【公式+代码】mPLUG-2:跨文本、图像、视频模块化多模态基础模型【论文精读注解】
mPLUG-2:一个跨文本、图像和视频的模块化多模态基础模型
个人学习笔记
详情参考原文链接
https://arxiv.org/abs/2302.00402
太臭太长不读之核心Method精简阅读
mPLUG-2 Method 精简总结
1. 整体架构
mPLUG-2采用模块化视觉-语言基础模型设计,包含三个核心模块:
- Visual Encoder: 提取图像特征
- Text Encoder: 提取文本特征
- Cross-Modal Module: 多模态融合与交互
2. 主要模块与数据流
2.1 Visual Encoder
- 输入: 图像 I ∈ R H × W × 3 I \in \mathbb{R}^{H \times W \times 3} I∈RH×W×3
- 处理: 将图像分割为patches并编码
- 输出: 视觉特征 V ∈ R N v × d V \in \mathbb{R}^{N_v \times d} V∈RNv×d
- N v = H × W P 2 N_v = \frac{H \times W}{P^2} Nv=P2H×W (patch数量)
- P P P: patch大小 (通常16×16)
- d d d: 特征维度 (768/1024)
2.2 Text Encoder
- 输入: 文本tokens T = { t 1 , t 2 , . . . , t N t } T = \{t_1, t_2, ..., t_{N_t}\} T={t1,t2,...,tNt}
- 处理: BERT-style编码
- 输出: 文本特征 T ∈ R N t × d T \in \mathbb{R}^{N_t \times d} T∈RNt×d
- N t N_t Nt: token序列长度
2.3 Cross-Modal Module
采用共享自注意力机制实现多模态融合:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中:
- Q = [ Q v ; Q t ] ∈ R ( N v + N t ) × d Q = [Q_v; Q_t] \in \mathbb{R}^{(N_v + N_t) \times d} Q=[Qv;Qt]∈R(Nv+Nt)×d
- K = [ K v ; K t ] ∈ R ( N v + N t ) × d K = [K_v; K_t] \in \mathbb{R}^{(N_v + N_t) \times d} K=[Kv;Kt]∈R(Nv+Nt)×d
- V = [ V v ; V t ] ∈ R ( N v + N t ) × d V = [V_v; V_t] \in \mathbb{R}^{(N_v + N_t) \times d} V=[Vv;Vt]∈R(Nv+Nt)×d
3. 训练目标
3.1 Image-Text Contrastive (ITC) Loss
L I T C = − 1 2 [ log exp ( s i , t / τ ) ∑ j = 1 B exp ( s i , j / τ ) + log exp ( s t , i / τ ) ∑ j = 1 B exp ( s j , i / τ ) ] \mathcal{L}_{ITC} = -\frac{1}{2}\left[\log\frac{\exp(s_{i,t}/\tau)}{\sum_{j=1}^B \exp(s_{i,j}/\tau)} + \log\frac{\exp(s_{t,i}/\tau)}{\sum_{j=1}^B \exp(s_{j,i}/\tau)}\right] LITC=−21[log∑j=1Bexp(si,j/τ)exp(si,t/τ)+log∑j=1Bexp(sj,i/τ)exp(st,i/τ)]
- s i , t = v i T ⋅ t i s_{i,t} = v_i^T \cdot t_i si,t=viT⋅ti: 图像-文本相似度
- τ \tau τ: 温度参数
- B B B: batch size
3.2 Image-Text Matching (ITM) Loss
L I T M = − E ( I , T ) [ y log p ( y = 1 ∣ I , T ) + ( 1 − y ) log p ( y = 0 ∣ I , T ) ] \mathcal{L}_{ITM} = -\mathbb{E}_{(I,T)}\left[y\log p(y=1|I,T) + (1-y)\log p(y=0|I,T)\right] LITM=−E(I,T)[ylogp(y=1∣I,T)+(1−y)logp(y=0∣I,T)]
- 二分类任务:判断图文是否匹配
- 采用hard negative mining策略
3.3 Masked Language Modeling (MLM) Loss
L M L M = − E ( I , T ) ∑ i ∈ M log p ( t i ∣ T \ M , I ) \mathcal{L}_{MLM} = -\mathbb{E}_{(I,T)}\sum_{i \in M} \log p(t_i|T_{\backslash M}, I) LMLM=−E(I,T)i∈M∑logp(ti∣T\M,I)
- M M M: 被mask的token位置集合
- 15%的tokens被随机mask
4. 数据流Shape变化示例
输入图像: [B, 3, 224, 224]
↓ Visual Encoder
视觉特征: [B, 196, 768] # 196 = (224/16)^2 patches
输入文本: [B, L] # L为序列长度,如77
↓ Text Encoder
文本特征: [B, L, 768]
↓ Cross-Modal Fusion
融合特征: [B, 196+L, 768]
↓ Transformer Layers
输出特征: [B, 196+L, 768]
5. 关键创新点
- 统一的多模态架构: 支持视觉和语言的双向建模
- 模块化设计: 各模块可独立优化和扩展
- 多任务学习: ITC + ITM + MLM联合训练
- 高效的注意力机制: 跨模态共享注意力权重
6. 总损失函数
L t o t a l = λ 1 L I T C + λ 2 L I T M + λ 3 L M L M \mathcal{L}_{total} = \lambda_1 \mathcal{L}_{ITC} + \lambda_2 \mathcal{L}_{ITM} + \lambda_3 \mathcal{L}_{MLM} Ltotal=λ1LITC+λ2LITM+λ3LMLM
其中 λ 1 , λ 2 , λ 3 \lambda_1, \lambda_2, \lambda_3 λ1,λ2,λ3为权重系数,通常设为相等权重。
又臭又长精读注解全文
摘要Abstract
近年来见证了语言、视觉和多模态预训练的大融合。在这项工作中,我们提出了mPLUG-2,一个用于多模态预训练的具有模块化设计的新统一范式,它可以从模态协作中受益,同时解决模态纠缠的问题。与仅依赖序列到序列生成或基于编码器的实例判别的主流范式相比,mPLUG-2通过共享通用的通用模块来实现模态协作,并通过解耦不同的模态模块来处理模态纠缠,从而引入了一个**多模块组合网络。它可以灵活地为跨所有模态(包括==文本、图像和视频)的不同理解和生成任务选择不同的模块。实证研究表明,mPLUG-2在超过30个下游任务的广泛范围内实现了最先进或具有竞争力的结果,涵盖了图像-文本和视频-文本理解与生成的多模态任务==,以及仅文本、仅图像和仅视频理解的单模态任务。值得注意的是,mPLUG-2在具有挑战性的MSRVTT视频问答和视频字幕任务上分别展示了48.0的top-1准确率和80.3的CIDEr新的最先进结果,而模型规模和数据规模要小得多。它还在视觉-语言和视频-语言**任务上展示了强大的零样本迁移能力。代码和模型将在https://github.com/alibaba/AliceMind发布。
【段落总结】
这是关于mPLUG-2多模态预训练模型的研究总结,以下是关键点:
核心创新mPLUG-2:提出了一个具有模块化设计的统一多模态预训练范式,通过独特的架构设计同时实现模态协作和解决模态纠缠问题。
技术方案
- 多模块组合网络:通过共享通用模块实现模态协作,通过解耦不同模态模块处理模态纠缠
- 灵活模块选择:可以针对不同的理解和生成任务灵活选择合适的模块组合
- 全模态覆盖:支持文本、图像、视频等所有主要模态
实验成果
广泛验证:在超过30个下游任务上达到最先进或具有竞争力的结果
突出表现:
- MSRVTT视频问答:48.0 top-1准确率
- 视频字幕任务:80.3 CIDEr分数
效率优势:在更小的模型和数据规模下实现了这些结果
迁移能力:在视觉-语言和视频-语言任务上展现强大的零样本迁移能力
应用范围涵盖多模态任务(图像-文本、视频-文本的理解与生成)和单模态任务(纯文本、纯图像、纯视频理解)的完整生态。
这项工作的主要贡献在于通过模块化设计有效解决了多模态预训练中的关键技术挑战,为多模态AI的发展提供了新的架构范式。
他这里硕的模态协作和模态纠缠主要是指什么?
根据论文内容,这两个概念在mPLUG-2中具有以下含义:
【模态协作 (Modality Collaboration)】
指的是不同模态(文本、图像、视频)之间能够有效地共享信息和相互促进的能力:
- 共享语义空间:通过通用层模块,将视觉和语言投影到共同的语义空间,使得不同模态能够相互理解和对齐
- 信息互补:利用一个模态的信息来增强另一个模态的表示,比如用文本信息帮助理解图像内容
- 降低模态差距:如图4所示,通过协作使得视觉和文本嵌入在特征空间中距离更近
【模态纠缠 (Modality Entanglement)】
指的是当多个模态共享同一个网络时产生的负面干扰现象:
- 相互干扰:论文提到"多个模态可能会相互干扰(Huang et al., 2022b),特别是当有许多模态和任务时"
- 任务差异大:不同模态任务(如图像分类vs文本生成)的巨大差异导致在同一网络中难以平衡
- 性能下降:单一网络难以同时优化所有模态的任务,导致某些任务性能受损
【mPLUG-2的解决方案】
论文提出了模块化设计来平衡这两者:
- 促进协作:通过共享的通用层模块实现模态间的有效协作
- 减少纠缠:通过模态特定的模块(如专门的视觉编码器、文本编码器)来避免不同模态之间的负面干扰
- 灵活组合:可以根据具体任务选择性地使用不同模块,实现最优的模态组合
这种设计让模型既能享受模态协作带来的好处,又能避免模态纠缠造成的性能损失。
【模态纠缠的具体表现】
模态纠缠的具体表现
- 参数冲突问题
当使用单一网络处理多模态时,不同模态会争夺同一组参数:
- 视觉任务需要网络学习空间特征、纹理、颜色等
- 语言任务需要网络学习语法、语义、上下文关系
- 视频任务还需要额外学习时间动态
这些不同的学习目标在共享参数时会产生冲突。
- 优化方向矛盾
论文中提到的具体例子:
- 图像分类:需要提取判别性的视觉特征
- 文本生成:需要建模序列依赖关系
