【LangChain RAG从零学】Query Transformations
【LangChain RAG从零学】Query Transformations
·
前言
- 该篇为【LangChain RAG从零学】的第二章,旨在记录学习RAG的过程
Query Trasformations
- 在RAG系统中,用户的原始查询(Query)直接决定了最终生成答案的质量
- 然而用户的输入存在模糊、抽象或者与知识库文档语言风格不匹配,会导致检索效率低
- 查询转换指的是对用户的原始查询进行一系列的修改、扩展和分解,生成一个或多个优化的新查询,提高检索到相关文档的准确率和召回率

Multi Query
概念
- 多查询重写是最常用的技术,其核心是围绕用户的原始查询,从不同角度和措辞生成多个语义相似但表达方式各异的新查询
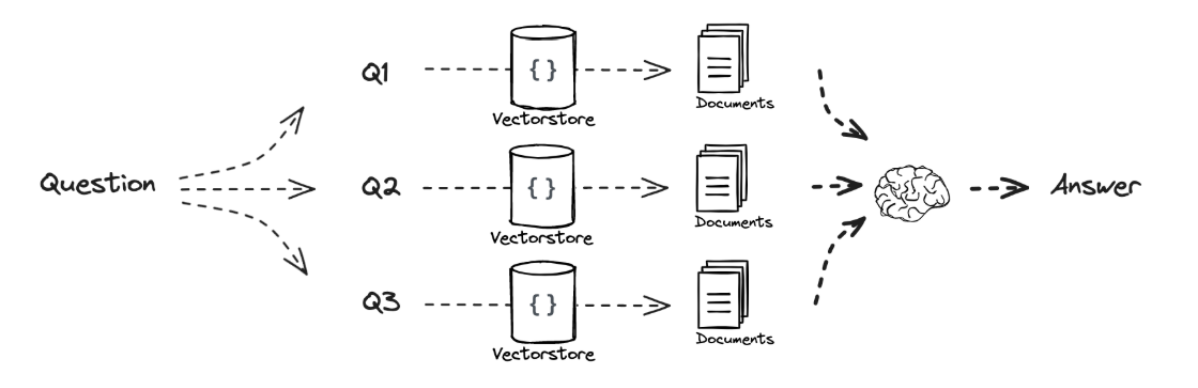
- 直觉:用户的初始查询嵌入后在高维嵌入空间无法与想要检索的文档对齐,但这个文档是相关的
- 通过几种不同的方式重写查询,实际上增加了检索到相关文档的可能性(更散弹的提问方式)

代码实现
- 环境导入和LangSmith配置
! pip install langchain_community tiktoken langchainhub chromadb langchain langchain-google-genai
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
os.environ['LANGCHAIN_API_KEY'] = 'YOUR_API_KEY'
os.environ["GOOGLE_API_KEY"] = "YOUR_API_KEY"
- 标准索引部分
# 加载文档
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
# CSS过滤
class_=("post-content", "post-title", "post-header")
)
),
)
blog_docs = loader.load()
# 分割
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1024,
chunk_overlap=50)
# Make splits
splits = text_splitter.split_documents(blog_docs)
# 索引
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits,embedding=GoogleGenerativeAIEmbeddings(model="models/text-embedding-004"))
# 默认4个
retriever = vectorstore.as_retriever()
- Prompt 驱动 Multi Query构建
from langchain.prompts import ChatPromptTemplate
# Multi Query: 不同的角度
template = """You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}"""
prompt_perspectives = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_google_genai import ChatGoogleGenerativeAI
generate_queries = (
prompt_perspectives
| ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0)
| StrOutputParser()
| (lambda x: x.split("\n"))
)
from langchain.load import dumps, loads
def get_unique_union(documents: list[list]):
# 文档去重 防止检索文档重复
# 展平二维列表,将文档序列化
flattened_docs = [dumps(doc) for sublist in documents for doc in sublist]
# 获取唯一文档
unique_docs = list(set(flattened_docs))
