论文精读:Continual Test-Time Domain Adaptation(持续测试时域自适应)
本文介绍了2022年CVPR上的CoTTA论文,针对动态目标域下的持续测试时自适应问题。传统方法在长期适应中会出现错误累积和灾难性遗忘。CoTTA通过权重平均和增强平均生成高质量伪标签,并采用随机恢复机制保留源知识。实验表明,在CIFAR10/100-C、ImageNet-C分类任务和Cityscapes→ACDC分割任务上,CoTTA显著优于其他方法。该方法无需源数据,可部署于任何预训练模型,有
本篇文章介绍的还是TTA这个领域的经典论文,是2022年CVPR上的一篇论文。
论文链接:https://arxiv.org/pdf/2203.13591
代码链接:https://qin.ee/cotta
一、论文摘要:
这篇文章针对的是非平稳的环境,也就是目标域是动态的(我们上篇笔记所介绍的tent目标域是静态的,模型只需要适应一次新的分布),目标域分布随着时间发生变化,在持续测试时自适应这种场景下会出现灾难性遗忘和错误累积两种。
为了应对这两种问题,作者提出了他的方法CoTTA。这个方法主要有两个创新点:1、通过权重平均和增强平均产生更高质量的预测结果,减轻错误累积的影响;2、通过随机将模型的部分权重恢复为源训练模型权重,一定程度保留源模型的知识,防止严重的遗忘问题。
作者提出的这个方法在图像分类任务中的CIFAR-10C、CIFAR100-C、ImageNet-C以及语义分割领域上都达到了非常好的效果。
二、论文背景
首先作者给出了几种域适应的不同设置,而这次CoTTA就是为了针对第四种这个持续测试时自适应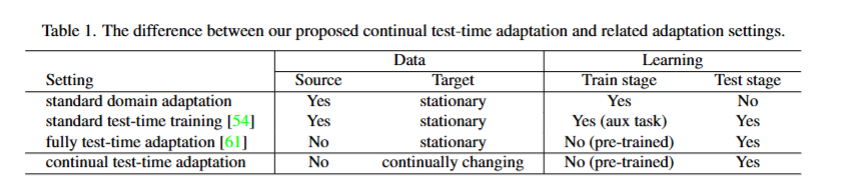
在这种环境下,目标域的分布一直在变化(实际生活中比如自动驾驶,模型遇到的环境一直在变化),这种情况下的自适应会出现错误累积和灾难性遗忘的问题。已经有的方法比如我上篇笔记提到的tent,比较依赖归一化层,一旦换模型架构,性能就会下降,同时在这种长期的自适应下,tent更新的模型性能会越来越差,几乎崩溃。因此,对于这种情景作者就提出了他的CoTTA方法。
可以看到在这种持续测试时自适应场景下,也不需要源数据,这种方向我感觉是很有必要的。
而且这个和那个全测试时自适应都不用源数据也没有目标数据的标签,那么在这种情况下,错误累积和灾难性遗忘一定是这两种情况需要解决的大头。
三、算法解析
那么话不多说,我们直接来看作者提出的CoTTA算法。
在详细梳理这个算法流程及算法细节之前我们需要先了解几个点。
权重平均和增强平均是什么意思,为什么要这样做?