- 视频理解:需要同时处理空间和时间信息
当这些任务共享同一个网络时,梯度更新方向可能相互矛盾,导致训练不稳定。
- 特征表示冲突
不同模态的最优特征表示方式不同:
- 图像:通常需要局部特征(边缘、纹理)和全局特征(物体、场景)
- 文本:需要序列化的语义表示
- 视频:需要时空一致的动态表示
在单一网络中,这些不同的表示需求会相互干扰。
- 任务规模不平衡
如表1所示,mPLUG-2支持30+个任务:
- 某些任务数据量大(如图像分类)
- 某些任务数据量小(如视频问答)
- 不同任务的难度差异很大
这种不平衡会导致网络偏向某些任务,忽视其他任务。
- 实际影响示例
没有模块化设计时的问题:
单一网络 → 所有模态共享所有层 ↓ 视频任务需要时间建模 ←→ 图像任务不需要时间信息 ↓ 相互干扰:图像任务的梯度可能破坏视频的时间建模能力mPLUG-2的解决方案:
模块化设计 → 视频专用:局部时间建模模块 → 图像视频共享:空间建模 → 通用:语义对齐层 ↓ 各司其职:避免不必要的干扰
- 具体的技术挑战
论文通过实验(表15)展示了这个问题:
- 使用时间自注意力处理所有视觉信息:性能较差(70.3)
- 使用局部时间建模仅处理视频:性能提升(73.5)
这说明当图像和视频完全共享时间建模机制时,会产生纠缠问题,因为图像根本不需要时间信息。
- 量化证据
从论文的实验结果可以看出模态纠缠的影响:
- 许多现有模型只能处理部分任务(见表1)
- 而mPLUG-2通过模块化设计能同时处理所有任务
- 这表明完全共享的架构确实存在模态纠缠限制
总结:模态纠缠本质上是多任务学习中的"负迁移"现象在多模态场景下的体现——不同模态的学习目标相互冲突,导致共享参数无法同时优化所有任务。
1. 引言(Introduction)
现有预训练模型背景
大规模预训练基础模型已成为人工智能(AI)广泛领域的新兴范式,跨越**语言(Devlin et al., 2018; Brown et al., 2020)、视觉(Dosovitskiy et al., 2020; Liu et al., 2021b)和多模态(Radford et al., 2021; Yu et al., 2022; Wang et al., 2022e)。随着Transformer架构(Vaswani et al., 2017)的广泛成功,近年来出现了语言、视觉和多模态预训练大融合的趋势(Yu et al., 2022; Wang et al., 2022e; Alayrac et al., 2022)。沿着这一趋势的一条路线提出使用统一的序列到序列生成框架来统一任务和模态,如T5(Raffel et al., 2020)、OFA(Wang et al., 2022d)和Flamingo(Alayrac et al., 2022)。另一方面,BERT(Devlin et al., 2018)、Florence(Yuan et al., 2021)和BEIT-3(Wang et al., 2022e)将所有任务建模为实例判别,并采用纯编码器架构**。
现有模型存在什么问题
主流的基础模型提出为**多模态共享相同的单一网络(Alayrac et al., 2022),以利用来自模态协作的信息。然而,由于不同模态任务的巨大差异,该策略将遭受模态纠缠的问题。挑战在于多个模态可能会相互干扰(Huang et al., 2022b),特别是当有许多模态和任务时。单模块基础模型很难平衡模态协作的收益和模态纠缠**的影响。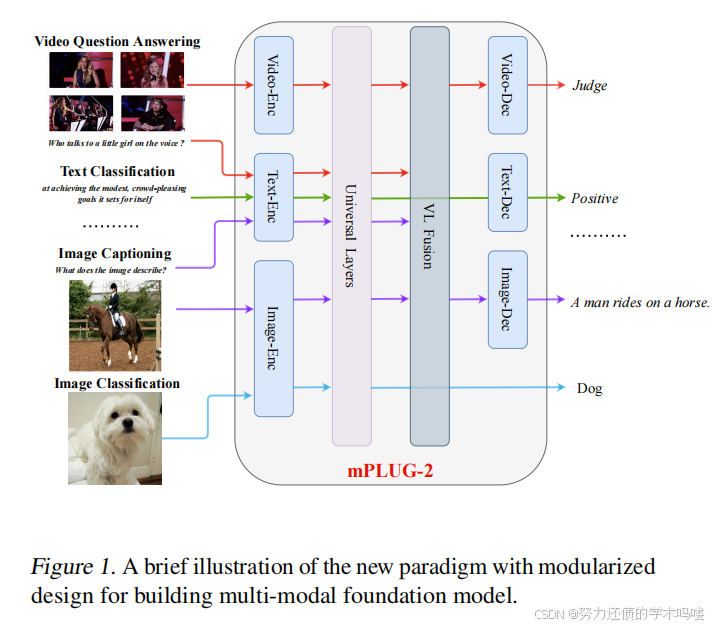
图1. 用于构建多模态基础模型的具有模块化设计的新范式的简要说明。
本文模型为了解决现有模型存在的平衡【模态纠缠】和【模态协作】的收益提出的方法【本文创新点】
为了缓解大量跨多模态下游任务的模态纠缠的挑战,在这项工作中,我们引入了一个新的多模态基础模型统一范式,如图1所示。它具有基于模块的网络设计,考虑了模态协作和模态纠缠,其中mPLUG-2设计了某些共享的功能模块来鼓励模态协作,同时保留特定于模态的模块来解决模态纠缠的问题。然后根据任务的模块设计有效地联合训练不同的模块。因此,可以为大量的单模态和跨模态理解与生成任务相应地灵活选择和组合不同的模块。支持的下游任务的详细信息见表1。据我们所知,所提出的方法处理了跨文本、图像和视频的最多不同类型的下游任务。
具体来说,我们设计了一个统一的**双视觉编码器模块,通过解耦空间和时间表示,其中视频输入与图像输入共享标准的Transformer模块来建模空间信息,并使用额外的局部时间建模模块来对视频相关任务进行时间关系建模。然后引入了一个新颖的通用层模块作为跨不同模态的枢纽,其中视觉和语言模态通过共享自注意力模块被投影到共同的语言引导的语义空间。此外,使用额外的交叉注意力模块将通用视觉表示与原始细粒度视觉表示融合。详细的模块设计如图2所示。最后,mPLUG-2的不同模块与任务和模态指令(Wang et al., 2022d)在单模态和跨模态任务上联合预训练。在推理过程中,mPLUG-2可以使用模块化的Transformer架构为各种单模态和跨模态任务选择不同的模块。不同任务的选定模块可在附录的表2**中找到。
设计理念mPLUG-2采用基于模块的网络设计来同时处理模态协作和模态纠缠问题:设计共享功能模块鼓励模态协作,保留特定模态模块解决模态纠缠。
核心架构
- 统一的**双视觉编码器模块:通过解耦 空间和时间表示,视频与图像共享标准Transformer模块处理空间**信息,额外使用局部时间建模模块处理视频==时间==关系
- 通用层模块:作为跨模态枢纽,将**视觉和语言模态通过共享自注意力模块投影到共同的语言引导语义空间**
- 交叉注意力融合:使用**额外交叉注意力模块将通用视觉表示与原始细粒度视觉表示融合**
训练方式不同模块与任务和模态指令在单模态和跨模态任务上进行**联合预训练**,根据任务模块设计有效地联合训练不同模块。
推理机制采用模块化Transformer架构,可以为各种单模态和跨模态任务**灵活选择和组合**不同模块,实现任务特定的模块配置。
任务覆盖【****任务泛化性比较强 】 支持跨文本、图像和视频的**最多不同类型下游任务,包括大量单模态和跨模态的理解与生成任务**,具体任务详情见相关表格。
这种模块化设计使mPLUG-2能够在**保持模态间协作的同时避免模态纠缠**,为不同类型任务提供最优的模块组合方案。
我们在超过30个具有挑战性的单模态和跨模态理解与生成基准上评估了mPLUG-2的新统一范式,它在相似的模型规模和数据规模下实现了最先进或具有竞争力的结果。配备基于模块的网络设计,mPLUG-2还可以通过选择和添加模块轻松扩展到其他任务。值得注意的是,mPLUG-2在具有挑战性的MSRVTT视频问答QA和视频字幕Captioning任务上分别展示了48.0的top-1准确率和80.3的CIDEr新的最先进结果。mPLUG-2还在视觉-语言 和视频-语言任务上展示了强大的零样本迁移能力。
2. 相关工作(Related Work)
(Vision-only Foundation Models)仅**视觉基础模型 在视觉Transformer(又名ViT)(Dosovitskiy et al., 2020)出现之前,ConvNets(Szegedy et al., 2017; He et al., 2015)长期以来一直是主流的视觉架构。由于Transformer网络的卓越能力,ViT在各种下游任务中脱颖而出(Carion et al., 2020; Xu et al., 2022)。除了使用JFT-3B等大规模数据集扩展朴素的ViT【扩展ViT】架构(Zhai et al., 2021),SwinV2-G(Liu et al., 2021a)使用【分层架构扩展】了原始ViT。此外,EVA(Fang et al., 2022a)通过利用大规模预训练的图像-文本模型(例如CLIP(Radford et al., 2021))使用未标记图像来提取多模态知识以【CLIP扩展ViT】。最近,InternImage(Wang et al., 2022f)使用【可变形卷积】 振兴了卷积神经网络,并在各种视觉下游任务上实现了最先进的性能。此外,InternVideo(Wang et al., 2022g)通过组装两个具有生成和判别自监督视频学习的大型视频模型扩展到视频任务。
(Language-only Foundation Models)仅**语言基础模型 受BERT(Devlin et al., 2018)在自然语言理解中成功实践的启发,为自然语言处理提出了大量大规模语言基础模型。BART(Lewis et al., 2020)是一个类似于BERT的去噪自动编码器,但具有编码器-解码器架构,显示了文本生成和理解任务**的有效性。除了BERT系列方法(Devlin et al., 2018; Lewis et al., 2020; Liu et al., 2019),还有许多其他有效的架构和预训练目标。T5【T5大模型,统一文本语言任务】(Raffel et al., 2020)引入了一个统一框架,将所有基于文本的语言任务涵盖为文本到文本格式。GPT-3(Brown et al., 2020)是一个包含1750亿参数的自回归语言基础模型,在少样本和零样本设置下在许多NLP任务上表现出强大的性能。
T5大模型的全称是Text-to-Text Transfer Transformer(文本到文本迁移Transformer)。这是Google在2019年提出的一个预训练语言模型,其核心理念是将所有自然语言处理任务都统一为"文本到文本"的生成任务格式,包括分类、问答、翻译、摘要等各种任务都被重新框架化为接收文本输入并生成文本输出的形式。
(Vision-Language Foundation Models)视觉-语言基础模型 受益于互联网中大量的图像/视频-文本对,视觉-语言基础模型的出现可以包含视觉-语言预训练。CLIP(Radford et al., 2021)和ALIGN(Jia et al., 2021)的成功表明,在嘈杂的图像-文本对上使用简单对比目标预训练的模型可以生成强大的视觉-语言表示。此外,ALBEF(Li et al., 2021b)、BLIP(Li et al., 2022c)和mPLUG(Li et al., 2022a)通过多模态文本补全和文本生成扩展任务以进行辅助学习。另一方面,一些基础模型通任务统一构建。例如,Florence(Yuan et al., 2021)统一了可以利用视觉和视觉-语言数据的对比目标。BEiT-3(Wang et al., 2022e)将预训练任务归因于文本、视觉和视觉-语言方面的掩码数据建模。SimVLM(Wang et al., 2021b)、OFA(Wang et al., 2022d)和CoCa(Yu et al., 2022)为视觉-语言理解和生成执行生成预训练。与主流基础模型不同,mPLUG-2引入了一个新的模块化Transformer框架,它可以通过共享通用的通用模块和解耦特定于模态**的模块来利用不同的模块组合来处理单模态和跨模态任务,以解决模态纠缠的问题。
视觉基础模型