# Return
return [loads(doc) for doc in unique_docs]
# Retrieve
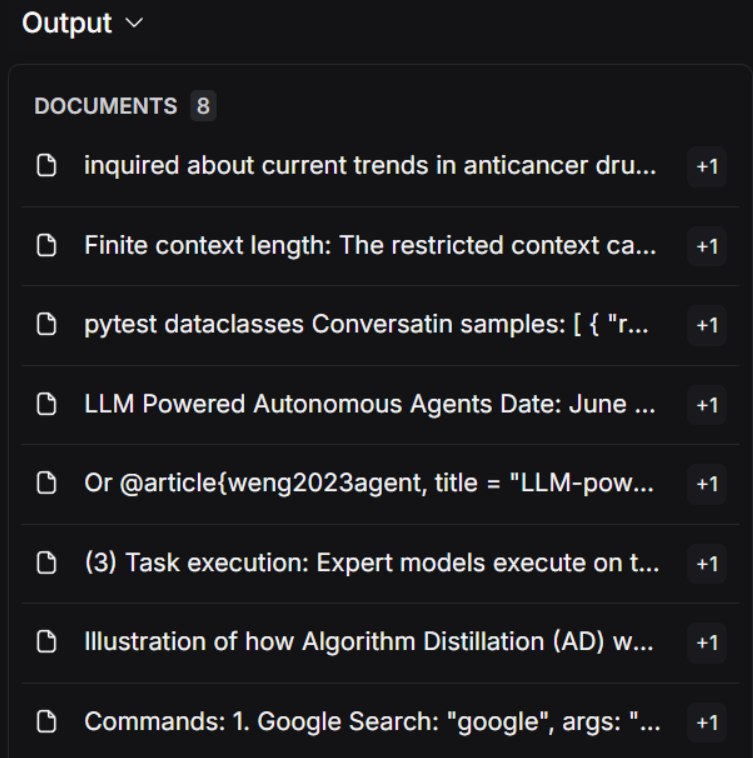
question = "What is task decomposition for LLM agents?"
retrieval_chain = generate_queries | retriever.map() | get_unique_union
docs = retrieval_chain.invoke({"question":question})
len(docs)
- Multi Query构建结果
How do Large Language Models break down complex tasks for agents?
Explain the process of subtasking within the context of LLM-driven agents.
What are the different strategies for assigning sub-tasks to agents controlled by LLMs?
Describe the methods used to manage and coordinate multiple sub-tasks in LLM agent systems.
What are the challenges and benefits of using task decomposition in LLM agent architectures?
- 最终RAG构建
from operator import itemgetter
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.runnables import RunnablePassthrough
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0)
final_rag_chain = (
{"context": retrieval_chain,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"question":question})
- Input
What is task decomposition for LLM agents?
- Output
Task decomposition for LLM agents is the process of breaking down large, complex tasks into smaller, more manageable subgoals. This allows the agent to handle complex tasks efficiently. Several methods exist, including:
* **Chain of Thought (CoT):** Prompts the LLM to "think step by step," decomposing the task into simpler steps.
* **Tree of Thoughts:** Extends CoT by exploring multiple reasoning possibilities at each step, creating a tree structure of potential solutions.
* **LLM+P:** Uses an external classical planner (and PDDL language) to handle long-horizon planning, outsourcing the planning step to an external tool.
* **Task-specific instructions:** Using instructions tailored to the task type (e.g., "Write a story outline" for writing a novel).
* **Human input:** Directly providing the decomposition steps from a human.
