2018 GPT1原文-OpenAI-Report Improving Language Understanding by Generative Pre-Training Reading Notes
这是一篇划时代的论文!OpenAI团队提出的GPT-1模型首次展示了"预训练+微调"范式的强大威力。通过在大规模无标注文本上进行生成式预训练,然后针对特定任务微调,GPT-1在12个自然语言理解任务中的9个达到了当时的最佳性能。这种通用的、任务无关的方法为后续的GPT系列奠定了基础,开启了大语言模型的新纪元。值得每个AI从业者深入研究!虽然此文距离当今比较久远,但是其思想仍在学术界有重要的参考价值
本文为个人阅读
GPT1,精读笔记,希望对您有帮助!详情参考原文链接
原文链接:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
通过生成式预训练改进语言理解能力(Improving Language Understanding by Generative Pre-Training)

文章目录
摘要 (Abstract)
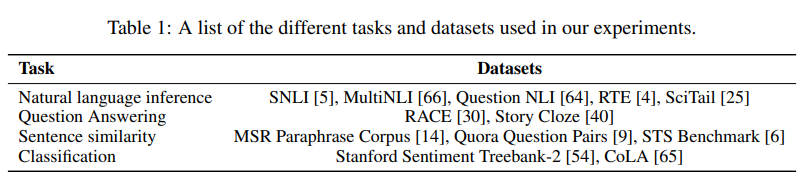
【背景-自然语言理解任务】 自然语言理解包含了这多样的任务,如文本蕴含(Textual Entailment)、问答(Question Answering)、语义相似性评估(Semantic Similarity Assessment)和文档分类(Document Classification)。【问题】 尽管大规模未标注文本语料库(Unlabeled Text Corpora)很丰富,但用于学习这些特定任务的标注数据(Labeled Data)却很稀缺,这使得判别式训练模型(Discriminatively Trained Models)难以充分发挥性能。【本文贡献】 我们证明了通过在多样化的未标注文本语料库上进行语言模型的生成式预训练(Generative Pre-training),随后在每个特定任务上进行判别式微调(Discriminative Fine-tuning),可以在这些任务上实现巨大收益。【优势对比】 与以往方法相比,我们在微调过程中使用任务感知的输入变换(Task-aware Input Transformations)来实现有效迁移,同时只需要对模型架构进行最小改动。【成果】 我们在广泛的自然语言理解基准测试(Benchmarks)上证明了我们方法的有效性。我们的通用任务无关模型(General Task-agnostic Model)在性能上超越了使用针对每个任务专门设计架构的判别式训练模型,在我们研究的12个任务中的9个任务上显著改进了现况技术水平(State of the Art)。例如,我们在常识推理(Commonsense Reasoning)(Stories Cloze Test)上取得了8.9%的绝对改进,在问答(RACE)上取得了5.7%的改进,在文本蕴含(MultiNLI)上取得了1.5%的改进。
要点总结
这段话的核心要点是:GPT-1提出了一种两阶段的半监督学习方法:
- 第一阶段:在大量未标注文本上进行生成式预训练,学习语言的通用表示
- 第二阶段:在具体任务的标注数据上进行判别式微调
- 创新点:使用任务感知的输入变换,避免为每个任务重新设计模型架构
- 效果:一个通用模型在12个任务中的9个上达到了当时的最佳性能
阅读注解
1、第一句提到的几个任务具体内容
文本蕴含(Textual Entailment) :给定两个句子,判断它们的逻辑关系(蕴含/矛盾/中性)【本质还是分类任务】
- 例:前提"所有鸟都会飞" + 假设"企鹅会飞" → 矛盾
问答(Question Answering) :根据给定文档/段落回答问题
- 例:文档讲述历史事件 + 问题"这件事发生在哪一年?"
语义相似性评估(Semantic Similarity Assessment) :判断两个句子的语义相似程度【回归任务,打分】
- 例:"他很开心"和"他心情不错"语义相似度很高
文档分类(Document Classification) :将文档分配到预定义的类别【本质还是分类任务】
- 例:新闻分类(体育/政治/娱乐)、情感分析(正面/负面)
2、判别式 vs 生成式的区别
基本概念:
- 生成式模型:学习数据的联合概率分布 P ( x , y ) P(x,y) P(x,y),能够生成新数据
- 判别式模型:学习条件概率分布 P ( y ∣ x ) P(y|x) P(y∣x),专注于分类边界
在训练上的区别:
生成式训练:
- 目标:预测下一个词 P ( x t + 1 ∣ x 1 , . . . , x t ) P(x_{t+1}|x_1,...,x_t) P(xt+1∣x1,...,xt)
- 数据:只需要大量无标注文本
- 学到:语言的通用表示和语法、语义知识
判别式训练:
- 目标:预测任务标签 P ( y ∣ x ) P(y|x) P(y∣x)
- 数据:需要任务特定的标注数据
- 学到:任务特定的分类能力
在微调上的区别:
- 生成式微调:保持预训练的语言建模目标作为辅助损失
- 判别式微调:添加任务特定的分类头,优化任务特定损失
3、什么叫任务感知的输入变换
任务感知的输入变换是指根据不同任务的特点,将结构化输入转换为模型能处理的序列格式:
- 文本分类:直接输入文本
- 文本蕴含:[前提] KaTeX parse error: Undefined control sequence: \[ at position 5: ** \̲[̲假设] (用 ** $ $分隔)
- 问答:[文档] [问题] ∗ ∗ [ 选项 A ] / [ 文档 ] [ 问题 ] ∗ ∗ ** [选项A] / [文档] [问题] ** ∗∗[选项A]/[文档][问题]∗∗ [选项B]
- 相似性:处理两种句子顺序,然后合并结果
这样做的好处是避免为每个任务重新设计模型架构,只需要改变输入格式。
4、什么是通用任务无关模型
通用任务无关模型指的是:
- 通用性:同一个模型可以处理多种不同类型的NLP任务
- 任务无关:模型架构不需要针对特定任务进行定制化设计
- 迁移能力:预训练获得的知识可以有效迁移到各种下游任务
相对于传统方法需要为每个任务设计专门的神经网络架构,GPT-1证明了一个统一的Transformer架构就能胜任多种任务。
5、什么叫常识推理
常识推理(Commonsense Reasoning) 是指:
定义:基于日常生活中的常识知识进行逻辑推理
特点:需要理解隐含的、未明确表述的背景知识
例子:
- “他忘记带伞,结果被淋湿了” → 推理出下雨了
- Stories Cloze Test:给故事前几句,从两个选项中选择合理的结尾
这类任务测试模型是否真正理解语言,而不仅仅是模式匹配。
1 引言(Introduction)
【监督学习局限】从原始文本中有效学习的能力对于减轻自然语言处理 (NLP) 中对监督学习的依赖至关重要。大多数深度学习方法需要大量的手动标注数据,这限制了它们在许多缺乏标注资源的领域中的适用性 [61] 。【无监督动机转向】在这些情况下,能够利用未标注数据中语言信息的模型为收集更多标注提供了有价值的替代方案,而收集标注可能是耗时且昂贵的。此外,即使在有大量监督数据可用的情况下,以无监督方式学习良好的表示 (Representations) 也能提供显著的性能提升。【证据】迄今为止最令人信服的证据是预训练词嵌入 (Pre-trained Word Embeddings) [10, 39, 42] 的广泛使用,这些嵌入改善了各种NLP任务的性能 [8, 11, 26, 45] 。
