AI 突进 70 年:从诞生到 GPT-5
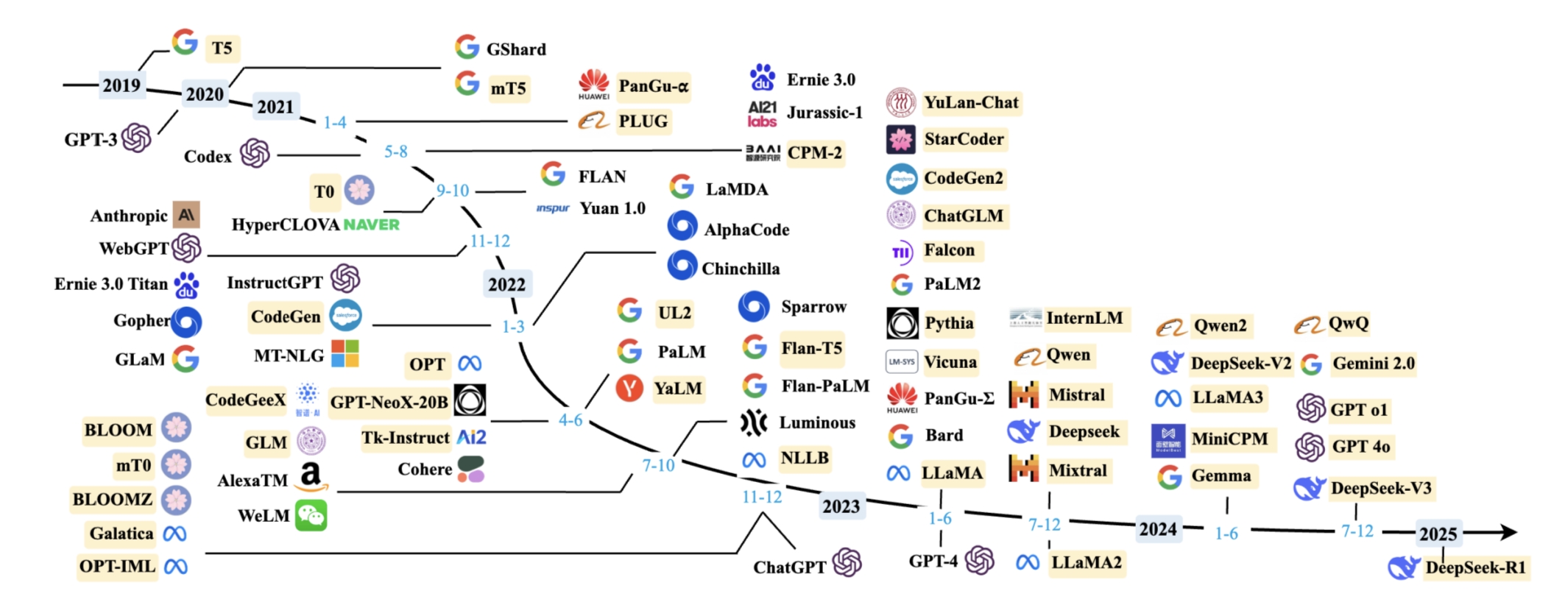
本文梳理人工智能 70年 发展脉络:1956年达特茅斯会议正式提出“人工智能”概念,开启探索之路。从早期基于规则的系统、统计机器学习,到2012年AlexNet推动深度学习崛起,再到2017年Transformer架构革新、AlphaGo引爆关注。2022年ChatGPT 开启大模型时代,GPT-3.5、GPT-4等持续迭代,2025年GPT-5 引入通用智能。同时涵盖技术分支(NLP、CV等)及
当 1956 年的科学家们写下 “人工智能” 时,不会想到 70 年后,GPT-5 正以智能洪流,漫过我们生活的每一条沟壑🛬
一、人工智能的诞生(1956)
人工智能(Artificial Intelligence, 简称 AI)概念于1956年正式提出。约翰・麦卡锡(John McCarthy)与其他科学家在美国达特茅斯学院组织的研讨会上,首次明确 “人工智能” 一词,标志着这门学科的诞生。作为一门年轻的科学,其发展至今不足70年
📌达特茅斯会议
与会者均为各自领域的开拓者,其贡献深刻影响了AI的发展轨迹
- 约翰·麦卡锡(John McCarthy)
- Lisp 编程语言的发明人之一,“人工智能”一词的提出者,主导了达特茅斯会议的组织
- 马文·明斯基(Marvin Minsky)
- 框架理论(AI知识表示核心理论)创立者,后期因对神经网络局限性的研究推动了领域反思,2016年获图灵奖
- 雷·索洛莫诺夫(Ray Solomonoff)
- 算法概率论创始人,提出“通用概率分布”与“通用归纳推理理论”,为AI的概率性推理奠定了数学基础
- 纳撒尼尔·罗切斯特(Nathaniel Rochester)