- ViT成为主流视觉架构,具有卓越的Transformer网络能力
- IERT-ViT:使用大规模数据集进行扩展
- SwinV2-G:采用分层架构改进原始ViT
- EVA:通过大规模预训练训练的图像-文本模型
- CLIP扩展ViT:使用未标记图像来提取多模态知识
- InternImage:采用可变形卷积提取卷积经网络
- InternVideo:专注于视频理解的大型视频预训练模型
语言基础模型
- BERT:开创预训练语言模型先河,提出大量语言基础模型
- BART:类似BERT的去噪自动编码器,展示文本生成和理解任务有效性
- T5大模型:引入统一框架,将所有基于文本的语言任务涵盖为文本到文本格式
- GPT-3:包含1750亿参数的自回归语言基础模型,在少样本和零样本设置下表现出强大性能
视觉-语言基础模型
发展背景:受益于互联网大量图像/视觉-文本对数据
对比学习方法:
- CLIP和ALIGN:通过简单对比目标预训练取得成功
生成学习方法:
- ALBEF、BLIP、mPLUG:通过多模态文本补全和文本生成任务进行辅助学习
统一任务框架:
- Florence:统一可利用视觉和视觉-语言数据的对比目标
- BEIT-3:将预训练任务归因于文本、视觉和视觉-语言方面的掩码数据建模
生成预训练:
- SimVLM、OFA、CoCa:进行视觉-语言理解和生成的生成预训练
mPLUG-2技术创新
- 引入新的模块化Transformer框架
- 通过共享通用模块和解耦特定模态模块来处理不同任务
- 解决模态纠缠问题,支持单模态和跨模态任务
3. 方法(Mehtod)
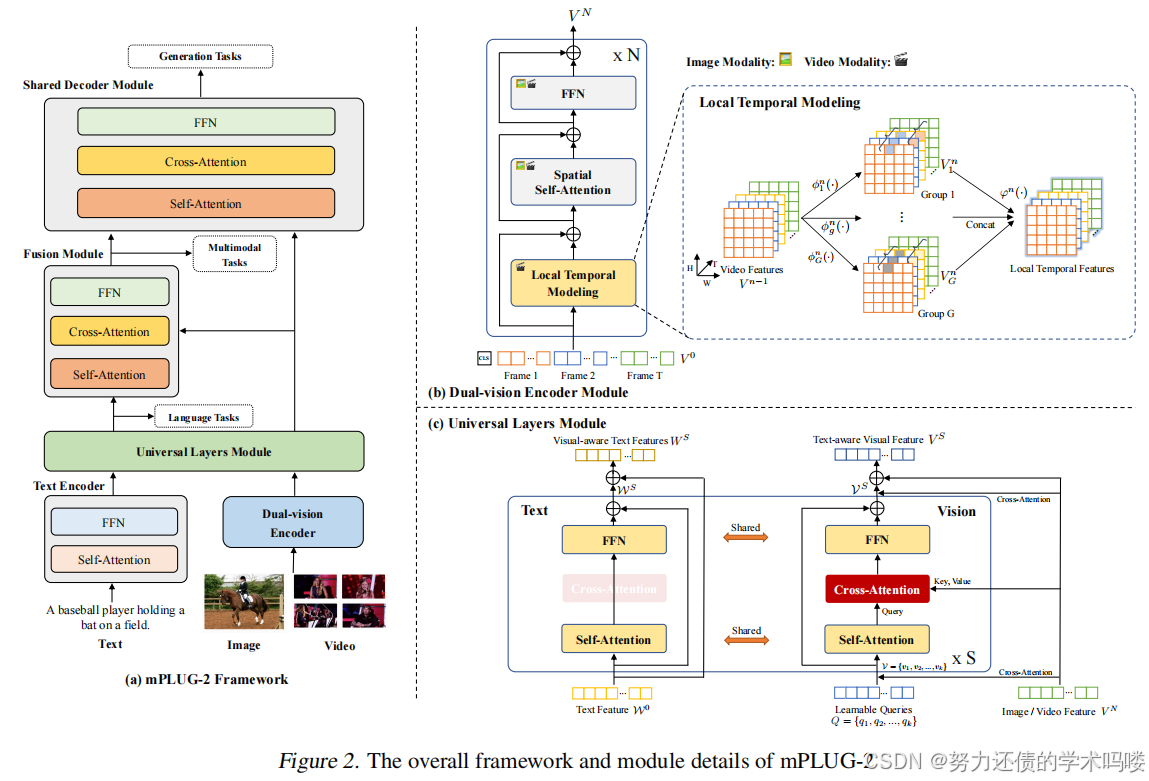
3.1. 整体框架(Overall Framework)
如图2所示,mPLUG-2由用于图像和视频的双视觉编码器模块、文本编码器模块、作为所有任务共享的多模态枢纽的**通用层模块、多模态融合模块和用于单模态和跨模态生成的共享解码器模块组成。我们首先使用两个单模态编码器,分别对图像/视频和文本进行编码,以表示各个模态的固有信息。对于图像/视频,我们采用双视觉编码器通过空间建模和局部时间建模**来编码视觉特征。然后,
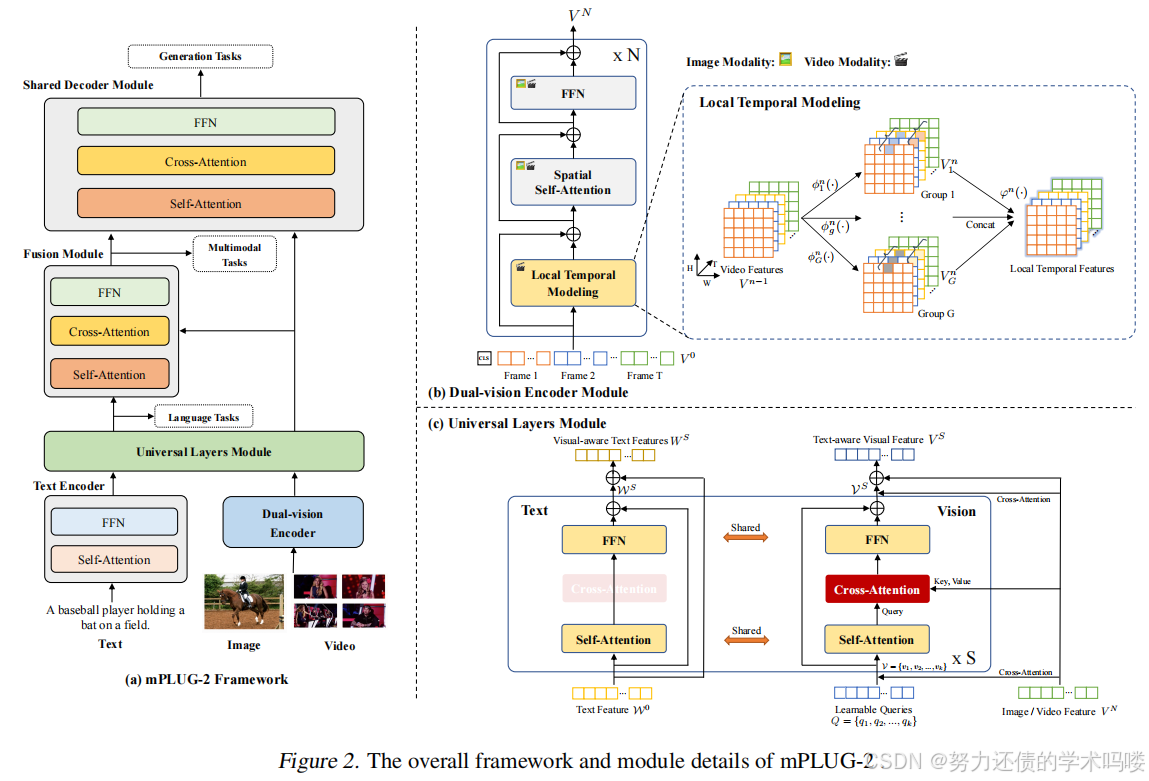
图2. mPLUG-2的整体框架和模块细节。
视觉和语言表示分别馈送到通用模块中,该模块由多个通用层组成。每个通用层将不同的模态投影到共享的语义空间以进行跨模态对齐,同时保留不同模态的原始表示。通用层的输出用于进行单模态判别任务。对于跨模态任务,将应用额外的融合模块来生成跨模态表示。最后,单模态和跨模态表示可以作为输入合并到共享的Transformer解码器中,用于各种生成任务,这有助于多任务预训练和迁移学习。不同下游任务的模块总结在表2中。

(Dual-vision Encoder Module)双视觉编码器模块 为了捕获各种视觉模态的视觉信息,我们提出双视觉编码器来同时建模图像和视频。特别地【具体而言】,我们将图像和视频帧分割成L个非重叠视觉标记【L个不重叠的视觉token】的序列。每个视觉标记token序列Sequence与可学习的(Learnable)空间位置嵌入 (Spacial Location Embedding)和额外的 [CLS] 标记token构成输入视觉序列。然而,在没有大规模视频预训练的情况下,建模完整的视觉序列会导致时空学习困难(Li et al., 2022d; Wang et al., 2022a;b)。为了缓解这个问题,我们通过引入时间局部性将视觉表示解耦为空间和时间表示。如图2(b) 所示,我们利用Transformer块中的自注意力(SA)层和前馈层(FFN)进行空间建模,并提出一个新颖的局部时间建模模块(LT)来建模空间表示之间的时间依赖性:
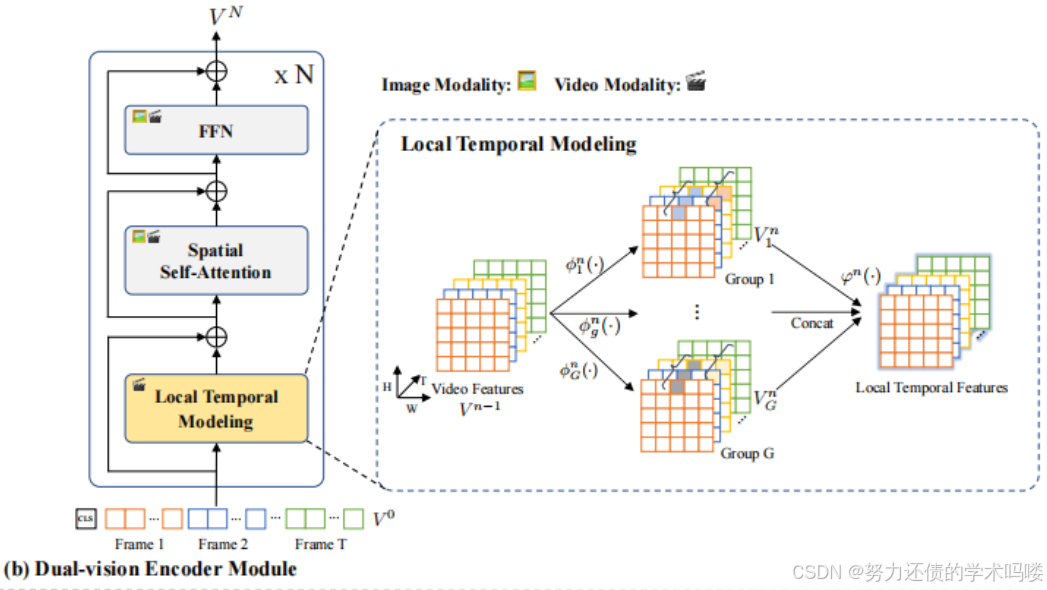
空间建模:利用Transformer中得Self-Attention(SA) + Feed Forward Network(FFN)
局部时间建模:Local Time ( L T LT LT)L N LN LN:归一化得缩写划分 G G G组是按照嵌入维度划分
具体流程是,对于一个视频 s h a p e = [ H , W , T , C ] shape=[H,W,T,C] shape=[H,W,T,C]其中 C C C代表hiddent state size也就是隐藏维度然后按照 G G G组将通道C划分成
s h a p e = [ H , W , T , G , C / / G ] shape=[H,W,T,G,C//G] shape=[H,W,T,G,C//G]
这里 V g n = R e L U ( A g n ϕ g n ( V n − 1 ) ) ∈ R T × C G V^n_g = ReLU(A^n_g \phi^n_g(V^{n-1})) \in \mathbb{R}^{T \times \frac{C}{G}} Vgn=ReLU(Agnϕgn(Vn−1))∈RT×GC (4)
V L T n = L N ( L T ( V n − 1 ) + V n − 1 ) V^n_{LT} = LN(LT(V^{n-1}) + V^{n-1}) VLTn=LN(LT(Vn−1)+Vn−1), (1) 【建模局部时序, V n − 1 V^{n-1} Vn−1指的是前面一层block的视觉表示】
3D卷积的使用方法详见我另外一篇博客->https://blog.csdn.net/2503_92010587/article/details/148979778?spm=1011.2415.3001.5331
【 L T LT LT,多组融合的Conv3d实现(对应公式4中的卷积核 A g n A^n_g Agn):】Local Temporal的代码实现【原文仓库】
class LocalTemporal(nn.Module): ''' input_shape : [bs, d_model, T, H, W] out_put_shape : [bs, d_model, T, H, W] ''' def __init__(self, d_model: int): super().__init__() d_bottleneck = d_model // 2 self.ln = LayerNorm(d_model) # 下采样in=d_model, out=d_bottleneck self.down_proj = nn.Conv3d(d_model, d_bottleneck, kernel_size=1, stride=1, padding=0) # 3D卷积建模Local局部时序表征 # in=out=d_bottle_neck self.conv = nn.Conv3d(d_bottleneck, d_bottleneck, kernel_size=(3, 1, 1), stride=1, padding=(1, 0, 0), groups=d_bottleneck) # kernal_size[0]=3,kernal_size[1]=1,kernal_size[2]=1则说明H,W维度是自己跟自己交互,而D维度也就是时间维度,跨不同帧交互 # 多层聚合 # 上采样in=d_model, out=d_bottleneck self.up_proj = nn.Conv3d(d_bottleneck, d_model, kernel_size=1, stride=1, padding=0) nn.init.constant_(self.up_proj.weight, 0) nn.init.constant_(self.up_proj.bias, 0) self.activation = QuickGELU() def forward(self, x): # initial x : [bs, d_model, T, H, W] 其中T是时间维度,也就是帧数 # x : [bs,T,H,W,d_model]为了在Channel归一化做准备 x = x.permute(0, 2, 3, 4, 1) # x: LayerNorm默认在最后一个维度 x = self.ln(x) # x: [bs,d_model, T, H, W] 恢复原维度 x = x.permute(0, 4, 1, 2, 3) # 下采样,降维投影层,将通道数从d_model降到d_bottleneck, # out x : [bs, d_bottleneck, T, H, W] x = self.down_proj(x) # 经过conv和activation: [bs, d_bottleneck, T, H, W] output_size = (input_size + 2*padding - kernel_size) / stride + 1 # 时间维度T: (T + 2*1 - 3) / 1 + 1 = T + 2 - 3 + 1 = T # 高度维度H: (H + 2*0 - 1) / 1 + 1 = H - 1 + 1 = H # 宽度维度W: (W + 2*0 - 1) / 1 + 1 = W - 1 + 1 = W x = self.activation(self.conv(x)) # 经过up_proj上采样,升维投影 : [bs, d_model, T,H, W] x = self.up_proj(x) return x
常见问题:
nn.LayerNorm是不是只在最后一个维度归一化?
不完全正确。Layer Norm的归一化维度取决于具体的实现和参数设置:
PyTorch中的LayerNorm:
nn.LayerNorm(normalized_shape)中的normalized_shape参数决定了归一化的维度- 如果
normalized_shape是一个整数,则只在最后一个维度归一化- 如果
normalized_shape是一个元组,则在对应的多个维度上归一化常见情况:
- 单维度归一化(最常见):
# 对于形状为 (batch, seq_len, hidden_dim) 的tensor layer_norm = nn.LayerNorm(hidden_dim) # 只在最后一个维度归一化
- 多维度归一化:
# 对于形状为 (batch, height, width, channels) 的tensor layer_norm = nn.LayerNorm((height, width, channels)) # 在后三个维度归一化与其他归一化的对比:
- Batch Norm: 在batch维度归一化
- Layer Norm: 在特征维度归一化(通常是除batch外的其他维度)
- Instance Norm: 在空间维度归一化
所以Layer Norm默认行为确实是在指定的特征维度进行归一化,最常见的是最后一个维度,但并不局限于此。在Transformer等模型中,通常确实是在最后一个维度(embedding/hidden dimension)进行归一化。
常见问题:那我如果是[N,C,T,H,.W]多维度归一化呢,反正他是默认在最后几个维度归一化,但是要传入shape匹配是吧?
