AI基础学习周报九
本周深入研究了计算机视觉中的基础操作与前沿模型。首先系统解析了池化层的工作原理,包括最大池化与平均池化的计算过程及其特征图尺寸变化规律;其次研读了轻量级视觉注意力模型SalM²的创新设计,该模型结合人类视觉机制构建“自底向上+自顶向下”双分支架构,通过SCPM模块优化Mamba特征表达,并利用跨模态注意力实现驾驶场景的语义引导;最后系统学习了卡尔曼滤波的数学原理与实现流程,掌握其预测-更新两阶段状
摘要
本周深入研究了计算机视觉中的基础操作与前沿模型。首先系统解析了池化层的工作原理,包括最大池化与平均池化的计算过程及其特征图尺寸变化规律;其次研读了轻量级视觉注意力模型SalM²的创新设计,该模型结合人类视觉机制构建“自底向上+自顶向下”双分支架构,通过SCPM模块优化Mamba特征表达,并利用跨模态注意力实现驾驶场景的语义引导;最后系统学习了卡尔曼滤波的数学原理与实现流程,掌握其预测-更新两阶段状态估计机制。研究覆盖了从基础特征降维到复杂状态估计的技术链条。
Abstract
This week focused on fundamental operations and cutting-edge models in computer vision. It systematically analyzed the working principles of pooling layers including max-pooling and average-pooling, detailing their computation processes and feature map size transformation rules. The study featured an in-depth review of the lightweight visual attention model SalM², which integrates human visual mechanisms via a dual “bottom-up + top-down” architecture, optimizes Mamba feature representation through SCPM modules, and achieves semantic guidance in driving scenarios via cross-modal attention. Finally, the mathematical principles and implementation