- IBM 701(早期商用计算机)首席设计师,编写世界首个汇编程序,推动计算机硬件与低级语言在AI研究中应用
- 克劳德·香农(Claude Shannon)
- 数学家、信息论创始人,其“信息熵”理论为AI处理不确定性、优化决策提供关键工具,被称为“数字时代奠基人”
- 奥利弗·塞弗里奇(Oliver Selfridge)
- “机器知觉之父”,提出的“ Pandemonium 模型”是早期计算机视觉与模式识别的重要框架
二、AI 的演进:从基于规则的系统到深度神经网络
1. 1950年: 图灵之问与感知机起源
- 计算机科学之父图灵在论文中提出“机器可以思考吗”这一划时代问题,推动了人类语言学与计算机科学的交融

- 20世纪50年代 深度学习的基础——神经网络技术起源,当时以“感知机”形式存在。早期为单层感知机,虽结构简单但能解决部分复杂问题,但其局限性显著:仅能学习线性可分函数,无法处理异或(XOR)等线性不可分问题
2. 1957~1980末:NLP 两派与网络技术突破
- 1957~1970年,自然语言处理(NLP)领域形成两大阵营:基于规则(人工编写语法 / 词汇规则,逻辑清晰但难适配复杂场景)与基于统计(通过数据训练模型,动态性强却依赖数据规模)
- 1969年 Marvin Minsky在著作《Perceptrons》中提出两个关键观点:
- 单层感知机作用有限,需多层感知机解决复杂问题
- 当时缺乏有效的训练算法
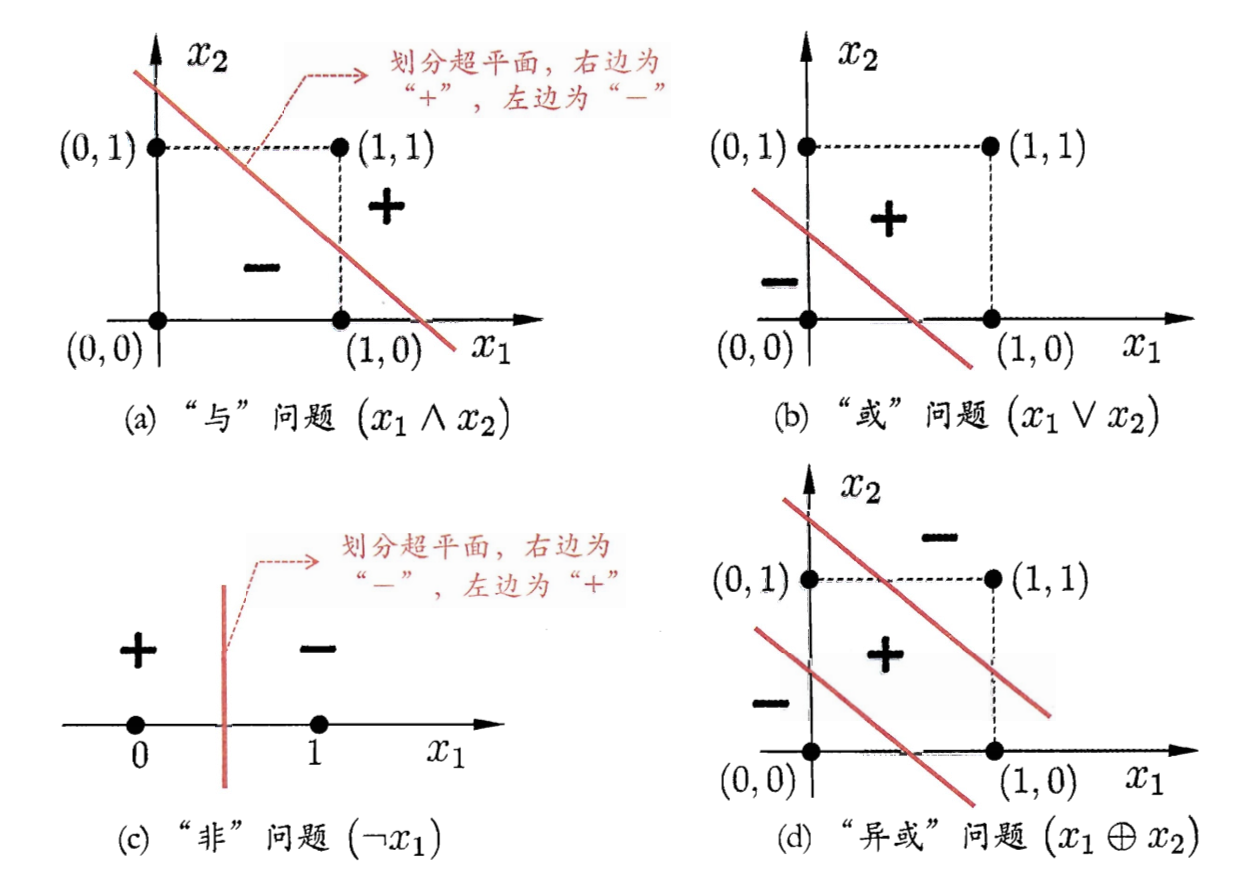
- 20世纪80年代末期 反向传播算法(BP算法) 发明,为机器学习带来突破,掀起基于统计模型的机器学习热潮(持续至今)。通过BP算法,人工神经网络可从大量训练样本中学习统计规律,对未知事件进行预测,其效果显著优于传统基于人工规则的系统
