超越算法:数据准备——大模型背后的真正挑战
数据准备是大模型训练的核心环节,涉及数据采集、清洗、标注、增强、分割、评估和存储等多个步骤。高质量的数据不仅能提升模型性能,还能减少训练成本和时间。
引言
现在每个人的生活似乎都已经离不开 AI,或是 DeepSeek,或是豆包,又或是各式各样其他的生成式 AI 应用。还有些是你无法感知的形式,比如购物软件的推荐算法,刷新闻和短视频的“猜你爱看”,AI 早已无处不在于我们的生活。在惊叹于这些 AI 或者大模型(LLMs)展现出的“智能”时,你是否有想过,这些 AI 是如何拥有着“与生俱来的智慧”。今天,我们不谈那些晦涩难懂的,离我们普通人遥远的算法与代码,只来聊聊这些令人惊叹的 AI/大模型能力背后,一个共同的、不可或缺的根基——数据。
大模型的学习过程
想象一下一个呱呱坠地的婴儿,他拥有学习语言的潜力,但如果没有听到父母、周围环境的声音,没有接触到书籍、对话,他永远无法学会说话,更无法理解世界的复杂。而大模型的学习过程,在本质上与此相似。
数据,就是大模型的“食物”,是它认知世界、构建“智慧”的唯一原料。 我们“喂”给它什么,它就“长”成什么样。给它丰富、多样、干净、均衡的“营养”(高质量数据),它就能茁壮成长,展现出强大的理解力、创造力和判断力。反之,如果“喂”的是劣质、单一、甚至“有毒”的信息(低质、偏见数据),那么无论背后的算法多么精妙,训练过程多么漫长,最终得到的模型也只会是“营养不良”甚至“病态”的——输出错误、偏见,或者毫无意义的废话。
那么支撑这份“智能”的庞大知识库,究竟是如何建立起来的?今天,我们就来了解下大模型训练中那个不常被提到,却如同“心脏”般至关重要的环节——数据准备。它远非简单的“收集资料”,而是一场涉及海量资源、复杂技术、深刻伦理考量的艰巨工程。
为什么数据准备是模型的命门?
数据是喂给模型的“食物”,但数据的质量究竟如何影响最终的模型的专业度?为什么说数据准备是整个模型训练过程的“命门”,决定了它的成败?让我们深入了解“食材”的选择和处理如何塑造模型的“智商”和“情商”。
数据是知识的唯一源泉:AI 的“世界百科全书”
虽说可以将模型类比为新生的婴儿,但它不能像人类一样通过感官和体验直接学习。它所有的“知识”——从基本的语法规则、历史事实、科学概念,到更微妙的推理能力、情感理解、写作风格——全部来源于它被“喂”进去的训练数据。
想象你要编写一本覆盖人类所有知识的百科全书。你的信息来源只能是别人写好的书籍、文章、网页、对话记录等文本资料。这些资料的广度、深度和准确性,直接决定了你这本百科全书的权威性和价值。模型本质上就是在消化这样一部由海量资料构成的“世界百科全书”,并从中学习规律、提取信息。
所以,数据决定了模型知道什么,不知道什么,以及它“理解”世界的边界在哪里。 没有足够相关数据,模型在特定领域,如医疗或工业的垂直领域,就会表现得像个“无知者”。
质量决定模型的“智商”与“情商”:Garbage in,Garbage out
数据的质量是模型能力的基石,直接影响其输出的准确性、可靠性、有用性和安全性。
-
高质量数据 = 更聪明、更靠谱的模型:
想象你正在训练一个医疗问答模型去开发智能问诊系统。如果它的训练数据里充斥着过时的医学知识、未经证实的偏方或错误信息,那么它给出的建议就可能误导病人,甚至危及生命。这就是“垃圾进,垃圾出”(Garbage In, Garbage Out)的残酷现实。
所以高质量数据意味着事实准确、信息清晰、逻辑连贯、语言规范。这能让 AI 学会正确的知识表达和推理逻辑,减少“一本正经地胡说八道”的情况。
-
多样性数据 = 更强的适应力与包容性:
如果一个翻译 AI 只训练了正式新闻稿和科技论文的数据,它可能完全无法理解网络俚语、方言或者诗歌的意境。如果一个服务全球用户的客服 AI 只接触过特定文化背景的对话,它可能会误解来自不同文化用户的表达方式和情感。
所以,多样性体现在语言种类、文化背景、专业领域、文体风格、观点视角等多个维度。丰富多样的“食材”能让AI 学会举一反三(泛化能力),理解复杂语境,服务更广泛的人群,并减少因数据单一带来的“偏见盲区”。
-
数据治理与准备 = 解锁 AI 的“专业技能”:
那么,想让 AI 学会特定任务,比如精准回答用户问题、总结长篇文章、识别文本中的情绪(是表扬还是投诉)?仅仅喂给它海量原始文本是不够的。这就像只给学徒看成品,却不教具体步骤,这时就需要数据准备与治理,覆盖从数据清洗到数据评估的方方面面,包括为数据添加上下文、分类或标签,对数据进行增强、评估等等。例如,从大规模纯文本中挖掘问答对(问答数据集),进行监督微调或强化学习训练,教会 AI 如何精准回答问题。
总而言之,精心准备的数据是训练强大、可靠、安全模型的绝对前提。它是 AI 能力的基石——决定了 AI 的知识储备和基本素质;它也是 AI 能力的潜在天花板——数据能达到的质量和多样性上限,很大程度上框定了模型最终能达到的高度。
巨大挑战:数据准备为何如此之难?
理解了数据准备对于大型语言模型(LLM)的核心价值,我们必须要正视其背后所蕴含的艰巨挑战了。为训练一个强大的模型去准备数据,远非简单的信息收集,而是一项融合了尖端技术、复杂工程、深刻伦理考量和严格法律合规的系统性工程。下面我们来看看数据准备环节面临的主要难点:
规模挑战:处理海量数据的复杂性
以企业来举例,如果企业想要训练顶尖模型,一般需要处理 PB 级别(即数百万GB)的文本+多模态数据,其规模相当于数字化数个大型图书馆的全部馆藏。另一方面,可能企业的数据会存在于不同的系统中,所以需要将这些不同的来源将数据整合到一起,进行安全存储、备份和有效管理。PB 级数据,需要构建强大的数据中心基础设施和复杂的数据管理系统,成本高昂。
另外,在数据治理方面,如果仅让人类专家做数据标注,对于精度高、能处理复杂/模糊/需要专业知识的任务(如标注医学影像、判断法律文本的隐含意图)等,速度慢、成本极其高昂。而雇佣成千上万名专家,手动阅读、理解并标记数亿甚至数十亿条数据,其时间和金钱成本更是天文数字。而且,如何科学地确定并实现不同来源、类型数据在数据集中的合理比例?比例失衡会导致模型在特定领域或场景表现不佳。
质量挑战:确保数据的高标准
我们在现实中经常遇到的状况是,原始数据普遍存在质量问题,包括:错误(事实性、拼写、语法)、过时信息、广告噪音、恶意内容、无意义文本(乱码、重复内容)以及大量低价值信息。所以核心难点就在于:
-
精准识别:自动化识别数据中的各类缺陷,特别是隐含偏见、逻辑谬误以及低质但形式合规的内容,技术上难度极大,难以达到完美。
-
高效清洗: 对海量数据进行精细化清洗和过滤,是一项极其耗时且资源密集的任务,亟需自动化工具进行质量控制和纠错,以减少人工介入的资源。
-
质量标准界定: 不同应用场景对“高质量”数据的定义存在差异(如严谨性 vs. 生动性),这为自动化清洗设置了统一标准的障碍。
预处理与工程挑战:构建高效处理流水线
-
数据格式标准化: 将来自不同源头(网页、PDF、数据库、文本文件)的异构数据统一转换为模型训练所需的标准化格式(如纯文本、特定token序列)。
-
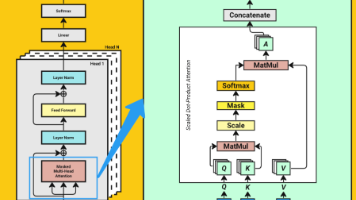
数据表征: 将文本进行分词(Tokenization)并转化为数值向量(Vectorization) 是模型理解的基础,不同的处理策略直接影响模型性能。
-
数据集构建: 科学地将清洗后的数据划分为训练集、验证集和测试集,并严格防止数据泄露,确保模型评估的客观性。