权重平均是集成不同的模型权重(比如在多次迭代中的不同的模型权重、不同随机种子的模型权重等等)的一种方法,通过这种方法形成新的权重再预测后可以平滑单次预测的噪声。
而增强平均主要是指使用多种数据增强的手段(比如颜色抖动、翻转等等)处理输入的图像,从而生成更多、更丰富的图像,这样模型在预测时就可以多次预测后取平均。
这两种方法主要是为了减轻错误累积,在这种持续测试时自适应中,通过这两种手段可以预测生成更高质量的伪标签,那么在利用这个伪标签去更新的时候错误率就会降低,从而提升模型性能。
算法流程
下面这张图是论文中给出的,非常生动形象地描述了整个持续测试时自适应的过程。
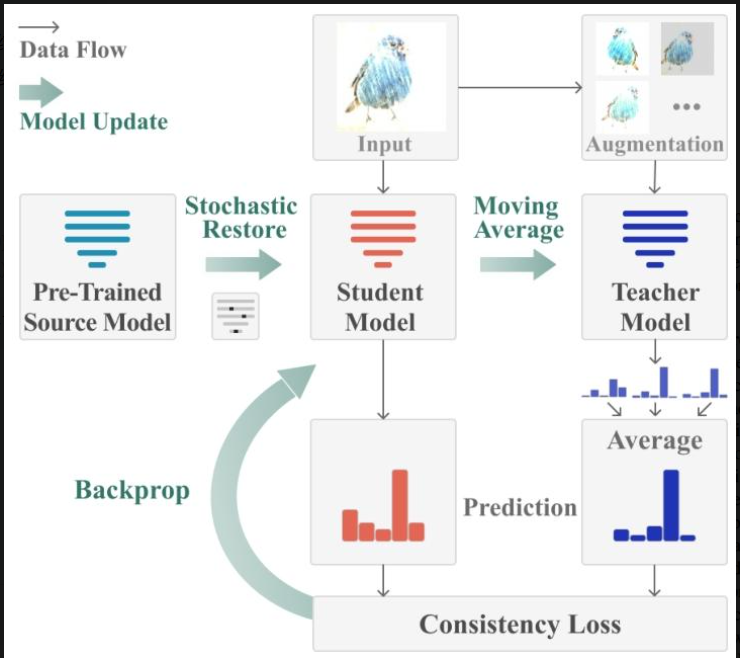
那么接下来是具体的算法过程。参照论文中的Algorithm

1、使用预训练好的源模型初始化。教师模型和学生模型均初始化为与预训练模型相同的参数。
2、接收当前时间步内输入的目标域的数据流。
3、依照情况决定是否对当前输入的数据进行数据增强,然后通过教师模型生成权重平均和增强平均后的伪标签。
4、使用伪标签作为监督,通过损失函数更新学生模型的参数。
5、使用移动平均策略更新教师模型的参数。
6、通过随机恢复机制,随机将学生模型的部分参数恢复为预训练模型训练好后的模型参数。
7、输出当前时间步的预测结果和更新后的学生模型和教师模型,进行下一个时间步的迭代。
算法细节
那么上面这个就是他提出的CoTTA算法的流程,那么这里会有几个问题,我们一一来分析。
什么时候对当前输入数据进行数据增强?
首先我们要知道,当教师模型经过权重平均后预测生成的伪标签质量较高时,那么这个时候就不用进行这个数据增强平均了,因为这时候生成的标签已经足够好,再强行使用数据增强效果反而可能会下降。而当预测生成的伪标签质量较低时,那么这个时候为了得到一个质量较高的伪标签,那么久需要进行数据增强来扩展图片丰富度。所以,这里就用到了一个置信度的知识,只有当预测出来的伪标签小于于置信度阈值pth时,才会引入数据增强来使预测平滑。
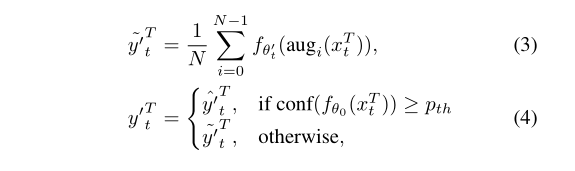
正如上面论文中的公式那样,其中公式3是增强平均,聚合多视角的预测,来提升伪标签质量。
那么这样置信度来过滤的意义其实无非两点:1、避免无效增强,对于高置信度样本增强可能会破坏样本原特征,使伪标签质量下降。2、减少错误累积,对于低置信度的伪标签直接用来更新模型,无疑会加剧模型的错误,导致错误累积。
学生模型和教师模型是如何更新的?
学生模型作为主模型通过教师模型生成的伪标签作为监督,然后通过最小化公式(如下图)中的损失函数反向传播,更新全部参数,实现在线自适应。
其中这里面的参数第一个y是教师模型生成的伪标签,第二个y是学生模型预测的结果。
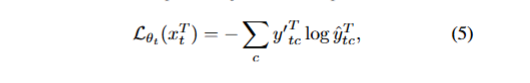
对于教师模型,采用移动平均的策略更新,聚合学生模型历史迭代过程中的参数状态,平滑单步更新的噪声,实现对长期知识的稳定保留,保障能够生成有质量的伪标签。
如下图公式θt+1是更新过后的学生模型参数(在一个时间步内,总是学生模型先更新),θ丿则是当前时间步还未更新的教师模型参数,α是平滑因子,更新后的教师模型参数就是θt+1丿。
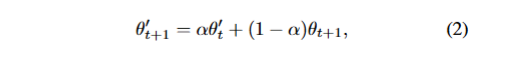
权重随机恢复机制是怎么样的?
