机器学习学习笔记——04
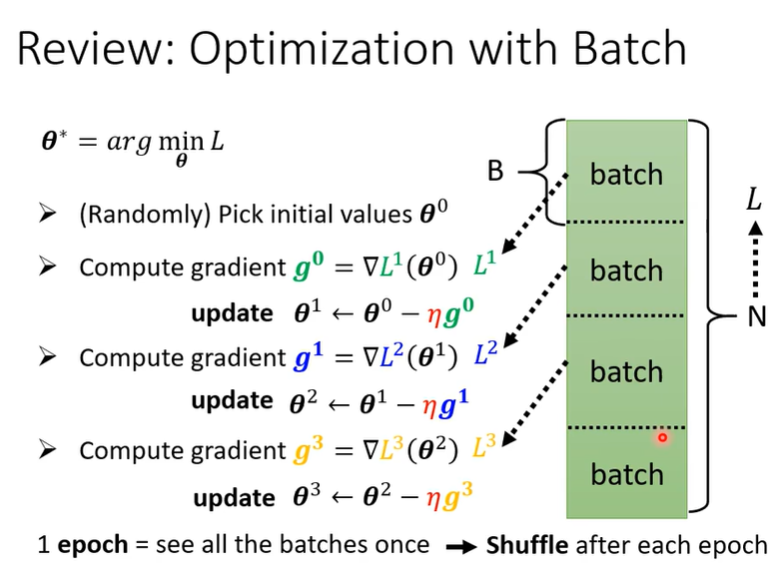
为什么training的时候要用batch?在计算微分的时候,不是将所有的data算微分,而是将整个training data分成一个一个的batch分别算微分。在之前的学习中已经了解到,在Optimization的过程中,会将整个Training Data分为数块,这样的一块称为一个Batch。更新参数的过程就变成了,将初始参数分别带入各个Batch进行更新,分别计算Gradient并更新参数。
Batch and Momentum
Batch
为什么training的时候要用batch?在计算微分的时候,不是将所有的data算微分,而是将整个training data分成一个一个的batch分别算微分。
在之前的学习中已经了解到,在Optimization的过程中,会将整个Training Data分为数块,这样的一块称为一个Batch。更新参数的过程就变成了,将初始参数 分别带入各个Batch进行更新,分别计算Gradient并更新参数
。而所有Batch都计算过一遍则称为一次 Epoch。
这里需要说明,每次epoch之后都要重新划分一次batch(就是说batch在每次更新参数前都要重新划分,它并不固定)。而这样在每次epoch中,保证哪个数据在哪个batch里都不一样,或者说是不确定的。这样的行为称为Shuffle(就是每次epoch之前都要保证各个batch不和上次更新完全相同,通俗理解就是更新之前先洗牌)
那我们已经知道了,batch、epoch以及相关的行为流程,那么在Optimization过程中使用batch有什么用呢?或者说batch的大小能对我们的优化过程产生什么帮助吗?
Batch大小的影响
李老师举了一个极端的例子,假设有一个训练集有20个数据,其中一组batch我们设定为20个,这样Batch Size = Training Data Size的Batch我们称为Full Batch。而另一组的大小设定为1个,我自己设为Mini Batch。在参数更新过程中我们就能明显看出差别。
Full Batch
对于Full Batch算法需要看完二十个数据才会开始计算gradient,进而才能计算Loss。也就是需要计算完所有数据,参数 才会更新。
Mini Batch
而对于Mini Batch每次更新参数则只需要看一个资料就能更新一次参数,一共有二十个batch,所以一个epoch会更新二十次参数。

两相对比之下,我们可以看出这两种方法的特点,对于Full Batch虽然更新比较慢,但是因为计算的样本更多所以更加稳定。对于Mini Batch来说则完全相反,较快的更新速度所带来的是更新方向的不准确。
Large Batch 与 Small Batch的优劣
这样好像就陷入了混沌= =,那既然各有优缺点我们应该选Large Batch还是Small Batch呢?