RAG Fusion
概念
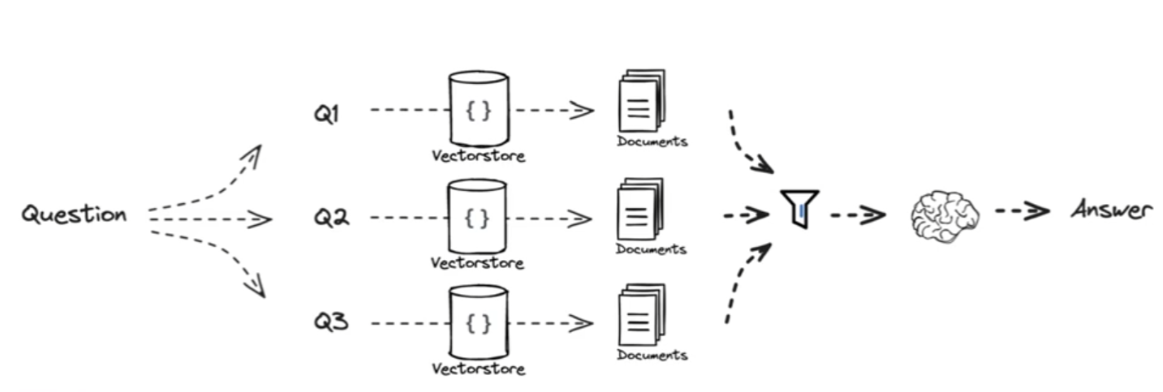
- 传统RAG流程是单一查询,会导致最终结果有局限性
- RAG-Fusion在Multi Query的多路查询上添加智能融合来克服局限性
- 通过RRF算法将所有查询返回的多个文档列表智能合并在一起
- RRF(Reciprocal Rank Fusion)算法抛弃了相关度分数,只关注每个文档在各自列表中的排名(先后顺序)
- 一个文档如果在多个不同的搜索结果中都排名靠前,那么它可能是一个重要的文档
代码实现
- Prompt
from langchain.prompts import ChatPromptTemplate
# RAG-Fusion: Related
template = """You are a helpful assistant that generates multiple search queries based on a single input query. \n
Generate multiple search queries related to: {question} \n
Output (4 queries):"""
prompt_rag_fusion = ChatPromptTemplate.from_template(template)
- 构建Query
from langchain_core.output_parsers import StrOutputParser
from langchain_google_genai import ChatGoogleGenerativeAI
generate_queries = (
prompt_rag_fusion
| ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0)
| StrOutputParser()
| (lambda x: x.split("\n"))
)
- RRF算法实现
from langchain.load import dumps, loads
def reciprocal_rank_fusion(results: list[list], k=60):
""" 倒数排序融合算法 接受一个嵌套列表 以及常数k """
# 字典存储每个文档的最终RRF分数
fused_scores = {}
# 遍历每个问题对应的查询文档列表
for docs in results:
# rank为每个文档的索引,doc为文档
for rank, doc in enumerate(docs):
# 将文档序列化,转换为key
doc_str = dumps(doc)
# 初始化
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# 获取之前的分数
previous_score = fused_scores[doc_str]
# 更新分数
fused_scores[doc_str] += 1 / (rank + k)
# 按照字典的第二个元素即为分数降序排序
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
# 返回最终排序信息
return reranked_results
retrieval_chain_rag_fusion = generate_queries | retriever.map() | reciprocal_rank_fusion
docs = retrieval_chain_rag_fusion.invoke({"question": question})
len(docs)
- LangSmith监控结果
1. "LLM agent task decomposition techniques"
2. "Best practices for decomposing tasks for large language model agents"
3. "How to break down complex tasks for LLM-based agents"
4. "Challenges and solutions in task decomposition for LLM agents"

-
结果分别是相关文档和对应的RRF计算的分数,与Multi Query的简单去重相比,RRF算法的筛选更加启发式
-
最终RAG实现
from langchain_core.runnables import RunnablePassthrough
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
{"context": retrieval_chain_rag_fusion,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"question":question})
- Input
What is task decomposition for LLM agents?