是的
对于形状为[N,C,T,H,W]的张量, L a y e r N o r m LayerNorm LayerNorm需要你明确指定要归一化的维度形状:import torch import torch.nn as nn # 假设张量形状为 [N,C,T,H,W] = [2,64,10,32,32] x = torch.randn(2, 64, 10, 32, 32) # 不同的归一化方式: # 1. 只在最后一个维度 W 归一化 layer_norm1 = nn.LayerNorm(32) # normalized_shape = (32,) # 2. 在最后两个维度 H,W 归一化 layer_norm2 = nn.LayerNorm((32, 32)) # normalized_shape = (32, 32) # 3. 在最后三个维度 T,H,W 归一化 layer_norm3 = nn.LayerNorm((10, 32, 32)) # normalized_shape = (10, 32, 32) # 4. 在除batch外的所有维度 C,T,H,W 归一化 layer_norm4 = nn.LayerNorm((64, 10, 32, 32)) # normalized_shape = (64, 10, 32, 32) # 使用 out1 = layer_norm1(x) # 在W维度归一化 out2 = layer_norm2(x) # 在H,W维度归一化 out3 = layer_norm3(x) # 在T,H,W维度归一化 out4 = layer_norm4(x) # 在C,T,H,W维度归一化关键点:
normalized_shape必须与你想要归一化的末尾维度的形状完全匹配- LayerNorm总是从最后一个维度开始往前匹配
- batch维度(通常是第0维)永远不参与归一化
LayerNorm确实是在最后几个维度进行归一化,并且必须传入匹配的shape才能正确工作。
V S A n = L N ( S A ( V L T n − 1 ) + V L T n − 1 ) V^n_{SA} = LN(SA(V^{n-1}_{LT}) + V^{n-1}_{LT}) VSAn=LN(SA(VLTn−1)+VLTn−1), (2) 【再对前面一层的 V L T n − 1 V^{n-1}_{LT} VLTn−1是前面一层的时序视觉表示, S A SA SA用自注意力则为空间自注意力,进行空间建模】
V n = L N ( F F N ( V S A n ) + V S A n ) V^n = LN(FFN(V^n_{SA}) + V^n_{SA}) Vn=LN(FFN(VSAn)+VSAn), (3) 【残差学习保留原始知识,同时学习新的表示】
其中LN是层归一化的缩写。局部时间建模模块通过多组融合捕获具有相同空间位置的补丁(patch) 之间的【时间相关性】相关性,公式化为:
V g n = R e L U ( A g n ϕ g n ( V n − 1 ) ) ∈ R T × C G V^n_g = ReLU(A^n_g \phi^n_g(V^{n-1})) \in \mathbb{R}^{T \times \frac{C}{G}} Vgn=ReLU(Agnϕgn(Vn−1))∈RT×GC (4) 【其实这里就是一个patch的表示,分组卷积,为什么是TxC啊?因为T是时间维度,C是dmodel维度,把通道划分到不同子空间当中去做】
L T ( V n − 1 ) = ϕ n ( C o n c a t [ V 1 n ; ⋯ ; V G n ] ) LT(V^{n-1}) = \phi^n(Concat[V^n_1; \cdots; V^n_G]) LT(Vn−1)=ϕn(Concat[V1n;⋯;VGn]), (5) 【TxC,这个代表的是一个patch的表示】
其中== ϕ g n ( ⋅ ) \phi^n_g(\cdot) ϕgn(⋅)和 ϕ n ( ⋅ ) \phi^n(\cdot) ϕn(⋅)==是**线性变换**函数。
-
A g n A^n_g Agn是**可学习(Learnable)** 的时间关系参数,实例化为**卷积核**。
-
T和C是帧数和==隐藏状态的大小【嵌入维度,也就是Channel】== 。
-
G表示组数【Group】,
-
Concat表示连接函数。通过使用多组融合,模型能够从不同时间位置的独特表示子空间**中学习丰富的时间信息。
因此,除了局部时间模块外,双视觉编码器模块实现了图像和视频的**权重共享**,有效且高效地学习空间和时间表示。
时序块实现,TemporalBlock【原文仓库】TemporalBlock类定义(包含LT、SA、FFN的组合)
def drop_path(x, drop_prob: float = 0., training: bool = False): """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks). This is the same as the DropConnect impl I created for EfficientNet, etc networks, however, the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper... See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the argument. """ """Drop paths (Stochastic Depth) 每个样本(当应用在residual blocks的主路径时)。 这与我为EfficientNet等网络创建的DropConnect实现相同,然而, 原始名称具有误导性,因为'Drop Connect'是另一篇论文中不同形式的dropout... 参见讨论:https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... 我选择将层和参数名称更改为'drop path',而不是混用DropConnect作为层名称并使用 'survival rate'作为参数。 """ if drop_prob == 0. or not training: return x keep_prob = 1 - drop_prob shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device) random_tensor.floor_() # binarize output = x.div(keep_prob) * random_tensor return output class DropPath(nn.Module): """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks). """ def __init__(self, drop_prob=None): super(DropPath, self).__init__() self.drop_prob = drop_prob def forward(self, x): return drop_path(x, self.drop_prob, self.training) '''Flash Attention''' class MultiheadAttention(nn.MultiheadAttention): def __init__(self, embed_dim, num_heads, dropout=0, bias=True, add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None, batch_first=False, device=None, dtype=None) -> None: # assert flash_attn_unpadded_func is not None, "FlashAttention is not installed." super().__init__(embed_dim, num_heads, dropout, bias, add_bias_kv, add_zero_attn, kdim, vdim, batch_first, device, dtype) def attention( self, q, k, v, batch_size=1, seqlen=77, softmax_scale=None, attention_dropout=0.0, causal=False, cu_seqlens=None, max_s=None, need_weights=False ): """Implements the multihead softmax attention. Arguments --------- q,k,v: The tensor containing the query, key, and value. each of (B*S, H, D) key_padding_mask: a bool tensor of shape (B, S) """ assert not need_weights assert q.dtype in [torch.float16, torch.bfloat16] assert q.is_cuda if cu_seqlens is None: max_s = seqlen cu_seqlens = torch.arange(0, (batch_size + 1) * seqlen, step=seqlen, dtype=torch.int32, device=q.device) output = flash_attn_unpadded_func( q, k, v, cu_seqlens, cu_seqlens, max_s, max_s, attention_dropout, softmax_scale=softmax_scale, causal=causal ) return output def forward( self, query: Tensor, key: Tensor, value: Tensor, key_padding_mask: Optional[Tensor] = None, need_weights: bool = False, attn_mask: Optional[Tensor] = None, average_attn_weights: bool = True ) -> Tuple[Tensor, Optional[Tensor]]: # set up shape vars seqlen, batch_size, embed_dim = query.shape # in-projection and rearrange `s b (3 h d) -> s b (h d) -> (b s) h d` q, k, v = F.linear(query, self.in_proj_weight, self.in_proj_bias).chunk(3, dim=-1) q = q.transpose(0, 1).contiguous().view(batch_size * seqlen, self.num_heads, self.head_dim) k = k.transpose(0, 1).contiguous().view(batch_size * seqlen, self.num_heads, self.head_dim) v = v.transpose(0, 1).contiguous().view(batch_size * seqlen, self.num_heads, self.head_dim) # flash attention (use causal mask) causal = attn_mask is not None attn_output = self.attention(q, k, v, batch_size, seqlen, causal=causal) # out-projection # `(b s) h d -> s b (h d)` attn_output = attn_output.contiguous().view(batch_size, seqlen, self.num_heads, self.head_dim) attn_output = attn_output.transpose(0, 1).contiguous().view(seqlen, batch_size, embed_dim) attn_output = F.linear(attn_output, self.out_proj.weight, self.out_proj.bias) return attn_output, None class TemporalBlock(nn.Module): def __init__( self, d_model, n_head, attn_mask=None, drop_path=0.0, dw_reduction=1.5, config=None ): super().