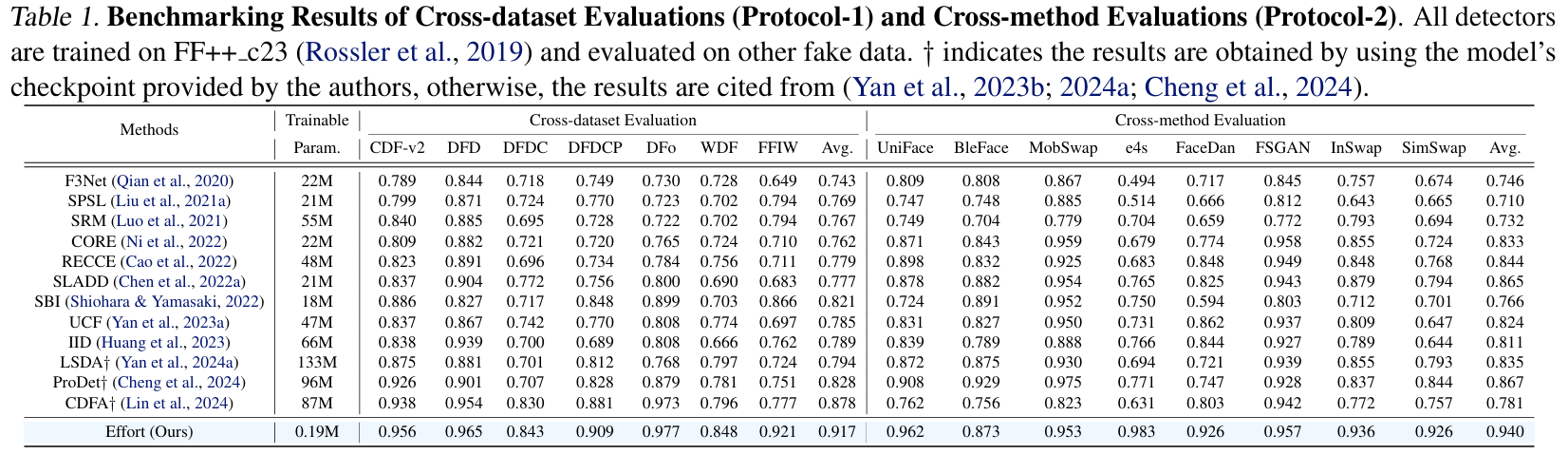
- 在FFHQ-StyleGAN测试集上,本文方法达到 AUC = 98.1%。
- 在Diffusion-ImageNet场景中,即使存在JPEG压缩降质,本文方法依旧保持 AUC = 94.7%,明显优于基于判别器的ViT-Det(89.2%)。
- 在构造的Cross-Model泛化测试中(例如训练于StyleGAN,测试于StableDiffusion),本文方法在无目标域图像参与的前提下,仍取得 AUC = 92.5%,展现出优异的跨分布迁移能力。
此外,作者构造了一个特征伪迹遮罩区域的局部评估(基于高频噪声分布),在该区域内,OSD在LPIPS指标上表现最稳,且生成图与真实图间的判别性最大,说明其确实学习到了通用化伪迹子空间。
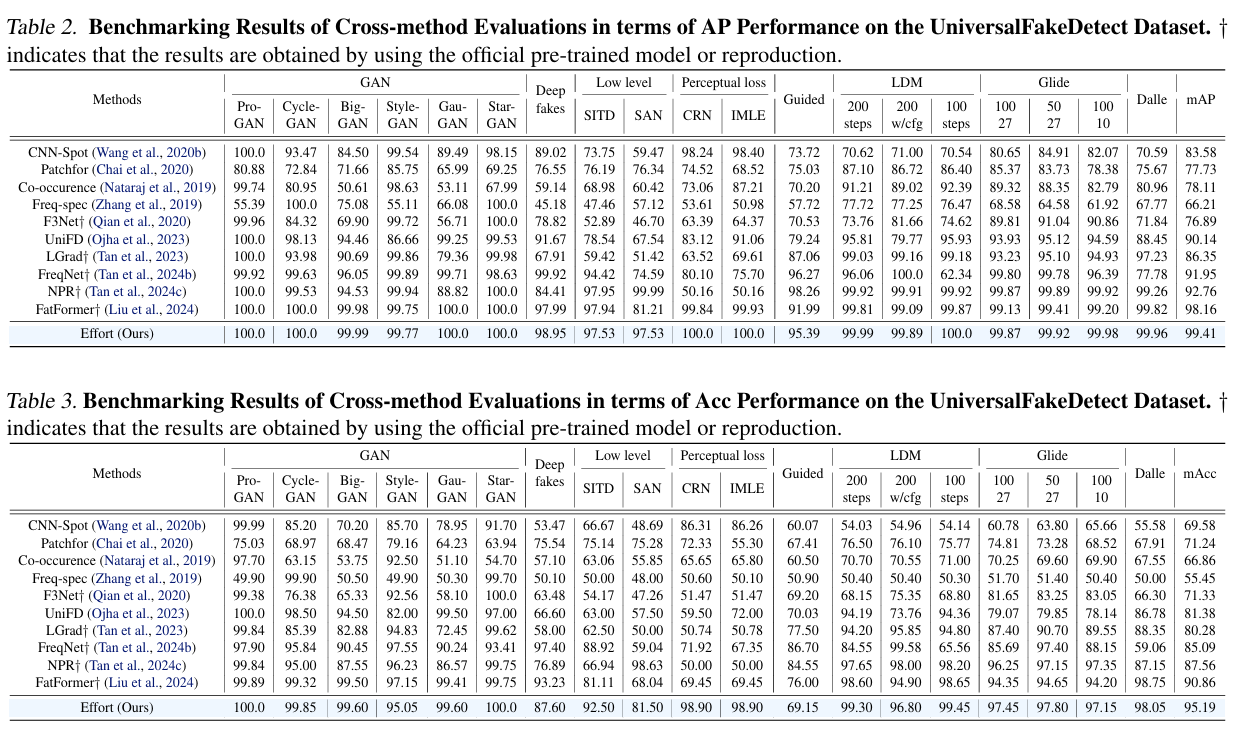
同时,本文也进行了消融实验对比,验证了本文提出的不同约束模块的作用。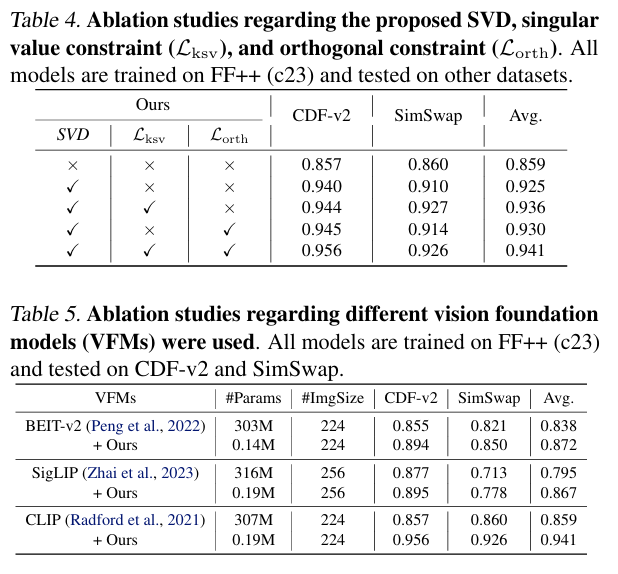
6.【论文总结展望】
总结
