【多模态大模型】-- BLIP系列
BLIP系列模型在多模态大语言模型领域做出了重要贡献。BLIP通过混合编码器-解码器架构融合检索、分类和生成任务,并创新性地采用自举方式清洗噪声数据。BLIP-2引入Q-Former作为预训练视觉编码器与语言模型的桥接器,通过表示学习和生成学习两阶段训练实现高效对齐。实验证明BLIP-2在多个任务上表现优异,其核心创新在于冻结预训练参数以降低计算成本。BLIP系列模型虽存在架构复杂、任务联合训练等
最近在准备秋招,感觉对多模态大预言模型的一些基础内容掌握的不够系统,借此梳理一下,今天主要想梳理一下BLIP系列,包括BLIP,BLIP2,BLIP3以及一些变体。
BLIP
多模态混合编码器解码器架构
在讲解BLIP之前我们先介绍一下CLIP,CLIP通过对比学习的方式来对齐图像编码和文本编码,但是CLIP最后得到的模型是文本和图像的编码,其中图片一般是用vit,文本哟该BERT,然后根据INFONCE Loss得到损失,更新这两个模型,但是CLIP一般适用于检索任务,不直接用于生成任务。BLIP通过一个大杂烩将几个任务融合到一块,使其既可以实现检索,又可以实现分类和生成,虽然现在看来,这样的做法有些繁杂,但是GPT说这个的好处是可以更好的处理视觉-语言任务,但是我认为如果有更好的架构能够同时完成多任务,还需要这样叠积木的方式吗。
BLIP的核心贡献主要可以总结为两点:
- 通过一个caption生成器和filter过滤含有噪声的图像文本对数据集。(自举的方式)
- 在各个下游任务上实现了不错的性能。
废话不多说,直接看它的模型的架构图。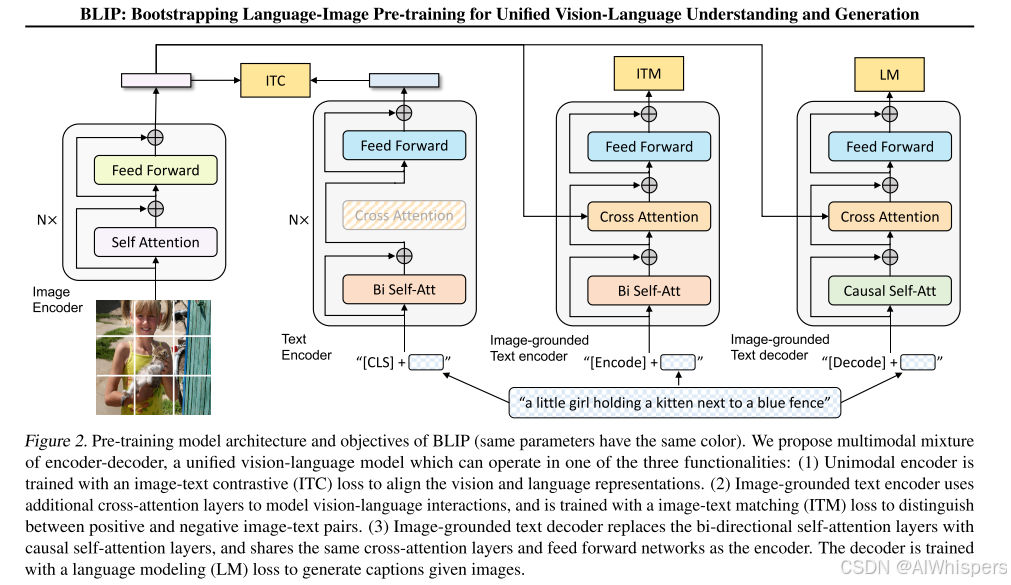
这里主要分为了三个任务,所以对应这三个损失函数的设计。
为了使得图像的编码表示和文本的编码表示对齐,所以采用的对比损失函数。
为了使得图像和文本的内容进行更细粒度的匹配,采用的交叉熵损失函数,对应的一个二分类的标签。
为了生成文本,采用的自回归的损失函数进行训练。
但是这里有个问题是,这里的模型训练的时候是一个一个训练,还是将损失函数合到一起,同时训练这三个模型呢? 这里给出的答案是他们共享一部分参数,然后进行来拟合训练,那就更扯淡了,这不是引入了信用分配的问题吗?就是你怎么知道大的loss是哪一个模型造成的呢?也就是说,你怎么保证这三个模型的目标是一致 的呢?