- 此时的人工神经网络虽称“多层感知机”,实为仅含一层隐层节点的浅层模型
3. 1994~1999年: 统计概率主导 NLP
- 基于统计的方法逐渐主导NLP领域,概率计算被引入各类NLP任务
4. 2000~2012年:机器学习成主流,深度学习赛破局
- 机器学习 兴起并迅速占领NLP主流市场
- 传统机器学习算法(未使用神经网络):线性回归(逻辑回归)、决策树、随机森林、XGBoost、朴素贝叶斯等

- 2012年 在ImageNet图像识别大赛中,杰弗里・辛顿团队的AlexNet(深度学习模型)夺冠。该模型采用ReLU激活函数解决梯度消失问题,并借助GPU提升运算速度
- 同年,斯坦福大学吴恩达与Jeff Dean主导的深度神经网络(DNN)在ImageNet评测中,将错误率从26%降至15%。深度学习算法的突破性表现,重新引发学术界与工业界的广泛关注
5. 2015~2022年:AI 模型迭代突破
-
人工智能时代全面到来,深度学习技术深刻重塑NLP的发展方向
-
2016年, 随着谷歌公司基于深度学习开发的 AlphaGo 以 4:1 的比分战胜了国际顶尖围棋高手李世石。后来,AlphaGo又接连和众多世界级围棋高手过招,均取得了完胜

-
2017年,基于强化学习算法的 AlphaGo 升级版 AlphaGo Zero 横空出世。其采用 “从零开始”,“无师自通” 的学习模式,以100:0的比分轻而易举打败了之前的AlphaGo。 除了围棋,它还精通国际象棋等其它棋类游戏,可以说是真正的棋类天才
-
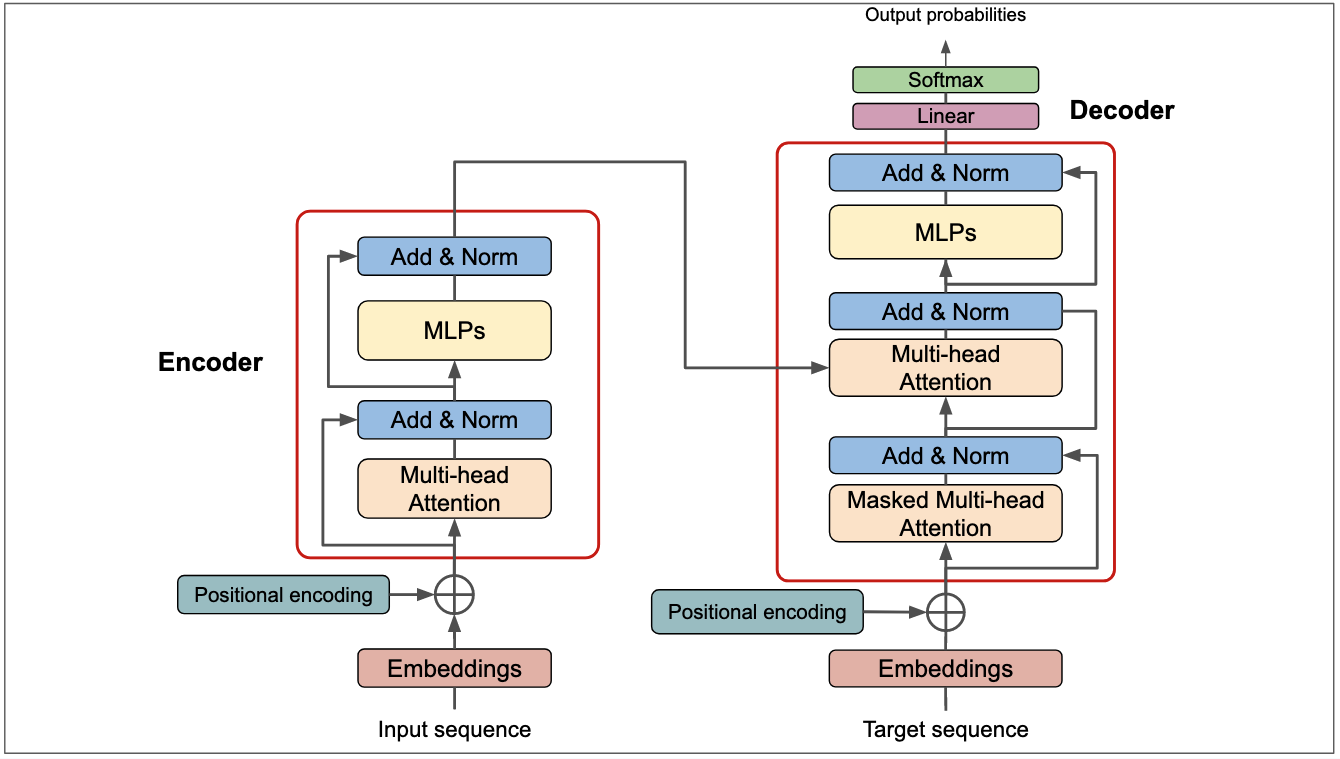
2017年,谷歌推出了划时代的作品 Transformer,对整个人工智能的发展影响深远。此外在这一年,深度学习的相关算法在医疗、金融、艺术、无人驾驶等多个领域均取得了显著的成果。所以,也有专家把2017年看作是深度学习甚至是人工智能发展最为突飞猛进的一年