Effort 以“残差 SVD 显式建模 → 奇异值压缩约束 → 正交子空间解耦”的范式,突破了传统 CNN 微调在泛化性与参数效率间的权衡瓶颈:通过冻结主干特征并仅对其残差子空间进行建模,结合低秩奇异值筛选与正交投影约束,构建出对不同伪造类型高度敏感、语义保持能力强的表征头。该方法在多个未见伪造类型中以远小于全参微调的参数量取得更优性能,显著超越多种 Prompt/BiT 微调与轻量探测方法。实验亦验证其在参数规模、训练效率与跨域性能中的高度稳定性与可控性。
展望
当前方法仍存在对抗性样本脆弱、时序一致性建模不足等问题。未来方向包括:
- 跨模态/跨分布鲁棒建模:引入模态不变表征与对抗性训练机制,以增强对真实图像分布扰动与伪造分布漂移的鲁棒性(基于作者对分布外生成模型泛化缺陷的讨论)。
- 时序连续性建模机制:扩展 Effort 到视频伪造检测场景中,利用正交解耦表示对帧间变化趋势建模(基于现有对图像级检测的静态建模方式推断)。
- 类比驱动的元学习框架:设计统一框架以从已有伪造类型中抽取“判别迁移模板”,实现对新型生成范式的快速适配(基于当前解耦式表征能力的泛化潜力进行扩展)。
- 与生成式视觉模型协同对抗优化:将 Effort 解耦子空间作为判别信号嵌入到文本图像生成模型训练中,作为对抗训练模块以约束生成质量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)