workflow of Kalman filtering were comprehensively studied, covering its two-stage state estimation mechanism of prediction and update. This research established a technical chain spanning from basic feature dimensionality reduction to complex state estimation.
1、池化
1.1 最大池化
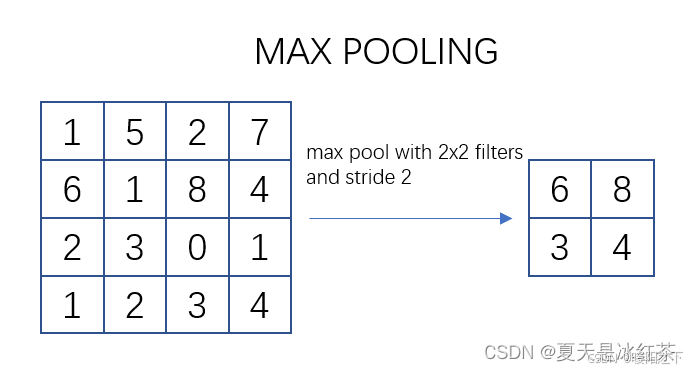
池化过程类似于卷积过程,如上图所示,表示的就是对一个 4X4 feature map邻域内的值,用一个 2X2 的filter,步长为2进行‘扫描’,选择最大值输出到下一层,这叫做 Max Pooling。
max pooling常用的 S=2,f=2 的效果:特征图高度、宽度减半,通道数不变。
1.2 平均池化

如上图所示,表示的就是对一个 4X4 feature map邻域内的值,用一个 2X2 的filter,步长为2进行‘扫描’,计算平均值输出到下一层,这叫做 Mean Pooling。
1.3 尺寸变化过程
import torch
import torch.nn as nn
input_features = torch.randn(1, 1, 28, 28) # 输入特征图大小为 28x28
max_pool = nn.MaxPool2d(kernel_size=2, stride=2) # 池化窗口大小为 2x2,步幅为 2
# avg_pool = nn.AvgPool2d(kernel_size=2, stride=2) # 池化窗口大小为 2x2,步幅为 2
output = max_pool(input_features)
print(output.size())
当将一个 1x1x28x28 的输入特征图应用最大池化操作时,可以通过使用池化窗口大小为 2x2 和步幅为 2 来实现输出尺寸为 torch.Size([1, 1, 14, 14]) 的特征图。
这是因为最大池化操作的池化窗口大小为 2x2,即在每个窗口中选择一个最大值作为输出值。同时,步幅为 2 表示在应用池化操作时,每次移动窗口的位置距离为 2。
首先,对于输入特征图的高度和宽度,由于池化窗口大小为 2x2,每次移动的步幅也为 2,因此高度和宽度都会减半。这将导致输出特征图的高度和宽度分别为原来的一半。