__init__() self.n_head = n_head#多个头 #初始化随机深度类,按照dorp_path的概率随机丢弃残差 self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity() self.config = config self.lmhra1 = LocalTemporal(d_model)# lmhra Local Multi-Head Regional Attention(局部多头区域注意力) self.lmhra2 = LocalTemporal(d_model) # spatial if flash_attn_unpadded_func: print("Using Flash Attention") self.attn = MultiheadAttention(d_model, n_head) else: self.attn = nn.MultiheadAttention(d_model, n_head) self.ln_1 = LayerNorm(d_model) self.mlp = nn.Sequential(OrderedDict([ ("c_fc", nn.Linear(d_model, d_model * 4)), ("gelu", QuickGELU()), ("c_proj", nn.Linear(d_model * 4, d_model)) ])) self.ln_2 = LayerNorm(d_model) self.attn_mask = attn_mask def attention(self, x): self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0] def forward(self, x, T=8, use_checkpoint=False): # x: 1+HW, NT, C tmp_x = x[1:, :, :] L, NT, C = tmp_x.shape N = NT // T H = W = int(L ** 0.5) tmp_x = tmp_x.view(H, W, N, T, C).permute(2, 4, 3, 0, 1).contiguous() # 公式中对应的残差链接 tmp_x = tmp_x + self.drop_path(self.lmhra1(tmp_x)) tmp_x = tmp_x.view(N, C, T, L).permute(3, 0, 2, 1).contiguous().view(L, NT, C) x = torch.cat([x[:1, :, :], tmp_x], dim=0) # MHSA x = x + self.drop_path(self.attention(self.ln_1(x))) if True: tmp_x = x[1:, :, :] tmp_x = tmp_x.view(H, W, N, T, C).permute(2, 4, 3, 0, 1).contiguous() tmp_x = tmp_x + self.drop_path(self.lmhra2(tmp_x)) tmp_x = tmp_x.view(N, C, T, L).permute(3, 0, 2, 1).contiguous().view(L, NT, C) x = torch.cat([x[:1, :, :], tmp_x], dim=0) # FFN x = x + self.drop_path(self.mlp(self.ln_2(x))) return
常见问题:什么是DropPath
DropPath(随机深度,Stochastic Depth) 是一种正则化技术,主要用于深度神经网络中的残差连接。
核心概念:
DropPath vs Dropout的区别:
- Dropout: 随机丢弃神经元(置零某些元素)
- DropPath: 随机丢弃整个路径(跳过整个分支/层)
- 当
drop_prob=0时,不跳过任何路径,DropPath完全失效。工作原理:
在残差块中:
# 正常的残差连接 output = x + F(x) # x是输入,F(x)是某个变换 # 使用DropPath的残差连接 output = x + DropPath(F(x)) # 有概率完全跳过F(x)随机行为:
- 训练时: 以
drop_prob概率完全跳过分支,直接返回输入x- 推理时: 不丢弃,但会对输出进行缩放补偿
具体实现逻辑:
def drop_path(x, drop_prob, training): if not training or drop_prob == 0: return x keep_prob = 1 - drop_prob # 生成随机mask,决定每个样本是否保留路径 random_tensor = keep_prob + torch.rand((x.shape[0], 1, 1, 1), device=x.device) binary_mask = torch.floor(random_tensor) # 0 or 1 # 缩放并应用mask output = x.div(keep_prob) * binary_mask return output应用场景:
- Vision Transformer (ViT) :在Transformer块的残差连接中
- EfficientNet:在MBConv块中
- ResNet变种:在残差连接中
优势:
- 缓解梯度消失:强制网络学会多条路径
- 正则化效果:减少过拟合
- 提升泛化:网络对路径失效更鲁棒
- 加速训练:训练时实际计算的层数减少
所以DropPath是一种路径级别的随机正则化,让网络在训练时随机"短路"某些分支,从而提升模型的鲁棒性。
DropPath原文-> https://arxiv.org/abs/1603.09382
原始论文: “Deep Networks with Stochastic Depth”
作者: Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, Kilian Q. Weinberger
发表信息: arXiv:1603.09382, 2016年3月30日
论文链接: https://arxiv.org/abs/1603.09382
核心思想:
论文提出了"随机深度"(Stochastic Depth)的概念,在训练时随机丢弃一部分层并用恒等函数绕过它们,从而实现训练短网络但测试时使用深网络的看似矛盾的设置。
术语演变:
- 原始术语: Stochastic Depth(随机深度)
- 实现名称: DropPath(路径丢弃)
- 原因: "stochastic depth"作为概念名称过于冗长,DropPath作为层名称更简洁,通过丢弃残差路径来实现随机深度
重要成果: 使用随机深度可以将残差网络深度增加到1200层以上,并在CIFAR-10上获得4.91%的测试错误率。
这篇论文是DropPath技术的理论基础,后来被广泛应用于Vision Transformer、EfficientNet等现代深度学习模型中。
常见问题:什么是FlashAttention
Flash Attention 是一种针对Transformer注意力机制的内存高效优化算法,旨在解决传统注意力机制在长序列上内存和计算的二次复杂度问题。
原始论文:
FlashAttention (第一版):
- 论文标题: “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”
- 作者: Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré
- 发表: arXiv:2205.14135, 2022年5月27日
- 链接: https://arxiv.org/abs/2205.14135
FlashAttention-2:
- 论文标题: “FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning”
- 作者: Tri Dao
- 发表: arXiv:2307.08691, 2023年7月17日
- 链接: https://arxiv.org/abs/2307.08691
核心思想:
问题:Transformers在长序列上速度慢且内存消耗大,因为自注意力的时间和内存复杂度在序列长度上是二次的
解决方案:FlashAttention是一个**IO感知的精确注意力算法,使用分块(tiling)** 来减少GPU高带宽内存(HBM)和GPU片上SRAM之间的**内存读写次数**
关键技术:
- 分块计算: 将大矩阵分块处理,避免存储中间的完整注意力矩阵
- 内存层次优化: 充分利用GPU的**内存层次结构(HBM vs SRAM)**
- 精确计算: 不是近似方法,保证与标准注意力完全相同的结果
性能提升: FlashAttention相比现有基线在BERT-large上实现15%的端到端加速,在GPT-2上实现3倍加速,在长序列任务上实现2.4倍**加速**
重要意义: Flash Attention使得第一个Transformer能够在Path-X挑战(序列长度16K)和Path-256(序列长度64K)上取得超过随机猜测的性能,极大地推动了长上下文模型的发展。
这项技术现在被广泛应用于各种大语言模型和长上下文应用中,是现代Transformer架构的重要优化基础。
【时序建模】【原文仓库】用TemporalBlock堆叠的TemporalTransformer
class TemporalTransformer(nn.Module): def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None, droppath=None, use_checkpoint=False, T=8, config=None): super().__init__() self.use_checkpoint = use_checkpoint if droppath is None: droppath = [0.0 for i in range(layers)] self.width = width self.layers = layers if use_checkpoint and checkpoint_wrapper: self.resblocks = nn.ModuleList([ checkpoint_wrapper(TemporalBlock(width, heads, attn_mask, droppath[i], config=config)) for i in range(layers)]) else: self.resblocks = nn.ModuleList([TemporalBlock(width, heads, attn_mask, droppath[i], config=config) for i in range(layers)]) def forward(self, x: torch.Tensor, T): L, NT, C = x.shape N = NT // T H = W = int((L - 1) ** 0.5) for i, resblock in enumerate(self.resblocks): x = resblock(x, T) return x
完整的VideoFormer
class VideoFormer(nn.Module): def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int, droppath = None, T = 8, use_checkpoint = False, config=None): super().__init__() self.input_resolution = input_resolution self.patch_size = patch_size self.output_dim = output_dim self.temporal_stride = config.get('temporal_stride', 2) self.temporal_downsampling = config.get('temporal_downsampling', False) if checkpoint_wrapper and use_checkpoint: self.conv1 = checkpoint_wrapper(nn.Conv3d( in_channels=3, out_channels=width, kernel_size=(3, patch_size, patch_size) if self.temporal_downsampling else (1, patch_size, patch_size), stride=(self.temporal_stride, patch_size, patch_size) if self.temporal_downsampling else (1, patch_size, patch_size), padding=(1, 0, 0) if self.temporal_downsampling else (0, 0, 0), bias=False )) else: self.conv1 = nn.Conv3d( in_channels=3, out_channels=width, kernel_size=(3, patch_size, patch_size) if self.temporal_downsampling else (1, patch_size, patch_size), stride=(self.temporal_stride, patch_size, patch_size) if self.temporal_downsampling else (1, patch_size, patch_size), padding=(1, 0, 0) if self.temporal_downsampling else (0, 0, 0), bias=False ) scale = width ** -0.5 