要点总结
NLP任务缺乏标注数据,需要利用未标注文本学习,词嵌入预训练证明了这一方向的价值。
【利用无监督数据的难点,2原因】然而,从未标注文本中利用超出词级信息的内容具有挑战性,主要有两个原因。首先,尚不清楚什么类型的这优化目标 (Optimization Objectives) 最有效地学习对迁移有用的文本表示。最近的研究已经探讨了各种目标,如语言建模 (Language Modeling) [44] 、机器翻译 (Machine Translation) [38] 和话语连贯性 (Discourse Coherence) [22] ,每种方法在不同任务上都超越了其他方法。其次,对于如何将这些学习到的表示最有效地迁移到目标任务,还没有达成共识。【现有方法局限性】现有技术涉及对模型架构进行特定任务的更改 [43, 44] ,使用复杂的学习方案 [21] 和添加辅助学习目标 [50] 的组合。这些不确定性使得开发有效的语言处理半监督学习方法变得困难。
要点总结*
利用未标注文本的两大难点:1)不知道用什么优化目标最好(语言建模、机器翻译还是话语连贯性等);2)不知道如何最好地将学到的表示迁移到具体任务。现有方法需要复杂的架构改动和学习方案,增加了开发难度。
【本文方法】在本文中,我们探索了一种半监督方法 (Semi-supervised Approach) 来处理语言理解任务,该方法结合了无监督预训练 (Unsupervised Pre-training) 和监督微调 (Supervised Fine-tuning) 。我们的目标是学习一种通用表示 (Universal Representation) ,这种表示只需要很少的适应就能迁移到广泛的任务中。我们假设可以访问大量未标注文本语料库和几个带有手动标注训练样本的数据集 (Target Tasks) 。我们的设置不要求这些目标任务与未标注语料库属于同一领域。我们采用两阶段训练程序 (Two-stage Training Procedure) 。首先,我们在未标注数据上使用语言建模目标来学习神经网络模型的初始参数。随后,我们使用相应的监督目标将这些参数适应到目标任务。
要点总结
GPT-1的核心方法:采用两阶段训练(先在大量未标注文本上进行**语言建模预训练,再在具体任务上监督微调),目标是学习一种通用表示,能以很少的适应成本迁移到各种任务,且不要求目标任务与预训练语料同域。
阅读注解
语言建模预训练是指:
核心概念: 在大量未标注文本上训练模型预测下一个词,让模型学习语言的统计规律和语义表示。
【本文方法,任务,表现】对于我们的模型架构,我们使用Transformer [62] ,它已经在各种任务上表现出色,如机器翻译 [62] 、文档生成 [34] 和句法分析 (Syntactic Parsing) [29] 。与循环网络 (Recurrent Networks) 等替代方案相比,这种模型选择为我们提供了更结构化的内存 (Structured Memory) 来处理文本中的长期依赖关系 (Long-term Dependencies) ,从而在不同任务间实现稳健的迁移性能。在迁移过程中,我们利用从遍历式方法 (Traversal-style Approaches) [52] 派生的任务特定输入适应,这些方法将结构化文本输入处理为单个连续的词符序列 (Token Sequence) 。正如我们在实验中所证明的,这些适应使我们能够有效地进行微调,同时对预训练模型的架构进行最小改动。
要点总结
GPT-1的架构选择:使用Transformer而非RNN,因为它能更好处理长期依赖关系,实现稳健的任务迁移;同时采用遍历式方法将结构化输入转换为连续词符序列,这样只需最小架构改动就能有效微调。
阅读注解
补充解释:
- 结构化内存: Transformer的自注意力机制能同时关注序列中任意位置,比RNN的顺序处理更适合捕捉长距离关系
- 遍历式方法: 将复杂的结构化输入(如问答对、前提-假设对)按某种顺序排列成一个词符序列,这样就能用同一个模型处理不同类型的任务
【成果,具体达到了什么样的表现】我们在四种类型的语言理解任务上评估我们的方法——自然语言推理 (Natural Language Inference) 、问答、语义相似性 (Semantic Similarity) 和文本分类 (Text Classification) 。我们的通用任务无关模型超越了采用专门为每个任务设计架构的判别式训练模型,在我们研究的12个任务中的9个任务上显著改进了最先进水平。例如,我们在常识推理(Stories Cloze Test) [40] 上取得了8.9%的绝对改进,在问答(RACE) [30] 上取得了5.7%的改进,在文本蕴含(MultiNLI) [66] 上取得了1.5%的改进,在最近推出的GLUE 多任务基准测试 [64] 上取得了5.5%的改进。我们还分析了预训练模型在四种不同设置下的零样本行为 (Zero-shot Behaviors) ,并证明它为下游任务获得了有用的语言知识。
2 相关工作(Related Work)
NLP的半监督学习(Semi-supervised Learning for NLP) 我们的工作大致归属于自然语言的半监督学习类别。这种范式已经引起了极大的兴趣,应用于序列标注 (Sequence Labeling) [24, 33, 57] 或文本分类 [41, 70] 等任务。最早的方法使用未标注数据来计算词级或短语级统计信息 (Word-level or Phrase-level Statistics) ,然后将其用作监督模型中的特征 [33] 。在过去几年中,研究人员已经证明了使用在未标注语料库上训练的词嵌入 [11, 39, 42] 来改善各种任务性能的益处 [8, 11, 26, 45] 。然而,这些方法主要迁移词级信息,而我们的目标是捕获更高级别的语义 (Higher-level Semantics) 。
最近的方法已经调查了从未标注数据中学习和利用超出词级语义的内容。短语级或 句子级嵌入(Phrase-level or Sentence-level Embeddings) 可以使用未标注语料库进行训练,已被用于将文本编码为适合各种目标任务的向量表示 [28, 32, 1, 36, 22, 12, 56, 31] 。
无监督预训练(Unsupervised Pre-training) 【解释我们为啥要用预训练,因为它好】无监督预训练是半监督学习的一种特殊情况,其目标是找到一个好的初始化点,而不是修改监督学习目标。早期工作探索了该技术在图像分类 [20, 49, 63] 和回归任务 [3] 中的使用。后续研究 [15] 证明了 预训练【后面解就是预训练,好用,给出参考文献证据】作为一种正则化方案 (Regularization Scheme) 的作用,使深度神经网络能够更好地泛化 (Generalization) 。在最近的工作中,该方法已被用于帮助训练深度神经网络处理各种任务,如图像分类 [69] 、语音识别 [68] 、实体消歧 (Entity Disambiguation) [17] 和机器翻译 [48] 。
