机器学习——CountVectorizer词向量转化评论预测案例(中文分词jieba+停用词过滤+词袋模型n-gram特征提取+SMOTE过采样+朴素贝叶斯分类+模型评估+交互预测)
本文实现了一个基于jieba 分词 + 朴素贝叶斯 + SMOTE + n-gram 词袋模型的中文情感分析系统,能高效判断好评和差评。加入 TF-IDF代替词袋模型,提升特征质量。使用深度学习(BERT、ERNIE)提高模型表达能力。结合情感词典提升可解释性。t=P758python网络爬虫小项目(爬取评论)超级简单-CSDN博客https://blog.csdn.net/2302_780226
基于 jieba 分词与朴素贝叶斯的中文评论情感分析案例
1. 案例背景
在电商平台和社交媒体中,大量用户评论是中文文本。为了自动化分析这些评论的情感倾向(好评、差评、中立),我们可以使用基础的自然语言处理(NLP)与机器学习分类算法进行建模,实现自动判别。
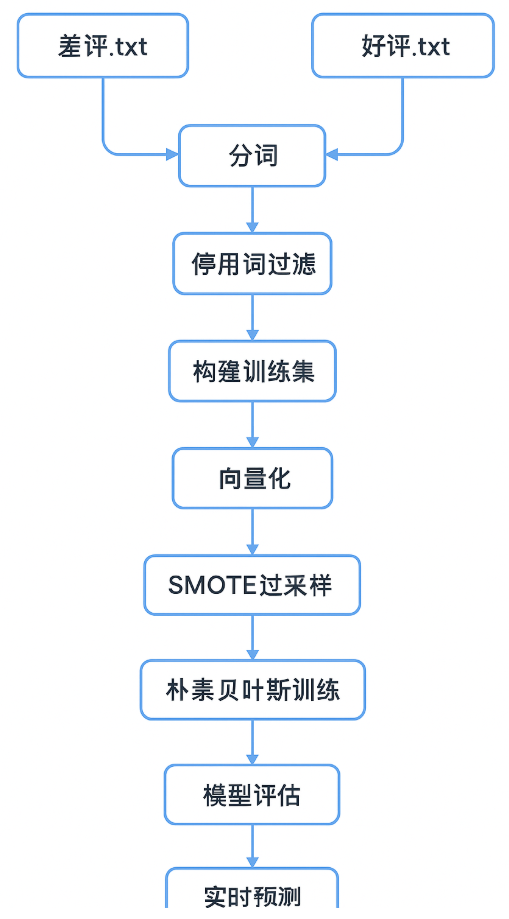
本文通过一个完整的 Python 案例,展示如何从评论文本出发,经过分词 → 停用词过滤 → 特征提取 → 数据平衡处理 → 模型训练与预测,最终实现一个可交互的评论情感分类系统。
2. 技术路线
本案例的技术组合如下:
-
jieba 分词 → 中文分词
-
停用词过滤 → 清理无意义的高频词
-
CountVectorizer 词袋模型 + n-gram → 文本特征提取
-
SMOTE → 数据平衡处理(过采样)
-
朴素贝叶斯(MultinomialNB) → 文本分类模型
-
classification_report → 模型效果评估
-
命令行交互 → 实时输入评论并预测
3. 数据准备
我们准备了三类文件:
-
差评.txt → 差评评论,每行一条
-
好评.txt → 好评评论,每行一条
-
StopwordsCN.txt → 中文停用词表,含“的、了、在”等无意义词
数据目录结构:
(可以自行爬取评论:python网络爬虫小项目(爬取评论)超级简单-CSDN博客![]() https://blog.csdn.net/2302_78022640/article/details/149488367)
https://blog.csdn.net/2302_78022640/article/details/149488367)
数据/
│
├── 差评.txt
├── 好评.txt
└── StopwordsCN.txt
4. 核心代码讲解
1️⃣
读取评论文本并分词
import jieba
import pandas as pd
作用分析:
-
jieba:中文分词库,将连续的中文句子拆分成单独词语。 -
pandas:用于数据读取、存储、清洗和导出,常用的 DataFrame 数据结构非常方便处理文本数据。
bad_segments = []
with open('数据/差评.txt', 'r', encoding='utf-8') as f:
for line in f:
content = line.strip() # 去除多余空白
results = jieba.lcut(content) # 使用 jieba 分词
if len(results) > 1: # 排除空行或无效内容
bad_segments.append(results)注意事项:
-
中文文本处理必须保证文件编码为
utf-8,否则会报编码错误。
作用分析:
-
打开差评文本文件并按行读取。
-
line.strip()去除每行前后的空格或换行符。 -
jieba.lcut()将文本拆成词列表。 -
if len(results) > 1用于排除空行或分词后为空的行。 -
bad_segments.append(results)保存每条评论的分词结果到列表。
同样的操作应用于好评文本:
good_segments = []
with open('数据/好评.txt', 'r', encoding='utf-8') as f:
for line in f:
content = line.strip()
results = jieba.lcut(content)
if len(results) > 1:
good_segments.append(results)
注意事项:
-
jieba 分词对新词、专业名词可能不准确,可以考虑自定义词典。
-
空行或仅含停用词的行会被后续处理丢弃。
保存分词结果
bad_segments_results = pd.DataFrame({'content':bad_segments})
bad_segments_results.to_excel('bad_fc_results.xlsx',index=False)
good_segments_results = pd.DataFrame({'content':good_segments})