- Output
Task decomposition for LLM agents is the process of breaking down large, complex tasks into smaller, more manageable subgoals. This allows the agent to handle complex tasks efficiently. Several methods exist, including:
* **Chain of Thought (CoT):** Prompts the model to "think step by step," decomposing the task into smaller steps.
* **Tree of Thoughts:** Extends CoT by exploring multiple reasoning possibilities at each step, creating a tree structure of potential solutions.
* **LLM+P:** Uses an external classical planner (via PDDL) to handle long-horizon planning, outsourcing the decomposition to a tool outside the LLM.
* **Task-specific instructions:** Using instructions tailored to the task type (e.g., "Write a story outline" for writing a novel).
* **Human input:** Directly providing the decomposition steps from a human.
- RAG-Fusion = Multi-Query策略 + RRF融合算法
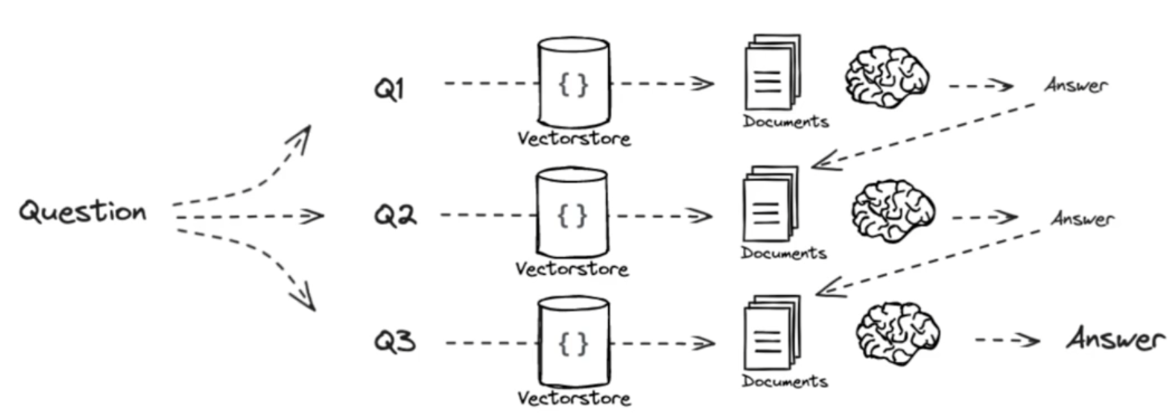
Decomposition
概念
- 当用户提出一个包含多个子问题的复杂查询时,Decomposition会将其拆解为一系列更简单、更具体地独立子问题
- 使用LLM自身的理解能力分析原始查询的结构和意图(Prompt)
- 每个子问题都更具体,更容易匹配到相关文档
- 使检索过程更有条理,便于后续对各个子问题的答案进行综合
代码实现
- Prompt
from langchain.prompts import ChatPromptTemplate
# Decomposition
template = """You are a helpful assistant that generates multiple sub-questions related to an input question. \n
The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation. \n
Generate multiple search queries related to: {question} \n
Output (3 queries):"""
prompt_decomposition = ChatPromptTemplate.from_template(template)
- 子问题分解
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.output_parsers import StrOutputParser
# LLM
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0)
# Chain
generate_queries_decomposition = ( prompt_decomposition | llm | StrOutputParser() | (lambda x: x.split("\n")))
# Run
question = "What are the main components of an LLM-powered autonomous agent system?"
questions = generate_queries_decomposition.invoke({"question":question})
Here are three search queries related to "What are the main components of an LLM-powered autonomous agent system?":
1. **"LLM agent architecture components"**: This query focuses on the structural elements of the system, aiming to find diagrams and descriptions of the overall architecture.
2. **"Key modules of large language model agents"**: This query emphasizes the functional modules, seeking information on specific components and their roles (e.g., memory, planning, action execution).