-
2018年,谷歌推出了BERT,开启了预训练模型和迁移学习的时代
-
2019年,GPT2、T5、AIBERT、RoBERTa、XLNet,一系列预训练模型的推出大大提升了AI的应用效果
-
2020年,深度学习扩展到更多的应用场景,比如积水识别、路面塌陷等,而且疫情期间,在智能外呼系统、人群测温系统、口罩人脸识别等都有深度学习的应用
-
2021年,巨量模型大量涌现,参数规模从几百亿迅速增长到上万亿
-
2021年7月,Codex基于GPT3进行了大量的代码训练而产生的模型Codex,使其具备了代码编写和代码推理能力
-
2021年10月,OpenAI内部发展出了GPT3.5,但未对外公开
-
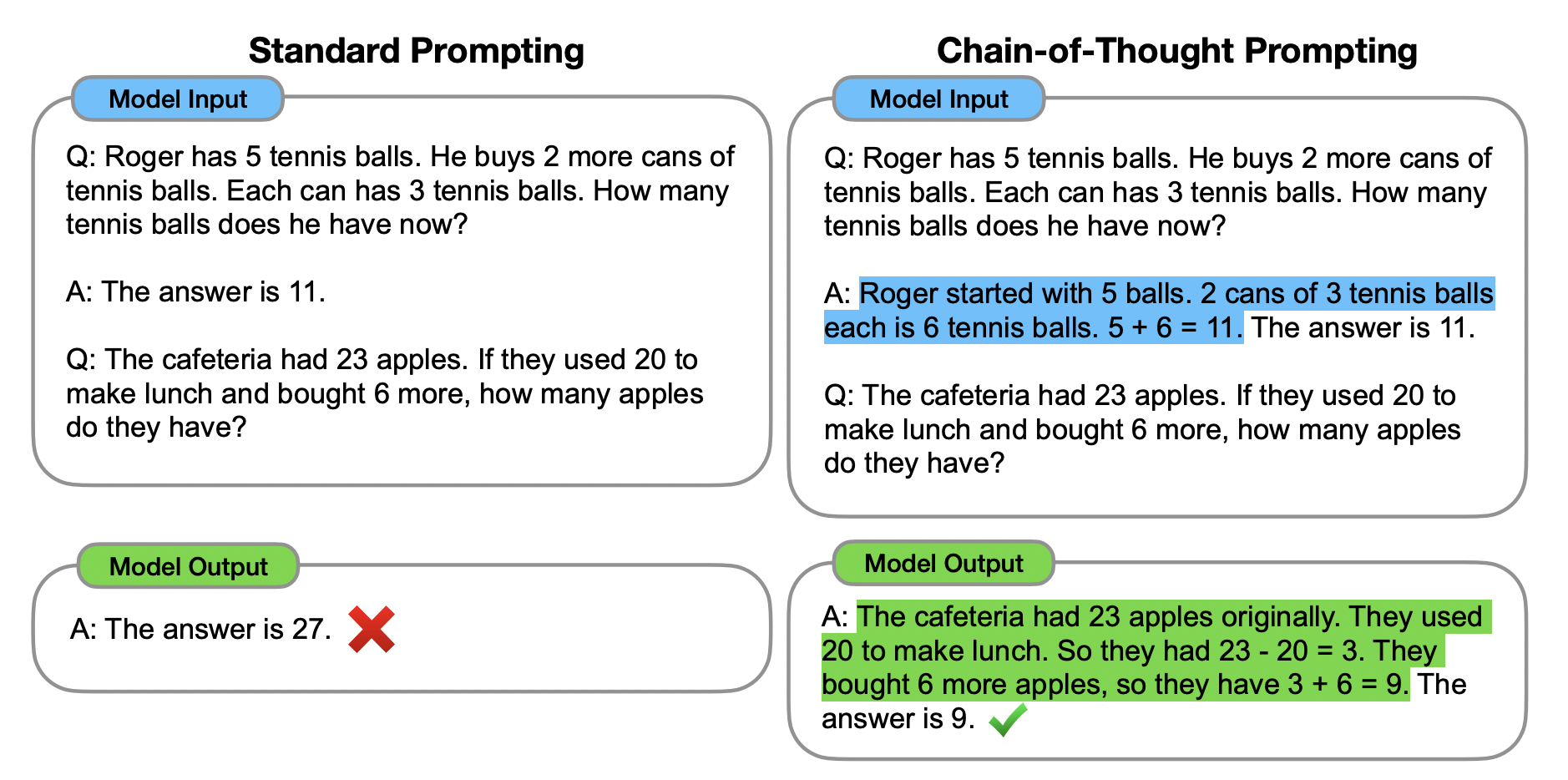
2022年1月,Google提出思维链技术CoT(Chain of Thought)
三、AI 大模型时代
-
2022年11月30日,ChatGPT横空出世,开启了AI大模型的时代,核心点是基于GPT3.5,融合了Codex + 强化学习的技术
-
2023年,是全世界大模型的战国时代,2023年3月,OpenAI正式发布GPT4,增加了多模态能力
-
2024年2月,OpenAI正式发布Sora,首次完成60s稳定、流畅、一致性的视频生成模型

-
2024年5月,GPT-4o、快手可灵大模型发布
-
2024年9月,GPT-o1推理大模型发布,AI第一次在复杂推理能力上取得突破性进展
📌 DeepSeek-R1
-
2024年12月26日,DeepSeek-V3大模型发布,以极低的训练成本得到顶尖的大模型效果
-
2025年1月20日,DeepSeek-R1推理大模型发布,引发了全球轰动,也在整个春节期间都处于一个AI热潮中