权重恢复机制是为了避免模型在长期自适应过程中产生的灾难性遗忘问题,通过这种方式,模型会以较低的概率随机将部分权重恢复到预训练模型(也就是源模型)的初始状态,在保留持续测试时自适应过程中学习到的新的知识外,还能够保留源模型的基础知识。
随机恢复机制的核心操作如下两个公式:
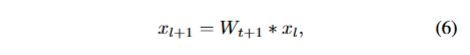
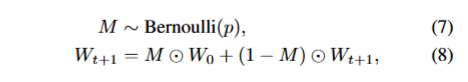
首先看公式6,Wt+1是一个可训练的卷积滤波器,*表示卷积操作,Xt,Xt+1分别表示该层的输入和输出。那么W这个权重是如何更新的呢?
我们从公式看到先生成一个服从伯努利分布的掩码张量M,M内的每个元素取值为1的概率是p(一个极小的恢复概率),那么取值为0的概率就是1-p。
M的形状与该卷积层的权重W是相同的,其中![]() 表示逐元素乘法,当M中某位置元素为1时,那么该位置的权重就会被恢复为源预训练模型的初始权重W0,否则还是当前训练好后的权重。
表示逐元素乘法,当M中某位置元素为1时,那么该位置的权重就会被恢复为源预训练模型的初始权重W0,否则还是当前训练好后的权重。
CoTTA算法代码解析
以下代码来自论文中代码链接的cifar文件夹里面的cotta.py文件
我们只需要来看它算法核心的几个实现来印证上面论文中所提到的算法原理
我们先来看cotta类和核心定义部分
class CoTTA(nn.Module):
"""CoTTA adapts a model by entropy minimization during testing.
Once tented, a model adapts itself by updating on every forward.
"""
def __init__(self, model, optimizer, steps=1, episodic=False, mt_alpha=0.99, rst_m=0.1, ap=0.9):
super().__init__() # 调用父类nn.Module的初始化
self.model = model # 学生模型(待适应的模型)
self.optimizer = optimizer # 优化器(用于更新学生模型)
self.steps = steps # 每个batch的适应步数(默认1)
assert steps > 0, "cotta requires >= 1 step(s) to forward and update" # 确保步数为正
self.episodic = episodic # 是否启用episodic模式(每个batch重置模型)
# 复制模型和优化器的初始状态,用于后续重置(包括教师模型和锚点模型)
self.model_state, self.optimizer_state, self.model_ema, self.model_anchor = \
copy_model_and_optimizer(self.model, self.optimizer)
self.transform = get_tta_transforms() # 初始化测试时数据增强管道
self.mt = mt_alpha # EMA更新系数(教师模型平滑系数)
self.rst = rst_m # 随机参数恢复概率(防止灾难性遗忘)
self.ap = ap # 置信度阈值(决定是否使用增强样本)可以看到这里面最重要的定义类学生模型,教师模型,教师模型的更新洗漱,随机恢复机制的概率,置信度阈值等这些非常重要的实现,与上面论文中说的核心机制相符。
那么接下来这段代码则展示了教师模型与学生模型不同的特点,使用学生模型初始状态深拷贝得来,同时不参与梯度计算,利用学生模型来更新。
def copy_model_and_optimizer(model, optimizer):
"""Copy the model and optimizer states for resetting after adaptation."""
model_state = deepcopy(model.state_dict()) # 深拷贝学生模型初始状态
model_anchor = deepcopy(model) # 深拷贝模型作为锚点模型(置信度参考)
optimizer_state = deepcopy(optimizer.state_dict()) # 深拷贝优化器初始状态
ema_model = deepcopy(model) # 深拷贝模型作为初始教师模型(EMA)
for param in ema_model.parameters():
param.detach_() # 教师模型参数不参与梯度计算
return model_state, optimizer_state, ema_model, model_anchor # 返回拷贝的状态和模型而学生模型更新利用的损失函数则跟论文中提到的一样,都是使用交叉熵损失,如下面代码。
@torch.jit.script # 用TorchScript编译,加速执行
def softmax_entropy(x, x_ema): # x:学生输出;x_ema:教师输出
"""Entropy of softmax distribution from logits."""