-
工程化支撑: 实现从数据采集、清洗、标注、转换到供给训练的全流程,需要构建稳定、高效、可扩展的大规模数据处理平台和基础设施(Data Pipeline),工程复杂度极高。
数据准备流程概述
在前文中,我们已经探讨了数据对大模型的重要性,以及数据准备过程中面临的巨大挑战。高质量的数据是大模型性能的基础,而数据准备则是将原始数据转化为可用训练数据的关键环节。下面将简单介绍大模型训练数据的完整准备流程:
-
数据采集:从公开数据集、企业内部系统、互联网(如网页、社交媒体)等多源获取原始数据,需确保数据多样性、合法性和时效性。
-
数据清洗:
-
去重:通过哈希算法等识别并删除重复数据。
-
去噪:过滤低质量内容(如乱码、广告)、敏感信息(如隐私数据)及非目标语言数据。
-
格式标准化:统一不同来源的数据格式(如文本、图像的编码规范)。
-
-
数据标注:对监督学习任务添加标签,如文本分类、命名实体识别等,可采用人工标注或半自动工具。
-
数据增强:通过同义词替换、数据翻译、随机删除等生成新样本,提升模型泛化能力。
-
数据分割:按比例划分为训练集、验证集、测试集,确保模型评估的可靠性。
-
质量评估:通过人工抽样、自动化工具检查数据的完整性、一致性、准确性及代表性。
-
存储与优化:选择高效存储方案,对数据进行分片、索引,提升训练效率。
注:多模态数据(如图像+文本)需额外处理跨模态对齐与语义融合,确保不同模态数据的语义一致性
数据准备是大模型训练的核心环节,涉及数据采集、清洗、标注、增强、分割、评估和存储等多个步骤。高质量的数据不仅能提升模型性能,还能减少训练成本和时间。
写在最后
AI 时代的到来,催着我们加快步伐跟上发展的潮流,未来的企业将不仅仅是“数字化”的,更是“智能化”,而 AI 智能化的背后离不开高质量数据集的构建。作为模型训练不可逾越的核心环节,数据准备也应该以一种新的范式来赋能 AI 应用落地实践。我们的新一代 ADP 智能数据平台应运而生——致力于打造一个智能化、标准化的数据生态闭环,为模型训练扫清最难的障碍,让数据真正成为驱动智能跃升的助力!
DataFlow 数据准备平台
DataFlow 是我们自研的数据准备系统,旨在从噪声数据源(PDF、纯文本、低质量问答)中解析,生成,加工并评估高质量数据,以提升大语言模型(LLMs)在特定领域的表现,支持预训练、监督微调(SFT)、强化学习训练以及基于知识库的 RAG 系统。已经在医疗、金融和法律等多个垂类领域实证验证了 DataFlow 的有效性。
DataFlow 内置了多种基于规则、深度学习、大语言模型及其 API 的 数据算子(Operators),并将其系统性地整合为多条 数据流水线(Pipelines),共同组成完整的 DataFlow 系统。此外,DataFlow 还构建了智能的 DataFlow-Agent,支持按需动态编排已有算子,合成新的数据流水线。
OriginHub MyScaleDB
OriginHub MyScaleDB 是一款统一存储和管理海量结构化+非结构化数据的 AI 数据库。它以 SQL 列存数据库为底座,融合了向量分析与检索引擎、全文检索引擎以及知识图谱引擎,用一个数据库即可支持多模态数据的管理与检索,打破企业数据孤岛,降低多库运维的成本。
OriginHub MyScaleDB 完全兼容并拓展了 SQL,仅使用一条 SQL 语句就可以对业务数据与向量数据完成联合查询,PB 级数据也可实现毫秒级查询速度。
如果你想体验这套端到端的自动化数据准备解决方案,我们的 ADP 平台已经准备就绪,欢迎注册使用!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)