3. **"Software components for building autonomous LLM agents"**: This query targets the practical implementation aspects, looking for information on specific software libraries, frameworks, or tools used in building such systems.
- 迭代添加(background question+answer)
# Prompt
template = """Here is the question you need to answer:
\n --- \n {question} \n --- \n
Here is any available background question + answer pairs:
\n --- \n {q_a_pairs} \n --- \n
Here is additional context relevant to the question:
\n --- \n {context} \n --- \n
Use the above context and any background question + answer pairs to answer the question: \n {question}
"""
decomposition_prompt = ChatPromptTemplate.from_template(template)
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
def format_qa_pair(question, answer):
"""Format Q and A pair"""
formatted_string = ""
formatted_string += f"Question: {question}\nAnswer: {answer}\n\n"
return formatted_string.strip()
# llm
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0)
q_a_pairs = ""
for q in questions:
rag_chain = (
{"context": itemgetter("question") | retriever,
"question": itemgetter("question"),
"q_a_pairs": itemgetter("q_a_pairs")}
| decomposition_prompt
| llm
| StrOutputParser())
answer = rag_chain.invoke({"question":q,"q_a_pairs":q_a_pairs})
q_a_pair = format_qa_pair(q,answer)
q_a_pairs = q_a_pairs + "\n---\n"+ q_a_pair
- 结果
Based on the provided text, several software components and tools are mentioned in the context of building autonomous LLM agents:
* **LangChain:** This framework is explicitly mentioned in the context of ChemCrow, a scientific discovery agent. It's used to implement the workflow combining Chain of Thought reasoning with tools relevant to the tasks. This suggests LangChain is a practical tool for building and managing the interactions between the LLM and external tools.
* **Vector databases:** The text repeatedly emphasizes the use of external vector stores (databases) for efficient long-term memory retrieval in LLM agents. While specific database names aren't provided, the implication is that tools capable of efficient similarity search (like those using Maximum Inner Product Search (MIPS) or Approximate Nearest Neighbors (ANN) algorithms) are crucial components. Examples of such databases include Weaviate (mentioned in the blog post's references).
* **Classical planners:** The LLM+P approach uses external classical planners to handle long-horizon planning. The text doesn't specify which planner is used, but it highlights the need for such tools when outsourcing the planning aspect to a dedicated system.
* **APIs and API interaction tools:** The ability to interact with external APIs is a core component. The text mentions several APIs used by different agents (e.g., Google Search, Wikipedia search API, robotics experimentation APIs). The API-Bank benchmark is specifically designed to evaluate the ability of LLMs to interact with a wide range of APIs. Tools and libraries that facilitate API calls and management are therefore essential.
* **Subprocesses:** AutoGPT uses subprocesses for commands that take longer than a few minutes to execute. This indicates the use of operating system-level tools for managing external processes.
The text also implicitly suggests the need for libraries and frameworks to handle:
* **Prompt engineering:** While not a specific software component, the effective design and management of prompts are crucial. Libraries or tools that assist in prompt generation, optimization, and management would be necessary.
* **Natural language processing (NLP) tools:** Beyond the LLM itself, additional NLP tools might be used for tasks like text parsing, information extraction, and sentiment analysis within the agent's workflow.
In summary, while the provided text doesn't offer an exhaustive list of every software component, it highlights LangChain as a specific framework and points to the crucial roles of vector databases, classical planners, API interaction tools, and subprocess management in building autonomous LLM agents. The need for supporting libraries and tools for prompt engineering and general NLP tasks is also implied.