# 对称交叉熵:同时考虑学生对教师的熵和教师对学生的熵(平衡两者)
return -0.5*(x_ema.softmax(1) * x.log_softmax(1)).sum(1)-0.5*(x.softmax(1) * x_ema.log_softmax(1)).sum(1)那么有了核心类的定义,学生模型和教师模型,我们来看cotta的前向传播和适应的核心方法。
@torch.enable_grad() # 确保在测试模式(可能关闭梯度)下启用梯度计算
def forward_and_adapt(self, x, model, optimizer):
# 学生模型前向传播,得到当前输出
outputs = self.model(x)
# 教师模型预测(用于生成目标分布)
# 1. 锚点模型(初始模型副本)计算输入的置信度(预测概率的最大值)
anchor_prob = torch.nn.functional.softmax(self.model_anchor(x), dim=1).max(1)[0]
# 2. 教师模型(EMA)的标准输出(无增强)
standard_ema = self.model_ema(x)
# 增强样本的教师预测(用于复杂分布适应)
N = 32 # 生成32个增强样本
outputs_emas = []
for i in range(N):
# 对输入x进行增强,教师模型预测并 detach(不参与梯度计算)
outputs_ = self.model_ema(self.transform(x)).detach()
outputs_emas.append(outputs_) # 收集增强样本的教师输出
# 根据锚点模型的置信度选择教师目标输出
# 若平均置信度低于阈值self.ap(如0.9),说明分布复杂,使用增强样本的平均输出
if anchor_prob.mean(0) < self.ap:
outputs_ema = torch.stack(outputs_emas).mean(0) # 32个增强样本输出的平均值
else:
outputs_ema = standard_ema # 否则使用标准输出(分布简单,无需增强)
# 学生模型更新:最小化与教师输出的交叉熵损失
loss = (softmax_entropy(outputs, outputs_ema)).mean(0) # 计算损失(见下方函数)
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新学生模型参数
optimizer.zero_grad() # 清空梯度
# 教师模型更新:用EMA更新教师参数(平滑跟踪学生模型)
self.model_ema = update_ema_variables(ema_model=self.model_ema, model=self.model, alpha_teacher=self.mt)
# 随机参数恢复(Stochastic Restore):缓解灾难性遗忘
if True: # 始终启用该机制
# 遍历学生模型的所有模块和参数
for nm, m in self.model.named_modules():
for npp, p in m.named_parameters():
# 仅处理可训练的权重和偏置
if npp in ['weight', 'bias'] and p.requires_grad:
# 生成随机掩码:按概率self.rst(如0.01)为1,否则为0
mask = (torch.rand(p.shape) < self.rst).float().cuda()
with torch.no_grad(): # 不跟踪梯度
# 按掩码恢复部分参数到初始状态:p = 初始值 * mask + 当前值 * (1 - mask)
p.data = self.model_state[f"{nm}.{npp}"] * mask + p * (1. - mask)
return outputs_ema # 返回教师模型的目标输出上面这段代码非常重要,几乎是整个论文最核心的部分,首先我们看到这里面实现了根据置信度来决定是否进行数据增强平均、学生模型通过梯度更新、教师模型通过学生模型和系数进行更新、以及随机恢复机制的实现。
而教师模型的更新如下:
def update_ema_variables(ema_model, model, alpha_teacher):
# 遍历教师模型和学生模型的参数,用指数移动平均(EMA)更新教师参数
for ema_param, param in zip(ema_model.parameters(), model.parameters()):
# EMA公式:ema_param = alpha * 旧ema_param + (1 - alpha) * 学生模型参数
ema_param.data[:] = alpha_teacher * ema_param[:].data[:] + (1 - alpha_teacher) * param[:].data[:]
return ema_model # 返回更新后的教师模型可以看到跟论文中提到的更新公式一模一样。
同时我们也别忘了,CoTTA是可以更新所有参数的,而tent只更新归一化层中的参数,那么区别在代码中体现如下:
def collect_params(model):
"""Collect all trainable parameters.