【Similar Work,不同点】与我们最接近的工作线涉及使用语言建模目标预训练神经网络,然后在有监督的目标任务上对其进行微调。Dai et al. [13] 和 Howard and Ruder [21] 遵循这种方法来改进文本分类。然而,尽管预训练阶段有助于捕获一些语言信息,但他们使用LSTM 模型限制了其预测能力的范围 (Short Range) 。相比之下,我们选择的Transformer 网络使我们能够捕获更长范围的语言结构 (Longer-range Linguistic Structure) ,正如我们的实验所证明的。此外,我们还在更广泛的任务范围内证明了我们模型的有效性,包括自然语言推理、释义检测 (Paraphrase Detection) 和故事完成 (Story Completion) 。其他方法 [43, 44, 38] 使用来自预训练语言或机器翻译模型的隐藏表示 (Hidden Representations) 作为辅助特征,同时在目标任务上训练监督模型。这涉及为每个单独的目标任务增加大量新参数,而【优势对比:Transformer vs LSTM】我们在迁移过程中只需要对模型架构进行最小改动。
辅助训练目标(Auxiliary Training Objective) 添加辅助无监督训练目标是半监督学习的另一种形式。Collobert and Weston [10] 的早期工作使用了各种辅助NLP任务,如词性标注 (POS Tagging) 、组块分析 (Chunking) 、命名实体识别 (Named Entity Recognition) 和语言建模来改进语义角色标注 (Semantic Role Labeling) 。最近,Rei [50] 在其目标任务目标中添加了辅助语言建模目标,并在序列标注任务上证明了性能提升。我们的实验也使用了辅助目标,但正如我们所展示的,无监督预训练已经学习了与目标任务相关的几个语言方面。
3 框架(Framework)
我们的训练程序包括两个阶段。第一阶段【预训练,Pre-training】是在大型文本语料库上学习高容量语言模型 (High-capacity Language Model) 。接下来是微调【Fine-Tunning】阶段,我们将模型适应到带有标注数据的判别任务。
3.1 无监督预训练(Unsupervised Pre-training)
给定一个无监督词符语料库 U = { u 1 , … , u n } U = \{u_1, \ldots, u_n\} U={u1,…,un},我们使用标准语言建模目标来最大化以下似然:
L 1 ( U ) = ∑ i log P ( u i ∣ u i − k , … , u i − 1 ; Θ ) ( 1 ) L_1(U) = \sum_i \log P(u_i|u_{i-k}, \ldots, u_{i-1}; \Theta) \quad (1) L1(U)=i∑logP(ui∣ui−k,…,ui−1;Θ)(1)
其中 k k k 是上下文窗口 (Context Window) 的大小,条件概率 P P P 使用参数为 Θ \Theta Θ 的神经网络建模。这些参数使用随机梯度下降 (Stochastic Gradient Descent) [51] 进行训练。
在我们的实验中,我们使用多层Transformer 解码器 (Decoder) [34] 作为语言模型,这是Transformer [62] 的一个变体。该模型在输入上下文词符上应用多头自注意力操作 (Multi-headed Self-attention Operation) ,然后是位置前馈层 (Position-wise Feedforward Layers) ,以产生目标词符上的输出分布:
h 0 = U W e + W p h_0 = UW_e + W_p h0=UWe+Wp
h l = transformer_block ( h l − 1 ) ∀ i ∈ [ 1 , n ] h_l = \text{transformer\_block}(h_{l-1}) \quad \forall i \in [1, n] hl=transformer_block(hl−1)∀i∈[1,n]
P ( u ) = softmax ( h n W e T ) ( 2 ) P(u) = \text{softmax}(h_n W_e^T) \quad (2) P(u)=softmax(hnWeT)(2)
其中 U = ( u − k , … , u − 1 ) U = (u_{-k}, \ldots, u_{-1}) U=(u−k,…,u−1) 是词符的上下文向量, n n n 是层数, W e W_e We 是词符嵌入矩阵 (Token Embedding Matrix) , W p W_p Wp 是位置嵌入矩阵 (Position Embedding Matrix) 。
要点总结
GPT-1的预训练就是让模型在大量文本上不断练习"看前面的词猜下一个词"这个游戏,通过Transformer架构学会理解语言规律,模型把每个词转换成数字向量,再用多层神经网络处理后预测下一个词的概率。
阅读注解:为什么隐藏状态 h n h_n hn要乘上原始 W e W_e We词嵌入矩阵?
核心原因:从隐藏空间映射回词汇空间
- ** h n h_n hn**的含义:最后一层Transformer的隐藏状态,包含了上下文信息
- 目标:要预测下一个词,需要输出词汇表大小的概率分布
- ** W e T W_e^T WeT**的作用:将隐藏维度映射到词汇表维度
数学逻辑:
- h n ∈ R H h_n \in \mathbb{R}^H hn∈RH(隐藏维度)
- W e T ∈ R H × V W_e^T \in \mathbb{R}^{H \times V} WeT∈RH×V(词嵌入矩阵的转置)
- h n × W e T ∈ R V h_n \times W_e^T \in \mathbb{R}^V hn×WeT∈RV(词汇表维度的logits)
- softmax后得到词汇表上的概率分布
所有公式的Shape分析(batch=1)
假设参数:
- 词汇表大小: V = 50 , 000 V = 50,000 V=50,000
- 隐藏维度: H = 768 H = 768 H=768
- 上下文窗口: k = 512 k = 512 k=512
- Transformer层数: n = 12 n = 12 n=12
公式1: L 1 ( U ) = ∑ i log P ( u i ∣ u i − k , … , u i − 1 ; Θ ) ( 1 ) L_1(U) = \sum_i \log P(u_i|u_{i-k}, \ldots, u_{i-1}; \Theta) \quad (1) L1(U)=∑ilogP(ui∣ui−k,…,ui−1;Θ)(1)
- 输入U: [ k ] = [ 512 ] [k] = [512] [k]=[512] (token indices)
- 输出L1:标量(损失值)
公式2: h 0 = U W e + W p h_0 = UW_e + W_p h0=UWe+Wp
- U U U: [ k ] = [ 512 ] [k] = [512] [k]=[512] → 经过embedding lookup变成 [ k , H ] = [ 512 , 768 ] [k, H] = [512, 768] [k,H]=[512,768]
- W e W_e We: [ V , H ] = [ 50000 , 768 ] [V, H] = [50000, 768] [V,H]=[50000,768] (词嵌入矩阵)
- W p W_p Wp: [ k , H ] = [ 512 , 768 ] [k, H] = [512, 768] [k,H]=[512,768] (位置嵌入矩阵)
- U W e UW_e UWe: [ 512 , 768 ] [512, 768] [512,768] (词嵌入结果)
- h 0 h_0 h0: [ 512 , 768 ] [512, 768] [512,768] (初始隐藏状态)