good_segments_results.to_excel('good_fc_results.xlsx',index=False)
作用分析:
-
将分词后的列表封装成 DataFrame,列名为
content。 -
to_excel保存为 Excel 文件,方便后续查看或二次处理。
注意事项:
-
若数据量大,Excel 文件可能打开缓慢,推荐保存为 CSV 格式。
2️⃣
停用词过滤函数
def drop_stopwords(contents, stopwords):
segments_clean = []
for content in contents:
line_clean = []
for word in content:
if word in stopwords:
continue
line_clean.append(word)
segments_clean.append(line_clean)
return segments_clean
作用分析:
-
遍历每条分词结果,删除停用词。
-
返回新的列表
segments_clean,每条评论都是去停用词后的词列表。
stopwords = pd.read_csv('数据/StopwordsCN.txt', encoding='utf-8', engine='python', sep='\t')
stopwords = stopwords.stopword.values.tolist()
作用分析:
-
读取停用词文件,转换成 Python 列表。
注意事项:
-
停用词文件必须与文本编码一致,否则会乱码。
-
停用词列表对结果影响很大,如果去掉过多可能会丢信息,去掉过少会增加噪声。
清理评论数据
bad_segments_results_clean = drop_stopwords(bad_segments, stopwords)
good_segments_results_clean = drop_stopwords(good_segments, stopwords)
作用分析:
-
对好评和差评的分词结果进行停用词过滤。
-
得到
*_clean数据,更干净、更有效用于特征提取和训练。
3️⃣
构建训练数据集
bad_train = pd.DataFrame({'segment_clean':bad_segments_results_clean,'label':1})
good_train = pd.DataFrame({'segment_clean':good_segments_results_clean,'label':0})
segments_train = pd.concat([bad_train,good_train])
segments_train.to_excel('segments_train.xlsx',index=False)
作用分析:
-
给差评加标签 1,给好评加标签 0。
-
合并数据集,形成完整的训练集。
-
保存到 Excel,以便再次查看或手动检查数据。
注意事项:
-
label 定义必须明确,方便后续训练模型时一致。
划分训练集和测试集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(
segments_train['segment_clean'].values,
segments_train['label'].values,
random_state=42
)
作用分析:
-
将训练数据随机分为训练集和测试集(默认 75%:25%)。
-
random_state=42保证结果可复现。
4️⃣
将分词列表转换为字符串
x_train_words = []
for i in range(len(x_train)):
x_train_words.append(' '.join(x_train[i]))
作用分析:
-
朴素贝叶斯或 CountVectorizer 接收的是字符串而非列表。
-
将每条分词结果用空格连接成一句话。
注意事项:
-
中文必须用空格隔开,否则 CountVectorizer 会把整条句子当作一个词。
词袋模型向量化
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(max_features=4000, lowercase=False, ngram_range=(1,3))
vec.fit(x_train_words)
x_train_vec = vec.transform(x_train_words)
作用分析:
-
CountVectorizer将文本转换为数值向量(词频统计)。 -
max_features=4000保留出现频率最高的 4000 个词,减少维度。 -
ngram_range=(1,3)表示考虑 1~3 连续词组合,捕获短语信息。