self.class_embedding = nn.Parameter(scale * torch.randn(width)) self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width)) self.ln_pre = LayerNorm(width) ## Attention Blocks self.transformer = TemporalTransformer(width, layers, heads, droppath=droppath, use_checkpoint=use_checkpoint, config=config) self.ln_post = LayerNorm(width) self.proj = nn.Parameter(scale * torch.randn(width, output_dim)) ## Temporal Related self.num_frames = T self.config = config # Initalization trunc_normal_(self.positional_embedding, std=.02) trunc_normal_(self.class_embedding, std=.02) # self.apply(self._init_weights) def init_weights(self): self.apply(self._init_weights) def _init_weights(self, m): if isinstance(m, nn.Linear) or isinstance(m, nn.Conv3d): trunc_normal_(m.weight, std=.02) if m.bias is not None: nn.init.constant_(m.bias, 0) elif isinstance(m, nn.LayerNorm): nn.init.constant_(m.bias, 0) nn.init.constant_(m.weight, 1.0) def forward(self, x: torch.Tensor, skip_last_layer=False, use_checkpoint=True): B, C, T, H, W = x.shape x = self.conv1(x) T, H, W = x.shape[-3:] x = rearrange(x, 'b d t h w -> (b t) (h w) d') x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width] x = x + self.positional_embedding.to(x.dtype) x = self.ln_pre(x) x = x.permute(1, 0, 2) x = self.transformer(x, T) # x 1+HW, NT, C x = rearrange(x, 'n (b t) d -> b t n d', b=B) cls_token = x[:,:,0,:].mean(1).unsqueeze(1) # [b, 1, d] x = x[:,:,1:,:] x = rearrange(x, 'b t n d -> b (t n) d') x = torch.cat([cls_token, x], dim=1) # x = rearrange(x, 'n bt d -> bt n d') x = self.ln_post(x) return x
核心模块公式解析
局部时间建模 (Local Time LT) 公式
V L T n = L N ( L T ( V n − 1 ) + V n − 1 ) ( 1 ) V_{LT}^n = LN(LT(V^{n-1}) + V^{n-1}) \quad (1) VLTn=LN(LT(Vn−1)+Vn−1)(1)
符号解释:
- V L T n V_{LT}^n VLTn:第n层的**局部时间特征**输出
- L N LN LN:Layer Normalization(层归一化)
- L T LT LT:Local Time局部时间建模函数
- V n − 1 V^{n-1} Vn−1:第n-1层的输入特征
- n n n:当前层数(上角标)
含义: 使用残差连接和层归一化的局部时间建模
残差连接的深层思想和直观理解
核心思想:学习"改进量"而非"从头开始"
残差连接的本质是让网络学习如何在原有基础上进行改进,而不是从零开始重新构建所有信息。
生活化类比
想象你在修改一篇文章:
- 传统方式:每次修改都要重写整篇文章
- 残差方式:在原文基础上标注修改建议,最终版本 = 原文 + 修改建议
数学表达的直观含义
V L T n = L N ( L T ( V n − 1 ) + V n − 1 ) V_{LT}^n = LN(LT(V^{n-1}) + V^{n-1}) VLTn=LN(LT(Vn−1)+Vn−1)
这个公式可以理解为:
- V n − 1 V^{n-1} Vn−1:原始信息(保持不变的基础)
- L T ( V n − 1 ) LT(V^{n-1}) LT(Vn−1):局部时间建模学到的"改进建议"
- + + +:把改进建议加到原始信息上
- L N LN LN:最后做一次规范化处理
深层优势
1. 避免信息丢失
- 原始信息通过 + V n − 1 +V^{n-1} +Vn−1 直接传递到下一层
- 即使 L T LT LT 函数表现不好,原始信息依然保留
2. 梯度流动更顺畅
- 反向传播时,梯度可以直接通过残差连接传回
- 避免【这里缓解是不是更好?】了深网络中的梯度消失问题
3. 学习更容易
- 网络只需要学习"需要改变什么"
- 而不是学习"完整的目标输出"
4. 模块化设计
- 每一层可以专注于特定的改进任务
- 如果某层没有贡献,可以学习输出接近0的值
在视频理解中的意义
对于局部时间建模:
- 保留原始帧特征的同时
- 添加时间维度的理解
- 让模型既能记住"看到了什么",又能理解"时间上发生了什么变化"
这就像是在观看视频时,我们既记住每一帧的内容,又能感知帧与帧之间的运动和变化关系。【而这里具体指的是帧局部于帧局部之间的运动和变化关系】
空间建模 (Spatial Attention) 公式
V S A n = L N ( S A ( V L T n − 1 ) + V L T n − 1 ) ( 2 ) V_{SA}^n = LN(SA(V_{LT}^{n-1}) + V_{LT}^{n-1}) \quad (2) VSAn=LN(SA(VLTn−1)+VLTn−1)(2)
符号解释:
- V S A n V_{SA}^n VSAn:第n层的空间注意力特征输出
- S A SA SA:Spatial Attention(空间注意力)
- V L T n − 1 V_{LT}^{n-1} VLTn−1:第n-1层局部时间特征(下角标LT表示来源)
前向网络 (FFN) 公式
V n = L N ( F F N ( V S A n ) + V S A n ) ( 3 ) V^n = LN(FFN(V_{SA}^n) + V_{SA}^n) \quad (3) Vn=LN(FFN(VSAn)+VSAn)(3)
符号解释:
- V n V^n Vn:第n层的最终输出特征
- F F N FFN FFN:Feed Forward Network(前向神经网络)
- V S A n V_{SA}^n VSAn:第n层空间注意力特征
分组特征公式
V g n = R e L U ( A g n ϕ g n ( V n − 1 ) ) ∈ R T × C G ( 4 ) V_g^n = ReLU(A_g^n \phi_g^n(V^{n-1})) \in \mathbb{R}^{T \times \frac{C}{G}} \quad (4) Vgn=ReLU(Agnϕgn(Vn−1))∈RT×GC(4)
符号解释:
- V g n V_g^n Vgn:第n层的分组特征
- A g n A_g^n Agn:可学习的时间关系参数矩阵
- ϕ g n \phi_g^n ϕgn:线性变换函数
- T T T:时间维度大小
- C C C:hidden state隐藏维度大小
- G G G:分组数量
- R T × G \mathbb{R}^{T \times G} RT×G:T×G维实数矩阵空间
局部时间建模具体实现
L T ( V n − 1 ) = ϕ n ( C o n c a t [ V 1 n ; ⋯ ; V G n ] ) ( 5 ) LT(V^{n-1}) = \phi^n(Concat[V_1^n; \cdots ; V_G^n]) \quad (5) LT(Vn−1)=ϕn(Concat[V1n;⋯;VGn])(5)
符号解释:
- ϕ n \phi^n ϕn:线性变换函数
- C o n c a t Concat Concat:拼接操作
- V 1 n , V 2 n , … , V G n V_1^n, V_2^n, \ldots, V_G^n V1n,V2n,…,VGn:G个分组的特征
- ; ; ;:表示拼接维度
- ⋯ \cdots ⋯:省略号,表示中间的分组
关键角标含义总结
上角标:
- n n n:层数索引
- n − 1 n-1 n−1:前一层
下角标:
- L T LT LT:Local Time(局部时间)
- S A SA SA:Spatial Attention(空间注意力)
- g g g:group(分组)
- 1 , 2 , … , G 1, 2, \ldots, G 1,2,…,G:分组索引
这个架构通过局部时间建模、空间注意力和前向网络的组合,实现了对视频序列的有效编码,每一步都使用了残差连接和层归一化来稳定训练过程。
end
(Text Encoder Module)文本编码器模块 对于文本编码器模块,我们使用BERT(Devlin et al., 2018)作为文本编码器,它将输入文本和**额外的[CLS]****标记token转换为文本嵌入序列。 [CLS] 标记的嵌入用于总结输入文本**。
本文原文Universal Layers Module
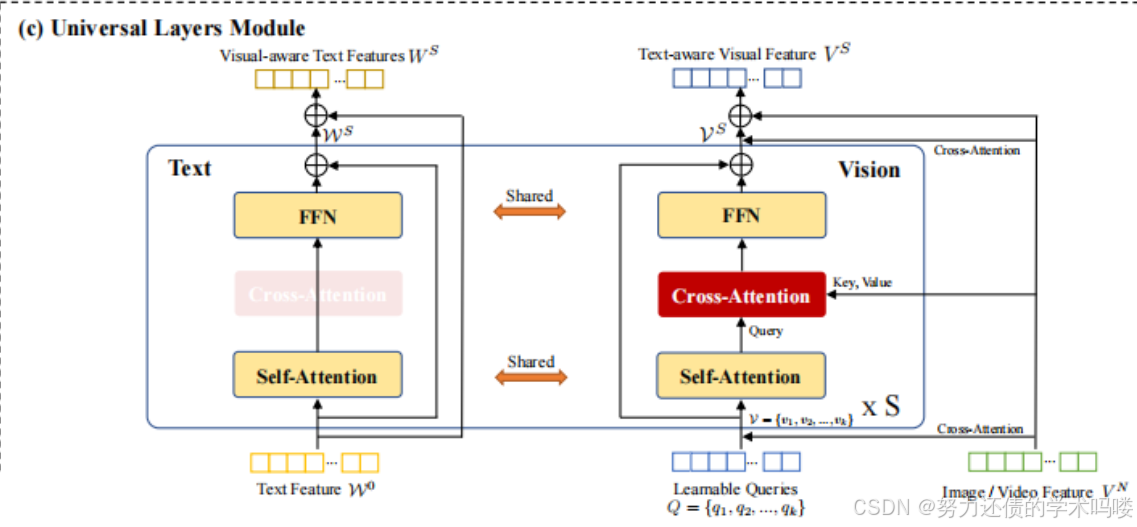
(Universal Layers Module T)通用层模块 为了从模态协作中受益,我们提出通用层在**共享语义空间中建模视觉和语言模态**,同时保留不同模态的原始表示。
在通用模块之前,我们从双视觉编码器获取**可变数量的图像或视频特征 V N V^N VN作为输入,以生成固定数量k的视觉标记token V = { v 1 , v 2 , . . . , v k } V = \{v_1, v_2, ..., v_k\} V={v1,v2,...,vk},以减少通用层的计算复杂度。在第 i i i个通用层中,视觉标记token V i − 1 V^{i-1} Vi−1和文本表示 W i − 1 W^{i-1} Wi−1被馈送到==共享的自注意力层==以对齐语义,然后通过交叉注意力层将视觉标记token注入到原始视觉特征空间中以保持原始表示**。
V S A i = L N ( S A ( V i − 1 ) + V i − 1 ) V^i_{SA} = LN(SA(V^{i-1}) + V^{i-1}) VSAi=LN(SA(Vi−1)+Vi−1) (6)
W S A i = L N ( S A ( W i − 1 ) + W i − 1 ) W^i_{SA} = LN(SA(W^{i-1}) + W^{i-1}) WSAi=LN(SA(Wi−1)+Wi−1) (7)
V C A i = L N ( C A ( V S A i , V n ) + V S A i ) V^i_{CA} = LN(CA(V^i_{SA}, V^n) + V^i_{SA}) VCAi=LN(CA(VSAi,Vn)+VSAi) (8)
V i = L N ( F F N ( V C A i ) + V C A i ) V^i = LN(FFN(V^i_{CA}) + V^i_{CA}) Vi=LN(FFN(VCAi)+VCAi) (9)
W i = L N ( F F N ( W S A i ) + W S A i ) W^i = LN(FFN(W^i_{SA}) + W^i_{SA}) Wi=LN(FFN(WSAi)+WSAi) (10)
然后 [ V i ; W i ] [V^i; W^i] [Vi;Wi]被**重复馈送到下一个通用层以获得最终的共同图像和文本表示**。最后,通用层的输出 [ V S ; W S ] [V^S; W^S] [VS;WS]通过交叉注意力层与原始表示 [ V N ; W M ] [V^N; W^M] [VN;WM]结合,用于文本感知的视觉和视觉感知的文本表示,其中S、N、M分别是通用模块、双视觉编码器和文本编码器的层数。
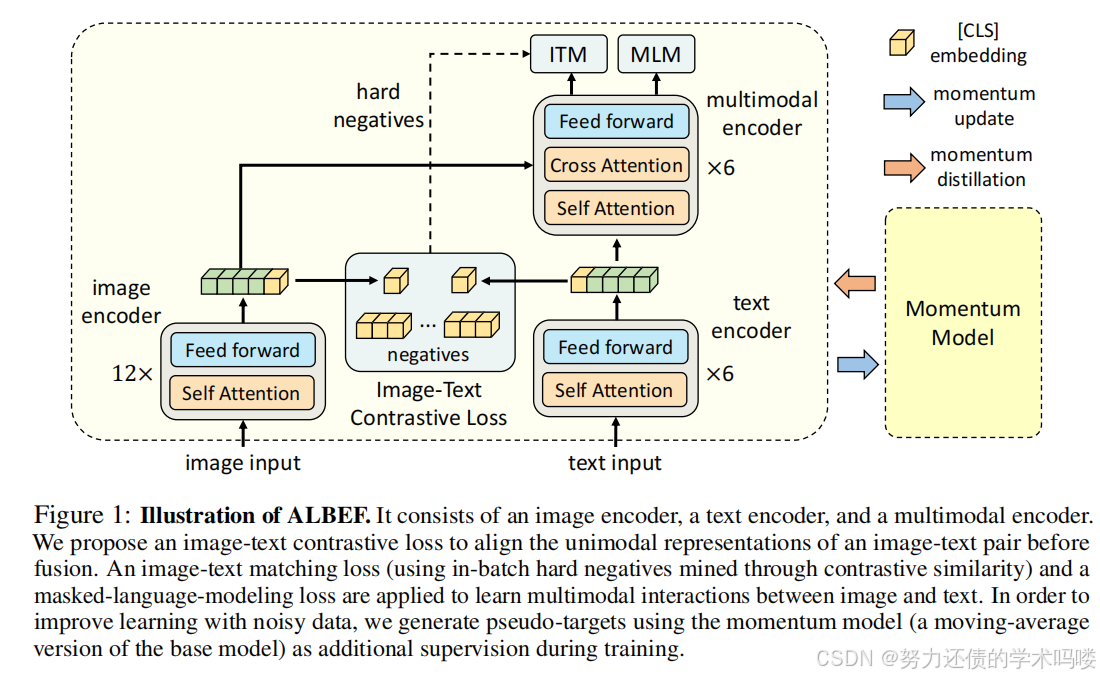
(Fusion Module)融合模块 为了有效捕获**视觉和语言模态之间的跨模态交互,我们使用ALBEF(Li et al., 2021b)中的融合模块,它由一堆带有交叉注意力层的Transformer块组成。具体来说,融合模块将来自通用层模块的文本嵌入作为输入。然后,文本感知的视觉嵌入在语言共享的公共空间中交叉关注视觉感知的文本嵌入。通过级联带有交叉注意力层的Transformer块,融合模块能够产生多模态视觉-语言**表示。
下图是ALBEF的结构图,融合模块为Multimodal多模态Encoder