这里就要根据现实情况引入一个概念:平行计算(Parallel computing)。在参数update的过程中其实可以用电脑的GPU参与实现数据的平行计算。所以计算Large Batch所需的时间不一定比Small Batch长。当然这个Large也不能太大,毕竟GPU的算力也是有极限的当Large太大,所需的时间同样也会随之上升。
这里就出现了一个意外,因为计算Large Batch的时间不一定更长,但是一次update所需的时间确实固定的。这就导致可能Small Batch在一次epoch的过程中所需的时间比Large Batch更久。
李老师用了一个实验例子来进行说明。当你将Batch Size分别设置为1、10、100、1000、10000等不同大小的情况下,你的一次update的时间以及一次epoch的时间。
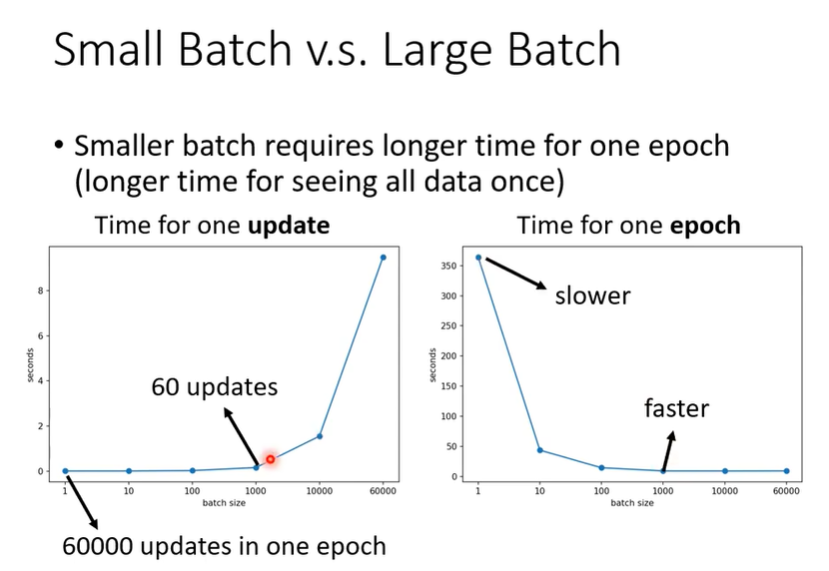
可以看出在Training Data较大的情况下,虽然Small Batch一次update很快,但是update的次数过多,导致整个epoch的时间反而没有Large Batch的速度快。
这么一看好像我们应该选Large Batch,毕竟Large Batch的时间优势明显的同时,更新的方向还非常稳定,怎么看都是优啊。然而实际结果却是反直觉的。