公式3: h l = transformer_block ( h l − 1 ) ∀ i ∈ [ 1 , n ] h_l = \text{transformer\_block}(h_{l-1}) \quad \forall i \in [1, n] hl=transformer_block(hl−1)∀i∈[1,n]
- 输入** h l − 1 h_{l-1} hl−1**: [ 512 , 768 ] [512, 768] [512,768]
- 输出** h l h_l hl**: [ 512 , 768 ] [512, 768] [512,768]
- 所有中间层:都保持 [ 512 , 768 ] [512, 768] [512,768]
公式4: P ( u ) = softmax ( h n W e T ) ( 2 ) P(u) = \text{softmax}(h_n W_e^T) \quad (2) P(u)=softmax(hnWeT)(2)
- h n h_n hn: [ 768 ] [768] [768] (取最后一个位置的隐藏状态)
- W e T W_e^T WeT: [ 768 , 50000 ] [768, 50000] [768,50000] (词嵌入矩阵转置)
- h n ⋅ W e T h_n \cdot W_e^T hn⋅WeT: [ 50000 ] [50000] [50000] (词汇表logits)
- P ( u ) P(u) P(u): [ 50000 ] [50000] [50000] (词汇表概率分布)
关键Shape变化流程:
[ 512 ] → [ 512 , 768 ] → [ 512 , 768 ] → [ 768 ] → [ 50000 ] → [ 50000 ] [512] \rightarrow [512, 768] \rightarrow [512, 768] \rightarrow [768] \rightarrow [50000] \rightarrow [50000] [512]→[512,768]→[512,768]→[768]→[50000]→[50000]
词索引 → 嵌入向量 → 隐藏状态 → 最终向量 → logits → 概率 \text{词索引} \rightarrow \text{嵌入向量} \rightarrow \text{隐藏状态} \rightarrow \text{最终向量} \rightarrow \text{logits} \rightarrow \text{概率} 词索引→嵌入向量→隐藏状态→最终向量→logits→概率
3.2 监督微调(Supervised Fine-tuning)
在使用公式1中的目标训练模型后,我们将参数适应到监督目标任务。我们假设有一个标注数据集 C C C,其中每个实例包含一个输入词符序列 x 1 , … , x m x^1, \ldots, x^m x1,…,xm 以及一个标签 y y y。输入通过我们的预训练模型传递,以获得最终Transformer 块的激活 h l m h_l^m hlm,然后将其输入到添加的带有参数 W y W_y Wy 的线性输出层 (Linear Output Layer) 来预测 y y y:
P ( y ∣ x 1 , … , x m ) = softmax ( h l m W y ) ( 3 ) P(y|x^1, \ldots, x^m) = \text{softmax}(h_l^m W_y) \quad (3) P(y∣x1,…,xm)=softmax(hlmWy)(3)
这给我们以下目标来最大化:
L 2 ( C ) = ∑ ( x , y ) log P ( y ∣ x 1 , … , x m ) ( 4 ) L_2(C) = \sum_{(x,y)} \log P(y|x^1, \ldots, x^m) \quad (4) L2(C)=(x,y)∑logP(y∣x1,…,xm)(4)
我们另外发现,将语言建模 [预训练时候] 作为微调的辅助目标有助于学习,通过 (a) 改善监督模型的泛化能力,以及 (b) 加速收敛 (Accelerating Convergence) 。这与先前的工作 [50, 43] 一致,他们也观察到使用这种辅助目标的性能改进。具体来说,我们优化以下目标(权重为 λ \lambda λ):
L 3 ( C ) = L 2 ( C ) + λ ⋅ L 1 ( C ) ( 5 ) L_3(C) = L_2(C) + \lambda \cdot L_1(C) \quad (5) L3(C)=L2(C)+λ⋅L1(C)(5)
总体而言,我们在微调期间需要的唯一额外参数是 W y W_y Wy 和微调期间(Delimiter Tokens) 的嵌入(如下文第3.3节所述)。
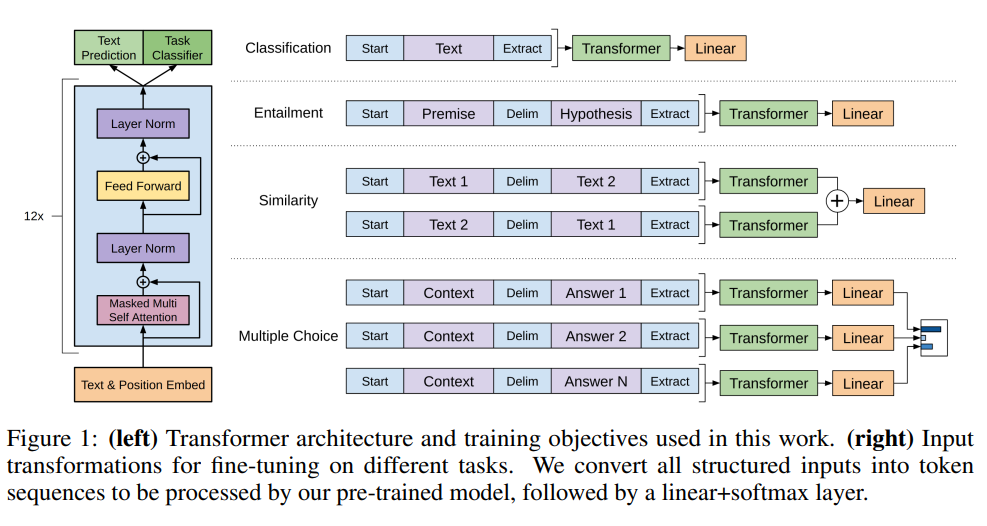
3.3 任务特定输入变换(Task-specific Input Transformations)
对于某些任务,如文本分类,我们可以按照上述描述直接微调我们的模型。某些其他任务,如问答或文本蕴含,具有结构化输入,如有序句子对 (Ordered Sentence Pairs) ,或文档、问题和答案的三元组 (Triplets) 。由于我们的预训练模型是在连续文本序列 (Contiguous Sequences of Text) 上训练的,我们需要进行一些修改来将其应用于这些任务。
以前的工作建议在迁移表示的基础上学习任务特定架构 [44] 。这种方法重新引入了大量任务特定的定制,并且不对这些额外的架构组件使用迁移学习。相反,我们使用遍历式方法 [52] ,将结构化输入转换为我们的预训练模型可以处理的有序序列。这些输入变换使我们能够避免在各个任务中对架构进行大量修改。我们在下面提供这些输入变换的简要描述,图1 提供了可视化说明。所有变换都包括添加随机初始化的开始和结束词符( ⟨ s ⟩ \langle s \rangle ⟨s⟩, ⟨ e ⟩ \langle e \rangle ⟨e⟩)。
文本蕴含(Entailment) 【输入:两个句子 | 输出:蕴含,中性,矛盾 其中之一,本质还是分类任务】对于蕴含任务,我们连接前提 p p p 和假设 h h h 词符序列,中间用分隔符词符($)分隔。
相似性(Similarity) 对于相似性任务,被比较的两个句子没有固有的顺序。为了反映这一点,我们修改输入序列以包含两种可能的句子顺序(中间用分隔符分隔),并独立处理每个以产生两个序列表示 h l m h_l^m hlm,然后逐元素相加后输入到线性输出层。
阅读注解:为什么要交换顺序输入两次?
增强模型的对称性理解
- (Text1, Text2) 和 (Text2, Text1) 应该得到相同的相似度
- 通过两次输入强制模型学习这种对称性
数据增强效果
- 相当于把一个训练样本变成了两个
- 提高模型的泛化能力
消除顺序偏差
- 避免模型对输入顺序产生偏好
- 确保模型关注的是语义内容而不是位置
问答和常识推理(QA Commense Reasoning) 对于这些任务,我们得到一个上下文文档 z z z、一个问题 q q q 和一组可能的答案 { a k } \{a_k\} {ak}。我们将文档上下文和问题与每个可能的答案连接,中间添加分隔符词符,得到 $[z; q; $; a_k]$。每个这样的序列都用我们的模型独立处理,然后通过softmax 层归一化以产生可能答案上的输出分布。
阅读注解:Figure1中的QA看起来只是,Questino和Answer做匹配,也就是说,这是一个选择题QA?