(Shared Decoder Module)共享解码器模块 为了赋予模型生成能力,引入了共享解码器模块,使模型能够使用单模态和多模态信息生成文本。详细地说,共享解码器模块是一个具有任意输入的Transformer解码器。例如,图像字幕只需要视觉特征,而多模态特征用于视觉问答。通过接受不同类型的输入,我们的共享解码器模块可以适应各种文本生成任务。共享解码器模块有助于多任务预训练和迁移学习。
就一句话:共享解码器模块是一个具有任意输入的Transformer解码器
作用:可以接受不同类型的输入,适应各种文本生成任务
3.2. 统一预训练目标
我们使用以下三个目标联合训练mPLUG-2的多个模块。
(Language Loss)语言损失 对于文本编码器模块,我们使用BERT(Devlin et al., 2018)中的掩码语言建模(MLM)来学习文本表示。我们在文本中随机掩码15%的标记,模型被要求使用上下文表示预测这些掩码标记。
(Multi-modal Loss)多模态损失 对于跨模态模块,我们采用ALBEF(Li et al., 2021b)中的**跨模态匹配损失**(CML=ITC(VLC)+ITM(VLM)),它由视觉-语言匹配(VLM)和视觉-语言对比学习(VLC)组成。
ALBEF原文中确实没有明确使用"跨模态匹配损失(CML)"这个术语。
【ALBEF原文中的损失函数】
ALBEF中有三个主要损失:
- ITC (Image-Text Contrastive) - 图像文本对比损失
- ITM (Image-Text Matching) - 图像文本匹配损失
- MLM (Masked Language Modeling) - 掩码语言建模损失
【可能的混淆来源】
1. 术语变化:
ITM = Image-Text Matching
有时在其他论文中被称为:
- Cross-Modal Matching Loss (CML)
- Cross-Modal Alignment Loss
- Multi-modal Matching Loss
- 不同论文的命名:
ALBEF: 使用 ITM
CLIP: 使用 Contrastive Loss
ALIGN: 使用 Alignment Loss
其他论文: 可能使用 CML【ITM就是跨模态匹配的实现】
ALBEF中的ITM损失本质上就是跨模态匹配损失:
ITM: 二分类任务
输入: [图像, 文本] pair
输出: [匹配概率, 不匹配概率]
损失: 交叉熵损失这就是跨模态匹配的实现方式
【结论】
- ALBEF原文: 使用术语"ITM (Image-Text Matching)"
- 功能等价: ITM = 跨模态匹配损失的实现
- CML术语: 可能出现在其他论文或综述中,指代类似功能
您的观察很准确!ALBEF确实没有显式使用"CML"这个缩写,都是用的"ITM"。可能是在阅读其他相关论文时看到了CML这个术语。
【总结】
ALBEF提到的
ITM【原文Image Text Matching】 = VLM【Vision Language Matching】跨模态匹配损失的实现
ITC【愿望Image Text Contrast】=VLC【Vision Language Contrast】
(Instruction-based Language Model Loss)基于指令的语言模型损失 遵循Flamingo(Alayrac et al., 2022)和OFA(Wang et al., 2022d),我们采用基于**指令的语言模型损失来统一各种生成任务。我们使用手工制作的指令来区分任务和模态,包括视频/图像-文本对、视频/图像字幕、视频/图像问答、文本生成**等。
以下是两篇论文的原文链接:
Flamingo论文
ArXiv链接:https://arxiv.org/abs/2204.14198
论文信息:
- 标题: “Flamingo: a Visual Language Model for Few-Shot Learning”
- 作者: Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, Karen Simonyan
- 发表: NeurIPS 2022
- 提交时间: 2022年4月29日
OFA论文
ArXiv链接:https://arxiv.org/abs/2202.03052
论文信息:
- 标题: “OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework”
- 作者: Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, Hongxia Yang
- 发表: ICML 2022
- 提交时间: 2022年2月7日
其他相关资源
GitHub代码仓库:
- OFA: https://github.com/OFA-Sys/OFA
- Flamingo: DeepMind团队的工作,暂无公开代码
PDF直接下载:
这两篇论文都是多模态大模型领域的重要工作,提出了基于指令的统一学习框架,为后续的多模态模型发展奠定了重要基础。
【基于指令的语言模型损失 (Instruction-based Language Model Loss)】
核心思想:
通过在输入中添加任务特定的指令,将所有多模态生成任务统一为条件语言建模问题,实现"一个模型处理多种任务"的目标。数学公式:
基础损失函数:
L I L M = − E ( x , y , t ) ∼ D [ ∑ i = 1 ∣ y ∣ log P ( y i ∣ x , I ( t ) , y < i ) ] L_{ILM} = -\mathbb{E}_{(x,y,t)\sim D} \left[ \sum_{i=1}^{|y|} \log P(y_i | x, I(t), y_{<i}) \right] LILM=−E(x,y,t)∼D i=1∑∣y∣logP(yi∣x,I(t),y<i)
符号详解:
- x x x: 输入数据(图像/视频/文本)
- y y y: 目标输出序列
- t t t: 任务类型标识
- I ( t ) I(t) I(t): 基于任务类型的指令模板
- y < i y_{<i} y<i: 前i-1个已生成的token
- y i y_i yi: 第i个目标token
条件概率展开:
P ( y i ∣ x , I ( t ) , y < i ) = softmax ( f θ ( [ x ; I ( t ) ; y < i ] ) ) P(y_i | x, I(t), y_{<i}) = \text{softmax}(f_{\theta}([x; I(t); y_{<i}])) P(yi∣x,I(t),y<i)=softmax(fθ([x;I(t);y<i]))
其中:
- f θ f_{\theta} fθ: 参数为θ的语言模型
- [ x ; I ( t ) ; y < i ] [x; I(t); y_{<i}] [x;I(t);y<i]: 输入序列的拼接
多任务联合损失:
L t o t a l = ∑ t ∈ T λ t ⋅ L I L M ( t ) L_{total} = \sum_{t \in \mathcal{T}} \lambda_t \cdot L_{ILM}^{(t)} Ltotal=t∈T∑λt⋅LILM(t)
其中:
- T \mathcal{T} T: 所有任务类型集合
- λ t \lambda_t λt: 任务t的权重系数
指令模板设计:
视觉理解任务:
图像描述: “Generate a caption for this image:”
视频描述: “Describe what happens in this video:”
视觉问答: “Answer the question about this image: [问题]”
视频问答: “Answer the question about this video: [问题]”
文本生成任务:
文本补全: “Complete this text:”
对话生成: “Respond to this conversation:”
摘要生成: “Summarize this text:”
具体应用示例:
图像描述任务:
输入: [猫的图像] + “Generate a caption for this image:”
目标: “A orange cat sitting on a blue sofa.”
训练: 最大化目标序列的条件概率
视觉问答任务:
输入: [狗的图像] + “Answer the question about this image: What is the dog doing?”
目标: “The dog is running in the park.”
训练: 最大化答案序列的条件概率
视频理解任务:
输入: [跑步视频] + “Describe what happens in this video:”
目标: “A person is jogging along the beach at sunset.”
训练: 最大化描述序列的条件概率
核心优势:
1. 任务统一:
传统方法: 每个任务需要专门的输出头和损失函数
指令方法: 所有任务都是条件文本生成,共享模型架构
2. 模态统一:
图像任务: [图像] + 指令 → 文本 视频任务: [视频] + 指令 → 文本
文本任务: [文本] + 指令 → 文本
3. 扩展性强:
新任务: 只需设计新的指令模板
无需修改模型架构或添加新的损失函数
4. 训练效率:
多任务共享参数,相互促进学习
避免了为每个任务单独训练模型的开销
与传统多任务学习的对比:
传统方法:
图像描述: CNN + LSTM + 描述损失 视觉问答: CNN + Transformer + 分类损失
文本生成: GPT + 语言建模损失 问题: 不同任务需要不同架构和损失指令方法:
所有任务: 多模态编码器 + 语言解码器 + 统一语言建模损失
优势: 架构统一,训练简化,任务间知识共享
实现细节:
指令嵌入:
指令通常作为特殊token嵌入到输入序列中
与图像/视频特征和文本token一起送入模型
训练策略:
混合批次训练: 每个batch包含来自不同任务的样本
任务平衡: 通过λt调整各任务的损失权重
课程学习: 可以先训练简单任务,再训练复杂任务
关键技术要点:
1. 指令设计原则:
清晰明确: 指令要准确描述任务要求
简洁统一: 保持指令格式的一致性
可扩展: 便于添加新任务的指令
2. 序列构建:
多模态输入: [视觉特征] + [指令token] + [文本token]
注意力机制: 允许跨模态的信息交互
位置编码: 区分不同模态和序列位置
这种基于指令的统一框架代表了多模态大模型发展的重要方向,实现了真正的"一个模型,多种能力"。
4. 实验(Experiment)
4.1. 训练设置(Training Setup)
预训练数据集 遵循以前的工作(Li et al., 2021b; 2022a),我们使用相同的流行图像-文本数据集预训练我们的模型,包含1400万张图像,包括MS COCO(Lin et al., 2014)、Visual Genome(Krishna et al., 2017)、Conceptual Captions 3M(Sharma et al., 2018)、Conceptual Captions 12M(Changpinyo et al., 2021)和SBU Captions(Ordonez et al., 2011)。对于视频-文本数据集,我们采用网络来源的视频数据集WebVid-2M(Bain et al., 2021a),包含250万个视频-文本对。文本数据集包括WikiCorpus(Devlin et al., 2018)(约20GB)和清理后的common crawl(约350GB)。后者的收集和清理方法与c4(Raffel et al., 2020)中使用的方法基本相同。预训练的实现细节可在附录中找到。
图像-文本数据集
总计:1400万张图像
- MS COCO (Lin et al., 2014)
- Visual Genome (Krishna et al., 2017)
- Conceptual Captions 3M (Sharma et al., 2018)
- Conceptual Captions 12M (Changpinyo et al., 2021)
- SBU Captions (Ordonez et al., 2011)
视频-文本数据集
WebVid-2M (Bain et al., 2021a)
- 来源:网络视频数据集
- 规模:250万个视频-文本对
纯文本数据集
WikiCorpus (Devlin et al., 2018)
- 规模:约20GB
Common Crawl(清理后)
- 规模:约350GB
- 处理方式:采用与c4 (Raffel et al., 2020) 基本相同的收集和清理方法
总结:该预训练方案采用了多模态数据集组合,涵盖图像-文本、视频-文本和纯文本三个维度,遵循了Li et al. (2021b; 2022a) 的经典数据集配置。
4.2. 主要结果(Main Results)
我们在超过30个基准上评估了mPLUG-2的新统一范式,包括视觉-语言任务(例如多模态检索、问答和字幕)(Xu et al., 2016; 2017; Chen & Dolan, 2011)、仅语言任务(例如文本分类、问答和摘要)(Wang et al., 2018; Rush et al., 2015a)和仅视觉任务(例如图像分类和视频动作识别)(Deng et al., 2009; Kay et al., 2017)。特别地,视觉-语言基准可以分为图像-文本部分和视频-文本部分。这些数据集的详细信息可在附录中找到。
视觉-语言任务
图像-文本部分