图 10. DeepSeek-R1推理大模型 -
2025年4月17日,OpenAI重磅发布o3和o4-mini,在解决复杂多模态推理能力上大幅提升
-
2025年4月29日,阿里巴巴正式发布Qwen3大模型
-
2025年5月22日,Anthropic发布Claude 4系列模型,支持连续7小时复杂编程任务,性能超越Gemini 2.5 Pro
📌 GPT 5
- 2025年8月8日,OpenAI发布GPT-5,引入递归训练架构与通用智能,医疗推理能力获权威认证

图 11. Generative Pre-trained Transformer 5
四、人工智能关键词
- 人工智能 (Artificial Intelligence)
- 机器学习 (Machine Learning)
- 深度学习 (Deep Learning)
- 大语言模型 (Large Language Model)
- 深度学习 (Deep Learning)
- 机器学习 (Machine Learning)
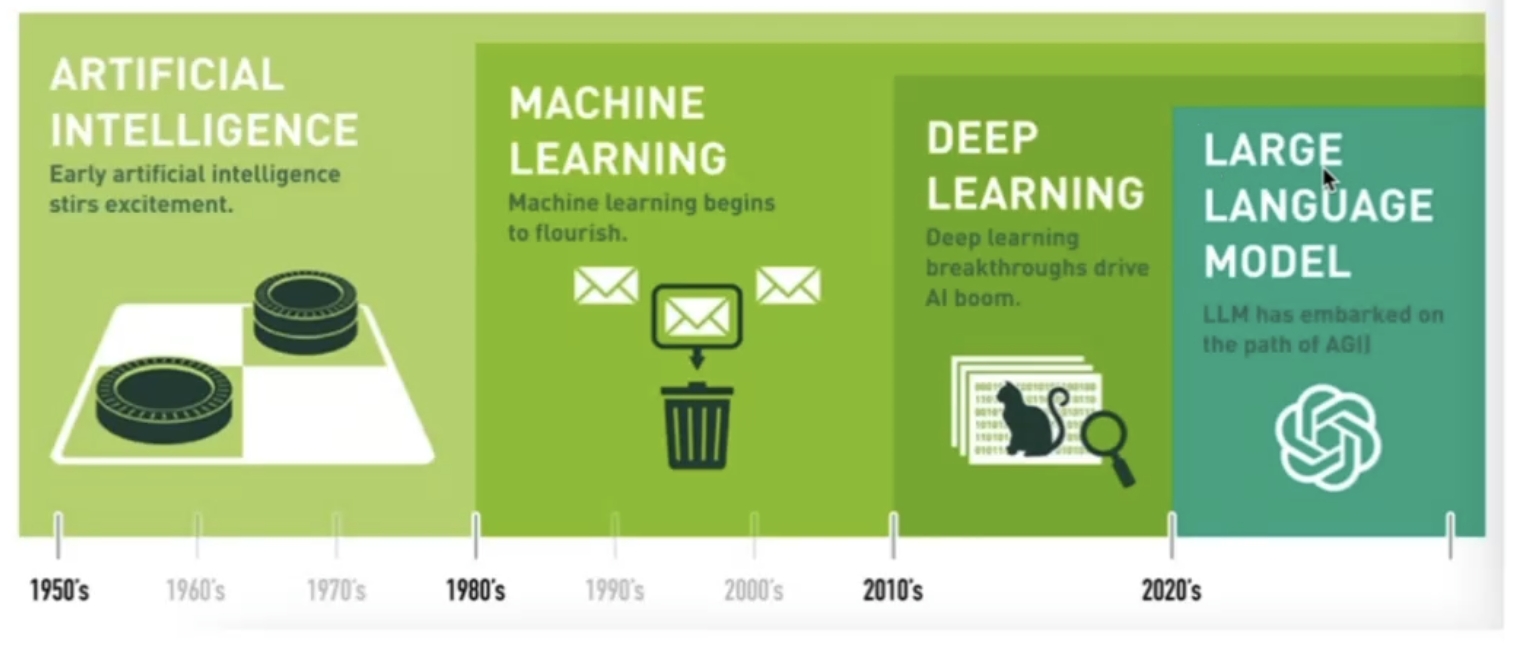
- 层级关系:人工智能 > 机器学习 > 深度学习
核心逻辑:所有应用神经网络技术的机器学习,都可称为深度学习。
1. AI 主流技术方向
-
ASR: 语音,专注语音信号转文字,支撑语音交互、实时翻译等场景
-
CV: 视觉,让机器解析图像视频,应用于人脸识别、自动驾驶等领域
-
NLP: 语言,处理人类文本语言,实现机器翻译、智能问答等功能
- 知识图谱:
- 2012~2019年:作为NLP的一个分支存在
- 2020~2022年:热度攀升,成为独立分支,市场出现专门的知识图谱工程师岗位
- 2023~2024年:受大模型冲击,许多功能被替代