其次,由于输入特征图的通道数为 1,所以输出特征图的通道数也是 1,保持不变。
因此,最终的输出特征图的大小为 torch.Size([1, 1, 14, 14])。
2、SalM2:AnExtremelyLightweightSaliencyMambaModelforReal-Time CognitiveAwarenessofDriverAttention
论文地址: https://arxiv.org/pdf/2502.16214
2.1 创新点
创新点一:结合人类视觉机制的“自底向上 + 自顶向下”双分支架构
亮点:模型设计灵感来自人类视觉注意力系统,将图像视觉刺激(Bottom-up)与驾驶任务语义信息(Top-down)结合,模拟人类司机的注意力分配过程
具体做法:
- 自底向上分支用于提取场景图像的感知特征;
- 自顶向下分支利用 CLIP 模型提取语义文本信息,如“前方有行人”、“红灯”等;
- 最终在特征融合阶段引入语义引导,实现更合理的注意力预测。
创新点二:提出 SCPM 模块,优化 Mamba 的高维特征表达
SCPM(Selective Channel Parallel Mamba)模块:
- 解决传统 Mamba 模型在处理高维视觉数据时的参数膨胀问题;
- 通过并行分支和 skip-scale 残差连接增强表达力,同时避免固定通道划分带来的信息损失;
- 极大压缩模型参数,仅有 0.0759M 参数(1.6MB),适合部署在嵌入式或边缘设备上
创新点三:提出极简的跨模态注意力融合模块(CMA)
亮点:解决图像特征和文本语义特征维度不匹配的问题,提升模态间融合效果;
具体设计:
- 将CLIP提取的语义信息通过轻量投影统一到图像特征空间;
- 使用类似通道注意力机制的结构,显著增强跨模态的关联能力;
- 仅引入一个新参数,但能显著提升“注意力热图”对驾驶任务变化的响应能力
2.2 实验与实际效果
- 在 TrafficGaze、DrFixD-rainy、BDDA 三大数据集上验证,性能达到或超过现有SOTA模型;
- 在保持 98%以上SOTA性能的同时,模型参数仅为主流模型的 0.09%–11.16%,极具实用性;
- 消融实验显示,“Top-down语义分支”和“SCPM结构”对性能提升至关重要
2.3 方法
整体结构