Large Batch 与 Small Batch的正确率
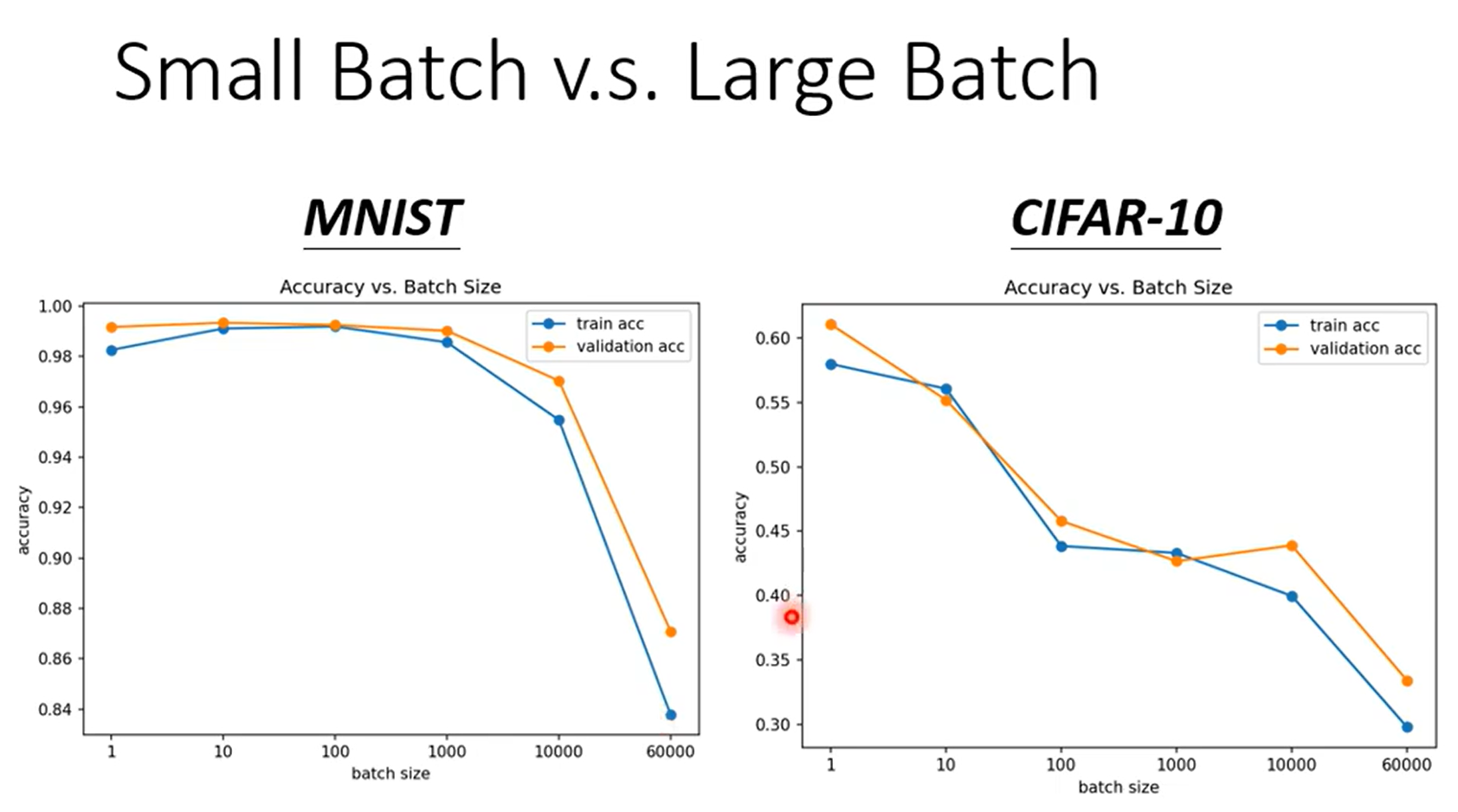
明显看出无论是Training Set还是Validation Set,Batch Size越大,正确率越低。使用的明明是一个Function,按理无论Batch Size大小,得到的结果应该差不多才对。
但事实就是Batch Size越大,正确率越低。
PS:Validation Set就是之前讲的机器学习学习笔记——02-CSDN博客,将原本的训练集分为两份,Training Set用来训练参数,Validation Set用来计算Loss
为什么会这样呢?
假设你使用Full Batch,沿着Loss Functio的方向update参数,当你Critical P oint的时候就会停止更新(假设不用Hessian矩阵)。但是你使用Small Batch的时候,虽然你依然会在Batch中算到Critical Point,但是你每个Batch都不完全相同,第一个Batch算到Critical Point停下,那就换第二个,第二个停下就换第三个。。。
所以Small Batch这种“Noisy”的方式在Train中可能效果更好。
这里李老师给了一个解释,我根据我的理解说明。