- 2025年之后:再次升温,因成为RAG(检索增强生成)的重要组成部分
- 工业界应用:知识图谱 + 向量数据库共同构建专有知识库,增强大模型能力
- 知识图谱:
-
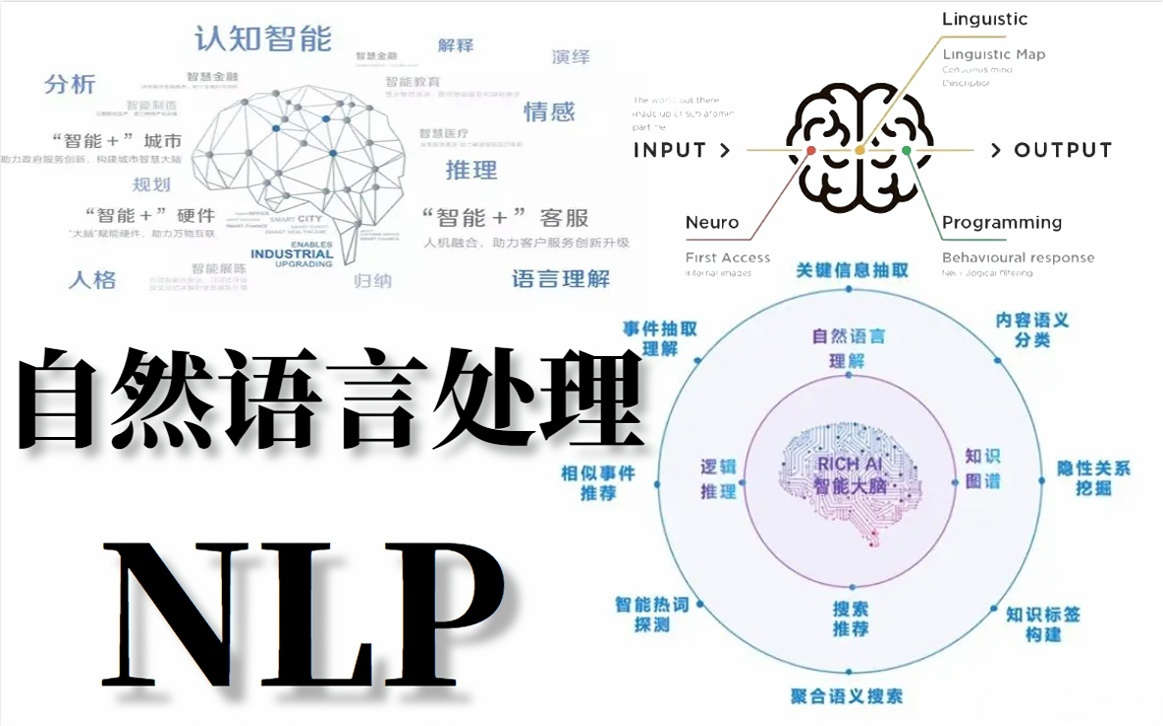
图 13. NLP 自然语言处理 [2]
- MM: 多模态,融合语音视觉语言等信息,提升AI感知理解的全面性
- RS: 搜广推,通过AI优化搜索、广告和推荐,实现精准信息匹配分发
- RL: 强化学习,基于环境反馈持续优化决策,用于博弈、机器人控制等
2. AI 主流就业方向
- AI 算法工程师,设计优化AI算法模型,解决实际业务中的技术难题
- AI 大模型工程师,负责大模型训练、调优与部署,提升模型性能效果
- AI 研发工程师,搭建AI系统架构,保障模型高效稳定运行与迭代
- AI 应用开发工程师,将AI技术落地到具体产品,开发实用化应用程序
- AI 产品经理,衔接技术与市场需求,规划AI产品路线与功能设计
- AI 训练师,构建训练数据集,优化模型训练过程,提升模型表现
- AI 数据标注师,对原始数据进行分类标注,为模型训练提供高质量素材
五、主流大模型发展
📌多模态大模型
1. GPT-5
- https://chat.chatbot.app/gpt5 (需要VPN并使用Google邮箱登录)
- 通过Chatbot App 可以访问GPT,Gemini,Claude等大模型
2. 快手:可灵
3. 字节跳动:即梦
4. 美图:Whee

📌语言大模型
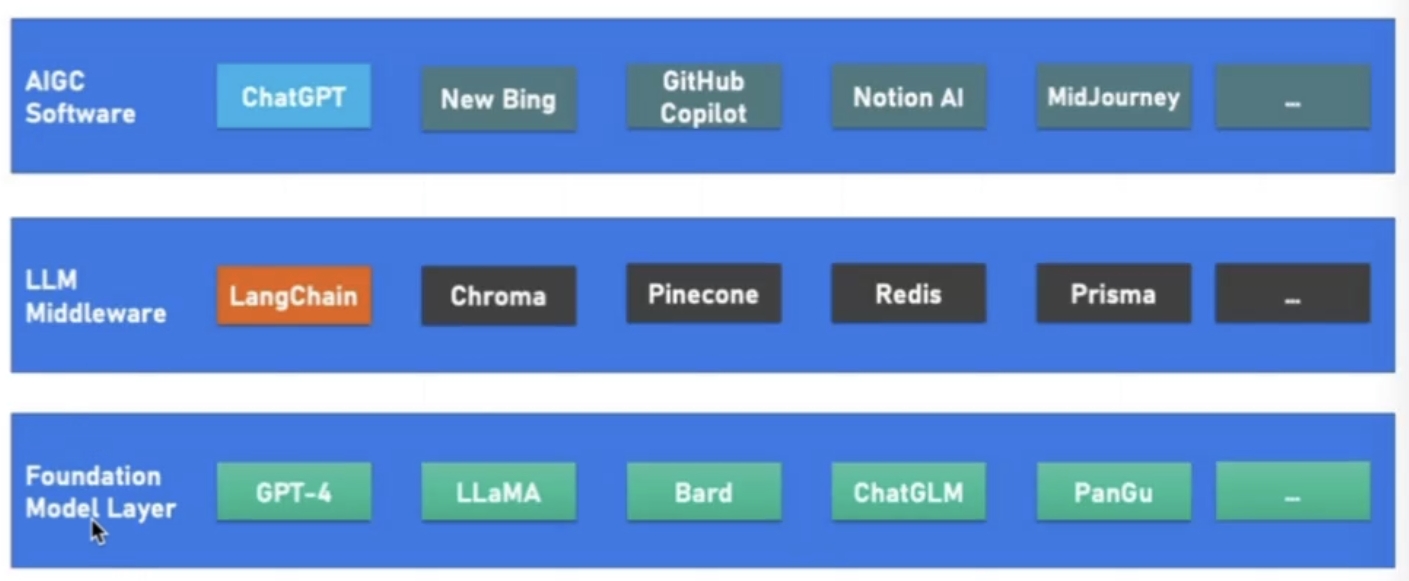
- 基础大模型底层—>LLM中间层—>AIGC软件层
1. 字节跳动:云雀大模型
2. 阿里巴巴:通义千问
3. 百度:文心一言
4. 深度求索:DeepSeek大模型