- Decompositon适合含有复杂子任务的查询,一般查询分解出的子查询没有很大的价值
Step-back
概念
- 对于一个非常具体的问题,先退一步思考其背后的更抽象、根本的问题或者原则
- 利用LLM提炼出一个更高层次、更一般性的问题
- 通过检索一般性的问题,可以找到包含根本问题和通用解决方案的文档
- 当知识库中没有针对特定问题的信息时,这种方案仍能找到有用的通用信息
代码实现
- 少样本样例(Prompt)
# Few Shot Examples
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
examples = [
{
"input": "Could the members of The Police perform lawful arrests?",
"output": "what can the members of The Police do?",
},
{
"input": "Jan Sindel’s was born in what country?",
"output": "what is Jan Sindel’s personal history?",
},
]
# We now transform these to example messages
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are an expert at world knowledge. Your task is to step back and paraphrase a question to a more generic step-back question, which is easier to answer. Here are a few examples:""",
),
# Few shot examples
few_shot_prompt,
# New question
("user", "{question}"),
]
)
generate_queries_step_back = prompt | ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0) | StrOutputParser()
question = "What is task decomposition for LLM agents?"
generate_queries_step_back.invoke({"question": question})
- Step-back Query
How can complex tasks be broken down for large language models?
- 完整RAG实现
from langchain_core.runnables import RunnableLambda
# Response prompt
response_prompt_template = """You are an expert of world knowledge. I am going to ask you a question. Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant.
# {normal_context}
# {step_back_context}
# Original Question: {question}
# Answer:"""
response_prompt = ChatPromptTemplate.from_template(response_prompt_template)
chain = (
# 字典结构 并行执行
{
# Retrieve context using the normal question
"normal_context": RunnableLambda(lambda x: x["question"]) | retriever,
# Retrieve context using the step-back question
"step_back_context": generate_queries_step_back | retriever,
# Pass on the question
"question": lambda x: x["question"],
}
| response_prompt
| ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0)
| StrOutputParser()
)
chain.invoke({"question": question})
- 进行了两次retrieve(origin query && step-back retrieve)
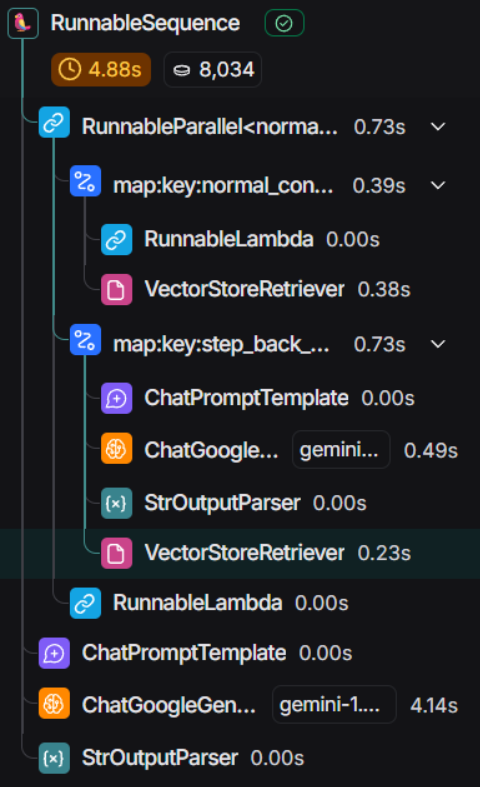
Task decomposition, in the context of Large Language Model (LLM) agents, is the process of breaking down a complex task into smaller, more manageable sub-tasks. This is crucial because LLMs, while powerful, have limitations in their ability to handle highly complex problems in a single step. Decomposing the task allows the agent to address each sub-task sequentially or concurrently, making the overall problem tractable.
Several techniques are used for task decomposition in LLM agents:
* **Chain of Thought (CoT):** This prompting technique instructs the LLM to "think step by step," explicitly outlining the reasoning process. This forces the model to decompose the task into smaller steps, revealing its internal thought process and improving performance.
* **Tree of Thoughts (ToT):** ToT extends CoT by exploring multiple reasoning paths at each step. The LLM generates multiple potential solutions for each sub-task, creating a tree structure. Search algorithms like Breadth-First Search (BFS) or Depth-First Search (DFS) are then used to explore this tree, with a classifier (often another LLM prompt) or majority voting used to evaluate the best path.