说得很对!这确实不是传统意义上的QA(问答系统) ,而是答案选择/答案排序任务。让我澄清一下:
这个图展示的实际任务
Multiple Choice Question Answering (多选题问答)
- 给定一个Context(上下文/问题)
- 从多个候选答案中选择最佳答案
- 本质上是在做答案匹配度打分
与真正QA的区别
真正的QA系统:
- 抽取式QA:从文本中抽取答案片段
- 生成式QA:生成新的答案文本
- 输出是具体的答案内容
这个图的任务:
- 输入:问题 + 预设的候选答案
- 输出:每个答案的匹配分数
- 本质:答案选择/排序任务
为什么容易混淆
这类任务常见于:
- 阅读理解选择题(如SQuAD 2.0的选择题版本)
- FAQ匹配系统(从预设答案库中找最佳答案)
- 检索式对话系统(从候选回复中选择)
更准确的叫法
- Answer Selection(答案选择)
- Answer Ranking(答案排序)
- Question-Answer Matching(问答匹配)
你的理解完全正确——这只是在计算问题和各个候选答案之间的匹配程度,然后选择得分最高的作为答案,并不是真正在"回答"问题,而是在"选择"最匹配的答案。
4 实验(Experiments)
4.1 设置(Setup)
无监督预训练(Unsupervised pre-training) 我们使用BooksCorpus 数据集 [71] 来训练语言模型。它包含超过7,000本来自各种体裁(包括冒险、奇幻和浪漫)的独特未发表书籍。关键是,它包含长段连续文本,这使得生成模型能够学习对长程信息的条件化。一个替代数据集是1B Word Benchmark,它被类似方法ELMo [44] 使用,大小大致相同,但在句子级别被打乱——破坏了长程结构。我们的语言模型在这个语料库上达到了非常低的词符级困惑度 (Token Level Perplexity) 18.4。
模型规格(Model specification) 我们的模型在很大程度上遵循原始Transformer 工作 [62] 。我们训练了一个12层仅解码器Transformer,带有掩码自注意力头 (Masked Self-attention Heads) (768维状态和12个注意力头)。对于位置前馈网络 (Position-wise Feed-forward Networks) ,我们使用3072维的内部状态。我们使用Adam 优化方案 [27] ,最大学习率为2.5e-4。学习率在前2000次更新中从零线性增加,然后使用余弦调度 (Cosine Schedule) 退火到0。我们在64个随机采样的连续512词符序列的小批次 (Minibatches) 上训练100个epoch。由于layernorm [2] 在整个模型中被广泛使用,简单的权重初始化 N ( 0 , 0.02 ) N(0, 0.02) N(0,0.02) 就足够了。我们使用了40,000次合并的字节对编码 (Bytepair Encoding,BPE) 词汇表 [53] 和残差 (Residual) 、嵌入和注意力dropout,率为0.1用于正则化 (Regularization) 。我们还采用了 [37] 中提出的修改版L2 正则化,对所有非偏置或增益权重使用 w = 0.01 w = 0.01 w=0.01。对于激活函数 (Activation Function) ,我们使用高斯误差线性单元 (Gaussian Error Linear Unit,GELU) [18] 。我们使用学习的位置嵌入 (Learned Position Embeddings) ,而不是原始工作中提出的正弦版本。我们使用ftfy 库来清理BooksCorpus 中的原始文本,标准化一些标点和空白,并使用spaCy 分词器。
微调细节(Fine-tuning Details) 除非另有说明,我们重复使用无监督预训练的超参数设置。我们在分类器中添加dropout,率为0.1。对于大多数任务,我们使用学习率6.25e-5和批次大小 (Batchsize) 32。我们的模型微调很快,对于大多数情况,3个epoch的训练就足够了。我们使用带有0.2%训练预热 (Warmup) 的线性学习率衰减调度 (Linear Learning Rate Decay Schedule) 。 λ \lambda λ 设置为0.5。
4.2 监督微调(Supervised Fine-tuning)
我们在各种监督任务上进行实验,包括自然语言推理、问答、语义相似性和文本分类。其中一些任务作为最近发布的GLUE 多任务基准测试 [64] 的一部分提供,我们利用了这一点。图1 提供了所有任务和数据集的概述。
自然语言推理(Natural Language Inference) 自然语言推理(NLI)任务,也称为识别文本蕴含 (Recognizing Textual Entailment) ,涉及阅读一对句子并从蕴含 (Entailment) 、矛盾 (Contradiction) 或中性 (Neutral) 中判断它们之间的关系。尽管最近有很多兴趣 [58, 35, 44] ,但由于存在各种现象,如词汇蕴含 (Lexical Entailment) 、共指 (Coreference) 和词汇和句法歧义 (Lexical and Syntactic Ambiguity) ,该任务仍然具有挑战性。我们在五个具有不同来源的数据集上进行评估,包括图像标题 (Image Captions) (SNLI)、转录语音 (Transcribed Speech) 、流行小说和政府报告(MNLI)、维基百科文章 (Wikipedia Articles) (QNLI)、科学考试(SciTail)或新闻文章(RTE)。
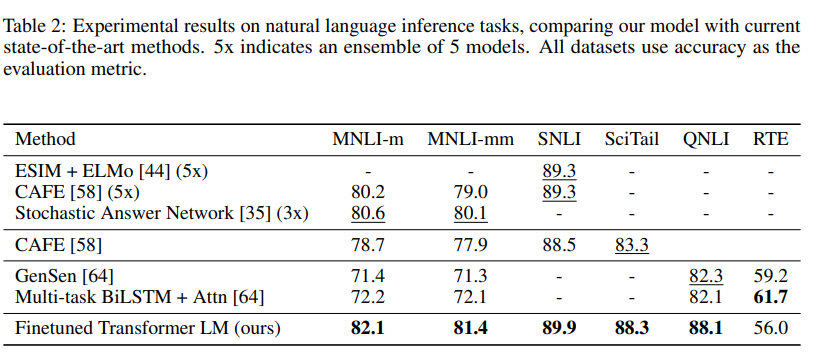
表2 详细说明了我们的模型和以前最先进方法在不同NLI任务上的各种结果。我们的方法在五个数据集中的四个上显著超越了基线,在MNLI 上取得了高达1.5%的绝对改进,在SciTail 上取得了5%的改进,在QNLI 上取得了5.8%的改进,在SNLI 上取得了0.6%的改进,均超过了先前的最佳结果。这证明了我们的模型在多个句子上进行更好推理并处理语言歧义方面的能力。在RTE(我们评估的较小数据集之一,2490个样本)上,我们达到了56%的准确率,低于多任务biLSTM 模型报告的61.7%。鉴于我们的方法在更大的NLI数据集上的强劲性能,我们的模型很可能也会从多任务训练(Multi-task Training)中受益,但我们目前还没有探索这一点。
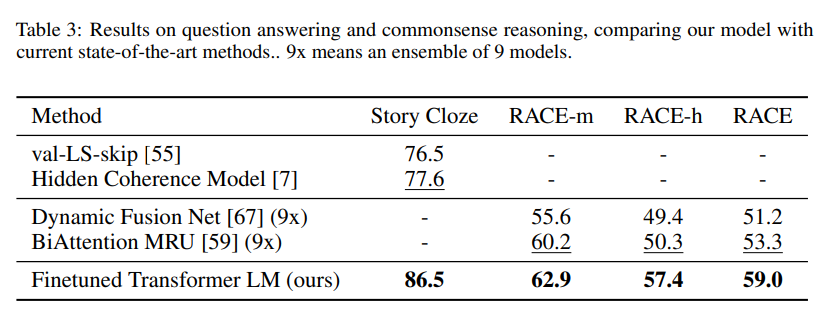
问答和常识推理(Question answering and commonsense reasoning) 另一个需要单句和多句推理方面的任务是问答。我们使用最近发布的RACE 数据集 [30] ,该数据集包含来自中学和高中考试的英语段落及相关问题。该语料库已被证明包含比其他数据集如CNN [19] 或SQuaD [47] 更多的推理类型问题,为我们训练来处理长程上下文的模型提供了完美的评估。此外,我们在Story Cloze Test [40] 上进行评估,该测试涉及从两个选项中选择多句故事的正确结尾。在这些任务上,我们的模型再次以显著边距超越了先前的最佳结果——在Story Cloze 上高达8.9%,在RACE 上总体5.7%。这证明了我们的模型有效处理长程上下文的能力。