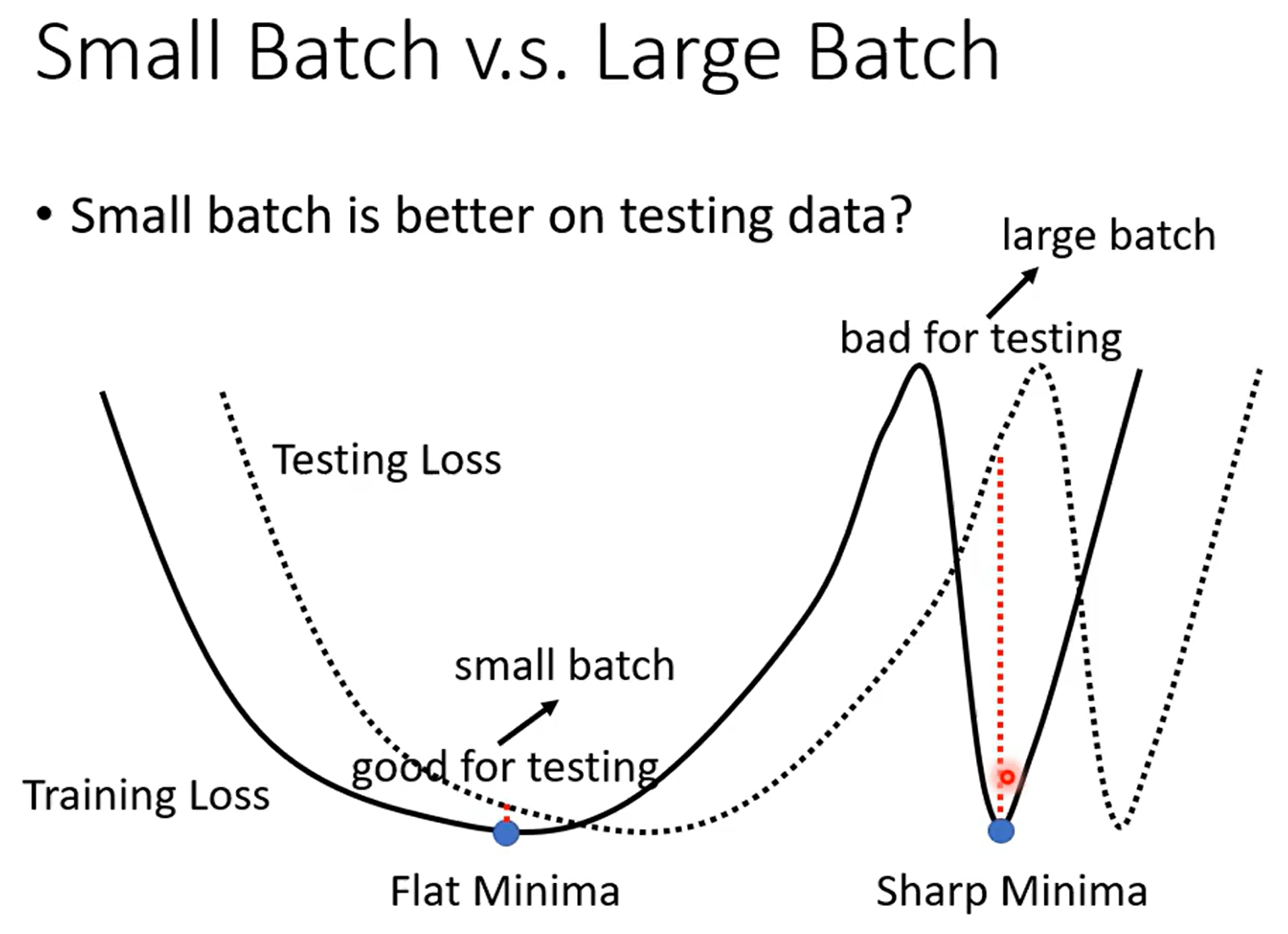
我们假设,Training Loss的曲线如图,很明显在曲线中有许许多多个Critical Point,我们只假设图中出现的两个均为Local Minima,且两个Minima的Loss都趋近于0。一个在深谷里面,一个在盆地里面。
这里就要引入一个概念,人们认为同样是Local Minima也有好的Minima和坏的Minima之分。人们认为在深谷里面的Minima效果是相对不好的,而在盆地里的Minima效果是相对好的。
因为计算得出的Testing Loss的曲线不一定与Training Loss相同,可能是选用的数据不一样或者其他原因。那我们假设Testing Loss的曲线就是想右偏移一些。结果发现,对于在盆地里的Flat Minima(平坦的极小值) Training和Testing的Loss相差还不算多,但是在深谷里的Sharp Minima(尖锐的极小值)却是天差地别。
而人们认为对于Large Batch在计算过程中更容易进入Sharp Minima,而对于Small Batch则更容易得到Flat Minima。