Walk the model's modules and collect all parameters.
Return the parameters and their names.
Note: other choices of parameterization are possible!
"""
params = [] # 存储可训练参数
names = [] # 存储参数名称(用于调试)
for nm, m in model.named_modules(): # 遍历模型所有模块
if True: # 此处为True,表示收集所有模块的参数(与TENT仅收集BN层不同)
for np, p in m.named_parameters(): # 遍历模块内参数
# 仅收集可训练的权重和偏置
if np in ['weight', 'bias'] and p.requires_grad:
params.append(p)
names.append(f"{nm}.{np}") # 记录参数路径(如conv1.weight)
print(nm, np) # 打印参数名称(调试用)
return params, names # 返回参数列表和名称列表这里面收集了所有可训练的参数,正好体现了CoTTA训练所有参数的设置。
那么以上就是CoTTA算法的代码实现的所有核心部分,有权重平均和数据增强平均减轻错误累积,也有随机恢复机制防止灾难性遗忘。
四、实验结果
接着我们来看看论文中的实验设置以及实验效果看看这个CoTTA算法到底怎么样。
实验设置
1、数据集与任务
对于分类任务:
在CIFAR10->CIFAR10C、CIFAR100->CIFAR100-C上,使用严重程度为5级的15种损坏类型,按数据流的方式输入,模拟目标域动态变化的过程。
在ImageNet->ImageNet-C上,测了10钟损坏类型。
对于分割任务:
从Cityscapes->ACDC在4种天气(雾、夜、雨、雪)上循环进行了10次,验证长期是否会遗忘
2、模型与参数设置
分类模型:WideResNet-28(CIFAR10)、ResNeXt-29(CIFAR100)、ResNet50(ImageNet),更新所有可训练参数(区别于仅更新 BN 层的 TENT)。
分割模型:Segformer-B5,使用多尺度增强和 Adam 优化器,学习率降低 8 倍(因 batch size=1)。
随机恢复的概率p=0.01,数据增强的次数N=32,置信度的阈值pth设置为0.9。
实验结果
在CIFAR10-C15种损坏类型的准确率如下,可以看到CoTTA在所列的几种方法中是最优的。
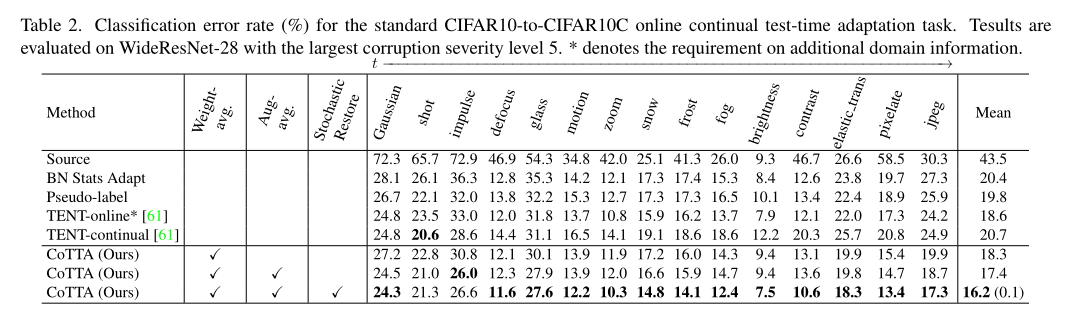