* **Simple Prompting:** Directly prompting the LLM with questions like "Steps for XYZ. 1.", or "What are the subgoals for achieving XYZ?" can elicit a decomposition of the task.
* **Task-Specific Instructions:** Providing task-specific instructions, such as "Write a story outline" for writing a novel, can guide the LLM towards a natural decomposition.
* **Human Input:** Human intervention can be used to decompose complex tasks, particularly in cases where the LLM struggles to do so effectively.
* **LLM+P:** This approach uses an external classical planner, often leveraging the Planning Domain Definition Language (PDDL). The LLM translates the problem into PDDL, the planner generates a plan, and the LLM translates the plan back into natural language. This outsources the planning (and thus decomposition) to a specialized tool.
The choice of decomposition method depends on the complexity of the task, the capabilities of the LLM, and the resources available. Effective task decomposition is critical for building robust and efficient LLM-powered autonomous agents.
HyDE
概念
- Hypothetical Document(HyDE)是一种巧妙的技术,它不直接转换查询语句,而是让LLM为用户构建一个假设性文档,然后将文档向量化,放入嵌入空间中取寻找相似的真实文档
- 解决查询-文档之间的语义差异:查询通常是疑问句式、关键词短,而文档是陈述句式、内容丰富
- HyDE通过查询生成一个伪文档,使得用于检索的向量在语义空间中更接近目标向量,提高检索的准确性
代码实现
from langchain.prompts import ChatPromptTemplate
# HyDE document generation
template = """Please write a scientific paper passage to answer the question
Question: {question}
Passage:"""
prompt_hyde = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
generate_docs_for_retrieval = (
prompt_hyde | ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0) | StrOutputParser()
)
# Run
question = "What is task decomposition for LLM agents?"
generate_docs_for_retrieval.invoke({"question":question})
# Retrieve
retrieval_chain = generate_docs_for_retrieval | retriever
retrieved_docs = retrieval_chain.invoke({"question":question})
retrieved_docs
- 伪文档生成
Task decomposition, in the context of Large Language Model (LLM) agents, refers to the process of breaking down a complex, high-level task into a sequence of simpler, more manageable sub-tasks that are individually tractable by the LLM. This decomposition is crucial because LLMs, while capable of impressive feats of language understanding and generation, often struggle with complex tasks requiring multi-step reasoning, external knowledge access, or interaction with the environment. Effective decomposition facilitates a more robust and reliable execution of the overall task by mitigating the limitations of the LLM's single-step reasoning capabilities. The sub-tasks generated through decomposition are typically designed to be individually solvable by the LLM, potentially leveraging its capabilities in information retrieval, planning, or code generation. The choice of decomposition strategy significantly impacts the agent's performance, with hierarchical approaches, where sub-tasks are further decomposed recursively, often proving more effective for highly complex tasks than flat, linear decompositions. Furthermore, the granularity of the decomposition—the size and complexity of the individual sub-tasks—requires careful consideration, balancing the need for manageable sub-tasks with the overhead of excessive decomposition. Ultimately, the effectiveness of task decomposition hinges on the ability to create a sequence of sub-tasks that are both solvable by the LLM and collectively achieve the desired outcome of the original complex task.
- 完整RAG实现
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"context":retrieved_docs,"question":question})
- answer
Task decomposition for LLM agents is the process of breaking down large, complex tasks into smaller, more manageable sub-goals. This allows the agent to handle complex problems more efficiently. Methods include using Chain of Thought (CoT) prompting to guide the LLM to think step-by-step, Tree of Thoughts (ToT) to explore multiple reasoning paths, using task-specific instructions, or employing an external classical planner (like LLM+P) which uses PDDL to define and solve the planning problem. The decomposition can be done by the LLM itself through prompting, with task-specific instructions, or with human input.
参考文献

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)