我的理解就是,对于Large Batch朝着减小Loss的方向稳定移动长距离,很有可能一脚直接踩进坑里,然后因为Large Batch的特性,就像进入陷阱一样出不来了。但是对于Small Batch因为移动方向的不确定以及移动距离较短,所以有可能第一个进去一点点,下一个Batch计算的时候就跳出去了,而在盆地因为移动距离的原因,可能移动完也跳不出去就回到了Flat Minima。
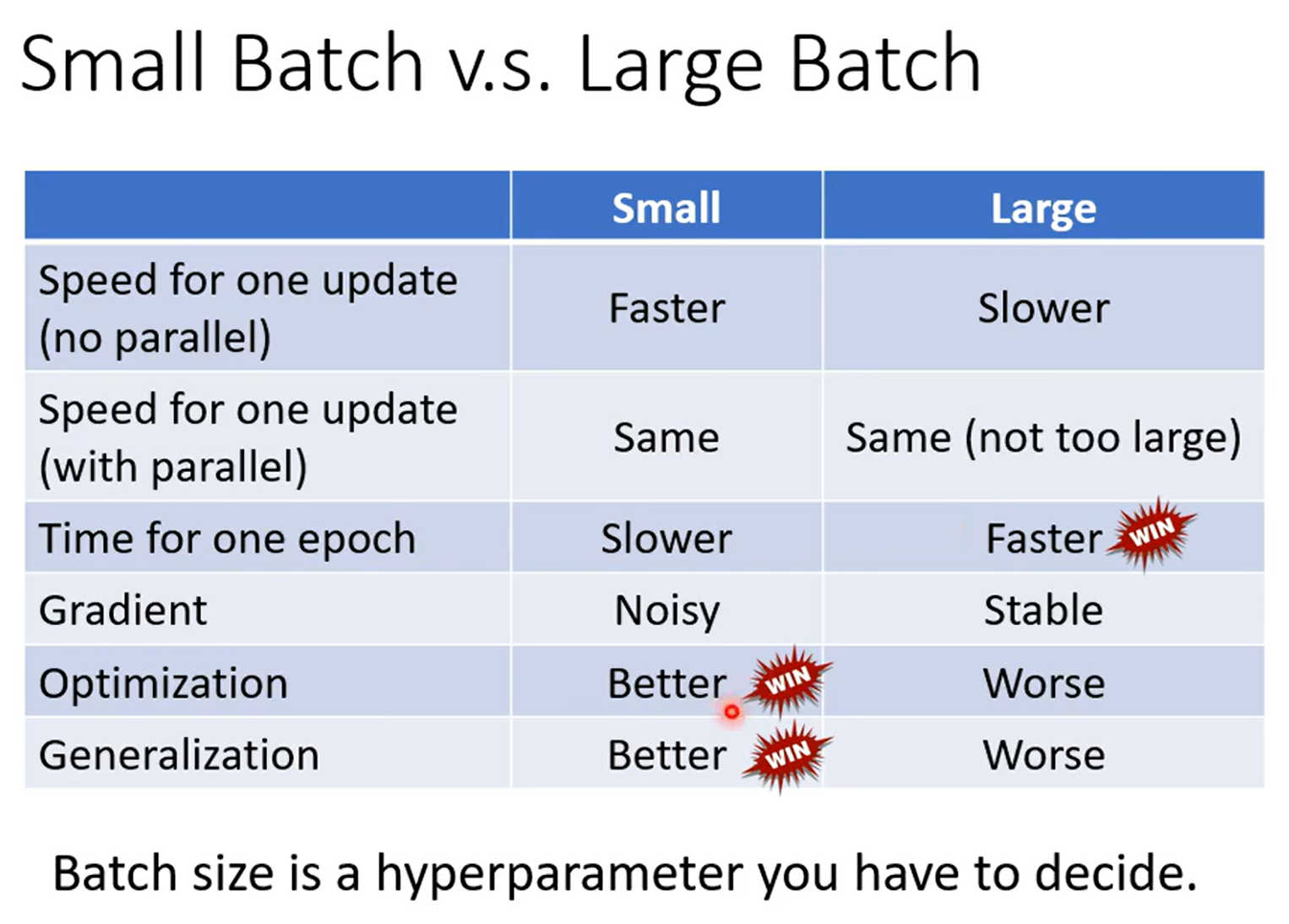
综上我们就可以总结两者的特点
Momentum
在讲Momentun之前先回顾一下普通Gradient Descent的过程。
1、设定一个参数
2、计算这个点的gradient(计算微分)
3、沿着这个点的反方向更新参数
这个过程一直反复知道gradient为0,也就是遇到Critical Point
再次基础上加上Momentum之后
我们新加入一个前一步的方向,也就是将上一步的移动方向也纳入考虑。初始的Movement: 。然后正常计算gradient。
关键:更新参数的方向不再是gradient的反方向,而是计算Movement的方向:
作为最终参数更新的方向:
同时 也作为新的前一步纳入下一步方向的计算。
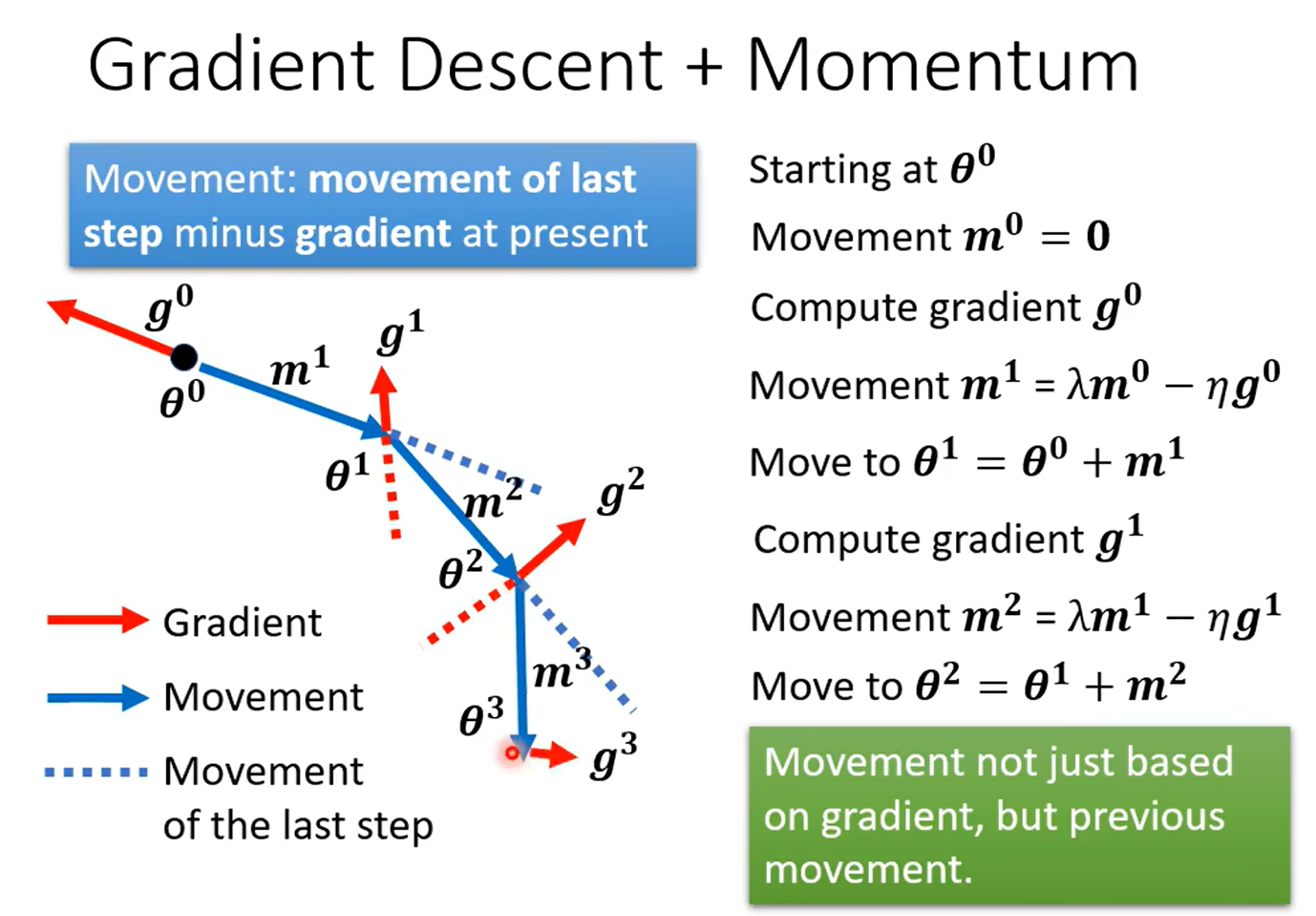
用一个图像的例子,可以更加容易理解。
Momentum可以看作是一种惯性,对于初始的参数 计算完G之后因为没有前一次移动的方向,所以G的方向就是移动的方向,因为G很大所以移动很远。假设移动到了一个Loss很小的点,这次G没有那么大了,但是因为前一次Movement的方向,一起加上后又往前移动了一段距离,假设这次走到了Local Minima,G = 0了,但是因为有前一次Movement的方向,所以依然会向前移动。即使这一次移动到的位置,G已经显示要往回走了,但是因为有前一次Movement的方向,两者相消后,依然可以向前走。
以上是根据图像和李老师的讲解进行的理解。我感觉Momentum的作用就是帮助解决Loss减小过程中Critical Point的问题,尤其是Local Minima,原来的Gradient Descent,虽然我们能够通过Hessian矩阵解决Saddle Point 问题,但是当我们真的遇到Local Point时却无法解决,即使我们前一次的下降已经越过了Local Point,但还是会因为G的方向再次滚回坑里。而现在我们可以通过Momentum滚过这个坑。
注:文章所有内容均来自李宏毅老师的机器学习系列课程以及本人的一些理解看法,如理解错误是本人问题。还在学习,敬请谅解。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)