语义相似性(Semantic Similarity) 语义相似性(或释义检测)任务涉及预测两个句子在语义上是否等价。挑战在于识别概念的重新表述 (Rephrasing of Concepts) 、理解否定 (Negation) 和处理句法歧义。我们为此任务使用三个数据集——Microsoft Paraphrase corpus(MRPC)[14] (从新闻来源收集)、Quora Question Pairs(QQP) 数据集 [9] 和Semantic Textual Similarity benchmark(STS-B)[6] 。
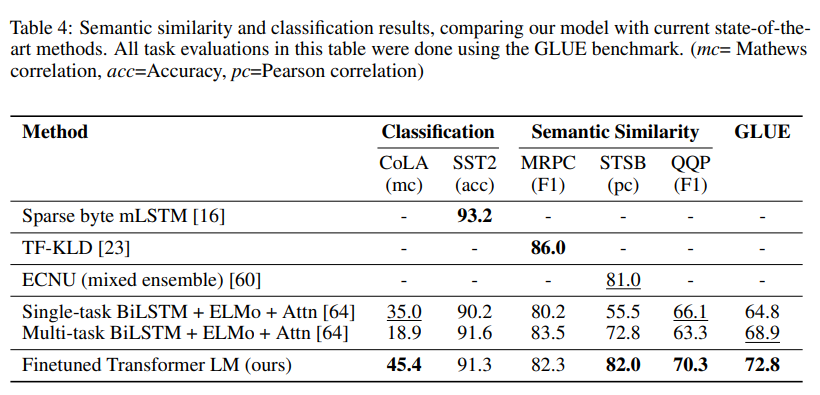
我们在三个语义相似性任务中的两个上获得了最先进的结果(表4),在STS-B 上取得了1分的绝对提升。在QQP 上的性能差异是显著的,比Single-task BiLSTM + ELMo + Attn 绝对改进了4.2%。
分类(Classification) 最后,我们还在两个不同的文本分类任务上进行评估。Corpus of Linguistic Acceptability(CoLA)[65] 包含关于句子是否符合语法的专家判断,并测试训练模型的内在语言偏见 (Innate Linguistic Bias) 。另一方面,Stanford Sentiment Treebank(SST-2)[54] 是一个标准的二元分类任务。我们的模型在CoLA 上获得了45.4的分数,这是对先前最佳结果35.0的特别大的跳跃,展示了我们模型学习到的内在语言偏见。该模型在SST-2 上也达到了91.3%的准确率,这与最先进的结果具有竞争力。我们还在GLUE 基准测试上取得了72.8的总分,显著优于先前最佳的68.9。
总体而言,我们的方法在我们评估的12个数据集中的9个上取得了新的最先进结果,在许多情况下超越了集成方法 (Ensembles) 。我们的结果还表明,我们的方法在不同大小的数据集上都表现良好,从较小的数据集如STS-B(约5.7k训练样本)到最大的数据集——SNLI(约550k训练样本)。
5 分析(Analysis)
迁移层数的影响(Impact of number of layers transferred) 我们观察了从无监督预训练到监督目标任务迁移可变数量层的影响。图2(左)说明了我们的方法在MultiNLI 和RACE 上的性能作为迁移层数的函数。我们观察到标准结果,即迁移嵌入提高了性能,每个Transformer 层都提供进一步的益处,在MultiNLI 上完全迁移的益处高达9%。这表明预训练模型中的每一层都包含解决目标任务的有用功能。
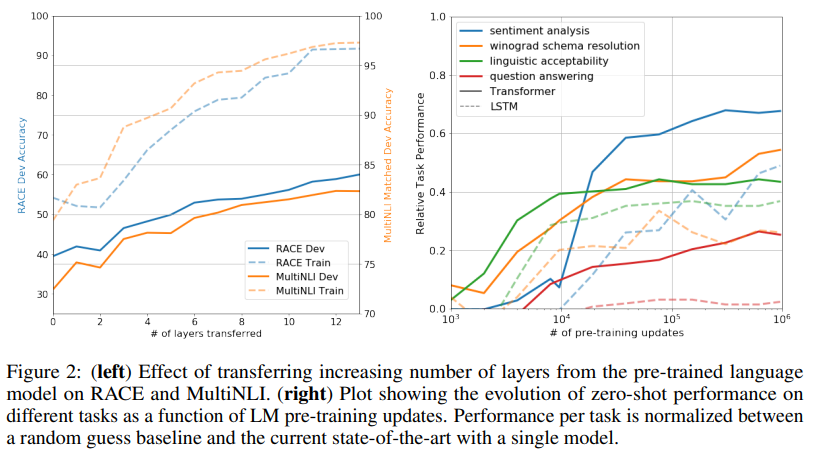
零样本行为(Zero-shot Behaviors) 我们想更好地理解为什么Transformer 的语言模型预训练是有效的。一个假设是,底层生成模型学会执行我们评估的许多任务,以便改善其语言建模能力,Transformer 更结构化的注意力记忆 (Attentional Memory) 与LSTM 相比有助于迁移。我们设计了一系列启发式解决方案 (Heuristic Solutions) ,使用底层生成模型在没有监督微调的情况下执行任务。我们在图2(右)中可视化了这些启发式解决方案在生成预训练过程中的有效性。我们观察到这些启发式的性能是稳定的,并且在训练过程中稳步增加,表明生成预训练支持学习各种任务相关功能。我们还观察到LSTM 在其零样本性能中表现出更高的方差,表明Transformer 架构的归纳偏置 (Inductive Bias) 有助于迁移。
对于CoLA(语言可接受性),样本被评分为生成模型分配的平均词符对数概率 (Average Token Log-probability) ,并通过阈值处理 (Thresholding) 进行预测。对于SST-2(情感分析),我们在每个样本后附加词符"very",并将语言模型的输出分布限制为仅包含单词"positive"和"negative",并猜测它分配更高概率的词符作为预测。对于RACE(问答),我们选择生成模型在以文档和问题为条件时分配最高平均词符对数概率的答案。对于DPRD [46] (winograd schemas),我们用两个可能的指代物 (Referrents) 替换定冠词代词 (Definite Pronoun) ,并预测生成模型在替换后为序列的其余部分分配更高平均词符对数概率的解析。
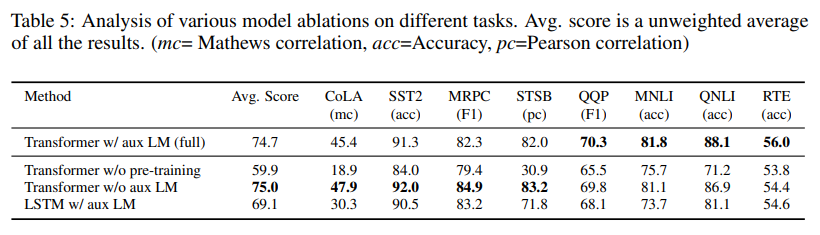
消融研究(Ablation studies) 我们进行了三种不同的消融研究 (Ablation Studies) (表5)。首先,我们检查我们的方法在微调期间没有辅助LM目标的性能。我们观察到辅助目标对NLI任务和QQP 有帮助。总体而言,趋势表明较大的数据集从辅助目标中受益,但较小的数据集不受益。其次,我们通过使用相同框架将其与单层2048单元LSTM 进行比较来分析Transformer 的效果。当使用LSTM 而不是Transformer 时,我们观察到平均分数下降5.6。LSTM 仅在一个数据集——MRPC 上超越了Transformer。最后,我们还与直接在监督目标任务上训练的Transformer 架构进行比较,没有预训练。我们观察到缺乏预训练会损害所有任务的性能,与我们的完整模型相比导致14.8%的下降。
6 结论(Conclusion)
我们介绍了一个框架,通过生成式预训练和判别式微调,使用单个任务无关模型实现强大的自然语言理解。通过在具有长段连续文本的多样化语料库上进行预训练,我们的模型获得了显著的世界知识 (World Knowledge) 和处理长程依赖关系的能力,然后成功迁移到解决判别任务,如问答、语义相似性评估、蕴含确定和文本分类,在我们研究的12个数据集中的9个上改进了最先进水平。使用无监督(预)训练来提升判别任务的性能长期以来一直是机器学习研究的重要目标。我们的工作表明,实现显著的性能提升确实是可能的,并提供了关于什么模型(Transformers)和数据集(具有长程依赖关系的文本)在这种方法中效果最好的提示。我们希望这将有助于促进对无监督学习的新研究,无论是对自然语言理解还是其他领域,进一步改善我们对无监督学习如何以及何时有效的理解。
简要总结:
本文提出了一个两阶段框架:先用生成式方法在大规模文本语料上进行无监督预训练,再针对具体任务进行判别式微调。该方法使单一模型能够处理多种自然语言理解任务,在12个数据集中的9个上达到了最先进性能。
核心贡献:
- 证明了无监督预训练+有监督微调能显著提升判别任务性能
- 发现Transformer架构和长文本数据是这种方法成功的关键
- 为无监督学习在NLP及其他领域的应用提供了重要见解
技术要点:
- 预训练阶段:在多样化长文本语料上学习世界知识和长程依赖处理能力
- 微调阶段:迁移到问答、语义相似性、文本蕴含、分类等下游任务
- 模型架构:基于Transformer的单一任务无关模型
这项工作为后续的预训练语言模型(如GPT系列、BERT等)奠定了重要基础。
本文为个人阅读
GPT1,精读笔记,希望对您有帮助!详情参考原文链接
原文链接:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
参考文献(References)
[1] S. Arora, Y. Liang, and T. Ma. A simple but tough-to-beat baseline for sentence embeddings. 2016.
[2] J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