同时通过设置是否权重平均、数据增强平均、以及是否使用随机恢复机制这样的消融实验,作者还证明了这些组件的效用。比如加了随机恢复之后可以看到准确率提升较为明显,抗遗忘能力增强。
在CIFAR10-C渐进域的实验结果如下:

渐进域的构造方法是使用严重程度从1->5->1这样的一直在变化的严重程度来模拟渐进效果,可以看到CoTTA方法较其他方法涨幅明显。
在CIFAR100-C上的实验结果如下:
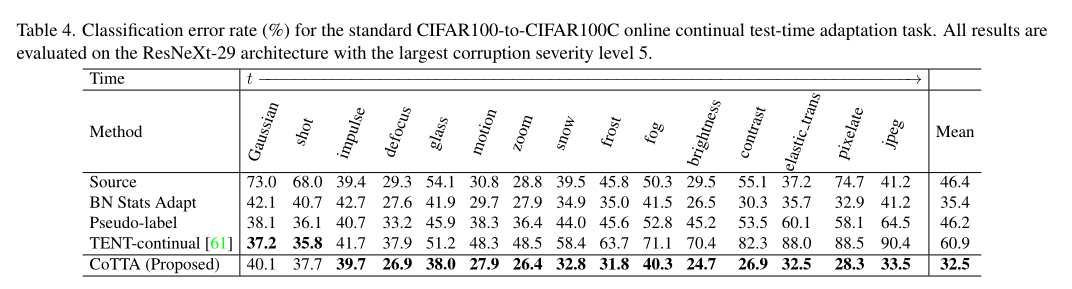
可以看到CoTTA的效果是比较优秀的,同时注意到TENT方法在这种目标域是动态的情况下,错误累积和灾难性遗忘显著,到最后模型性能大大下降,几乎崩溃。
在ImageNet-C上的实验结果如下:

CoTTA的效果较其他几种方法是较为优秀的。
最后是在分割任务上的实验结果如下:
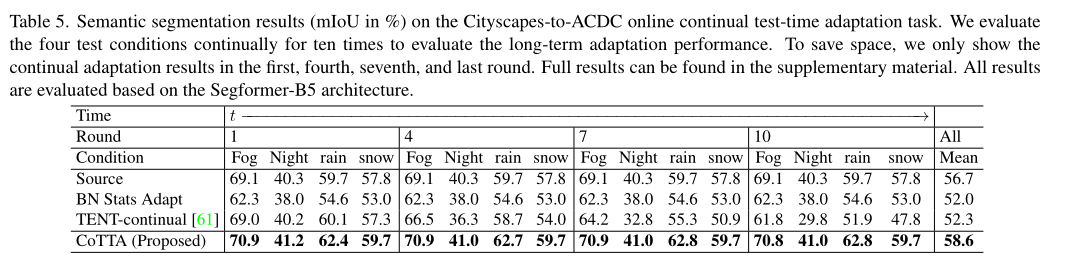
可以看到,CoTTA在测试后期仍能保持不错的准确率,而其他两种优化的方法在测试后期性能大幅下降,正是错误累积和遗忘的效果,这展现了CoTTA在此类问题上的优秀。
五、论文总结
读完了论文之后,依旧是熟悉的8个问题等着我们来总结。
1、论文研究了什么问题
针对动态目标域的持续测试时自适应,解决错误累积和灾难性遗忘问题。
2、为什么这个问题是一个很重要的问题
现实场景(比如如自动驾驶)中环境持续变化,现有方法(比如 TENT)在长期适应中性能会崩溃,对于这种新的场景需要提出新的方法。
3、当前这个问题的研究现状
传统方法(说的就是你TENT)依赖归一化层或固定增强策略,无法应对动态分布变化,易导致错误累积和遗忘。
4、本文提出了什么算法
提出了CoTTA算法,通过权重平均(教师模型 EMA)和增强平均(置信度触发数据增强)提升伪标签质量,结合随机恢复机制保留源知识。
5、为什么这个算法是合理且有效的
权重平均和增强平均减少错误累积,随机恢复缓解遗忘,作者通过消融实验证明了组件的有效。
6、文章做了什么实验来验证这个算法
在分类任务和分割任务上进行实验,在分类任务上CIFAR10/100-C、ImageNet-C 上错误率显著低于 TENT,在分割任务上Cityscapes→ACDC 的 mIoU 达 58.6%,远超 TENT 的 52.3%。
7、为什么这些实验是合理的
模拟了真实的目标域变化的动态环境,同时在多种任务上进行测试,较为全面。
8、作者还做了什么论述来证明这个算法的有效性
CoTTA方法不需要源数据,可以在任何预训练好的模型上部署。同时随机恢复机制通过数学方法如生成伯努利掩码然后进行矩阵操作的方法实现。
以上是近期看的论文CoTTA,希望对读者有所帮助,同时作为我学习论文的见证,感谢观看。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)