5️⃣ 使用 SMOTE 过采样处理类别不平衡
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=100)
x_train_vec_dense = x_train_vec.toarray() # 转为稠密矩阵
x_train_vec_os, y_train_os = smote.fit_resample(x_train_vec_dense, y_train)
作用分析:
-
SMOTE 自动生成少数类别样本,使类别均衡,防止模型偏向多数类。
-
由于 SMOTE 不支持稀疏矩阵,所以先转成稠密矩阵,再转回训练。
6️⃣朴素贝叶斯训练与自测
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB(alpha=0.1)
classifier.fit(x_train_vec_os, y_train_os)
作用分析:
-
MultinomialNB 对词频特征非常适合,是文本分类经典模型。
-
alpha=0.1是平滑参数,避免零概率问题。
from sklearn import metrics
train_pr = classifier.predict(x_train_vec_os)
print(metrics.classification_report(y_train_os, train_pr))
作用分析:
-
在训练集上评估模型性能,包括精确率、召回率、F1-score。
7️⃣测试集预测与评估
x_test_words = [' '.join(x) for x in x_test]
test_pr = classifier.predict(vec.transform(x_test_words))
print(metrics.classification_report(y_test, test_pr))
作用分析:
-
对测试集做同样处理(分词列表 → 字符串 → 向量)。
-
输出测试集的分类指标,检验模型泛化能力。
8️⃣ 新评论实时预测函数
def new_segments_predict(new_segments):
new_segments_cut = [jieba.lcut(new_segments)]
new_segments_cut_clean = drop_stopwords(new_segments_cut, stopwords)
new_segments_cut_clean_vec = vec.transform(new_segments_cut_clean[0])
prediction = classifier.predict(new_segments_cut_clean_vec).tolist()
if prediction.count(0) > prediction.count(1):
return '这是好评'
elif prediction.count(1) > prediction.count(0):
return '这是差评'
else:
return '这是中肯评价'
作用分析:
-
分词 → 停用词过滤 → 向量化 → 模型预测。
-
将预测结果映射为“好评/差评/中肯评价”。
-
支持用户输入任意新的评论进行实时预测。
循环输入评论
while True:
new_segments = str(input('请输入新的评论:'))
if not new_segments:
break
print(new_segments_predict(new_segments))
作用分析:
-
提供命令行交互界面,可连续输入评论进行预测。
-
输入为空时循环结束。
✅ 总结
整个代码完整流程是:
文本读取 → 分词 → 停用词过滤 → 训练集构建 → 向量化 → SMOTE 平衡 → 朴素贝叶斯训练 → 模型评估 → 实时预测
5. 案例运行结果示例
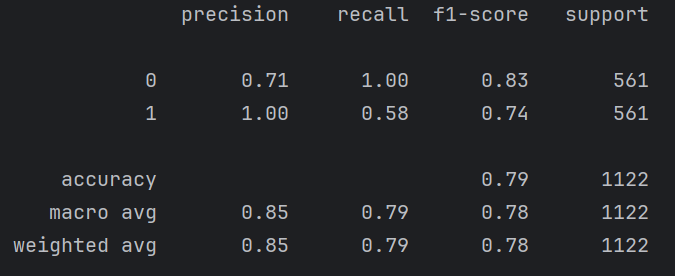
训练集评估(输出):
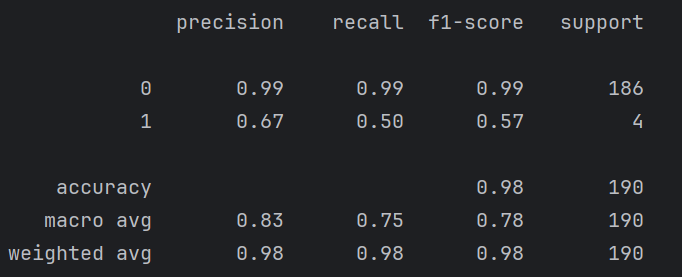
测试集评估(输出):
实时预测示例:

预测差评的准确率很低,是因为差评数量太少(好评:差评=748:12),即时使用了过采样也任然无法改变“得到的差评相关词太少”的问题
建议爬取时寻找更好的商品的评论数据集
停用词设置不完善:“手机”这类中意词也被划分为了差评词
6. 总结与优化方向
本文实现了一个基于 jieba 分词 + 朴素贝叶斯 + SMOTE + n-gram 词袋模型 的中文情感分析系统,能高效判断好评和差评。
优化方向:
-
加入 TF-IDF 代替词袋模型,提升特征质量。
-
使用 深度学习(BERT、ERNIE) 提高模型表达能力。
-
结合情感词典提升可解释性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)