5. 智谱清言:ChatGLM 大模型
6. 月之暗面:Kimi大模型
7. 腾讯:混元大模型
8. 科大讯飞:星火大模型
9.Minimax:ABAB大模型
- https://www.minimaxi.com/
- 海螺视频、星野
10. 阶跃星辰:Step大模型
📌AI搜索
1. 秘塔
- https://metaso.cn/
总结:以上是当前学术圈和产业圈AI大模型最新进展
六、新时代算力驱动与开发范式变革
1. AI 技术演进阶段脉络
- 随着时代的发展,技术也在不断迁移
| 阶段 | 时间 | 代表性成果 | 数据规模 | 技术栈 |
|---|---|---|---|---|
| 人工规则 | 1950年代-1990年代 | 基于手工设计的规则系统 | 少量规则集 | 基于专家知识和规则的系统设计 |
| 统计机器学习 | 1990年-2012年 | HMM, CTF, SVM | 百万级 标注数据 | 统计机器学习算法 |
| 深度学习 | 2013年-2018年 | Encoder-Decoder, Word2vec, Attention | 十亿级 标注数据 | 深度神经网络 + 框架 |
| 预训练 | 2018年-2020年 | Transformer, ELMo, GPT-1, BERT, GPT-2, GPT-3 | 数千亿 未标注数据 | Pre-training + Fine-tuning |
| 大语言模型 | 2020年–至今 | GPT-3.5, GPT-4 | 更大规模 用户数据 | Instruction-tuning、Prompt-tuning、RLHF |
2. 算力增长和AI效能
-
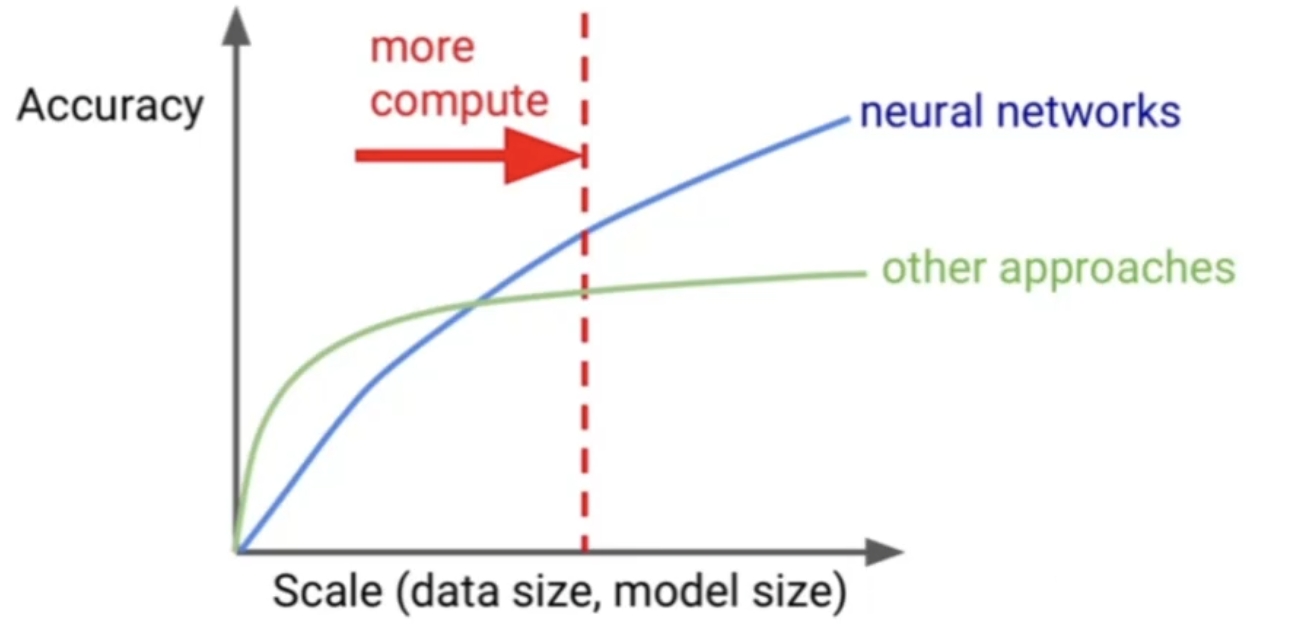
图 15. 神经网络的规模增益效应 -
关于 GPU 的价格?
