如何通过ollama, vllm框架以及python(GPU)本地私有化部署大模型
本文介绍了三种大模型部署方法:1)通过Ollama本地部署(推荐个人使用),支持命令行操作和API调用;2)采用vLLM框架部署(适合企业级应用),支持分布式推理和量化技术;3)通过Python+GPU下载魔搭社区模型到本地运行,提供了完整的代码示例。每种方法均包含具体操作步骤,从模型下载到实际调用,涵盖不同应用场景需求。
1.通过Ollama方式部署大模型(推荐个人部署模型使用,方便)
可以直接通过下面的链接下载windows版本ollama https://ollama.com/
安装后,Ollama会作为服务运行,下载各类大模型名称参考Ollama的官方模型库 library
主要使用命令如下:(以模型deepseek-r1:1.5b为例,没有gpu可以在本地跑)
下载deepseek-r1:1.5b 模型:
ollama pull deepseek-r1:1.5b
删除模型:
ollama rm deepseek-r1:1.5b
运行模型:(第一次运行会自动下载模型)
ollama run deepseek-r1:1.5b
查看本地已下载的模型:
ollama list
安装成功后,可以在命令行可以进行测试如下:
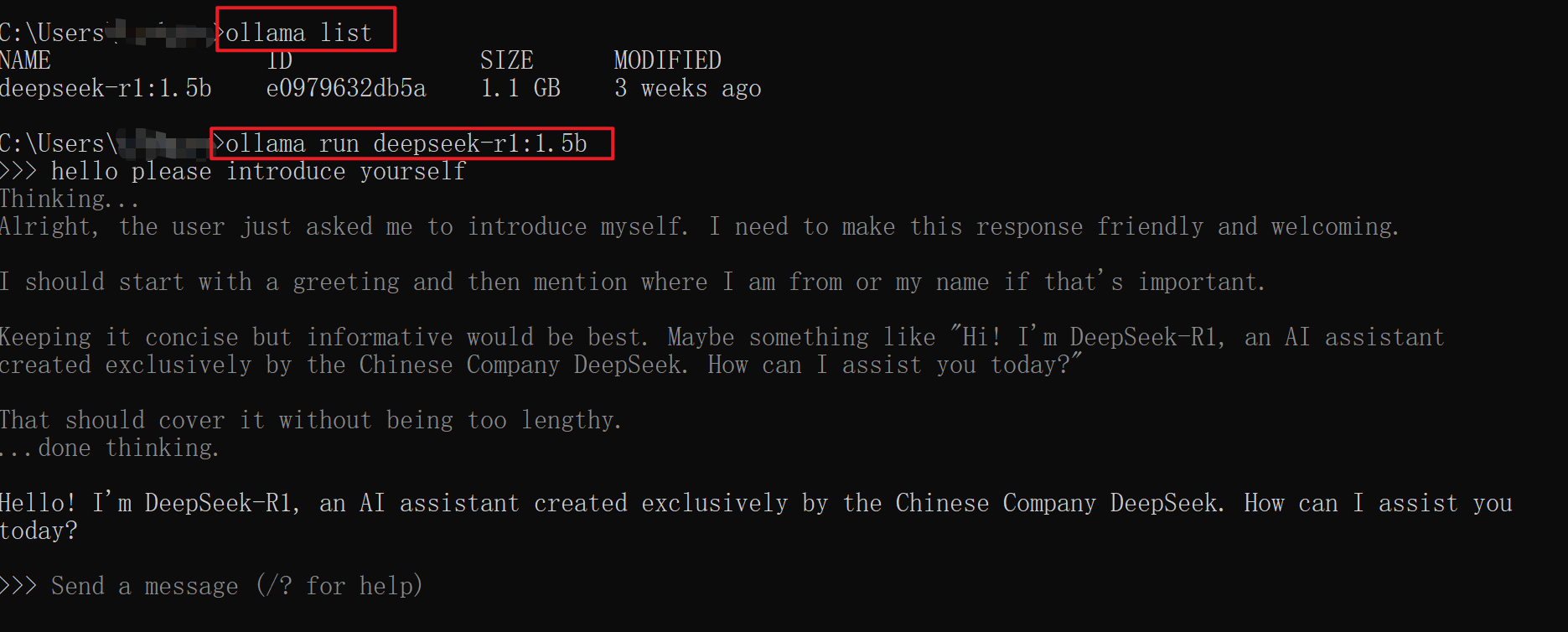
Ollama 自带本地 API,可以作为服务被调用。默认端口11434。Python代码示例如下:
import requests
def query_ollama(prompt, model="deepseek-r1:1.5b"):
url = "http://localhost:11434/api/generate"
data = {
"model": model,
"prompt": prompt,
"stream": False #如果为True获取流式响应
}
response = requests.post(url, json=data)
if response.status_code == 200:
return response.json()["response"]
else:
raise Exception(f"API 请求失败: {response.text}")
# 使用示例
response = query_ollama("Please introduce yourself")
print(response)2.通过vllm方式部署大模型:(推荐企业级应用,并行度高)