- 多模态检索 (Xu et al., 2016; 2017)
- 问答 (Xu et al., 2016; 2017)
- 字幕生成 (Chen & Dolan, 2011)
视频-文本部分
- 多模态检索
- 问答
- 字幕生成
仅语言任务
- 文本分类 (Wang et al., 2018)
- 问答 (Rush et al., 2015a)
- 摘要生成 (Rush et al., 2015a)
仅视觉任务
- 图像分类 (Deng et al., 2009)
- 视频动作识别 (Kay et al., 2017)
评估规模:mPLUG-2的新统一范式在超过30个基准上进行了全面评估,涵盖了多模态、单模态语言和单模态视觉三个主要任务领域。详细的数据集信息可在附录中查阅。
4.2.1. 多模态任务(MULTI-MODAL TASK)
文本到视频检索(Text-to-video Retrieval) 我们在MSRVTT(Xu et al., 2016)、DiDeMo(Anne Hendricks et al., 2017)和LSMDC(Rohrbach et al., 2015)数据集上将mPLUG-2与几种最先进的方法进行比较。结果总结在表3中。我们可以观察到,mPLUG-2在大多数数据集上都优于以前的SoTA方法。特别是,与HiTeA相比,我们的方法在LSMDC数据集上的R@1方面提高了5.7%,这表明所提出的模型可以通过提出的局部时间建模模块利用丰富的电影片段中呈现的时间信息。
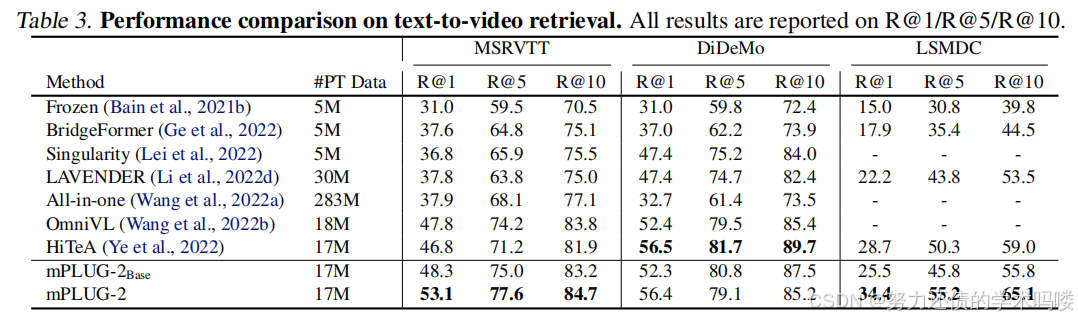
表3. 文本到视频检索的性能比较。所有结果都报告为R@1/R@5/R@10。
视频问答(Video Question Answering) 表4总结了MSRVTT-QA(Xu et al., 2017)、MSVD-QA(Xu et al., 2017)和TGIF-FrameQA(Jang et al., 2017)上的视频问答结果。可以观察到,mPLUG-2在MSRVTT-QA和TGIF-FrameQA上以很大的优势超越了所有现有的基础模型,并且在MSVD-QA上也取得了与大型基础模型GIT2(Wang et al., 2022c)相当的结果,即使使用的预训练数据量要少得多。特别是,mPLUG-2在MSRVTT上实现了0.6%的绝对改进,在TGIF-FrameQA上实现了0.5%的绝对改进。此外,mPLUG-2Base与大型模型(即VideoCoCa和GIT2)相比,在较小的模型规模下取得了可比的结果。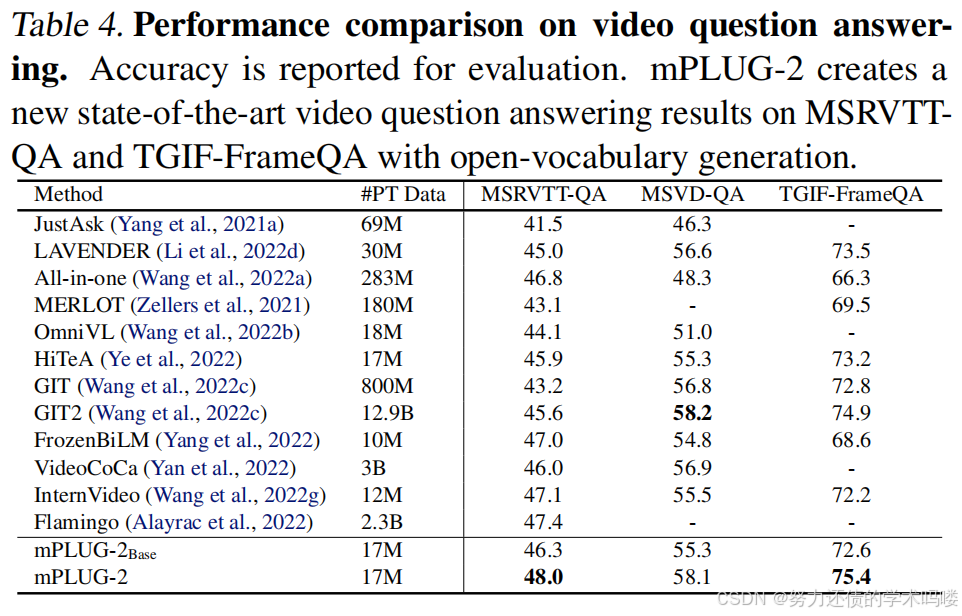
表4. 视频问答的性能比较。报告准确率用于评估。mPLUG-2在MSRVTT-QA和TGIF-FrameQA上以开放词汇生成创建了新的最先进视频问答结果。
视频字幕(Video Captioning) 表5比较了mPLUG-2与现有方法在视频字幕数据集MSRVTT和MSVD上的结果。如表所示,尽管在较少的数据上进行预训练,mPLUG-2在MSRVTT数据集上取得了显著的改进,在MSVD数据集上取得了可比的性能。在MSRVTT字幕上,我们的方法在CIDEr上超过SoTA方法VideoCoCa(Yan et al., 2022)和GIT2(Wang et al., 2022c)4.4%,在BLEU@4上超过3.0%。此外,我们可以注意到mPLUG-2在相同数量的预训练数据下优于HiTeA,这表明mPLUG-2能够生成更强的视频-语言表示。
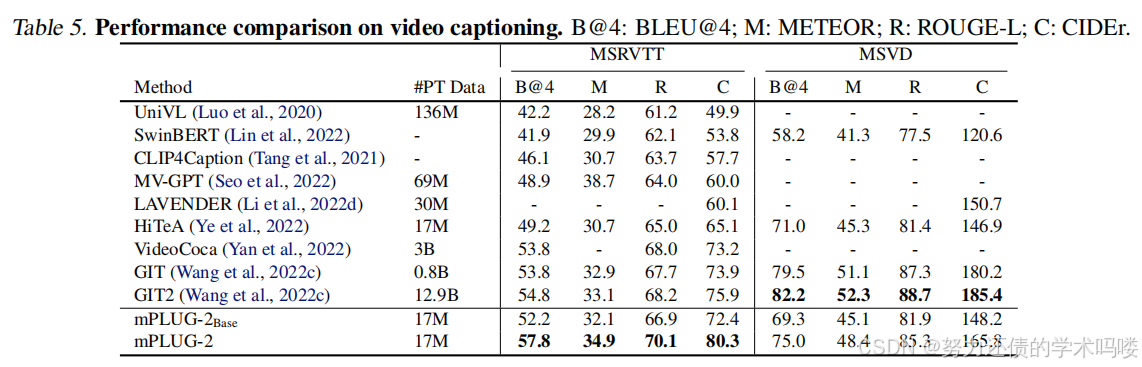
表5. 视频字幕的性能比较。B@4:BLEU@4;M:METEOR;R:ROUGE-L;C:CIDEr。
视觉定位(Visual Grounding ) 我们在视觉定位数据集上将mPLUG-2与现有的最先进方法进行比较,包括RefCOCO(Yu et al., 2016)、RefCOCO+(Yu et al., 2016)和RefCOCOg(Mao et al., 2016)。表7显示mPLUG-2达到了与最先进方法相当的性能。我们的方法在RefCOCO"testB"分割上比第二好的方法实现了0.97%的绝对改进,而没有使用对象检测数据进行预训练。"testB"分割中的查询可以指代各种视觉概念,但"testA"中只能指代人。这一改进表明,引入通用层可以帮助对图像中的视觉概念进行建模。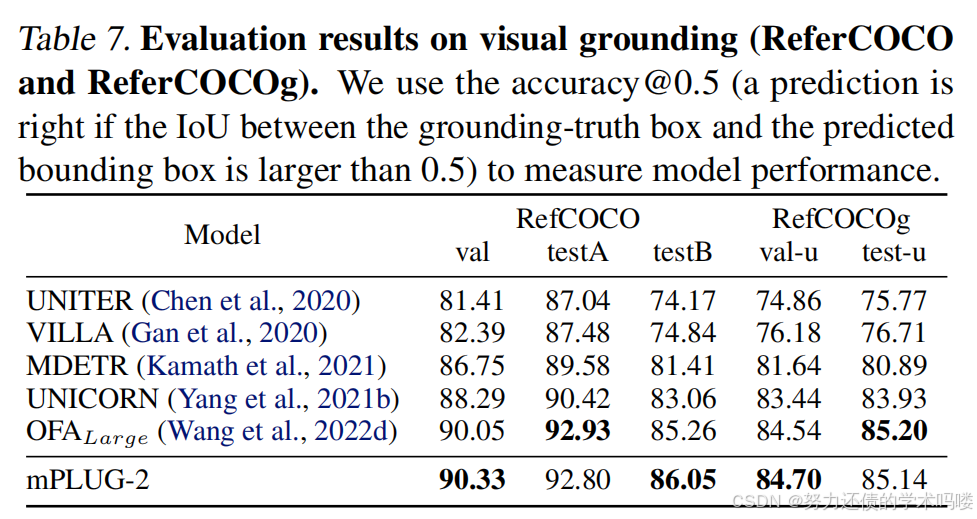
表7. 视觉定位(RefCOCO和RefCOCOg)的评估结果。我们使用accuracy@0.5(如果真实框和预测边界框之间的IoU大于0.5,则预测正确)来衡量模型性能。
图像-文本检索(Image-Text Retrieval) 我们在图像-文本检索数据集MSCOCO和Flickr30k上评估mPLUG-2。如表6所示,mPLUG-2Base和mPLUG-2都达到了与最先进方法相当或更好的性能。Florence(Yuan et al., 2021)和BLIP(Li et al., 2022c)分别使用0.9B和129M数据进行预训练。相比之下,我们的mPLUG-2只需要17M数据。这表明mPLUG-2是数据高效的。
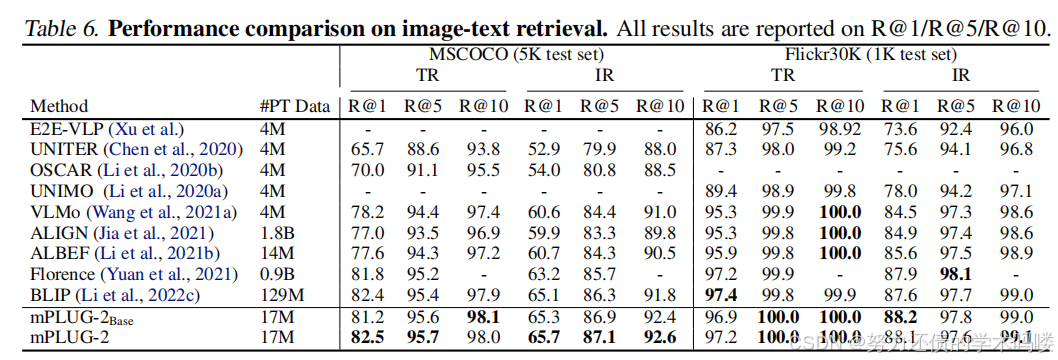
表6. 图像-文本检索的性能比较。所有结果都报告为R@1/R@5/R@10。
视觉问答(Visual Question Answering) 我们报告了mPLUG-2在视觉问答测试集上的性能。mPLUG-2在test-dev上超过最先进方法Florence(Yuan et al., 2021)0.95%,在test-std上超过0.77%。我们模型中使用的预训练数据规模比Florence少89.11%。这表明我们的mPLUG-2可以高效且有效地学习多模态表示。
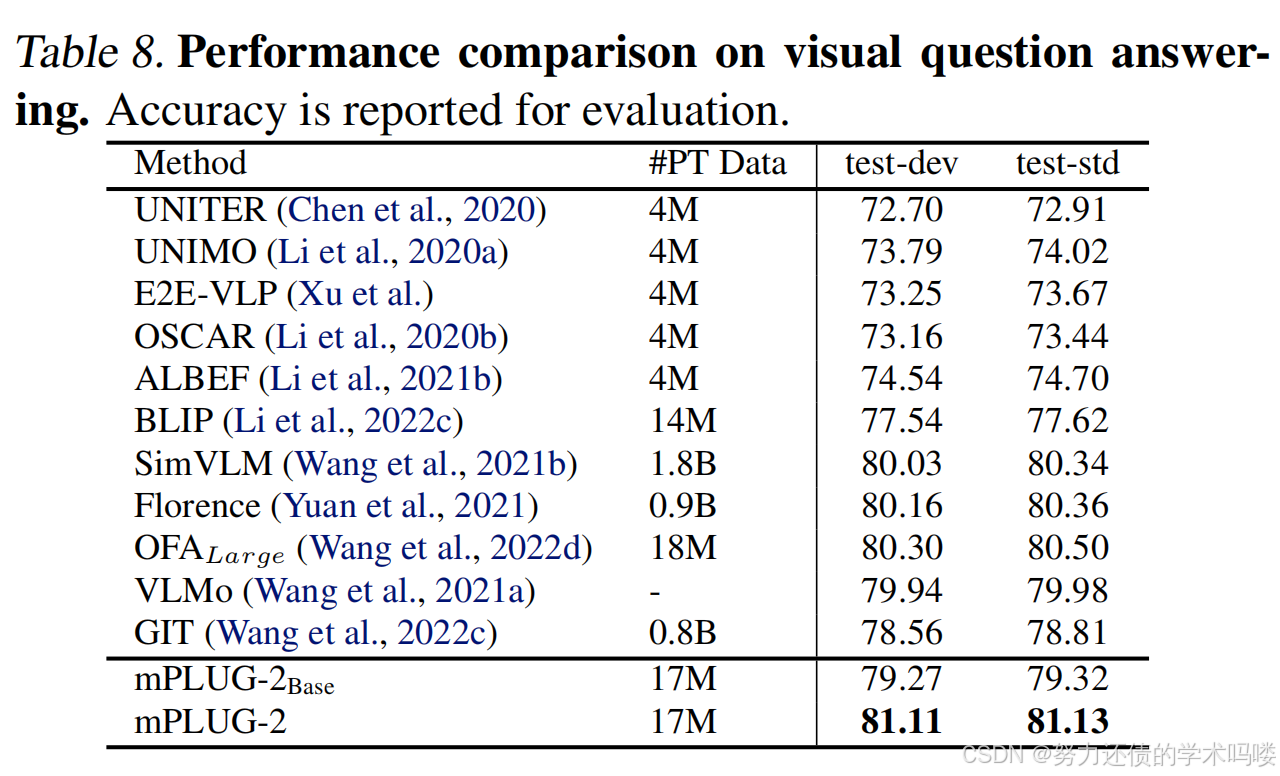
表8. 视觉问答的性能比较。报告准确率用于评估。
图像字幕(Image Captioning) 我们在MSCOCO(Lin et al., 2014)上将mPLUG-2与现有的最先进方法进行比较。遵循(Li et al., 2020b),我们在COCO Caption上使用交叉熵损失训练mPLUG-2,并在相同的Karpathy分割上进行测试。如表9所示,我们的mPLUG-2在COCO Caption上实现了新的SoTA结果。此外,我们的方法与大型基础模型取得了竞争性结果,如LEMON(Hu et al., 2021)和BLIP(Li et al., 2022c),它们使用了近10倍的预训练数据量。具体来说,我们的mPLUG-2在COCO字幕上的BLEU@4上明显超过BLIP 1.2个点,在CIDEr上超过1个点。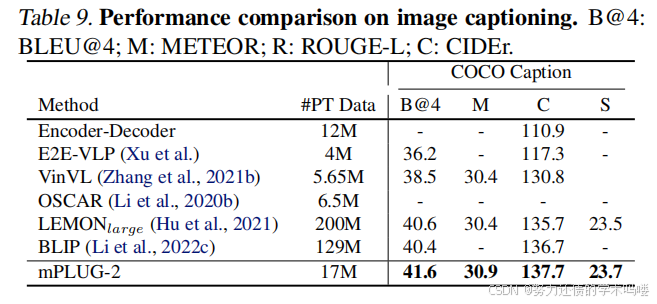
表9. 图像字幕的性能比较。B@4:BLEU@4;M:METEOR;R:ROUGE-L;C:CIDEr。
4.2.2. 仅语言任务
自然语言理解 我们在GLUE基准(Wang et al., 2018)的6个任务上评估mPLUG-2用于自然语言理解。表10显示mPLUG-2达到了与最先进的自然语言和多模态预训练模型相当的性能,包括RoBERTa(Liu et al., 2019)、DeBERTa(He et al., 2021b)。我们的方法与DeBERTa相比,在三个任务上实现了改进,这也证明了通用模块对模态协作的有效性。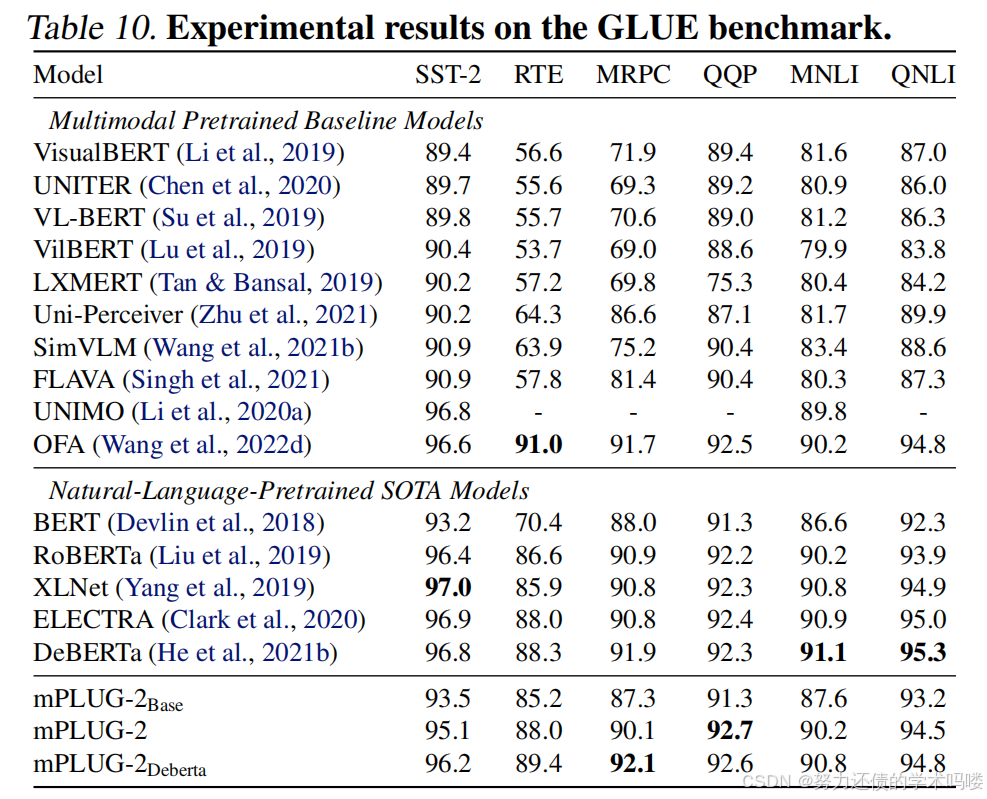
表10. GLUE基准上的实验结果。
自然语言生成 我们在Gigaword抽象摘要(Rush et al., 2015b)上评估mPLUG-2用于自然语言生成。如表11所示,mPLUG-2与最先进模型取得了可比的结果。
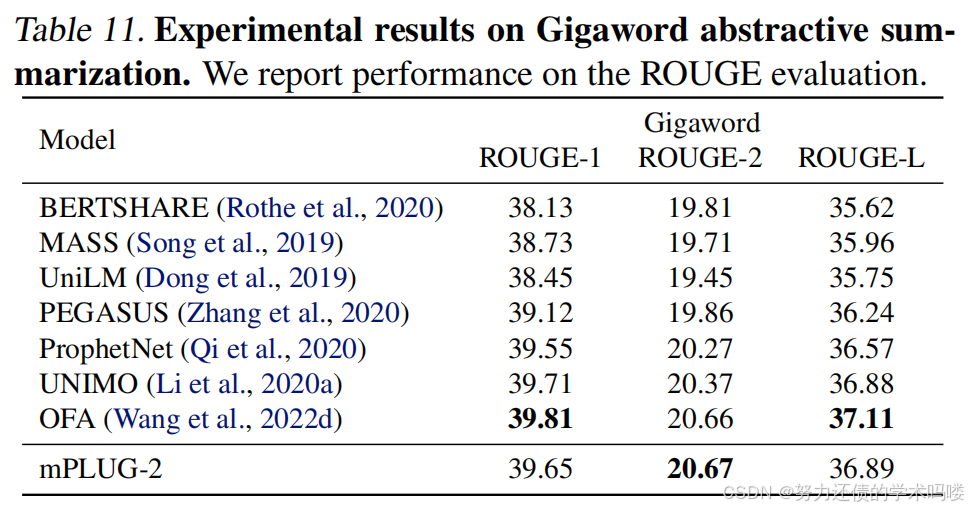
表11. Gigaword抽象摘要的实验结果。我们报告ROUGE评估的性能。
4.2.3. 仅视觉任务
视频动作识别 视频动作识别是视频理解最具代表性的任务,因为它需要模型理解视频中揭示的时空线索。表12总结了不同方法在Kinetics 400、Kinetics 600和Kinetics 700数据集上的性能。我们的mPLUG-2超越了大多数SoTA方法。例如,与在9亿视觉-文本对上预训练的Florence相比,mPLUG-2在Kinetics 600上将Top-1准确率提高了1.9%,在Kinetics 400上提高了0.6%。同时,我们可以注意到,mPLUG-2的性能优于具有相似预训练数据量的OmniVL,这显示了双视觉编码器模块对视频表示学习的有效性。
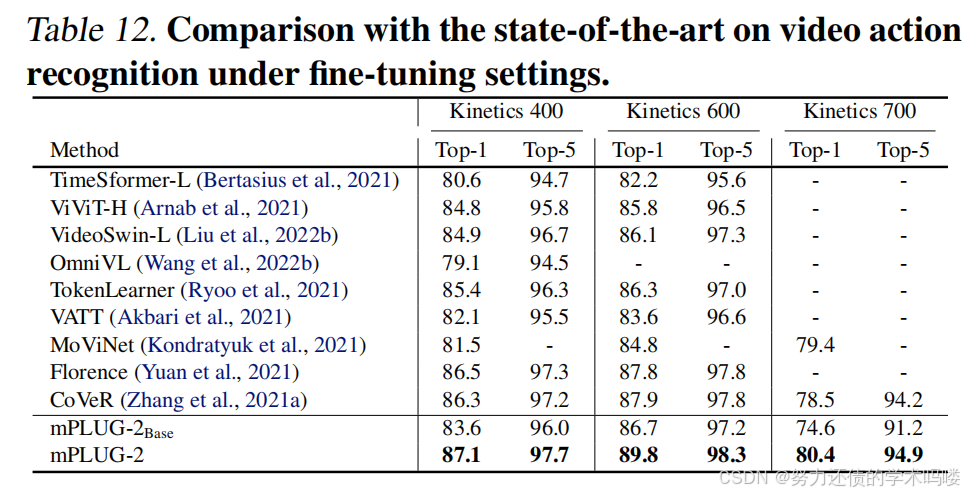
表12. 在微调设置下与最先进方法在视频动作识别上的比较。
图像分类 我们进一步评估mPLUG-2在ImageNet-1K上的图像分类性能。如表13所示,我们可以看到mPLUG-2在ImageNet-1K上达到了可比的结果,甚至在没有使用ImageNet数据进行预训练的情况下超越了SoTA方法。此外,为了有效评估mPLUG-2的鲁棒性和泛化能力,我们在5个ImageNet变体(即IN-V2、IN-Real、IN-Adversarial、IN-Rendition和IN-Sketch)上进行了评估。遵循标准评估程序(Fang et al., 2022a),所有这些模型首先在原始ImageNet-1K训练集上进行微调,然后直接在6个变体上进行测试,而无需进一步微调。如表13所示,mPLUG-2不仅在ImageNet-1K验证集上实现了最高的准确率,而且获得了相对较小的差距(即Δ↓),这反映了mPLUG-2在通用层模块通过学习语言共享表示的帮助下的出色鲁棒性和泛化能力。
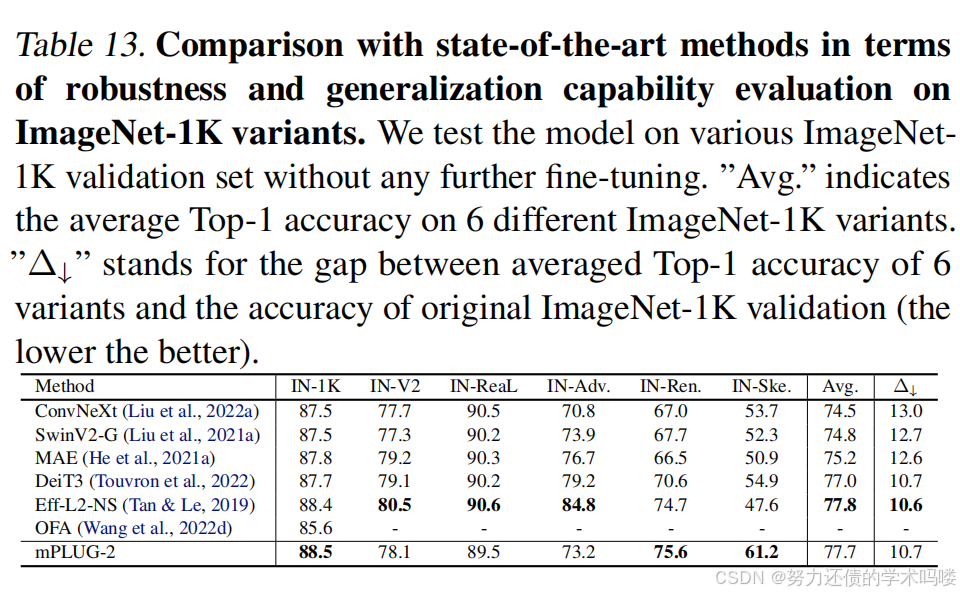
表13. 在ImageNet-1K变体上的鲁棒性和泛化能力评估方面与最先进方法的比较。我们在各种ImageNet-1K验证集上测试模型,而无需任何进一步的微调。"Avg."表示6个不同ImageNet-1K变体的平均Top-1准确率。"Δ↓"代表6个变体的平均Top-1准确率与原始ImageNet-1K验证的准确率之间的差距(越低越好)。
4.3. 讨论
基于指令学习的影响 基于指令的学习能够通过特定指令区分不同类型的任务。表14展示了基于指令学习的有效性。在表中,我们可以观察到基于指令的学习在平均召回率和准确率方面分别将检索和问答的性能提高了至少0.7%和1.2%。在基于指令学习的帮助下,mPLUG-2能够在不同

表14. 在下游任务上评估所提出的基于指令学习。对于检索任务,我们报告Recall@1、Recall@5和Recall@10的平均值。对于QA和字幕任务,报告Top-1准确率和CIDEr。
指令用于提升性能时利用不同的模块。
局部时间建模模块的影响(Impact of Local Temporal Modeling Module) 为了验证我们在双视觉编码器中提出的局部时间建模模块的有效性,我们使用不同的时间建模结构进行了实验。特别地,我们尝试了时间自注意力和时间卷积进行比较。结果总结在表15中。我们可以注意到,局部时间建模模块通过引入建模时间局部性优于时间自注意力模块。同时,在多组融合机制的帮助下,局部时间建模模块可以在独特的表示子空间中学习多样化的时间表示,而时间卷积被限制在相同的时间表示空间中,从而导致更好的性能。
表15. 评估双视觉编码器模块中不同时间建模模块。对于检索任务,我们报告Recall@1、Recall@5和Recall@10的平均值。对于QA和字幕任务,报告Top-1准确率和CIDEr。
通用层的影响() 为了验证我们提出的通用层模块的有效性,我们对所有单模态和多模态任务消融该模块。如表16和表17所示,我们将第1/2/2行设置为此实验中视觉/语言/视觉-语言任务的基线。我们可以发现,与基线相比,共享通用层通过鼓励模态之间的协作对所有模态任务都有益。

表16. 评估通用层在提升视觉任务性能方面的影响。
表17. 评估通用层在提升语言和视觉-语言任务性能方面的影响。
在图3中,可视化了第一个通用层中交叉注意力图的Grad-CAM。对于每个样本,

图3. 通用层中潜在查询的Grad-CAM可视化。
呈现了两个关注不同视觉概念的交叉注意力图。结果表明,通用层可以通过关注图像中各种视觉概念的区域来鼓励视觉补丁特征和语言特征之间的模态协作和模态纠缠。
用于模态协作的通用层(Universal Layer for Modality Collaboration) 在这里,研究通用层在模态协作方面的影响。我们随机采样一些视觉-语言对,并在图4中绘制从预训练的mPLUG-2生成的嵌入的UMAP可视化。我们可以观察到,在通用层的帮助下,视觉和文本样本之间的距离更近,而不是仅仅两个集中的簇。此外,我们定量计算模态差距 ∥ Δ ∥ \|\Delta\| ∥Δ∥(Liang et al., 2022),其中Δ是视觉嵌入和文本嵌入中心之间的差异。可以观察到,具有通用层的模型将鼓励视觉和语言模态之间的协作,从而与没有通用层的模型相比产生更低的模态差距。
图4. 从预训练的mPLUG-2生成的视觉和语言嵌入的UMAP可视化。黑线表示视觉-语言对。
5. 结论
本文提出了mPLUG-2,一个用于构建多模态基础模型的具有模块化设计的新统一范式。mPLUG-2引入了一个基于模块的网络设计,共享通用的通用模块用于模态协作,并解耦特定于模态的模块以解决模态纠缠的问题。实验结果表明,mPLUG-2的新统一范式可以在跨文本、图像和视频模态的超过30个任务的广泛范围内实现强大的性能。通过选择

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)