这个方向超级好出论文!非常适合做大模型的同学
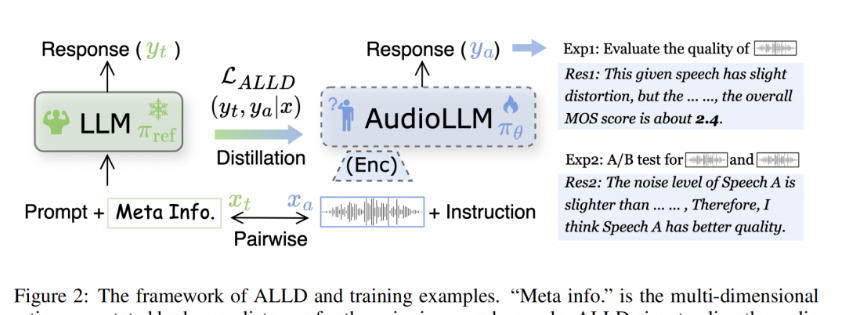
主要内容:当前音频大模型在输入音频的质量评估推理能力方向不足,所以作者提出了一种ALLD的蒸馏技术,通过meta info+prompt输入到LLM中获取LLM的response,然后对AudioLLM进行蒸馏,提高其在MOS得分预测和A/B test中的能力,实现过程其实并不复杂,重要的是这种思路以及实验设计挺值得借鉴的。主要内容:音频-语言模型(ALMs) 是在音频-文本对上进行预训练的,这些
现在文本大模型已经很成熟了,但是音频大模型还是有很多值得研究的方向,比如音频大模型做输入音频质量的评估等
下面总结了部分的论文,其中的改进思路值得学习和借鉴,有助于大家寻找研究方向和论文创新带你,并附上对应的代码,有需要可以自取

蒸馏策略+音频质量评估
ICLR 2025: Audio large language models can be descriptive speech quality evaluatiors
主要内容:当前音频大模型在输入音频的质量评估推理能力方向不足,所以作者提出了一种ALLD的蒸馏技术,通过meta info+prompt输入到LLM中获取LLM的response,然后对AudioLLM进行蒸馏,提高其在MOS得分预测和A/B test中的能力,实现过程其实并不复杂,重要的是这种思路以及实验设计挺值得借鉴的
Kimi
技术报告:Kimi-Audio Technical Report
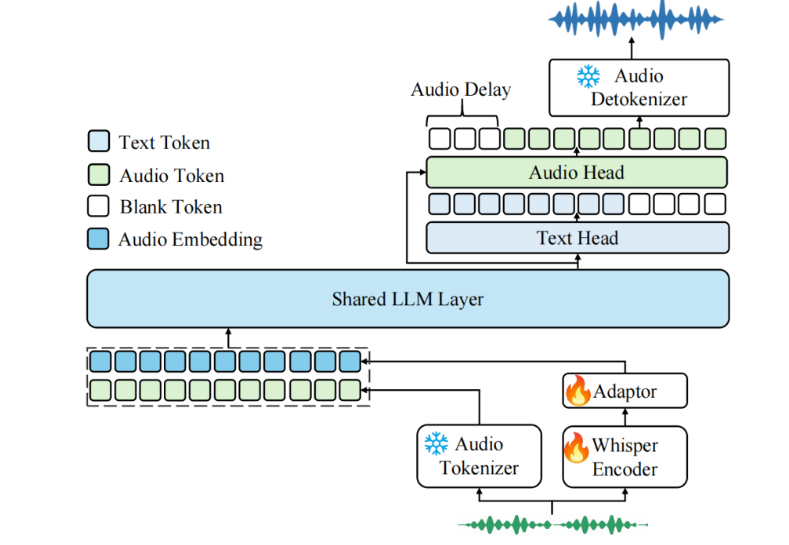
主要内容:推出 Kimi-Audio,这是一个开源的音频基础模型,在音频理解、生成和对话任务中表现出色。我们详细介绍了构建 Kimi-Audio 的实践过程,包括模型架构设计、数据整理、训练方法、推理部署以及评估方式。具体来说,我们采用了一个 12.5Hz 的音频 tokenizer,设计了一种基于大语言模型(LLM)的新架构,该架构以连续特征作为输入,以离散 token 作为输出,并开发了一个基于流匹配的分块流式反量化器(chunk-wise streaming detokenizer)。
提示词工程+音频质量评估
PAM: Prompting Audio-Language Models for Audio Quality Assessmen
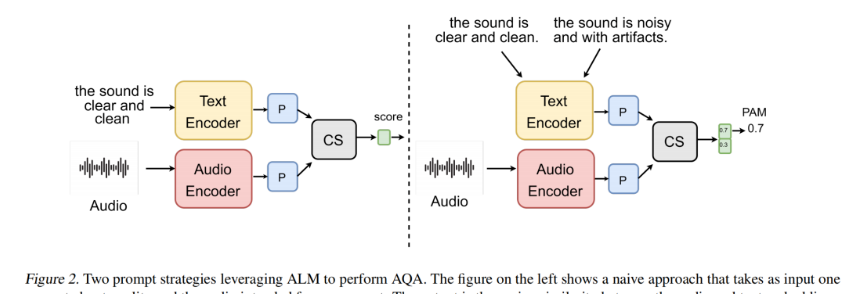
主要内容:音频-语言模型(ALMs) 是在音频-文本对上进行预训练的,这些模型可能包含了关于音频质量、是否存在伪影或噪声的信息。给定一段音频输入和一个与质量相关的文本提示,ALM 可以用于计算两者之间的相似度得分。在此基础上,我们利用这一能力,提出了 PAM ,是一种无参考(no-reference) 的音频质量评估指标,适用于多种音频处理任务。