vLLM是由伯克利大学LMSYS 组织开源的LLM高速推理框架,用于提升LLM的吞吐量与内存使用效率。vLLM支持量化技术、分布式推理、与Hugging Face 模型无缝集成。
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
vllm serve 命令启动vLLM推理服务。
deepseek-ai/DeepSeek-R1-Distill-Qwen-32B,Hugging Face 模型库中的模型名称,vLLM 会尝试从huggingface下载模型。Hugging face Hugging Face – The AI community building the future.需要外网,可以使用镜像网站 HF-Mirror。
--tensor-parallel-size 2,启用张量并行,在 几个GPU 上分布式运行模型
--max-model-len 32768,设置模型的最大上下文长度(32K tokens),确保能处理长文本
--enforce-eager,禁用 CUDA Graph 优化
3.Python+GPU下载模型到本地
魔塔社区模型选择 模型库首页 · 魔搭社区,这里选择7B的大模型,用RTX 3090 * 1卡跑
下载模型到指定目录。
from modelscope import snapshot_download
snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', cache_dir="/root/autodl-tmp/models")下载完成后,python代码调用参考:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "/root/autodl-tmp/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="cuda"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "帮我写一个二分查找法"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=2000
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)成功运行结果: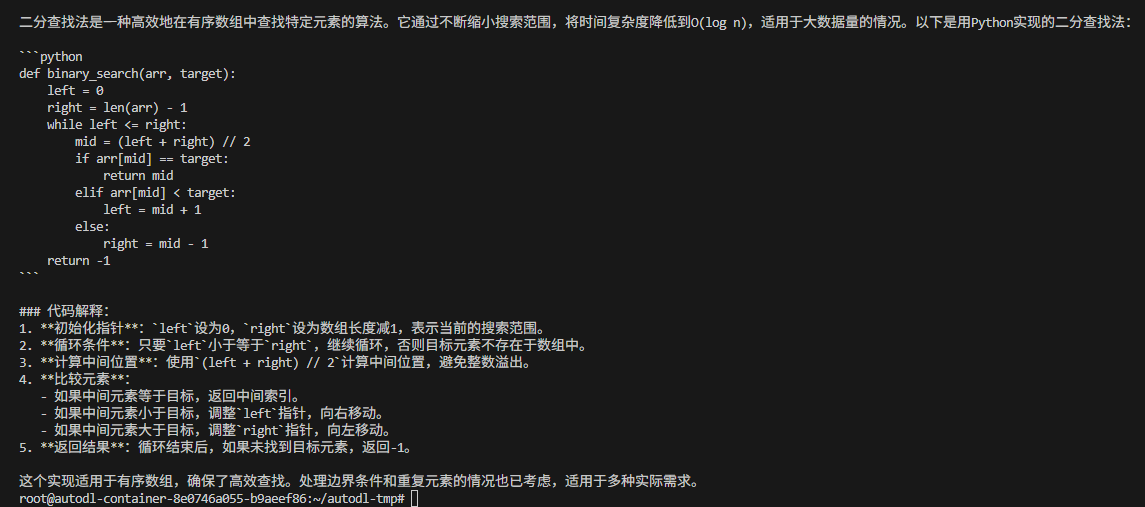

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)