[3] Y. Bengio, P. Lamblin, D. Popovici, and H. Larochelle. Greedy layer-wise training of deep networks. In Advances in neural information processing systems, pages 153–160, 2007.
[4] L. Bentivogli, P. Clark, I. Dagan, and D. Giampiccolo. The fifth pascal recognizing textual entailment challenge. In TAC, 2009.
[5] S. R. Bowman, G. Angeli, C. Potts, and C. D. Manning. A large annotated corpus for learning natural language inference. EMNLP, 2015.
[6] D. Cer, M. Diab, E. Agirre, I. Lopez-Gazpio, and L. Specia. Semeval-2017 task 1: Semantic textual similarity-multilingual and cross-lingual focused evaluation. arXiv preprint arXiv:1708.00055, 2017.
[7] S. Chaturvedi, H. Peng, and D. Roth. Story comprehension for predicting what happens next. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 1603–1614, 2017.
[8] D. Chen and C. Manning. A fast and accurate dependency parser using neural networks. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 740–750, 2014.
[9] Z. Chen, H. Zhang, X. Zhang, and L. Zhao. Quora question pairs. https://data.quora.com/First-QuoraDataset-Release-Question-Pairs, 2018.
[10] R. Collobert and J. Weston. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th international conference on Machine learning, pages 160–167. ACM, 2008.
[11] R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, and P. Kuksa. Natural language processing (almost) from scratch. Journal of Machine Learning Research, 12(Aug):2493–2537, 2011.
[12] A. Conneau, D. Kiela, H. Schwenk, L. Barrault, and A. Bordes. Supervised learning of universal sentence representations from natural language inference data. EMNLP, 2017.
[13] A. M. Dai and Q. V. Le. Semi-supervised sequence learning. In Advances in Neural Information Processing Systems, pages 3079–3087, 2015.
[14] W. B. Dolan and C. Brockett. Automatically constructing a corpus of sentential paraphrases. In Proceedings of the Third International Workshop on Paraphrasing (IWP2005), 2005.
[15] D. Erhan, Y. Bengio, A. Courville, P.-A. Manzagol, P. Vincent, and S. Bengio. Why does unsupervised pre-training help deep learning? Journal of Machine Learning Research, 11(Feb):625–660, 2010.
[16] S. Gray, A. Radford, and K. P. Diederik. Gpu kernels for block-sparse weights. 2017.
[17] Z. He, S. Liu, M. Li, M. Zhou, L. Zhang, and H. Wang. Learning entity representation for entity disambiguation. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), volume 2, pages 30–34, 2013.
[18] D. Hendrycks and K. Gimpel. Bridging nonlinearities and stochastic regularizers with gaussian error linear units. arXiv preprint arXiv:1606.08415, 2016.
[19] K. M. Hermann, T. Kocisky, E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, and P. Blunsom. Teaching machines to read and comprehend. In Advances in Neural Information Processing Systems, pages 1693–1701, 2015.
[20] G. E. Hinton, S. Osindero, and Y.-W. Teh. A fast learning algorithm for deep belief nets. Neural computation, 18(7):1527–1554, 2006.
[21] J. Howard and S. Ruder. Universal language model fine-tuning for text classification. Association for Computational Linguistics (ACL), 2018.
[22] Y. Jernite, S. R. Bowman, and D. Sontag. Discourse-based objectives for fast unsupervised sentence representation learning. arXiv preprint arXiv:1705.00557, 2017.