- A100, A800: 98000 一块
- H20: 20 万一块
- H100, H200: 25 ~ 30 万一块
- A100, 4090 — 都是基于安培架构 (Ada Love)
3. AI 大模型时代的开发模式
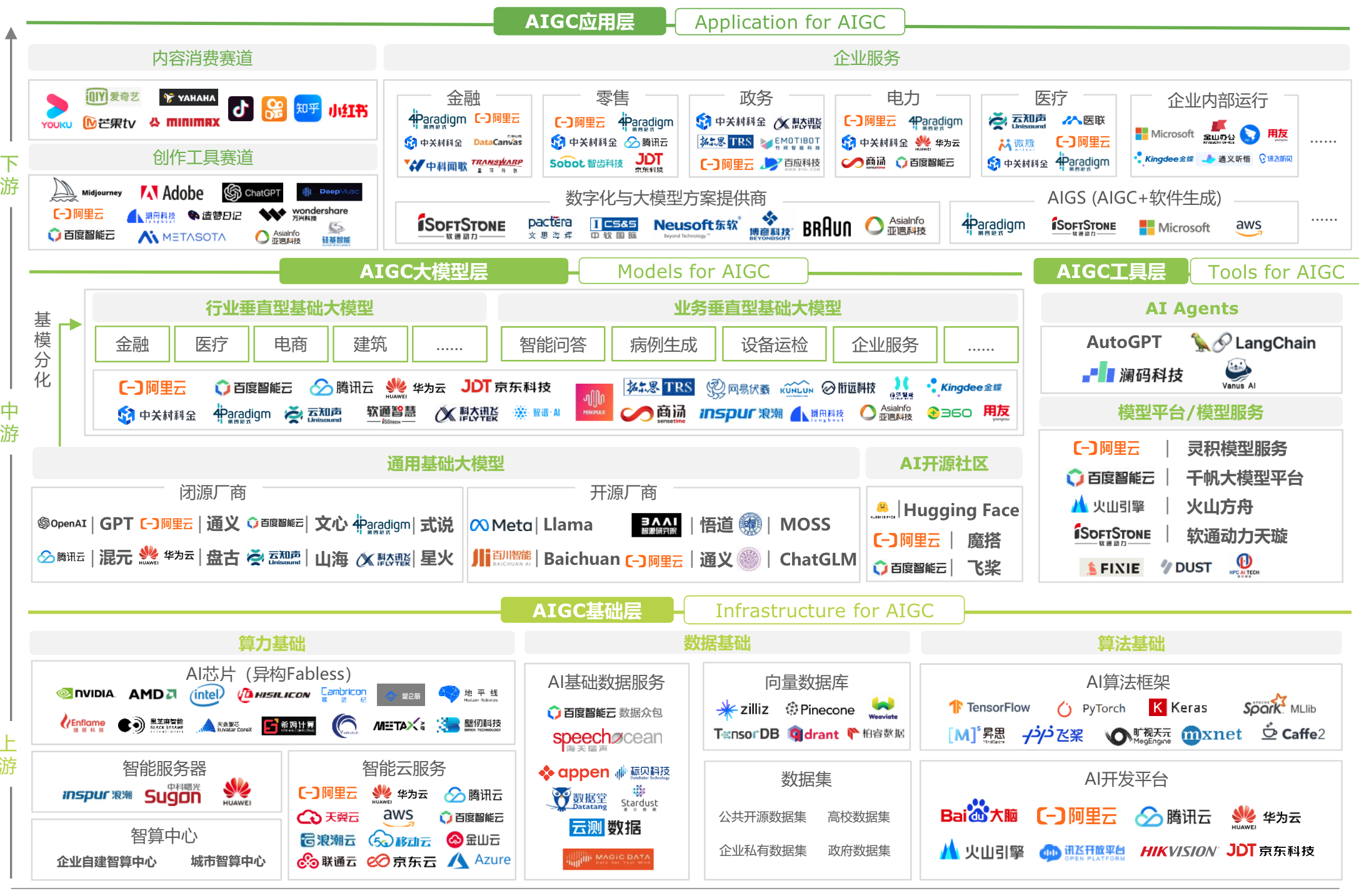
图 16. 大模型应用开发
七、如何初步配置AI开发环境
1. 开发环境
- Linux 优先
2. 开发 IDE
- vim
- VSCode (推荐)
- PyCharm
- Jupyter Notebook
3. 软件版本
- anaconda
- Pytorch 2.4, 2.5, 2.6
- 2.7.0 移除了 cuda12.4 的支持,只支持 cuda12.8, 但是这个版本的 CUDA 只适配 Hopper 架构的 GPU, H100, H200, H800, H20
- transformers 2.6, 3.6, 4.32, 4.51
pip install torch==2.6.0+cu124 transformers==4.51.0
4. GPU算力云平台
- AutoDL: GPU
- 魔搭: GPU
- 趋动云: GPU
- 青云:
- 基石:
参考资料
[1] Zhao W X, Zhou K, Li J, et al. A survey of large language models[J]. arXiv preprint arXiv:2303.18223, 2023.
[2] Chaos_Wang_. 【NLP相关】NLP的发展历程[EB/OL]. CSDN博客, 2023-03-04[2025-08-19]. https://blog.csdn.net/qq_41667743/article/details/129297303.
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)