SalM²模型采用双分支结构,结合“自底向上”的图像感知特征和“自顶向下”的语义任务引导信息进行驾驶员注意力预测。其主干网络基于轻量级的Mamba框架构建,使用SCPM模块高效提取图像特征;同时引入CLIP模型提取驾驶场景的语义描述,通过跨模态注意力模块(CMA)将语义信息与视觉特征融合,引导模型更精准地生成符合驾驶任务的注意力显著图,实现高性能、低计算成本的注意力预测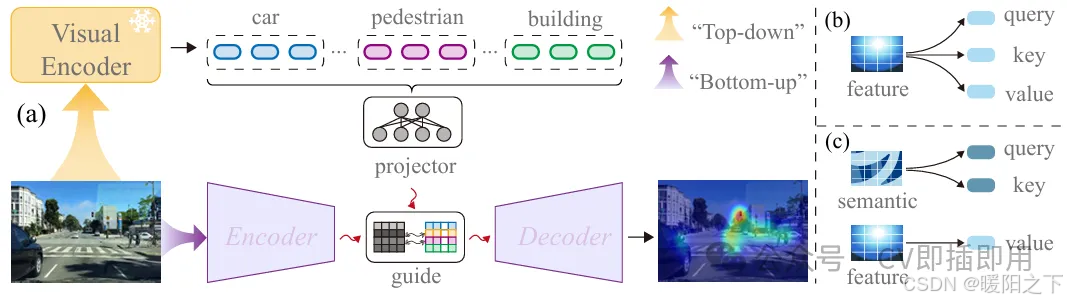
3、卡尔曼滤波
卡尔曼滤波(Kalman Filter)是一种线性最小方差估计器,用于在存在噪声的情况下对随机过程或系统进行估计。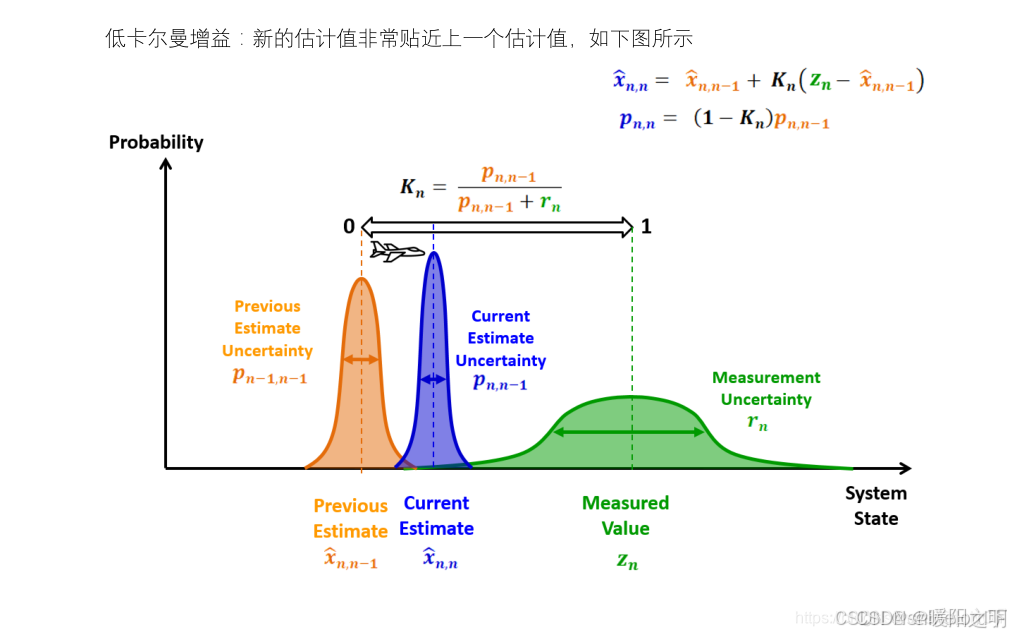
3.1 算法原理
卡尔曼滤波算法的基本思想是通过一系列的迭代步骤,不断优化对系统状态的估计。算法的主要步骤如下:
预测:根据当前的系统状态估计和噪声,预测下一个状态。
更新:根据新的测量值和预测状态,更新系统状态估计。
卡尔曼滤波算法适用于线性系统,并且可以处理随机噪声。算法通过预测和更新步骤,不断优化对系统状态的估计,从而实现对系统的准确控制。
卡尔曼滤波(Kalman Filter)是一种递归滤波器,能够通过一系列不完全和噪声数据来估计系统的状态。它广泛应用于控制系统、导航、信号处理等领域。卡尔曼滤波的核心思想是利用线性动态系统的状态方程和观测方程,通过预测和更新步骤来逐步逼近真实状态。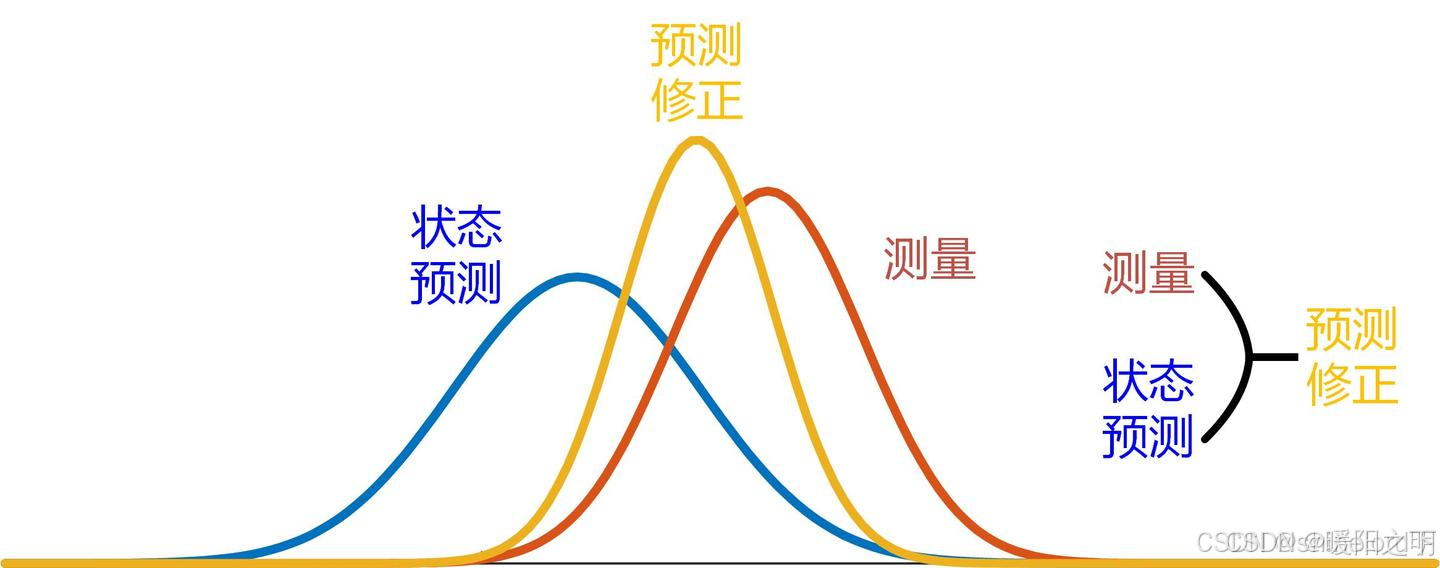
3.2 数学模型
卡尔曼滤波基于以下线性动态模型:
卡尔曼滤波的过程分为两个主要步骤:
3.3 数据结构
卡尔曼滤波算法主要涉及以下数据结构:
- 状态向量 (x):表示系统当前状态的向量。
- 状态转移矩阵 (F):描述系统如何从一个状态转移到下一个状态的矩阵。
- 控制输入矩阵 (B):描述控制输入对状态的影响。
- 观测矩阵 (H):描述如何从状态向量获得观测值的矩阵。
- 过程噪声协方差 (Q):描述过程噪声的协方差矩阵。
- 观测噪声协方差 ®:描述观测噪声的协方差矩阵。
- 误差协方差矩阵 §:描述状态估计的不确定性。
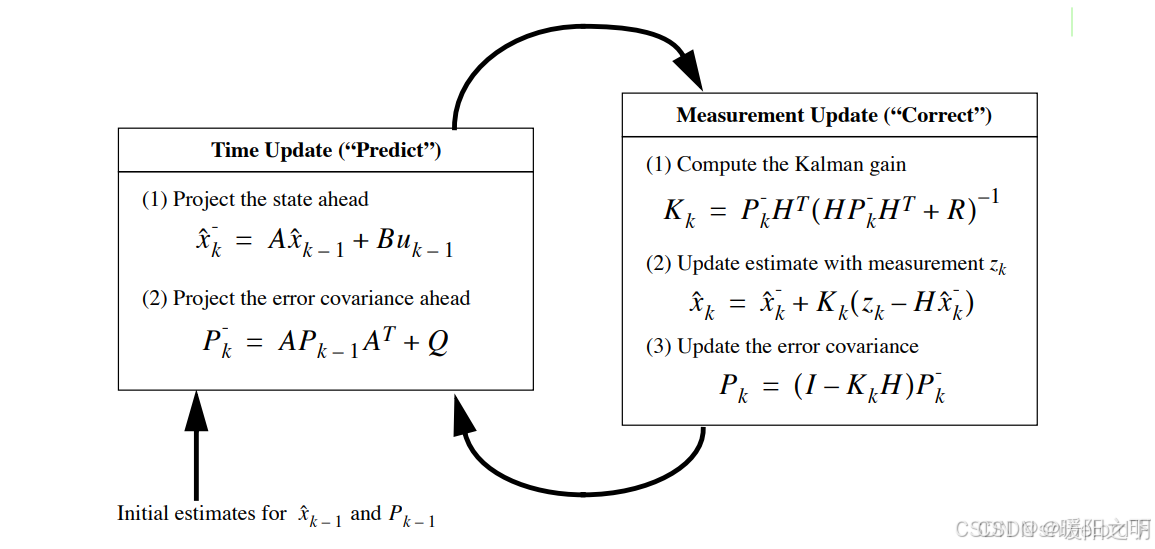
总结
本周通过三方面研究构建了完整的技术认知体系:在基础操作层,详细解析了池化操作的核心原理——最大池化通过局部最大值提取显著特征,平均池化通过局部均值保留整体信息,二者均能实现特征图尺寸减半;在模型创新层,重点剖析了SalM²的双分支架构设计;在算法层,系统推导了卡尔曼滤波的数学框架。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)