图文匹配数据集过滤与清洗
接下来,我们再来看看,它对数据是怎么过滤的?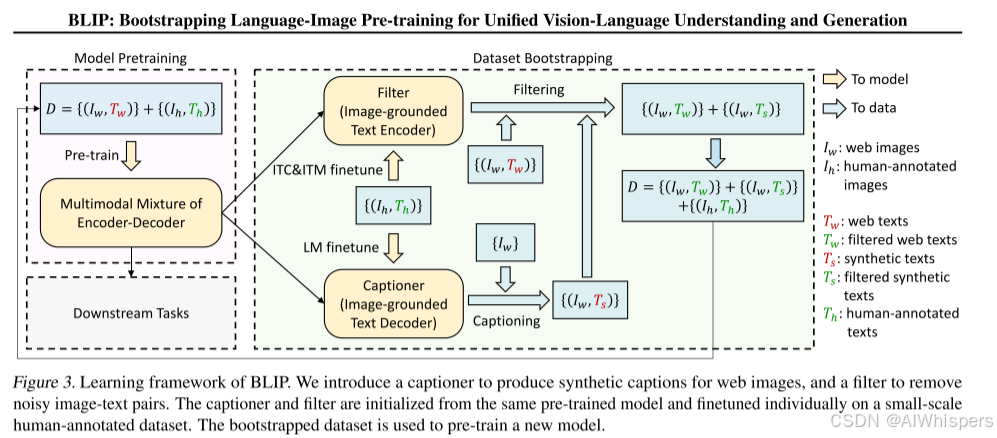
这一步主要是针对web图文匹配数据含有噪声,做的数据处理的一个工作,首先用含有噪声的web数据进行训练,分别得到三个模型,对比模型,分类模型和生成模型,然后再利用人类标注的高质量数据进行微调,微调完之后,其分类能力会进一步提升,然后对含有噪声的web数据进行过滤,主要是采用对比模型和分类模型进行过滤(这里有一个问题就是,这两个不是取任何一个都能完成过滤任务吗?为什么要放一起过滤呢?二者是互补了哪些东西吗?),同样,用caption生成器生成图片对应的caption,然后再用过滤器进行检查,这相当于一种自举的方式,就是用我的数据进行模型的训练,然后模型再过滤和生成我的数据,逐渐清洗,最后得到一个高质量的图文数据集。
实际的实验中证明了caption和filter确实可以提高图文数据集的质量。
但是BLIP有几个局限性,首先它要训练的网络比较多,对训练资源的要求很高,其次它的模型架构有一些叠积木的感觉。
BLIP-2
我们考虑一个问题,我们现在想训练一个多模态大语言模型,虽然在我看来真正的多模态大语言模型按理说应该输出也包含图片才对,就是输入模态和输出模态的空间一样,才算是严格的多模态大模型,但是由于大语言模型断崖式的发展,所以多模态大模型的训练一直是以大语言模型作为核心进行。
当训练的参数量变大时,如果还采用BLIP的形式,从头训练,对计算资源和数据要求十分高,BLIP-2通过采用预训练的视觉编码器和语言生成器,训练一个模态桥接器,来德奥多模态大语言模型。核心就是对齐二者的模态,然后再训练多模态的生成能力。
所以BLIP-2的训练分为两个阶段,第一个阶段是表示学习,用于对齐语言和图片的表示,第二个阶段是训练多模态的生成能力,我们来具体看一下它的架构。
表示学习
这里面提出的桥接器是Q-former,它将图像编码的信息根据文本提取除一个固定数量的向量信息,具体的训练的任务和数据集沿用了BLIP的做法,也就是对齐,匹配和生成。
我这里有个问题是,在训练Q-former的时候,采用的三个任务的训练,最后用的是哪一个特征,将其输入第二阶段中呢?是可学习的这个query吗?这就奇怪,我是不是可以理解为他在提取图像信息的时候,利用了可学习的query和文本的编码,然后做一个自注意力,之后再用图像的编码信息做一个cross-attention,使其文本和query去匹配图像的信息,相当于去关注和文本相关的图像的区域,这样的话,再生成的时候,我只要将最后得到的编码信息输入到文本模型就行了。但是这样的话,为什么还需要query呢?是为了实现固定的输出数量吗
不同的任务对应不同的注意力机制,对于图像-文本对齐任务,相互不可见;对于匹配任务,相互可见;对于生成任务,因果注意力,图像可见(这都不知道咋做的,既然Q-former的作用是根据文本提取图像信息,得到一个固定数量的图像相关表示,但是在生成任务中,是拿的刚开始的prompt进行提取吗?)
多模态生成学习
架构如下,分别用了decoder-only和encoder-decoder架构。Q-Former输出之后还经过一个全连接层,进行维度对齐。
实验结果
在多个任务上,效果都比较好。
局限性
BLIP-2的训练还是分为了多任务联合训练的方式,不知道Q-Former训练的时候,这里的多任务的是联合训练的吗?
除此之外,Q-Former的设计相对复杂,但是它有一个好处是将图像的表示整理成了一个固定维度的信息,但是这个在遇到信息丰富的图像和复杂的任务时不知道是否够用。
BLIP-2的关键创新就是提出了Q-Former来桥接图像和文本模态,并通过冻结预训练的图像编码器和语言模型,减少计算成本和避免灾难性遗忘。
一些细节的进一步解释
问题 1: 在训练Q-Former的时候,采用的三个任务的训练,最后用的是哪一个特征,将其输入第二阶段中呢?是可学习的这个query吗?
是的,就是可学习的query经过transformer得到的表示
问题 2: 为什么还需要query呢?是为了实现固定的输出数量吗?
是的
问题 3: 在生成任务中,是拿的刚开始的prompt进行提取吗?
是的
问题 4: Q-Former训练的时候,这里的多任务是联合训练的吗?
是的
InstructBLIP

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)