与其它“无参考”指标不同,PAM 不需要在参考数据集上计算嵌入向量,也不需要在一个昂贵的人类听力评分数据集上训练特定任务的模型。我们在四个任务上对 PAM 的可靠性进行了广泛评估,并将其与现有的指标和人类听力评分进行对比:
-
文本到音频生成(Text-to-Audio, TTA)
-
文本到音乐生成(Text-to-Music, TTM)
-
文本到语音合成(Text-to-Speech, TTS)
-
深度降噪(Deep Noise Suppression, DNS)
音频数据集
Audio-Language Datasets of Scenes and Events: A Survey
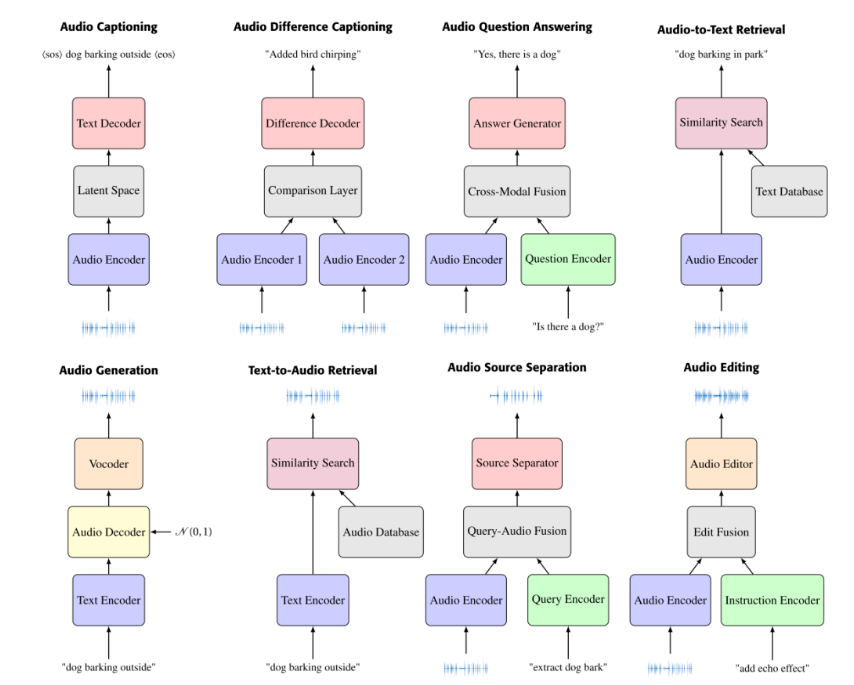
主要内容:本文对用于训练 ALMs 的 69 个数据集进行了综述,涵盖截至 2024 年 9 月 的研究进展。该综述全面分析了这些数据集的来源、音频与语言特征以及应用场景。主要的数据来源包括基于 YouTube 的大规模数据集如 AudioSet(包含超过 200 万个样本),以及社区平台如 Freesound(包含超过 100 万个样本)。综述通过分析音频和文本嵌入的主成分,评估了不同数据集在声学和语言方面的多样性;并通过 CLAP 嵌入 分析了数据泄露问题,同时考察了声音类别分布以识别其中的不平衡现象。最后,文章指出了在构建更大、更多样化的数据集以提升 ALM 性能过程中面临的关键挑战。
提示词工程
Coustic Prompt Tuning: Empowering Large Language Models with Audition Capabilities
主要内容:作者提出了声学提示调优(Acoustic Prompt Tuning, APT),这是一种新的适配器方法,通过将音频嵌入注入到语言模型的输入中(即软提示),将 LLM 和 VLM 扩展到音频领域。具体而言,APT 使用一个指令感知的音频对齐器,基于输入文本和音频内容生成软提示,并将其作为语言模型的输入。为了缓解音频领域数据稀缺的问题,我们提出了一种课程学习策略,将多样化的音频任务以逐步递进的方式进行建序训练。此外,我们还通过使用交错式的音频-文本嵌入序列来改进音频语言模型的输入方式。该模型对输入格式没有任何限制,因此能够处理多种建模任务,例如小样本音频分类和音频对比。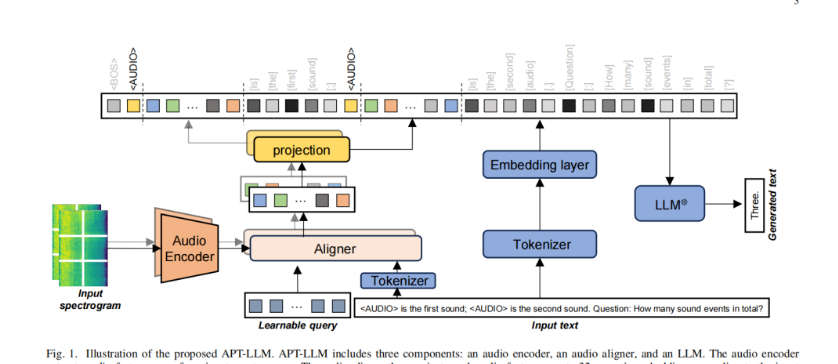


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)