[23] Y. Ji and J. Eisenstein. Discriminative improvements to distributional sentence similarity. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 891–896, 2013.
[24] F. Jiao, S. Wang, C.-H. Lee, R. Greiner, and D. Schuurmans. Semi-supervised conditional random fields for improved sequence segmentation and labeling. In Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Computational Linguistics, pages 209–216. Association for Computational Linguistics, 2006.
[25] T. Khot, A. Sabharwal, and P. Clark. Scitail: A textual entailment dataset from science question answering. In Proceedings of AAAI, 2018.
[26] Y. Kim. Convolutional neural networks for sentence classification. EMNLP, 2014.
[27] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
[28] R. Kiros, Y. Zhu, R. R. Salakhutdinov, R. Zemel, R. Urtasun, A. Torralba, and S. Fidler. Skip-thought vectors. In Advances in neural information processing systems, pages 3294–3302, 2015.
[29] N. Kitaev and D. Klein. Constituency parsing with a self-attentive encoder. ACL, 2018.
[30] G. Lai, Q. Xie, H. Liu, Y. Yang, and E. Hovy. Race: Large-scale reading comprehension dataset from examinations. EMNLP, 2017.
[31] G. Lample, L. Denoyer, and M. Ranzato. Unsupervised machine translation using monolingual corpora only. ICLR, 2018.
[32] Q. Le and T. Mikolov. Distributed representations of sentences and documents. In International Conference on Machine Learning, pages 1188–1196, 2014.
[33] P. Liang. Semi-supervised learning for natural language. PhD thesis, Massachusetts Institute of Technology, 2005.
[34] P. J. Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer. Generating wikipedia by summarizing long sequences. ICLR, 2018.
[35] X. Liu, K. Duh, and J. Gao. Stochastic answer networks for natural language inference. arXiv preprint arXiv:1804.07888, 2018.
[36] L. Logeswaran and H. Lee. An efficient framework for learning sentence representations. ICLR, 2018.
[37] I. Loshchilov and F. Hutter. Fixing weight decay regularization in adam. arXiv preprint arXiv:1711.05101, 2017.
[38] B. McCann, J. Bradbury, C. Xiong, and R. Socher. Learned in translation: Contextualized word vectors. In Advances in Neural Information Processing Systems, pages 6297–6308, 2017.
[39] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pages 3111–3119, 2013.
[40] N. Mostafazadeh, M. Roth, A. Louis, N. Chambers, and J. Allen. Lsdsem 2017 shared task: The story cloze test. In Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 46–51, 2017.
[41] K. Nigam, A. McCallum, and T. Mitchell. Semi-supervised text classification using em. Semi-Supervised Learning, pages 33–56, 2006.
[42] J. Pennington, R. Socher, and C. Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543, 2014.
[43] M. E. Peters, W. Ammar, C. Bhagavatula, and R. Power. Semi-supervised sequence tagging with bidirectional language models. ACL, 2017.
[44] M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer. Deep contextualized word representations. NAACL, 2018.
[45] Y. Qi, D. S. Sachan, M. Felix, S. J. Padmanabhan, and G. Neubig. When and why are pre-trained word embeddings useful for neural machine translation? NAACL, 2018.
[46] A. Rahman and V. Ng. Resolving complex cases of definite pronouns: the winograd schema challenge. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pages 777–789. Association for Computational Linguistics, 2012.
[47] P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang. Squad: 100,000+ questions for machine comprehension of text. EMNLP, 2016.
[48] P. Ramachandran, P. J. Liu, and Q. V. Le. Unsupervised pretraining for sequence to sequence learning. arXiv preprint arXiv:1611.02683, 2016.
[49] M. Ranzato, C. Poultney, S. Chopra, and Y. LeCun. Efficient learning of sparse representations with an energy-based model. In Advances in neural information processing systems, pages 1137–1144, 2007.
[50] M. Rei. Semi-supervised multitask learning for sequence labeling. ACL, 2017.
[51] H. Robbins and S. Monro. A stochastic approximation method. The annals of mathematical statistics, pages 400–407, 1951.
[52] T. Rocktäschel, E. Grefenstette, K. M. Hermann, T. Kocisk ˇ y, and P. Blunsom. Reasoning about entailment `
with neural attention. arXiv preprint arXiv:1509.06664, 2015.
[53] R. Sennrich, B. Haddow, and A. Birch. Neural machine translation of rare words with subword units. arXiv preprint arXiv:1508.07909, 2015.
[54] R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Ng, and C. Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pages 1631–1642, 2013.
[55] S. Srinivasan, R. Arora, and M. Riedl. A simple and effective approach to the story cloze test. arXiv preprint arXiv:1803.05547, 2018.
[56] S. Subramanian, A. Trischler, Y. Bengio, and C. J. Pal. Learning general purpose distributed sentence representations via large scale multi-task learning. arXiv preprint arXiv:1804.00079, 2018.
[57] J. Suzuki and H. Isozaki. Semi-supervised sequential labeling and segmentation using giga-word scale unlabeled data. Proceedings of ACL-08: HLT, pages 665–673, 2008.
[58] Y. Tay, L. A. Tuan, and S. C. Hui. A compare-propagate architecture with alignment factorization for natural language inference. arXiv preprint arXiv:1801.00102, 2017.
[59] Y. Tay, L. A. Tuan, and S. C. Hui. Multi-range reasoning for machine comprehension. arXiv preprint arXiv:1803.09074, 2018.
[60] J. Tian, Z. Zhou, M. Lan, and Y. Wu. Ecnu at semeval-2017 task 1: Leverage kernel-based traditional nlp features and neural networks to build a universal model for multilingual and cross-lingual semantic textual similarity. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), pages 191–197, 2017.
[61] Y. Tsvetkov. Opportunities and challenges in working with low-resource languages. CMU, 2017.
[62] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, pages 6000–6010, 2017.
[63] P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th international conference on Machine learning, pages 1096–1103. ACM, 2008.
[64] A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461, 2018.
[65] A. Warstadt, A. Singh, and S. R. Bowman. Corpus of linguistic acceptability. http://nyu-mll.github.io/cola, 2018.
[66] A. Williams, N. Nangia, and S. R. Bowman. A broad-coverage challenge corpus for sentence understanding through inference. NAACL, 2018.
[67] Y. Xu, J. Liu, J. Gao, Y. Shen, and X. Liu. Towards human-level machine reading comprehension: Reasoning and inference with multiple strategies. arXiv preprint arXiv:1711.04964, 2017.
[68] D. Yu, L. Deng, and G. Dahl. Roles of pre-training and fine-tuning in context-dependent dbn-hmms for real-world speech recognition. In Proc. NIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2010.
[69] R. Zhang, P. Isola, and A. A. Efros. Split-brain autoencoders: Unsupervised learning by cross-channel prediction. In CVPR, volume 1, page 6, 2017.
[70] X. Zhu. Semi-supervised learning literature survey. 2005.
[71] Y. Zhu, R. Kiros, R. Zemel, R. Salakhutdinov, R. Urtasun, A. Torralba, and S. Fidler. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In Proceedings of the IEEE international conference on computer vision, pages 19–27, 2015.
本文为个人阅读
GPT1,精读笔记,希望对您有帮助!详情参考原文链接
原文链接:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)